自然语言处理(四): Part of Speech Tagging
目录
1. What is Part of Speech (POS)? 词性是什么
2. Information Extraction 信息提取
2.1 POS Open Classes
2.2 POS Closed Classes (English)
2.3 Ambiguity
2.4 POS Ambiguity in News Headlines
3. Tagsets
3.1 Major Penn Treebank Tags
3.2 Derived Tags (Open Class)
3.3 Derived Tags (Closed Class)
3.4 Tagged Text Example
4. Automatic Tagging
4.1 Why Automatically POS tag?
4.2 Automatic Taggers
4.3 Rule-based tagging
4.4 Unigram tagger
4.5 Classifier-Based Tagging
4.6 Hidden Markov Models
4.7 Unknown Words
4.8 A Final Word
1. What is Part of Speech (POS)? 词性是什么
AKA word classes, morphological classes, syntactic categories 又名词类,形态词,句法类
Nouns, verbs, adjective, etc
POS tells us quite a bit about a word and its neighbours POS告诉我们关于一个词和它的邻居的相当多的信息:
- nouns are often preceded by determiners 名词前面经常有定语从句
- verbs preceded by nouns 动词前面是名词
- content as a noun pronounced as CONtent content作为名词读作CONtent
- content as a adjective pronounced as conTENT content作为形容词读作conTENT
2. Information Extraction 信息提取
Given this:
- “Brasilia, the Brazilian capital, was founded in 1960.”
Obtain this:
- capital(Brazil, Brasilia)
- founded(Brasilia, 1960)
Many steps involved but first need to know nouns (Brasilia, capital), adjectives (Brazilian), verbs (founded) and numbers (1960).
2.1 POS Open Classes
Open vs closed classes: how readily do POS categories take on new words? Just a few open classes: 开放类与封闭类:POS类别多容易接受新词?只有几个开放类。
Nouns
- Proper (Australia) versus common (wombat)
- Mass (rice) versus count (bowls)
Verbs
- Rich inflection (go/goes/going/gone/went)
- Auxiliary verbs (be, have, and do in English)
- Transitivity (wait versus hit versus give) — number of arguments
Adjectives
- Gradable (happy) versus non-gradable (computational)
Adverbs
- Manner (slowly)
- Locative (here)
- Degree (really)
- Temporal (today)
2.2 POS Closed Classes (English)
Prepositions (in, on, with, for, of, over,…)
- on the table
Particles
- brushed himself off
Determiners
- Articles (a, an, the)
- Demonstratives (this, that, these, those)
- Quantifiers (each, every, some, two,…)
Pronouns
- Personal (I, me, she,…)
- Possessive (my, our,…)
- Interrogative or Wh (who, what, …)
Conjunctions
- Coordinating (and, or, but)
- Subordinating (if, although, that, …)
Modal verbs
- Ability (can, could)
- Permission (can, may)
- Possibility (may, might, could, will)
- Necessity (must)
And some more…
- negatives, politeness markers, etc
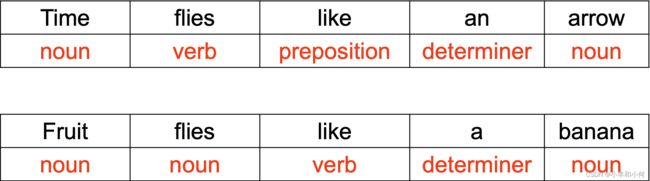
2.3 Ambiguity
Many word types belong to multiple classes
POS depends on context
Compare:
- Time flies like an arrow
- Fruit flies like a banana
2.4 POS Ambiguity in News Headlines
- British Left Waffles on Falkland Islands
- [British Left] [Waffles] [on] [Falkland Islands]
- Juvenile Court to Try Shooting Defendant
- [Juvenile Court] [to] [Try] [Shooting Defendant]
- Teachers Strike Idle Kids
- [Teachers Strike] [Idle Kids]
- Eye Drops Off Shelf
- [Eye Drops] [Off Shelf]
3. Tagsets
A compact representation of POS information
- Usually ≤ 4 capitalized characters (e.g. NN = noun)
- Often includes inflectional distinctions
Major English tagsets
- Brown (87 tags)
- Penn Treebank (45 tags)
- CLAWS/BNC (61 tags)
- “Universal” (12 tags)
At least one tagset for all major languages
3.1 Major Penn Treebank Tags
NN noun
VB verb
JJ adjective
RB adverb
DT determiner
CD cardinal number
IN preposition
PRP personal pronoun
MD modal
CC coordinating conjunction
RP particle
WH wh-pronoun
TO to
3.2 Derived Tags (Open Class)
NN (noun singular, wombat)
- NNS (plural, wombats)
- NNP (proper, Australia)
- NNPS (proper plural, Australians)
VB (verb infinitive, eat)
- VBP (1st /2nd person present, eat)
- VBZ (3rd person singular, eats)
- VBD (past tense, ate)
- VBG (gerund, eating)
- VBN (past participle, eaten)
JJ (adjective, nice)
- JJR (comparative, nicer)
- JJS (superlative, nicest)
RB (adverb, fast)
- RBR (comparative, faster)
- RBS (superlative, fastest)
3.3 Derived Tags (Closed Class)
PRP (pronoun personal, I)
- PRP$ (possessive, my)
WP (Wh-pronoun, what):
- WP$ (possessive, whose)
- WDT(wh-determiner, which)
- WRB (wh-adverb, where)
3.4 Tagged Text Example

4. Automatic Tagging
4.1 Why Automatically POS tag?
Important for morphological analysis, e.g. lemmatisation
For some applications, we want to focus on certain POS
- E.g. nouns are important for information retrieval, adjectives for sentiment analysis
Very useful features for certain classification tasks
- E.g. genre attribution (fiction vs. non-fiction)
POS tags can offer word sense disambiguation
- E.g. cross/NN vs cross/VB cross/JJ
Can use them to create larger structures (parsing; lecture 14–16)
4.2 Automatic Taggers
Rule-based taggers
Statistical taggers
- Unigram tagger
- Classifier-based taggers
- Hidden Markov Model (HMM) taggers
4.3 Rule-based tagging
Typically starts with a list of possible tags for each word
- From a lexical resource, or a corpus
Often includes other lexical information, e.g. verb subcategorisation (its arguments)
Apply rules to narrow down to a single tag
- E.g. If DT comes before word, then eliminate VB
- Relies on some unambiguous contexts
Large systems have 1000s of constraints
4.4 Unigram tagger
Assign most common tag to each word type
Requires a corpus of tagged words
“Model” is just a look-up table
But actually quite good, ~90% accuracy
- Correctly resolves about 75% of ambiguity
Often considered the baseline for more complex approaches
4.5 Classifier-Based Tagging
Use a standard discriminative classifier (e.g. logistic regression, neural network), with features:
- Target word
- Lexical context around the word
- Already classified tags in sentence
But can suffer from error propagation: wrong predictions from previous steps affect the next ones

4.6 Hidden Markov Models
A basic sequential (or structured) model
Like sequential classifiers, use both previous tag and lexical evidence
Unlike classifiers, considers all possibilities of previous tag
Unlike classifiers, treat previous tag evidence and lexical evidence as independent from each other
- Less sparsity
- Fast algorithms for sequential prediction, i.e. finding the best tagging of entire word sequence
Next lecture!
4.7 Unknown Words
Huge problem in morphologically rich languages (e.g. Turkish)
Can use things we’ve seen only once (hapax legomena) to best guess for things we’ve never seen before
- Tend to be nouns, followed by verbs
- Unlikely to be determiners
Can use sub-word representations to capture morphology (look for common affixes)
4.8 A Final Word
- Part of speech is a fundamental intersection between linguistics and automatic text analysis 语音部分是语言学和自动文本分析之间的一个基本交叉点
- A fundamental task in NLP, provides useful information for many other applications NLP的一项基本任务,为许多其他应用提供有用的信息
- Methods applied to it are typical of language tasks in general, e.g. probabilistic, sequential machine learning 应用于它的方法是一般语言任务的典型,例如概率、顺序机器学习