深度学习笔记:卷积神经网络(2)
卷积神经网络SimpleConvNet的python实现
# coding: utf-8
import sys, os
sys.path.append('D:\AI learning source code') # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""求梯度(数值微分)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
1
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
在构造方法中我们设置了卷积神经网络的参数输入神经元个数,filter_num(卷积核个数),filter_size(卷积核大小),pad(填充量),stride(卷积核步幅),隐藏层神经元个数,输出神经元个数,权重初始值标准差。
根据传入的参数,程序算出卷积层和池化层的输出大小。
2
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
初始化权重,将各个权重和偏置的值保存为字典并为各权重赋值为随机正态 * weight_init_std,将偏置初始值设为0
3
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
搭建网络结构并将网络保存为OrderedDict。
网络的结构:
卷积层–ReLU–池化–Affine(求和)–ReLU–Affine–softmax(输出)
3
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
使用反向传播梯度下降法求各权重和偏置的梯度,其实现过程和全连接网络一致。
训练网络
# coding: utf-8
import sys, os
sys.path.append('D:\AI learning source code') # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from simple_convnet import SimpleConvNet
from common.trainer import Trainer
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
# 处理花费时间较长的情况下减少数据
x_train, t_train = x_train[:5000], t_train[:5000]
#x_test, t_test = x_test[:1000], t_test[:1000]
max_epochs = 20
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# 保存参数
network.save_params("params.pkl")
print("Saved Network Parameters!")
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, trainer.train_acc_list, marker='o', label='train', markevery=2)
plt.plot(x, trainer.test_acc_list, marker='s', label='test', markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
跑完5000次训练后得到的预测准确度图象:
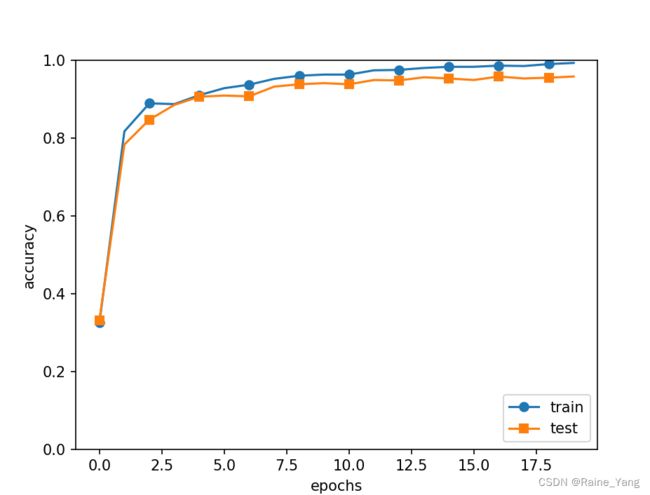
可以看到卷积神经网络对图像识别问题可以达到的准确度远远强于普通的全连接网络。在最后可以达到几乎98%左右的预测准确度
CNN可视化
在下面程序中,我们使用30个5 X 5,通道为1的卷积核对灰度图进行检查,并将学习前和学习后的各个卷积核权重进行可视化
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from simple_convnet import SimpleConvNet
def filter_show(filters, nx=8, margin=3, scale=10):
"""
c.f. https://gist.github.com/aidiary/07d530d5e08011832b12#file-draw_weight-py
"""
FN, C, FH, FW = filters.shape
ny = int(np.ceil(FN / nx))
fig = plt.figure()
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(FN):
ax = fig.add_subplot(ny, nx, i+1, xticks=[], yticks=[])
ax.imshow(filters[i, 0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
network = SimpleConvNet()
# 随机进行初始化后的权重
filter_show(network.params['W1'])
# 学习后的权重
network.load_params("params.pkl")
filter_show(network.params['W1'])
学习前:

学习后:

可以看到,在学习前由于权重初始值为随机生成,卷积核黑白区域随机分别。但在学习后可以看到黑色区域的分别呈现了特定的图样(被称为blob)。
不同图样代表了图像边缘和斑块的特征。水平图样的卷积核会更好提取图像中水平方向的边缘,竖直图样的卷积核提取竖直方向边缘,其他以此类推。
在深度学习中,后面的CNN网络会在第一层CNN得到的基本图样特征进行进一步特征提取,提取的特征会逐渐由局部到整体。

如对于上图8层的AlexNet。第一层神经元会提取边缘和斑块,第3层提取到物体纹理,第5层提取到物体部件,而最后的全连接层会根据物体部件特征进行物体分类
具有代表性的CNN
1 LeNet

LeNet是最早的卷积神经网络,其结构已经已经形成了卷积–池化结构的雏形。不过和现在常用的CNN模型不同的是LeNet使用sigmoid作为激活函数(现在多用ReLU),并且LeNet使用subsampling缩小中间数据大小,而现在CNN一般使用Max Pooling
AlexNet

相比于LeNet,AlexNet基本网络结构相同,但有以下差异:
使用ReLU作为激活函数
使用局部正规化的LRN层
使用Dropout