爬虫练习题(二)
- 博主链接:张立梵的爬虫开端
- 个人介绍:小编大一视传在读,目前即将大二
- 欢迎大家对文章
关注、点赞、收藏
最近小伙伴问我有什么刷题网站推荐,我在这里推荐一下牛客网,这里面包含各种题库,全都是免费的题库,可以全方面提升你的数据操纵逻辑,提升编程实战技巧,赶快来一起刷题吧牛客网笔试题库|面试经验
题目:利用referer防盗链参数反爬数据,以梨视屏为例
1.携带referer参数
2.把视屏下载保存到本地
打开视屏,抓他的包,要求要有referer防盗链的视屏

防盗链式记录从哪个地址跳转过来的?有些会携带,有些会不携带,服务器会根据这个检查,一旦核验,同样也会视为爬虫自动化程序,所以我们要携带这个参数
headers = {
'referer':'https://www.pearvideo.com/video_1766981'
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}只向 request url 发起请求,只会返回源代码,就是 HTML 文件,不是视频数据,一般音视频都在媒体,也就是 media 里,好看视频可以在,数据包里显示视频信息,她的 request url 对应的就是视频,点开就能打开,其实梨视频也是一样的

用字符串切片,并且可以以符号'_'分割,split 是分割,rsplit,也是分割方向是从右向左,这样可以把链接最后的数字拿下来,因为唯一变得一串数字是指定视频的位置,不同的数字串指定的是不同的视频,所以是个变量
以上海人的吃瓜自由奋斗史为例
https://xie.infoq.cn/link?target=https%3A%2F%2Fwww.pearvideo.com%2Fvideo_1763204
import requests
work = input('视频url:')
# work = 'https://www.pearvideo.com/video_1763204'
# print(work.split('_')[-1]) 导出最后一串数字
z_f = work.split('_')[-1]我们第一步,首先找链接相同的部分,看看不同的部分有没有什么规律?但很显然,貌似并没有什么规律
我们先复制链接,粘贴到 py charm 上,复制 1 到 2 个链接,查看一下有没有什么规律?我们发现中间有一部分是有区别的,但是并不能看出它有什么规律
我们可以在元素里定位视频,也会有一个 src 参数能拿到链接,可以把这个链接与第二个链接进行对比,发现是一模一样的,在元素面板中就可以看到 URL,那么直接对 URL 发起请求,能不能得到这个 URL?我们可以在网页源码中用快捷键 ctrl+c,ctrl+f,ctrl+v,查找一下这个链接,我们发现没有搜索结果,也就是说,没有数据,因为这个数据是动态数据,所以我们直接在手页面发起请求是无法获得 MP4 文件的
如果在主页面响应内容里没有找到数据,但我们能在哪里查看呢?可以在 XHR 里面筛选
这是通过两种方法获得的 URL
所以接下来就要满足用户输入这个网址
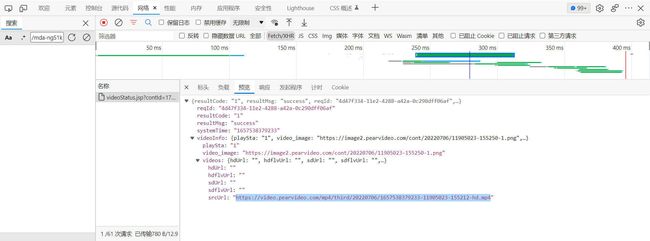
在 XHR 里复制的链接是不完整的,在源码中找到并与 XHR 链接比较,补全缺失

发现有部分不一致,我们更改不一致的地方
比较两个视频,我们可以发现都是 cont 开头,那么接下来就是找数字的规律了
搜索数字在搜索栏中也可以看到
所以我们要在其他视频上找到缺失的部分
XHR:https://video.pearvideo.com/mp4/adshort/20220524/1657541705071-15884803_adpkg-ad_hd.mp4
视频:https://video.pearvideo.com/head/20220524/cont-1763204-15884893.mp4
能够得到这个网址
https://video.pearvideo.com/mp4/adshort/20220531/cont-1763997-15888808_adpkg-ad_hd.mp4
https://video.pearvideo.com/mp4/adshort/20220524/cont-1763204-15884803_adpkg-ad_hd.mp4
根据上面得到的数字串,拼接新的 url,就是把 1763204 改为 z_f
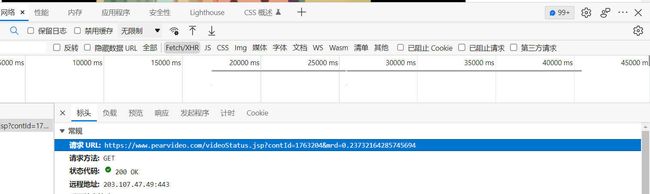
url = f'https://www.pearvideo.com/videoStatus.jsp?contId={z_f}&mrd=0.23732164285745694'
打印验证
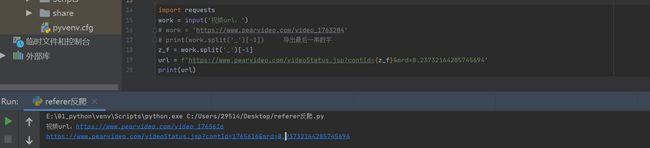

URL 是一模一样的,但是为什么会出现上面的问题呢?手动复制 URL 就没有网页,可能是 referer 反爬
import requests
work = input('视频url:')
# work = 'https://www.pearvideo.com/video_1763204'
# print(work.split('_')[-1]) 导出最后一串数字
z_f = work.split('_')[-1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49',
'Referer': 'https://www.pearvideo.com/video_1763204'
}
url = f'https://www.pearvideo.com/videoStatus.jsp?contId={z_f}&mrd=0.23732164285745694'
print(url)
解释数据:
E:\01_python\venv\Scripts\python.exe E:/01_python/反爬.py
视频url:https://www.pearvideo.com/video_1763204
https://www.pearvideo.com/videoStatus.jsp?contId=1763204&mrd=0.23732164285745694
进程已结束,退出代码0接下来就是获取数据
import requests
work = input('视频url:')
z_f = work.split('_')[-1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49',
'Referer': f'https://www.pearvideo.com/video_{z_f}'
}
url = f'https://www.pearvideo.com/videoStatus.jsp?contId={z_f}&mrd=0.23732164285745694'
print(url)
response = requests.get(url,headers=headers)
print(response.text)
解释数据:
E:\01_python\venv\Scripts\python.exe E:/01_python/反爬.py
视频url:https://www.pearvideo.com/video_1765616
https://www.pearvideo.com/videoStatus.jsp?contId=1765616&mrd=0.23732164285745694
{
"resultCode":"1",
"resultMsg":"success", "reqId":"b1c73e26-99f2-4393-9f7e-6d6c12aeaef1",
"systemTime": "1657550407682",
"videoInfo":{"playSta":"1","video_image":"https://image.pearvideo.com/cont/20220617/cont-1765616-12687510.jpeg","videos":{"hdUrl":"","hdflvUrl":"","sdUrl":"","sdflvUrl":"","srcUrl":"https://video.pearvideo.com/mp4/adshort/20220617/1657550407682-15897269_adpkg-ad_hd.mp4"}}
}
进程已结束,退出代码0
json 可以转为字典格式
li_fan = response.json()['videoInfo']['videos']['srcUrl']
li_fan = li_fan.replace(li_fan.rsplit('/',1)[-1].split('-',1)[0],f'cont-{z_f}')
with open('视屏.mp4','wb')as f:
f.write(requests.get(li_fan).content)所以这题整体代码为
import requests
work = input('视频url:')
z_f = work.split('_')[-1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49',
'Referer': f'https://www.pearvideo.com/video_{z_f}'
}
url = f'https://www.pearvideo.com/videoStatus.jsp?contId={z_f}&mrd=0.23732164285745694'
print(url)
response = requests.get(url,headers=headers)
print(response.text)
li_fan = response.json()['videoInfo']['videos']['srcUrl']
li_fan = li_fan.replace(li_fan.rsplit('/',1)[-1].split('-',1)[0],f'cont-{z_f}')
with open('视屏.mp4','wb')as f:
f.write(requests.get(li_fan).content)
解析结果:
E:\01_python\venv\Scripts\python.exe E:/01_python/反爬.py
视频url:https://www.pearvideo.com/video_1765616
https://www.pearvideo.com/videoStatus.jsp?contId=1765616&mrd=0.23732164285745694
{
"resultCode":"1",
"resultMsg":"success", "reqId":"d52fda1d-ad5b-46c5-a151-d062b789e371",
"systemTime": "1657554157561",
"videoInfo":{"playSta":"1","video_image":"https://image.pearvideo.com/cont/20220617/cont-1765616-12687510.jpeg","videos":{"hdUrl":"","hdflvUrl":"","sdUrl":"","sdflvUrl":"","srcUrl":"https://video.pearvideo.com/mp4/adshort/20220617/1657554157561-15897269_adpkg-ad_hd.mp4"}}
}
进程已结束,退出代码0
这样一个视屏就爬到手了,此题代码可使用于梨视屏,其他网站需要进一步分析重新搭建
切记 referer 参数可以用于反爬
大家一起来牛客刷题吧!
