二、 FATE实战:实现横向逻辑回归任务的训练及预测
文章目录
- 前言
- 一、数据集描述
-
- 1. 数据描述
- 2. 逻辑回归模型
- 二、FATE单机版部署
-
- 1.安装centos7
- 2. 安装Docker
- 3. FATE-standalone部署
- 三、FATE实现横向横向逻辑回归
-
- 1. 上传数据
- 2. 训练任务
- 3. 任务预测
- 4. fate dsl_conf v2版本的训练和预测流程
-
- 4.1 上传数据和任务训练
- 4.2 配置预测dsl
- 4.3 任务预测
- 总结
前言
本章节利用FATE构建了一个简单的横向逻辑回归模型。本章实验运行在FATE单机环境下,可以点击链接直达FATE官方github相关网页。
进行本章节的实验要先在CENTOS7下安装FATE单机版,本文就安装流程以及安装中遇到的问题进行了简单概括。
一、数据集描述
1. 数据描述
本章节使用威斯康辛州临床科学中心开源的乳腺癌肿瘤数据集。该数据集内置在sklearn库,首先在notebook中观察数据描述:
# 导入威斯康辛州临床科学中心开源的乳腺癌肿瘤数据集
from sklearn.datasets import load_breast_cancer
import pandas as pd
breast_dataset = load_breast_cancer()
breast = pd.DataFrame(breast_dataset.data, columns=breast_dataset.feature_names)
breast['y'] = breast_dataset.target
breast.head()
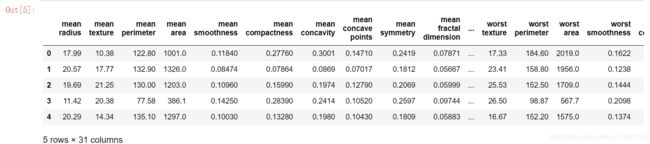
breast.info()
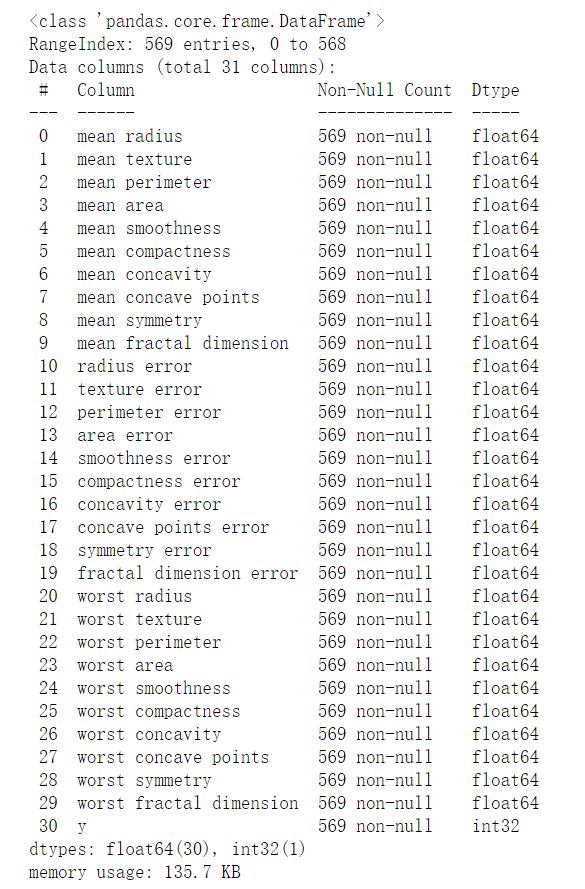
可以观察到该数据集一共有30个数据特征,仔细观察后发现其实只有十个属性,每个属性都统计了均值(mean)、标准差(std error)以及最差值(worst)。本数据集一共有569个样本,标签的意义是肿瘤是否是良性肿瘤,是标签为1,否标签为0。根据数据的统计信息,在569个样本中,良性肿瘤样本有357个,恶性肿瘤样本212个。
2. 逻辑回归模型
很明显这是一个二分类的模型训练问题,即对良恶性肿瘤进行分类。很容易就想到Logistic回归模型,下面我们对洛基回归进行一个简单的回顾。
逻辑回归模型是目前最常用的二分类模型,属于广义线性模型。线性回归模型的定义:
y = W T X + b , y = W^{T}X + b, y=WTX+b,
但是上式得到的y是个连续值,我们要对它施加一个函数将值映射成0或者1:
y = f ( W T X + b ) , y = f(W^{T}X + b), y=f(WTX+b),
逻辑回归中使用sigmoid函数做非线性映射:
f ( z ) = 1 1 + e − z , f(z)= \frac{1}{1+e^{-z}}, f(z)=1+e−z1,
图像如下:
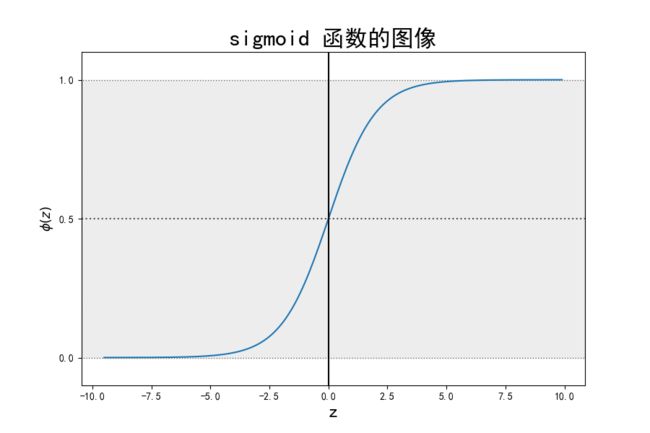
逻辑回归进行预测时,当预测值 W T X + b ≥ 0 W^{T}X + b\geq0 WTX+b≥0时,预测为正例输出1,否则预测为负例输出0。
二、FATE单机版部署
1.安装centos7
fate单机版部署的文档见链接单机部署。
推荐虚拟机安装,配置好GNOME桌面,硬盘分配最好大一点100G足够。
2. 安装Docker
官方docker建议版本为18.09,您可以使用以下命令验证docker环境:docker --version。
在未安装过docker的centos7上安装docker执行下列命令即可:
# 安装docker:
# 安装依赖
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加库
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 安装特定版本:
yum install -y docker-ce-18.09.0 docker-ce-cli-18.09.0 containerd.io
# 开启服务和开机自启动
systemctl start docker
systemctl enable docker
如果之前安装过docker,需要进行卸载和重装,参考下面链接:
https://www.cnblogs.com/qkstart/p/10973445.html
3. FATE-standalone部署
在此教程中使用的版本是fate1.6.0。官方给出最新的环境配置版本如下:
FATE=1.6.0
FATEBoard=1.6.0
EGGROLL=2.2.1
CENTOS=7.2
UBUNTU=16.04
PYTHON=3.6.5
MAVEN=3.6.3
JDK=8
SPARK=2.4.1
在centos命令行执行下列命令进行部署:
#获取安装包
wget https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/docker_standalone_fate_1.6.0.tar.gz
tar -xzvf docker_standalone_fate_1.6.0.tar.gz
#执行部署
cd docker_standalone_fate_1.6.0
bash install_standalone_docker.sh
对安装的版本进行测试,在本地命令行执行:(注意测试还有下面的实验都是在fate容器里执行的,而不是在本地目录下执行!)
# 单元测试
CONTAINER_ID=`docker ps -aqf "name=fate"`
docker exec -t -i ${CONTAINER_ID} bash
bash ./python/federatedml/test/run_test.sh
如果成功,屏幕显示类似下方的语句:
there are 0 failed test
# Toy测试
CONTAINER_ID=`docker ps -aqf "name=fate"`
docker exec -t -i ${CONTAINER_ID} bash
python ./examples/toy_example/run_toy_example.py 10000 10000 0
如果成功,屏幕显示类似下方的语句:
success to calculate secure_sum, it is 2000.0
三、FATE实现横向横向逻辑回归
首先要注意如果未特别说明在本地执行,以下命令大多数都是在fate容器中执行的。 我在做实验时因为对docker不熟悉,在本地运行命令浪费了很多时间。
首先给出一些基本的docker命令:
docker images # 显示镜像
docker ps -a #查看当前系统中容器的列表。
docker ps -l #会列出最后一次运行的容器,包括正在运行和已经停止的。
docker start #启动一个或多个已经被停止的容器
docker stop #停止一个运行中的容器
docker rm #删除一个或多个容器
docker exec #在运行的容器中执行命令
docker restart #重启容器
docker stop [容器名称/容器ID] #停止容器运行
在本地root命令行执行命令docker exec -it fate /bin/bash进入fate容器。
1. 上传数据
对于FATE训练任务流程主要有:
- 上传数据
- 配置dsl以及runtime_conf文件
- 训练模型或者继续进行预测
- FATE Board查看结果
每一步在fate容器中使用的命令建议查看fate官方文档,具体链接为:https://github.com/FederatedAI/FATE/blob/master/examples/dsl/v1/README.rst
我们直接使用Fate提供的案例数据,目录在fate容器中/fate/examples/dsl/v1/homo_logistic_regression/upload_data_host.json和/fate/examples/dsl/v1/homo_logistic_regression/upload_data_guest.json。
这里上传数据需要准备host以及guest两方的上传数据
根据官方解释在Fate的概念中分成3种角色,Guest、Host、Arbiter
Guest表示数据应用方,Host是数据提供方,在纵向算法中,Guest往往是有标签y的一方。
arbiter是用来辅助多方完成联合建模的,主要的作用是用来聚合梯度或者模型,
比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等,
arbiter还参与以及分发公私钥,进行加解密服务等等。一般是由数据应用方Guest发起建模流程。
下面要编写上传数据的配置文件upload_data_host.json和upload_data_guest.json。docker中是没有任何编辑器的,当然你可以复制到本地在本地改完配置文件后再复制回容器。推荐在docker中安装vim直接修改文件。
安装vim流程如下:
# 配置国内镜像源
# 实际在使用过程中,运行 apt-get update,然后执行 apt-get install -y vim,下载地址由于是海外地址,下载速度异常慢而且可能中断更新流程,所以做下面配置:
# 更换国内源
mv /etc/apt/sources.list /etc/apt/sources.list.bak
echo "deb http://mirrors.163.com/debian/ jessie main non-free contrib" >> /etc/apt/sources.list
echo "deb http://mirrors.163.com/debian/ jessie-proposed-updates main non-free contrib" >>/etc/apt/sources.list
echo "deb-src http://mirrors.163.com/debian/ jessie main non-free contrib" >>/etc/apt/sources.list
echo "deb-src http://mirrors.163.com/debian/ jessie-proposed-updates main non-free contrib" >>/etc/apt/sources.list
#更新安装源
apt-get update
#安装vim
apt-get install -y vim
#安装时若报错:vim : Depends: libtinfo5 (>= 6) but it is not going to be installed依赖库版本过低导致,先安装依赖
#安装依赖
apt-get install -y libtinfo5 --allow-remove-essential
然后再安装vim
apt-get install -y vim
使用vim修改/fate/examples/dsl/v1/homo_logistic_regression/upload_data_host.json为(也可以不做修改,在这里笔者仅仅修改了partition为10,如作修改做好原文件备份或者直接查看fate github中相应的原文件):
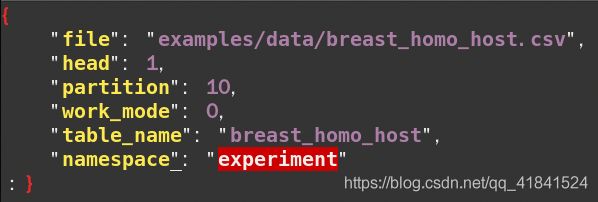
vim修改/fate/examples/dsl/v1/homo_logistic_regression/upload_data_guest.json为:
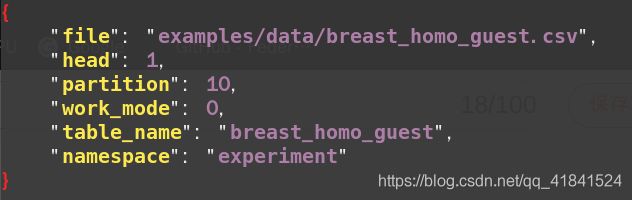
字段说明:
file: 文件路径
head: 指定数据文件是否包含表头
partition: 指定用于存储数据的分区数
work_mode: 指定工作模式,0代表单机版,1代表集群版
table_name&namespace: 存储数据表的标识符号
上传数据的标准命令为:
python ${your_install_path}/fate_flow/fate_flow_client.py -f upload -c ${upload_data_json_path}
${your_install_path}: fate的安装目录
${upload_data_json_path}:上传数据配置文件路径
由于我们前面已经进入fate容器,直接在容器fate目录下执行下列命令:
python python/fate_flow/fate_flow_client.py -f upload -c examples/dsl/v1/homo_logistic_regression/upload_data_host.json
python python/fate_flow/fate_flow_client.py -f upload -c examples/dsl/v1/homo_logistic_regression/upload_data_guest.json
# 下面这条upload_data_test.json 是上传测试数据,仅仅在作evaluation时需要上传,执行普通的train_job可以不用上传
python python/fate_flow/fate_flow_client.py -f upload -c examples/dsl/v1/homo_logistic_regression/upload_data_test.json
返回下面信息说明上传成功:
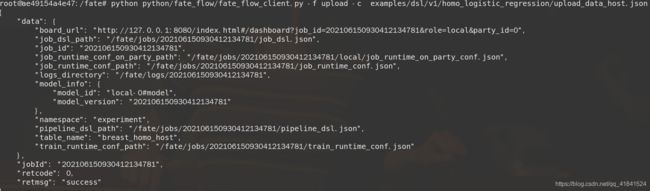
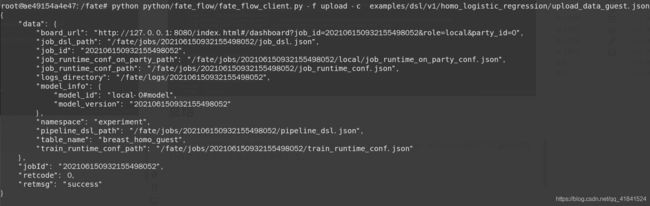
打开fate监控面板fate_boardhttp://127.0.0.1:8080,127.0.0.1换成自己虚拟机本地ip。
根据上传完之后的job_id查询得,刚刚上传的两个任务

点击可以看见参数配置等信息。
2. 训练任务
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的域特定语言 (DSL) 来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
借助FATE,我们可以使用组件的方式来构建联邦学习,而不需要用户从新开始编码,FATE构建联邦学习Pipeline是通过自定义dsl和conf两个配置文件来实现,dsl以及conf具体描述请见FATE使用官方示例文档:
- dsl文件:用来描述任务模块,将任务模块以有向无环图(DAG)的形式组合在一起。
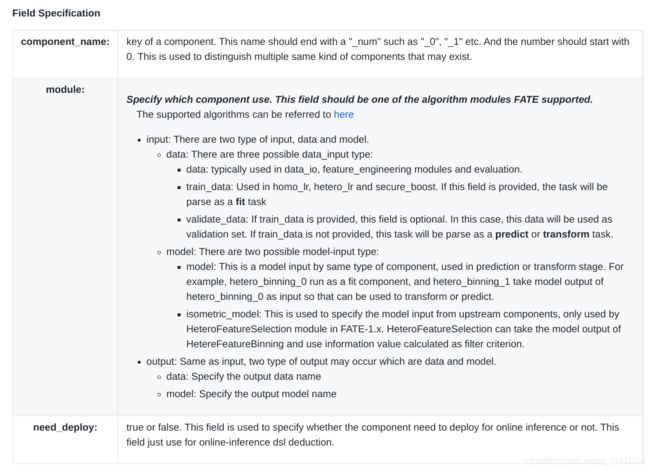
- conf文件:设置各个组件的参数,比如输入模块的数据表名;算法模块的学习率、batch大小、迭代次数等。

在容器中可以修改我们逻辑回归的dsl和conf文件,目录分别为:/fate/examples/dsl/v1/homo_logistic_regression/test_homolr_train_job_conf.json和/fate/examples/dsl/v1/homo_logistic_regression/test_homolr_train_job_dsl.json。此处直接使用原文件的示例文件即可,笔者未作修改,要注意的是conf文件中data中的name和namespace要与上传数据upload_data.conf中定义的一致。

- 训练模型
执行训练的命令如下:
python $fate_dir/fate_flow/fate_flow_client.py -f submit_job -d test_homolr_train_job_dsl.json -c test_homolr_train_job_conf.json
将路径替换成fate容器中的路径,在fate目录下执行下列命令开始训练:
python python/fate_flow/fate_flow_client.py -f submit_job -d examples/dsl/v1/homo_logistic_regression/test_homolr_train_job_dsl.json -c examples/dsl/v1/homo_logistic_regression/test_homolr_train_job_conf.json
返回下列信息则成功:
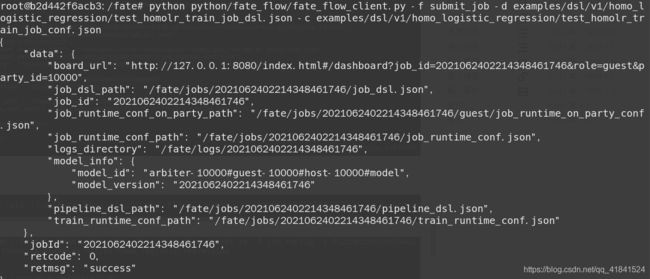
这里值得注意的是fate容器中有大量的示例供你选择,包括提供了测试验证、cv交叉验证等模式的dsl以及conf文件,当然你也可以在示例上进行修改达到自己的实验要求,相对来说DSL中每个模块的组合是较为灵活的。详情可以参考横向逻辑回归示例文件说明:

其中含有test功能的任务需要提前上传test_data文件,操作同上述上传数据的命令。含有验证evaluate功能的任务dsl和conf文件不能直接进行下一步的预测,因为本身的验证过程中就已经进行了预测和检验,需要对组建进行进一步修改并对预测conf做好配置。这样才可以使用我们训练好的模型去做预测。建议精读fate文档,有一些比较小的点容易忽略。
- 查看训练结果
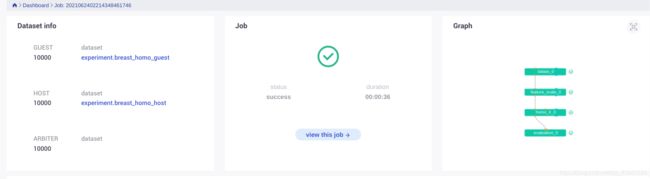
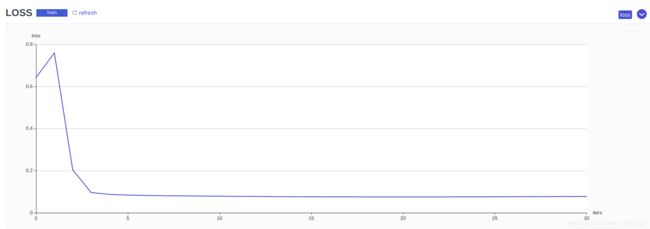
在homo_lr_0的组件中我们可以很清楚的看见loss的曲线图:
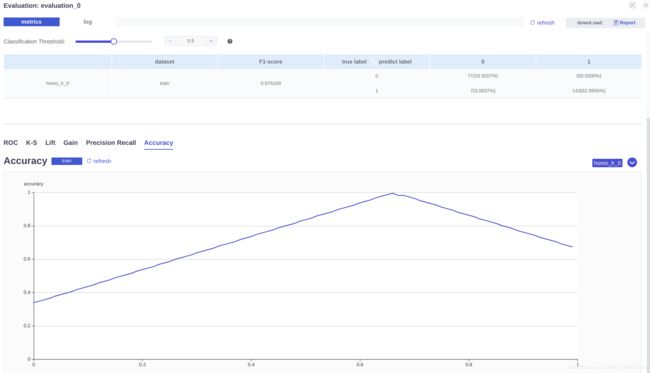
在evaluation_0组件中可以看到更多的模型评价参数:
3. 任务预测
下面我们将用上面训练得到的模型来进行数据的预测。预测的配置文件为examples/dsl/v1/homo_logistic_regression/test_predict_conf.json,在dsl/v2的版本中预测任务需要同时定义预测的dsl和conf文件,而v1中只需要定义conf,dsl文件和训练的dsl文件相同。
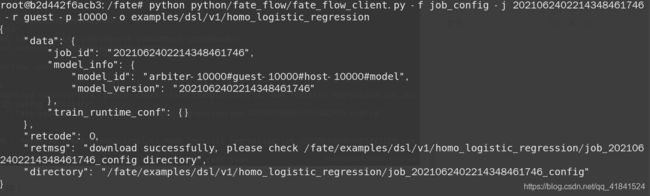
预测的配置文件中需要修改model_id以及model_version,这两个参数在训练任务结束时返回的信息中已经包含。当然你也可以使用下列命令来获得两个参数:
python python/fate_flow/fate_flow_client.py -f job_config -j 202106160854555482725 -r guest -p 10000 -o examples/dsl/v1/homo_logistic_regression
上述命令中-j后面加训练任务的job_id,guest -p后加guest的party号,-o后面加保存路径。
- 修改预测配置文件
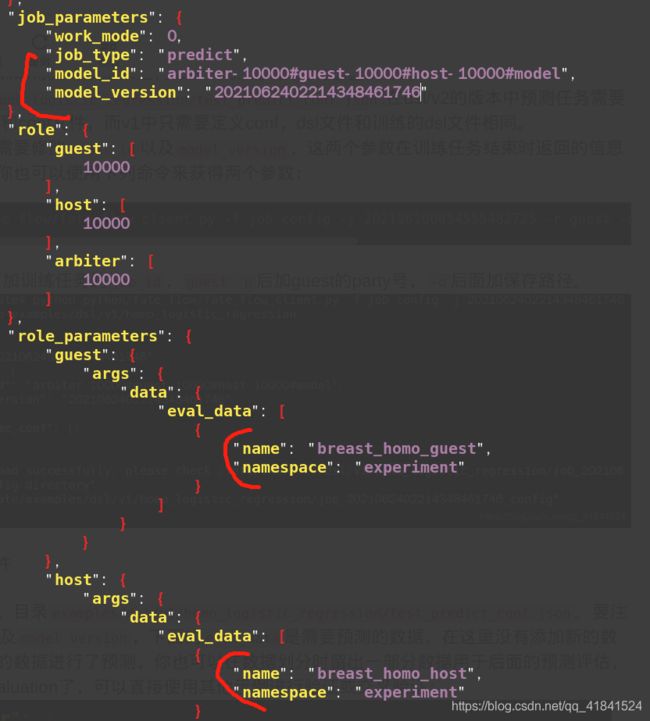
修改预测配置文件,目录examples/dsl/v1/homo_logistic_regression/test_predict_conf.json。要注意修改model_id以及model_version,下面的eval_data是需要预测的数据,在这里没有添加新的数据,直接使用原来的数据进行了预测,你也可以在数据划分时留出一部分数据用于后面的预测评估,当然这就相当于evaluation了,可以直接使用其他示例进行验证或交叉验证:
- 执行预测
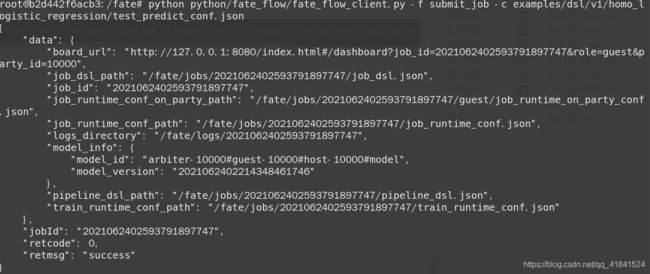
在fate容器中直接执行预测命令:
python python/fate_flow/fate_flow_client.py -f submit_job -c examples/dsl/v1/homo_logistic_regression/test_predict_conf.json
返回下列信息,下面我们到fate board查看结果。
- 查看结果
我们直接查看homo_lr_0的输出即可:
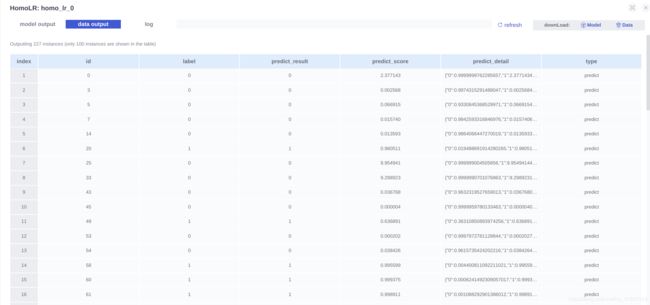
在board中只能看到前100条记录,如果需要全部数据,可以用下列命令下载:
python python/fate_flow/fate_flow_client.py -f component_output_data -j 2021062308372668986321 -p 10000 -r guest -cpn hetero_lr_0 -o ./
官方给出的下载数据命令格式:
python ${your_fate_install_path}/fate_flow/fate_flow_client.py -f component_output_data -j ${job_id} -p ${party_id} -r ${role} -cpn ${component_name} -o ${predict_result_output_dir}
参数说明:
${job_id}: predict task's job_id
${party_id}: the partyid of current user.
${role}: the role of current user. Please keep in mind that host users are not supposed to get predict results in heterogeneous algorithm.
${component_name}: the component who has predict results
${predict_result_output_dir}: the directory which use download the predict result to.
4. fate dsl_conf v2版本的训练和预测流程
在上面的训练和预测过程中,使用的是fate dsl_conf的v1版本,具体文档见v1。而后面fate又推出了dsl_conf的v2版本,具体文档见v2。

v2版本里有一些改变和提升,最直观的来说,在v1中预测任务的dsl文件是自动生成的,难免会出现一定的问题。而v2中是需要用户自己定义预测任务dsl的,当然也可以使用flow命令来自动配置出预测dsl。下面简单介绍一下v2版本任务训练和预测的流程。
建议在容器中部署单机fate时,在容器内安装交互工具FATE-Client以及测试工具FATE-Test:
直接在容器内部执行:
pip install fate-client
pip install fate-test
fate-client需要进行初始化配置:
# configure values in conf/service_conf.yaml
flow init -c /data/projects/fate/conf/service_conf.yaml
# alternatively, input real ip address and port info to initialize cli
flow init --ip 127.0.0.1 --port 9380
配置好之后就可以愉快的使用flow命令啦,flow命令官方文档:
https://github.com/FederatedAI/FATE/blob/master/python/fate_client/flow_client/README_zh.rst
下面的操作使用flow命令进行操作,都是对examples/dsl/v2/homo_logistic_regression中的文件进行演示。
4.1 上传数据和任务训练
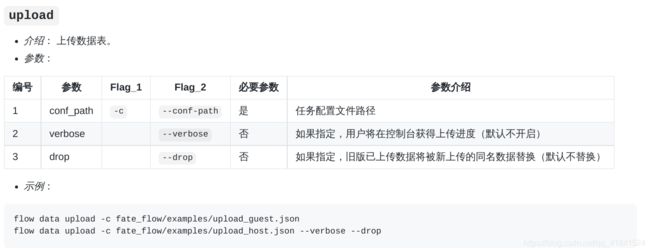
# 上传数据仍然用1中的upload_data_host.json和upload_data_guest.json
flow data upload -c examples/dsl/v1/upload_data_host.json
flow data upload -c examples/dsl/v1/upload_data_guest.json
在v2文件夹下选择示例dsl和conf进行训练:
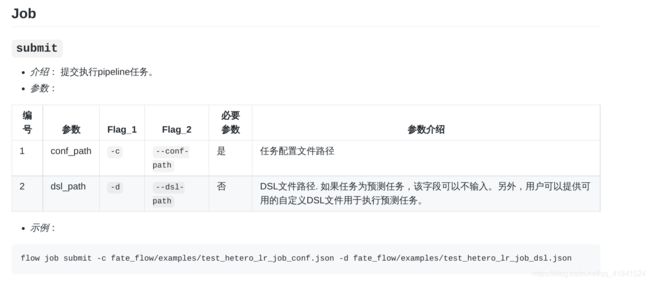
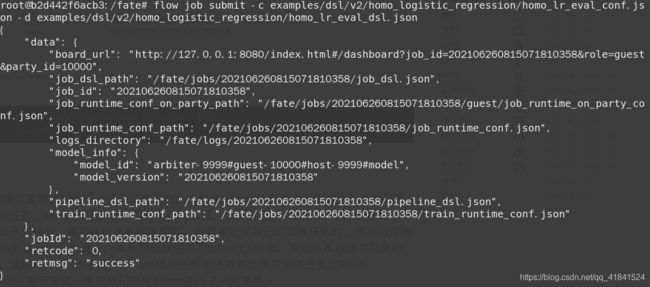
flow job submit -c examples/dsl/v2/homo_logistic_regression/homo_lr_eval_conf.json -d examples/dsl/v2/homo_logistic_regression/homo_lr_eval_dsl.json
返回信息:
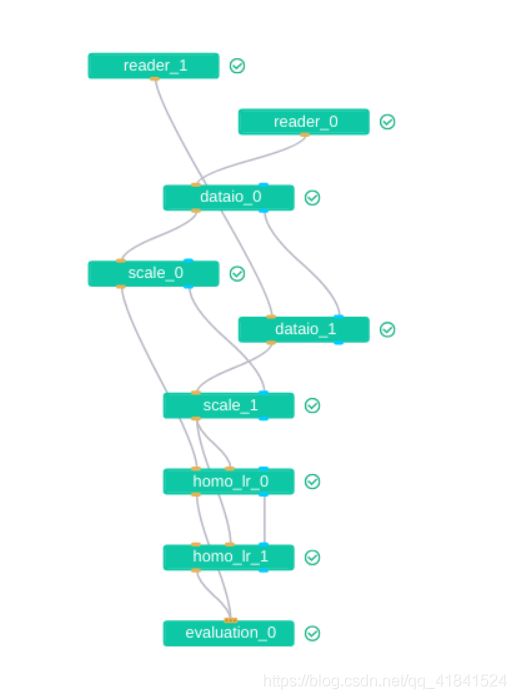
fate board中guest的DAG图:
4.2 配置预测dsl
划重点:v2中训练好的任务需要进行部署才能用于下一步的预测任务
部署命令:
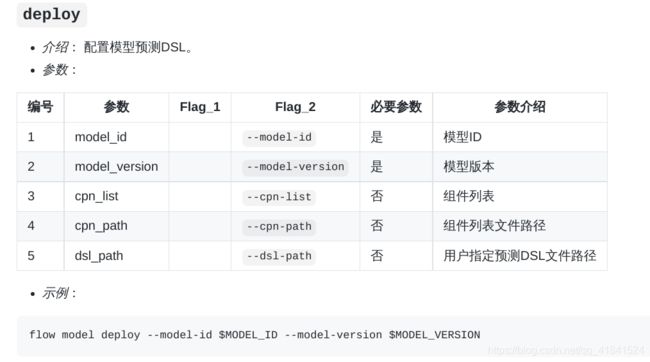
我们将model_id和model_version更换成上面训练好的模型参数然后进行部署:
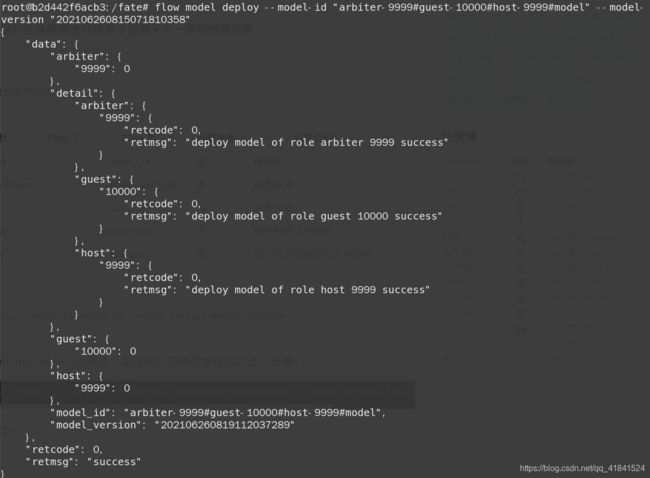
flow model deploy --model-id "arbiter-9999#guest-10000#host-9999#model" --model-version "202106260815071810358"
返回信息则配置成功:
我们可以通过下列命令得到预测的dsl和conf文件,注意这里我们用的model_version是上面部署之后的model_version
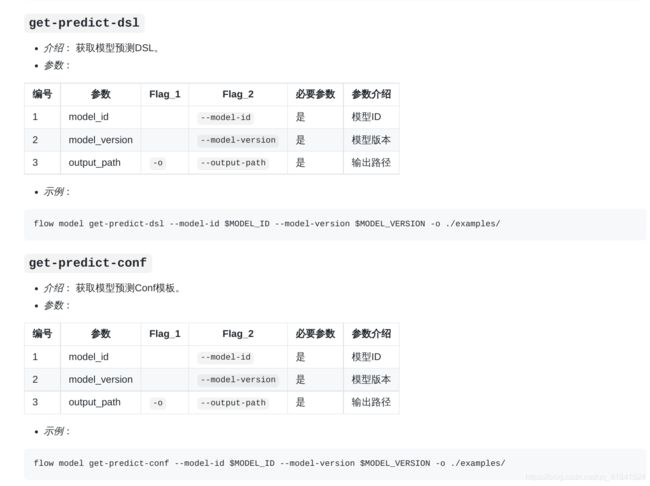
# 获取dsl
flow model get-predict-dsl --model-id "arbiter-9999#guest-10000#host-9999#model" --model-version "202106260819112037289" -o examples/dsl/v2/homo_logistic_regression/
# 获取conf
flow model get-predict-conf --model-id "arbiter-9999#guest-10000#host-9999#model" --model-version "202106260819112037289" -o examples/dsl/v2/homo_logistic_regression/
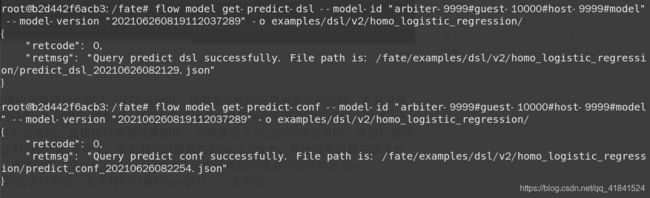
4.3 任务预测
从上面得到conf后我们需要修改里面的数据表和namespace,修改为下图:
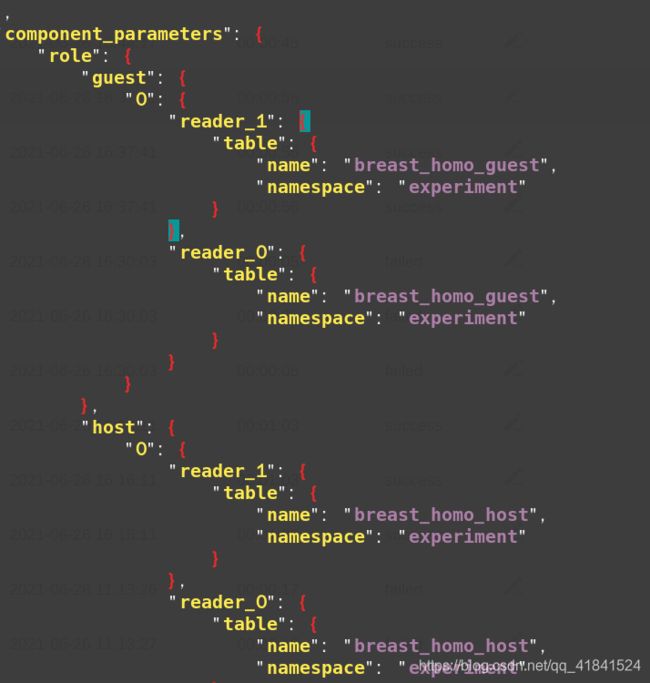
使用我们上面获取到的预测dsl和conf进行预测:
flow job submit -c examples/dsl/v2/homo_logistic_regression/predict_conf_20210626082254.json -d examples/dsl/v2/homo_logistic_regression/predict_dsl_20210626082129.json
fateboard结果和训练任务类似,可以使用数据下载命令下载数据到本地。以上为v2版本任务训练和预测的示例,当然也可以把数据换成其他切分数据进行训练和预测,不再赘述。
总结
本章节对FATE中的横向逻辑回归代码进行了简单示例,当然官方代码还有很多示例文件,本文只是最简单的训练和预测任务。fate横向逻辑回归中还有测试验证、交叉验证等示例代码可以去尝试。一般来说示例文件可以不加修改,直接执行查看结果即可,当需要定义自己的训练任务时,再进行修改dsl文件和conf文件达到自己的配置要求。本系列实战使用的为fate1.6版本,其他版本容器中目录的结构或许存在不同,请核对对应文件的目录。fate横向任务中还有其他很多训练任务比如nn、secureboost等,都可以进行尝试,本次我们只是对fate进行了一定熟悉。
网上有很多实战教程,可能由于版本原因或者其他原因读起来有些晦涩,建议大家直接阅读官方文档。本教程也仅仅时记录了本人的操作经验,不足之处各位海涵~
