相邻两行差值的求解与连续天数求解 --hive大数据分析
这一篇文章的题目来源于2022安徽省大数据网络赛的大数据分析部分。为了保证题目的完整性我把前面几问也贴出来了,如果您只是想查看一下思路可以忽略前面直接跳到思路部分。
数据结构说明:
user_low_carbon 用户蚂蚁森林低碳生活记录流水表
-
- 字段 描述 类型
-
- user_id 用户ID String
-
- data_dt 日期 String
-
- low_carbon 减少碳排放(g) Int
plant_carbon 蚂蚁森林植物换购表
-
- 字段 描述 类型
-
- plant_id 植物编号 String
-
- plant_name 植物名 String
-
- low_carbon 换购植物所需要的碳 Int
注意,数据文件名称分别与表名称对应,(字段分隔符为“,”)
1、 创建一个数据库,以你的用户名命名,创建成功后使用use命令切换为该库,并执行set hive.cli.print.current.db=true;截图(2分)
1)命令截图:

2)执行命令结果截图:
2、根据表结构在HIVE中创建所需表,并写出建表语句(3分)
1) 创建hive表语句截图:

2)创建成功,执行show tables;截图;

3、将数据加载到表中,写出加载数据的语句(3分)
- 导入第2步 创建表中的语句截图;

2)执行 select * from table_name 并截图(其中table_name 为前面创建的表名)

前面几问都比较常见因此我没有展开说,后面两问比较有难度因此我进行一定的思路阐述
问题描述:
假设2022年01月01日开始记录低碳数据(user_low_carbon),假设2022年10月01日之前满足申领条件的用户都申领了一颗p004-胡杨,剩余的能量全部用来领取“p001-梭梭树” 。统计在10月01日(不包含)累计申领“p001-梭梭树” 排名前10的用户信息,以及他比后一名多领了几颗梭梭树。 输出结果样式:
user_id plant_count less_count(比后一名多领了几颗梭梭树)
u_101 20 5
u_088 15 1
u_103 14 …使用所建的表完成蚂蚁森林低碳用户排名分析
问题描述:
查询user_low_carbon表中每日流水记录,条件为:
用户在2022年,连续三天(或以上)的天数里,
每天减少碳排放(low_carbon)都超过100g的用户低碳流水。
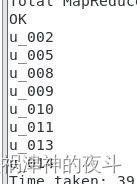
最终返回满足以上条件的user_id
例如用户u_002符合条件的记录如下,因为2022/06/02~2022/06/05连续四天的碳排放量之和都大于等于100g:
--------------------------------------思路介绍---------------------------------------------------------------------------------------
后面这两问相较于往年的题目就没有那么熟悉,需要一定的灵活处理。并且这两问第二个连续天数问题有相关的思路,但第一个网上我没有找到合适的。
相邻两行差值的求解
这里题目要求的是按照降序排序后,求出当前一名与下一名的种植树的数量的差值。涉及到order by 排序,表的连接等还有一些比如将浮点数按照下取整的方式转化为整形等细节操作。
为了减少思维的复杂性,我建立了临时表,且建立了不止一个,以使得每一次写的sql语句没有那么长。
创建每名用户的梭子树数量表
字段包括user_id,plant_count 指用户的种植梭子树的数量。
hive的取整函数:
Hive浮点数取整:
Round:四舍五入取整
Ceil:向上取整
Floor:向下取整
Cast:舍弃小数取整 cast(xx as int)
这里我们使用的是cast取整
create table temp as select user_id,cast((sum_carbon-215)/27 as int) plant_count from
(select user_id,sum(low_carbon) sum_carbon from user_low_carbon group by user_id) b where sum_carbon-215>=0;

为用户添加序号标签
create table temp2 as select user_id,plant_count,row_number() over(order by plant_count desc) rk from temp;
create table temp1 as select user_id,plant_count,row_number() over(order by plant_count desc) rk from temp;
这里建了两个一模一样的表,都只是加上了标签而已如果用于生产就会显得多余造成资源浪费,但解题的话可以省去思维难度。下面要对这两个表进行表连接,可以采用笛卡尔积连接的形式其实也可以采用内连接的方式
相邻两行某列元素差值的求解
这里我之前一直想着使用窗口函数,但试了好久都不行,后来突然灵机一动发现这原来也是个表连接呀!!!!接着就解决了。
select temp1.user_id,temp1.plant_count,temp1.plant_count-temp2.plant_count
from temp1,temp2 where temp2.rk - temp1.rk ==1;
这个就很简单啦!进行笛卡尔积连接后筛选出一行与下一行连接的情况,然后做个差就可以了
也可以使用内连接的形式
select temp1.user_id,temp1.plant_count,temp1.plant_count - temp2.plant_count from
temp1 join temp2 on temp2.rk = temp1.rk+1;
问题总结
这一问有难度但也不是特别难,其考察的还是一个简单的表连接问题,我一直想着使用窗口函数,导致思路有些偏了,然后卡了好久,思路还是要灵活一些,不能总想着用一行代码就给写完。
连续天数的求解
日期处理
hive常用日期处理函数hive sql的常用日期处理函数总结


这里字符串已经是标准形式了,因此我们不需要对他进行转化。
这一部分有一篇博客比较详细,请查看:hive之连续登录问题
求解
思路
这个的思路用到的是一个开窗函数与求解TopN问题用到的其实是一个,并没有什么新的,只是求解起来思维难度更大了。我们按user_id进行partion by 然后按date进行order by然后给每行一个rank,再使每行date减去rank,然后按其结果进行group by最后统计一下个数。
不是太好理解以至于一开始我觉得这种方法是错的,大致模拟一下确实是这样。

代码
hive> select user_id from (
> select user_id,count(1) as count_date from (
> select user_id,date_sub(data_dt,rk) as start_date from (
> select user_id,data_dt,row_number() over(partition by user_id order by data_dt) rk from (
> select user_id,data_dt,sum(low_carbon) as sum_carbon from user_low_carbon group by user_id,data_dt)a
> where a.sum_carbon>100)b)c group by c.user_id,c.start_date)
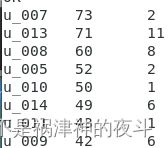
> d where d.count_date>=3;
结果