Transformer详解笔记
Transformer
Transformer是在一篇名为《Attention Is All You Need》的文章中提出的,采用了encoder-decoder架构,抛弃了传统的CNN和RNN,整个网络结构完全由Attention构成,使用到了self-attention,因此首先先了解一下self-attention,然后再去看Transformer的结构。文章的主要内容为台大李宏毅老师的机器学习课的笔记,老师将的十分细致并描述了很多应用案例,同时这篇博文将的也十分细致,图文并茂http://jalammar.github.io/illustrated-transformer/,如果英文阅读有苦难,也可阅读知乎的这篇文章https://zhuanlan.zhihu.com/p/48508221
文章目录
- Transformer
-
- Transformer结构
- Self-attention
-
- 矩阵乘法的角度
- Multi-head Self-attention
- Positional Encoding
- Seq2Seq
-
- Encoder
- Decoder
-
- Self-attention到Masked Self-attention
- encoder对decoder的信息传入
- 训练
- 参考
Transformer结构
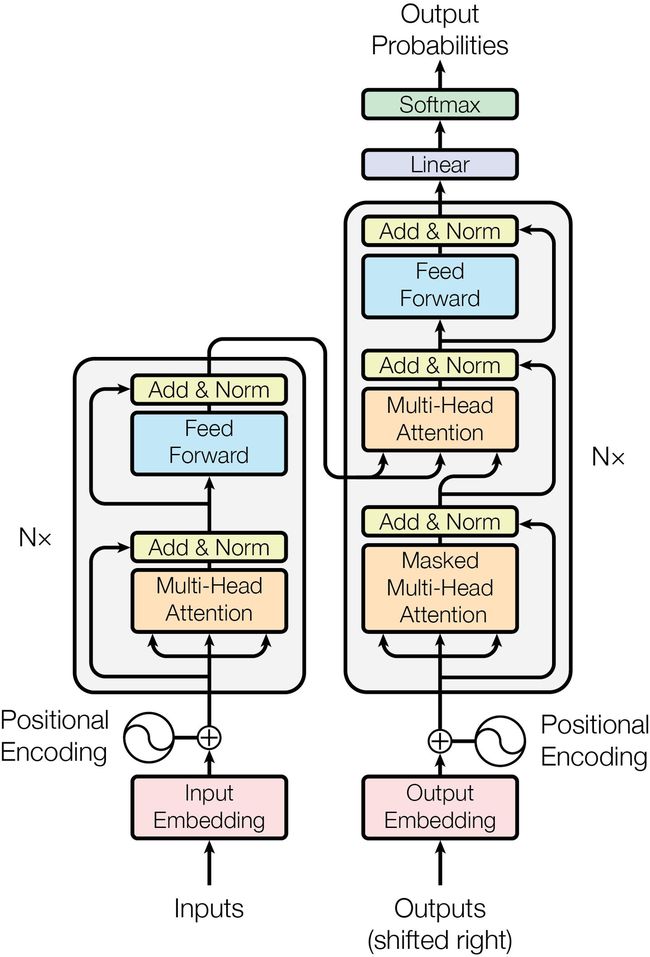
Transformer的结构如下图所示,可以看到几个关键的部分为Multi-Head Attention、Feed Forward、Positional Encoding,Feed Forward我们知道是前馈神经网络,其它内容下文将展开介绍,并且Transorformer使用的是Seq2Seq模型,下文也会有对Seq2Seq的介绍。
Self-attention
在self-attention中,每一个输出 b i b^i bi是考虑了整个输入序列才产生出来的

以 a 1 a^1 a1为标准计算 b 1 b^1 b1为例
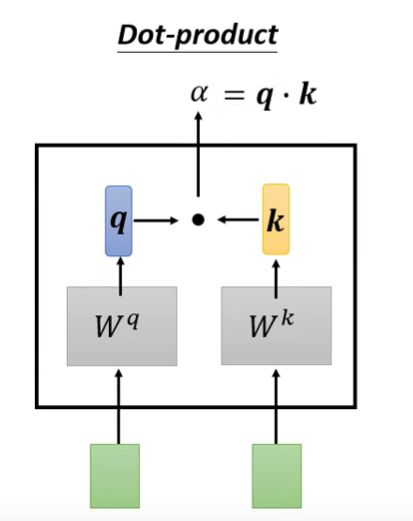
首先找出输入序列中和 a 1 a^1 a1相关的向量,用 α \alpha α表示两个向量的关联程度。

α \alpha α的计算规则:
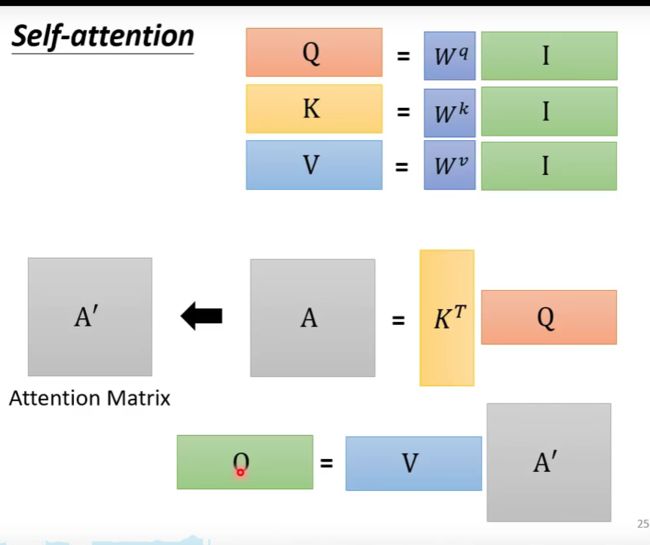
将输入的两个向量分别乘以 W q W^q Wq和 W k W^k Wk,得到 q 、 k q、k q、k两个向量,之后两者做点积,得到 α \alpha α
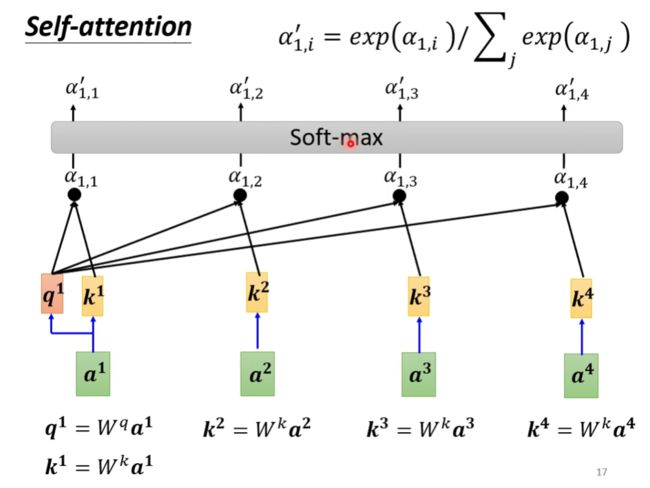
如此,我们由 a 1 a^1 a1求得 q 1 q^1 q1( q = W q a q=W^qa q=Wqa),这里将 q q q称为Query,然后计算出其它所有向量的 k k k( k = W k a k=W^ka k=Wka),这里将 k k k称为Key, q 1 q^1 q1与 a 2 a^2 a2产生的 k 2 k^2 k2求点积得到 α 1 , 2 \alpha_{1,2} α1,2,这个分数称为attention score,一般向量也会与自己计算关联性,因此也要计算 a 1 a^1 a1的 k 1 k^1 k1然后得到 α 1 , 1 \alpha_{1,1} α1,1。
得到关联分数后,做一个softmax
在得到 α ′ \alpha' α′之后,计算所有向量的 v v v( v = W v a v=W^va v=Wva),这里将 v v v称为Value,然后将每个 α 1 , i ′ \alpha'_{1,i} α1,i′与其对应的 v i v_i vi相乘,再将所有相乘的结果加起来,得到 b 1 b^1 b1,如果某一个关联分数比较高,由于softmax后的关联分数是在(0,1)间的,所以其值越靠近1的话,那么 v i v_i vi就会越多的加入到 b 1 b_1 b1中,这有点类似于LSTM的门机制。
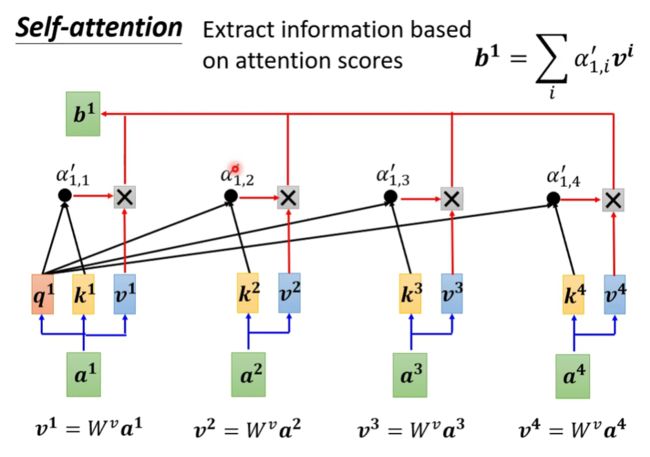
下面我们就可以按照 b 1 b^1 b1的计算方法去计算其他的 b b b值。
下图来源于http://jalammar.github.io/illustrated-transformer/,博主对Transformer将的非常细致,通过这张图我们可以清晰的看出计算过程,防止其结果过大,会除以一个尺度标度 d k \sqrt{d_k} dk,其中 d k d_k dk为一个query和key向量的维度
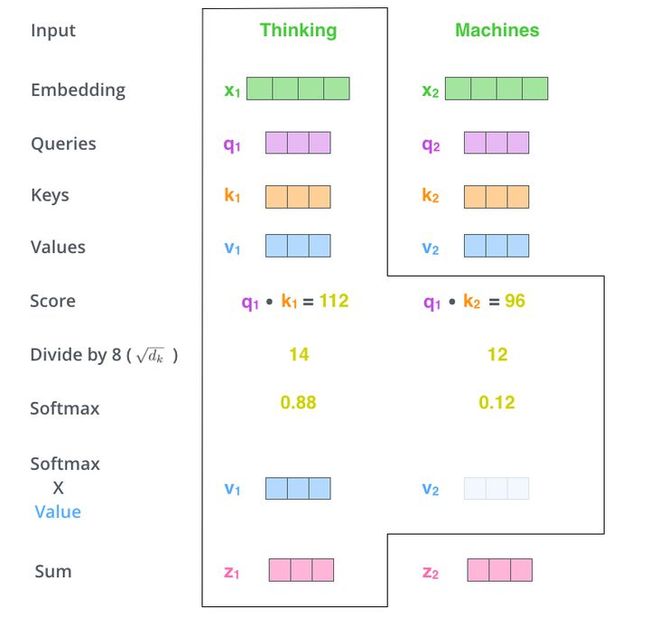
矩阵乘法的角度
由于每一个 a a a都需要计算 q 、 k 、 v q、k、v q、k、v,即形如 q i = W q a i q_i=W^qa^i qi=Wqai,那我们就可以把不同的 a a a拼接起来,看做一个矩阵
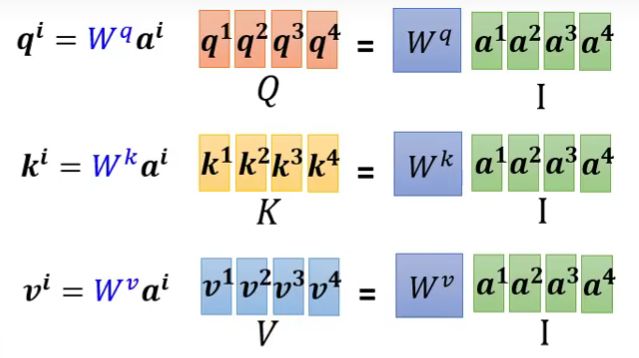
其次是 α = q k \alpha=qk α=qk
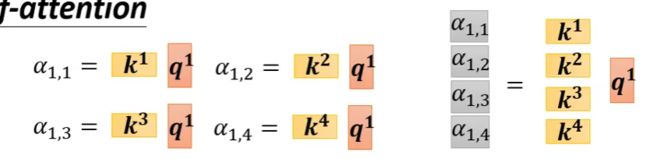
这样某一个向量所对应的关联分数就计算出来了,那么再进一步,我们将 q q q也堆叠
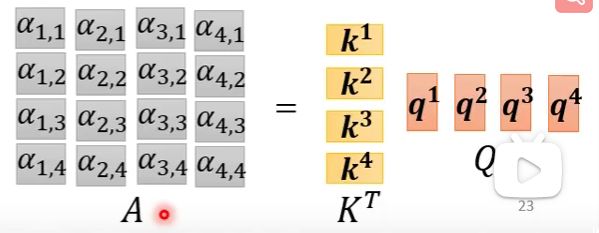
然后做softmax
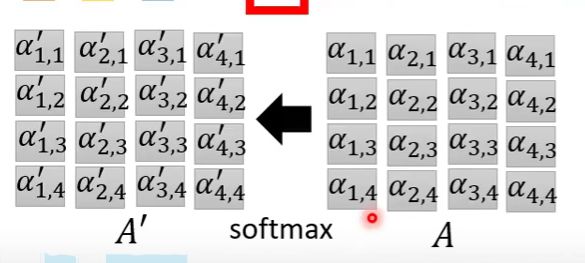
最后计算 b b b
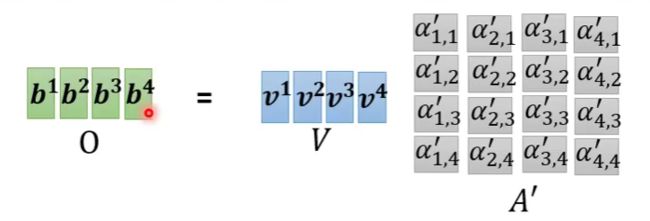
训练过程中需要训练的参数就为 W 1 W k W v W^1 \quad W^k \quad W^v W1WkWv
Multi-head Self-attention
相关有多种不同的形式,不同的定义,我们用 q q q去找 k k k,或许应该有多个不同的方式,不同的 q q q负责不同的相关方式。
由 a a a得到 q q q后, q q q再乘以不同的权值向量得到 q 1 , q 2 , ⋯ q^1,q^2,\cdots q1,q2,⋯,同样的, k k k与 v v v也同样有多个

这样一来如何组合相乘呢?答案就是 q i , 1 q^{i,1} qi,1与 k j , 1 k^{j,1} kj,1相乘, q i , 2 q^{i,2} qi,2与 k j , 2 k^{j,2} kj,2相乘, v v v也是同理。这样就得到了 b i , 1 、 b i , 2 b^{i,1}、b^{i,2} bi,1、bi,2
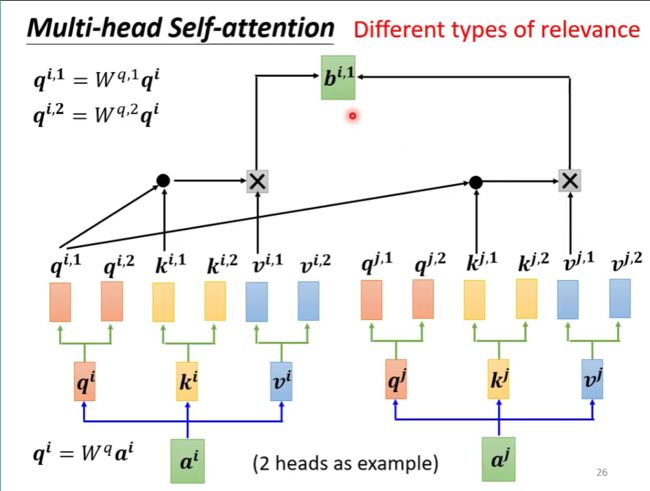
然后堆叠 b i , n b^{i,n} bi,n,乘以权值矩阵,得到 b i b^i bi

Positional Encoding
但是Self-attention遗失了序列中输入的位置信息,因为不管Self-attention的输入如何排列,结果都一样。那么,如果输入的位置信息是重要的,那么将利用Positional Encoding,为Self-attention添加输入的位置信息。
在Positional Encoding中,每一个位置有一个独一无二的位置向量 e i e^i ei,将其加到 a i a^i ai上
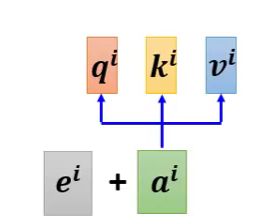
Seq2Seq
seq2seq主要分为两部分,encoder和decoder,encoder处理输入的序列,再把处理好的传给decoder,由它决定输出什么样的序列

Encoder
encoder要完成的是由输入向量序列生成另一向量序列
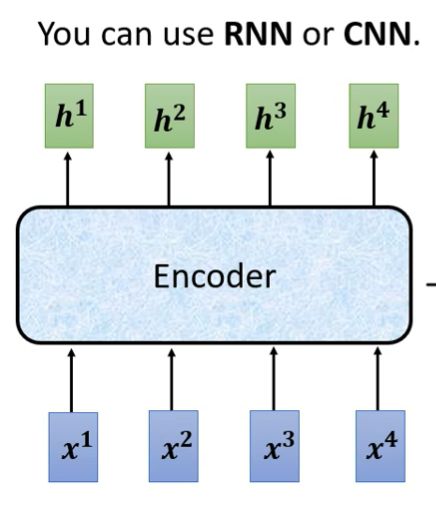
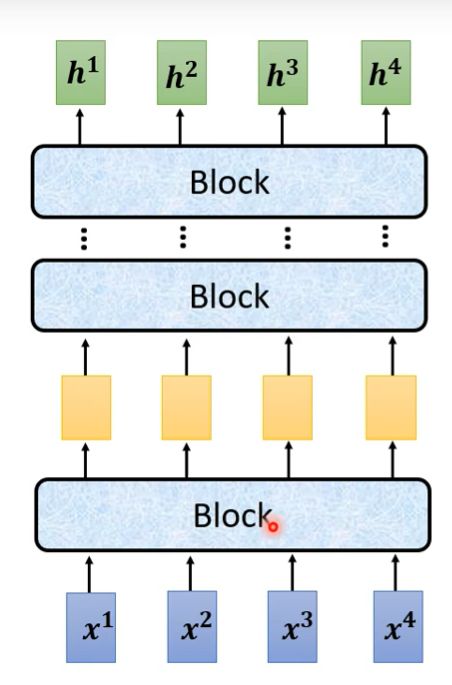
下图为encoder的结构,其内包含了若干个block,不同block的内容不同,可能有一层或多层网络
Decoder
Autoregressive(Speech Recognition as example)
首先给第一个输入的向量特殊的标记token,Begin,经过decoder后输出一个向量,向量为输入的概率向量,概率最大的那个为下一步的输出
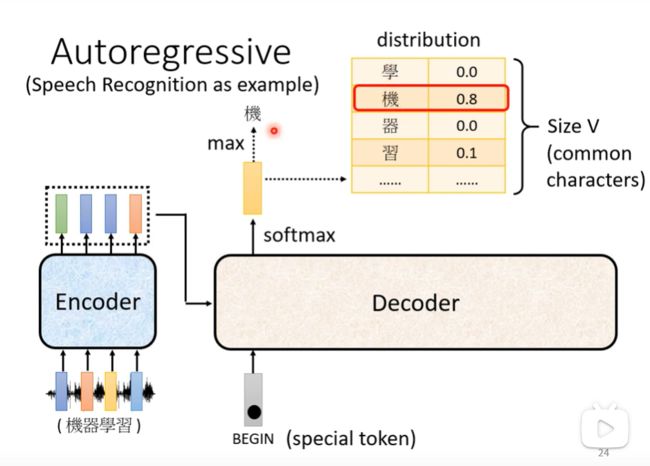
下一步将前一步的输出当做输入,也就是将“机”作为输出传给decoder做下一个输出,之后反复如此。
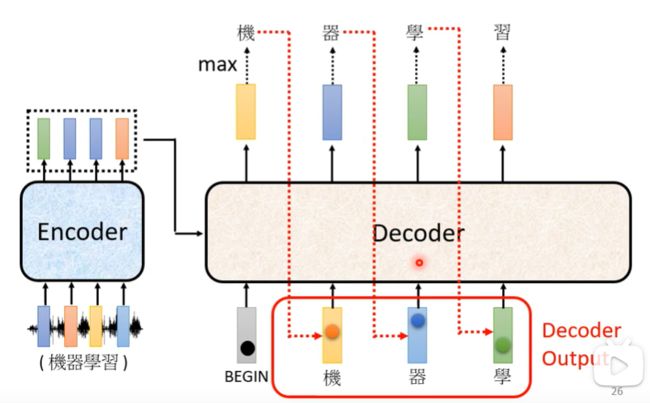
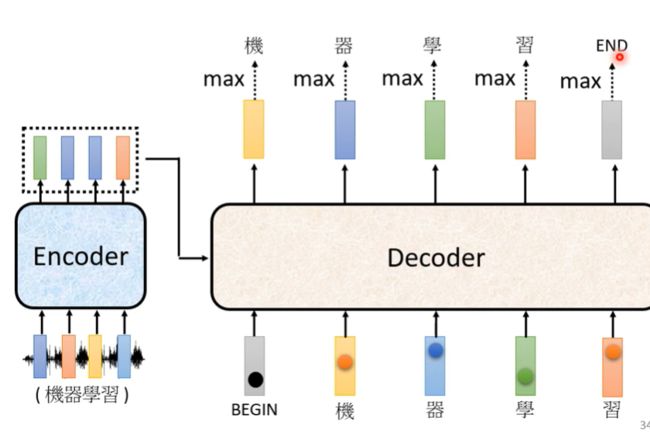
由于decoder不知道合适改停止这种循环,所以我们在distribution表中加入一个END标记

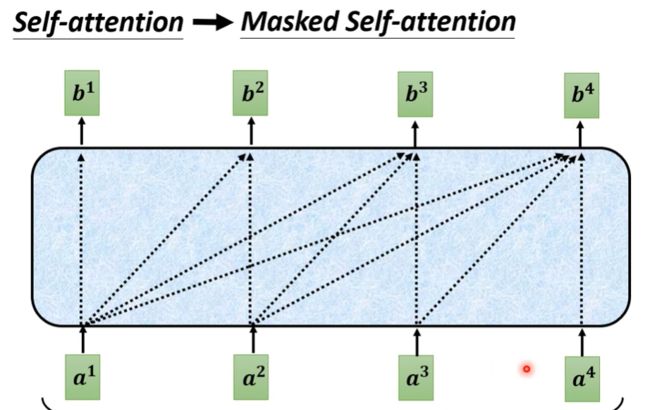
Self-attention到Masked Self-attention
每一个 a i a^i ai 计算 b i b^i bi时只与其前面的 a a a以及自身计算,不考虑后面的
encoder对decoder的信息传入
decoder的输出产生一个 q q q然后去与encoder的输入做一个self-attention计算(无需计算自己的 k k k和 v v v),这个过程称为Cross attention,同时decoder产生的输出之间不需要做self-attention的计算。
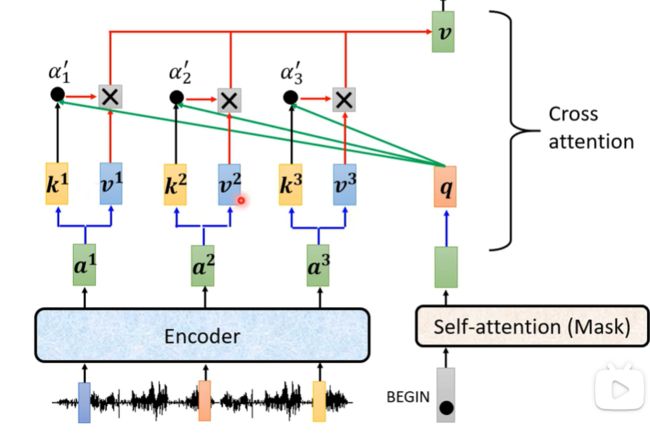
Cross attention指的就是Transformer中红线所框的部分,即Transformer的Encoder向Decoder传输的过程

训练
我们将encoder这里每一个输出做损失函数的计算,类似于分类,将输出与one-hot向量比较。

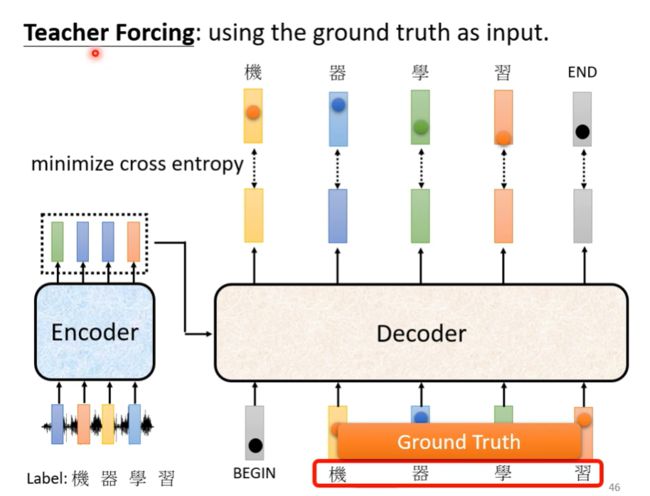
训练是decoder的输出的序列长度是不确定的,在训练时,我们会给decoder的输入以正确答案,这种方法称为Teacher Forcing
参考
https://zhuanlan.zhihu.com/p/47282410
https://zhuanlan.zhihu.com/p/48508221
http://jalammar.github.io/illustrated-transformer/