Co-training with High-Confidence Pseudo Labels for Semi-supervised Medical Image Segmentation-23CVPR

paper:https://arxiv.org/abs/2301.04465
code:https://github.com/Senyh/UCMT
这篇文章是2023的cvpr关于医学图像分割的,用的半监督的方式,最近在工作中也尝试了解半监督,毕竟不仅仅是医学,各种领域的标签都还蛮难弄的,这篇文章正好对应了学校的研究方向,所以赶快分享出来。
ssl-semi supervised leaning 半监督
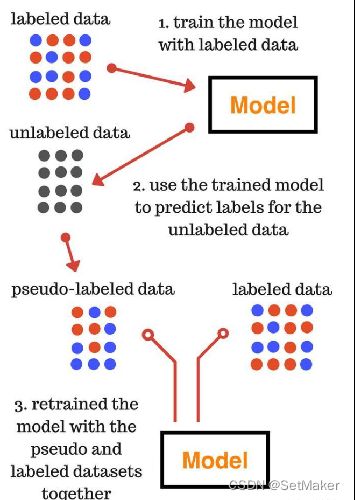
关于半监督的解释如下图,清晰明了
作者对于目前半监督领域存在的问题展开说明:主要说明了两种当前的问题:
问题:协同训练模型在训练过程中趋于早期收敛于共识,因此模型退化为自我训练模型。此外,多视图输入是通过扰动或增强原始图像而产生的,这不可避免地会在输入中引入噪声,导致伪标签的质量下降。
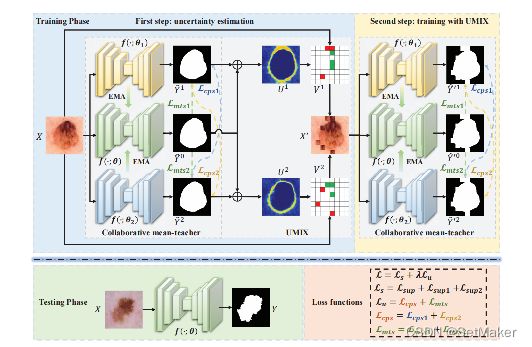
为了解决这些问题,提出了一种不确定性导向的协作均值-teacher(UCMT-Uncertainty-guided Collaborative Mean-Teacher),用于具有高置信度伪标签的半监督语义分割。具体地说,UCMT由两个主要部分组成: 1)协作平均teacher(CMT)用于鼓励模型不一致和执行子网络之间的共同训练;2)不确定性引导区域混合(UMIX)用于根据CMT的不确定性图操纵输入图像,促进CMT产生高置信的伪标签。 UCMT结合UMIX和CMT的优势,可以保留模型的不一致,提高协同训练分割中伪标签的质量。在四个公共医学图像数据集上的实验中进行了广泛的实验,证明了UCMT优于最先进的技术。
关键名词---model disagreement:子网络之间的不一致性是至关重要的,用不同的参数初始化或用不同的视图训练的子网络具有不同的偏差(即不一致性),以确保它们提供的信息是相互补充的。
这种模型间的不一致性可以互相补充两个模型之间互补的信息,这样是提高生成伪标签的很好手段。

简单来说作者觉得能够生成高质量伪标签的网络有两个特性:
1.该网络下的子网络之间要有一种不一致性,也就是刚才提到的那个名词解释。
2.伪标签之间的不确定性要足够小。
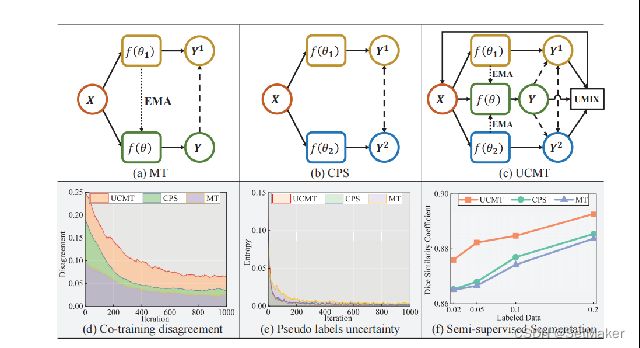
针对上面说的两点想法,作者先做了实验验证自己的想法,实验结果如上图,a中的MT模型和b中的CPS模型,这两种结构分别来自前几年的两篇顶会中,后面会详细说明,简单来说,作者发现MT模型的整体DICE不如CPS模型好,而CPS刚好满足上面说的两个特性,这一点证实了作者的想法。
接下来我们看一下MT以及CPS是啥?
在说之前先介绍一个名词叫做Consistency learning。翻译过来是一致性学习。
当前,Consistency learning主要有三类做法:mean teacher,CPC, CPS,UCMT。 Consistency learning:通过对一个样本进行扰动(添加噪声等等),即改变了它在feature space中的位置。但我们希望模型对于改变之后的样本,预测出同样的类别。比如一个人穿不同的衣服,仍然可以确定是谁。
知道了一致性学习后,我们先来看MT。

paper:Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems, 30, 2017.
Mean teacher是17年提出的模型。给定一个输入图像X,添加不同的高斯噪声后得到X1和X2。我们将X1输入网络f(θ)中,得到预测P1;我们对f(θ)计算EMA,得到另一个网络,然后将X2输入这个EMA模型,得到另一个输出P2。最后,我们用P2作为P1的目标,用MSE loss约束。
这里有一个很关键的操作叫做EMA,对于EMA的解释:EMA---指数移动平均 ,应用在深度学习领域又可叫做权重移动平均(Weighted Moving Average) 原理:权重取平均比取最优更具鲁棒性。简单来说EMA就是对模型中的最优参数附近一个邻域内的参数取均值,用这样的均值来代替我们求的最优参数,这样的模型更具泛化能力。
接着说CPC。
paper:ECCV2020:Guided Collaborative Training for Pixel-wise Semi-Supervised Learning
将同一图像输入两个不同网络,然后约束两个网络的输出是相似的。这种方法虽然简单,但是效果很不错。
接着还有CPS
Cross Pseudo Supervision (CPS)

PAPER:CVPR 2021CPS: Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
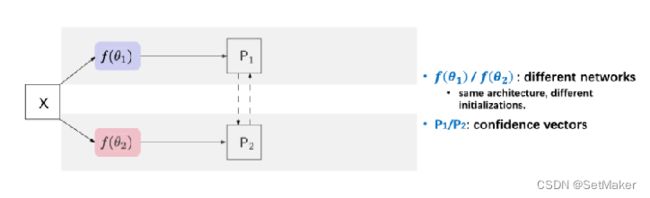
CPS的设计非常的简洁。训练时,使用两个网络f(θ1) 和 f(θ2)。这样对于同一个输入图像X,可以有两个不同的输出P1和P2。通过argmax操作得到对应的one-hot标签Y1和Y2。类似于self-training中的操作,我们将这两个伪标签作为监督信号。举例来说,我们用Y2作为P1的监督,Y1作为P2的监督,并用cross entropy loss约束。
对于这两个网络,使用相同的结构,不同的初始化。用PyTorch框架中的kaiming_normal进行两次随机初始化,而没有对初始化的分布做特定的约束。如果设计特定的初始化,没准CPS的效果会更好。
至此为止,介绍完了这个领域比较主流的几种model。
那么作者是怎样利用上面的想法的呢?
作者提出了这样的一个结构。
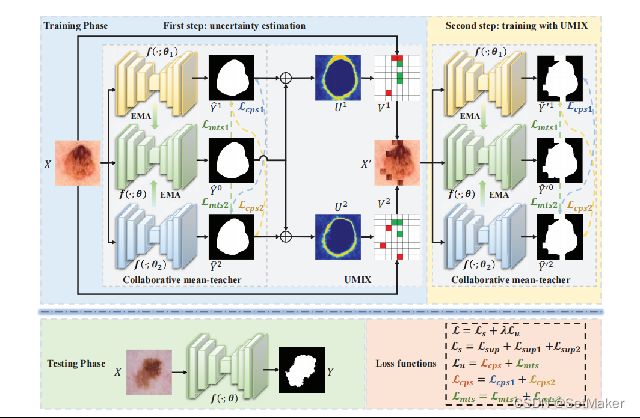
上面的图为整体图不容易看懂。
下面对模型进行分块讲解。
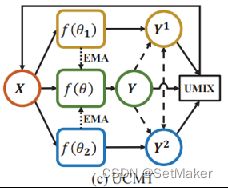

这便是一个UCMT的主要架构,作者命名上面的fΘ1和fΘ2为student,中间的fθ2为teacher。
teacher是由上下两个学生经过刚才提到的EMA操作生成的,具体咋生成的可以看源代码,盲猜是取均值,这个问题不大,知道咋来的就行了。黄色的fθ1和蓝色的fθ2是两个不同的网络,原文说的是different model吧好像,但是作者实验用的是一样的网络,只是在初始化的时候给了不同的参数。这些都是细节, 如果要复现或者用起来的话,直接在源代码找就行,问题不大。
接着说,
作者一直的思想都是希望这两个学生可以朝着不同的方向进行拟合,然后互相学习彼此没有学习到的特征,加入teacher的目的便是对这两个学生的学习给予一个限制,毕竟学生不能随便学,如果学习到错误的信息那就得不偿失了。
对于该部分可以看原文的解释:

这一大段英文最有用的就一句话:这些模型具有相同的结构,但是对其进行初始化时的权重是不同的。这句话作者开始也解释过,作者认为如果想让两个模型往不同的方向进行拟合,有两种方式:第一种便是在初始化的时候给不同的权重;第二个便是在训练的时候给不同的数据。但是往往大家给的伪标签都是原始数据经过加入噪声或者数据增强等操作实现的,这样的方式不可避免的会给伪标签带来噪声,从而影响最终伪标签的生成质量。*这个在最后的实验作者也做的对比,可以说这篇文章从始至终扣题非常严谨,前后照应。
上面的英文还说了,网络的总损失由两部分组成,一个是Ls一个是Lu,Ls是带标签数据的损失,Lu是没有标签数据的损失。
那么继续来说一下Ls,也就是带标签的数据损失咋求。


直接上英文了,这里很好理解,既然数据都有标签了,那直接送入X,分别经过三个模型跑出来预测图,直接和Groundtruth做损失就好了,至于损失函数可以用交叉熵也可以用dice,作者用的是dice,因为作者觉得dice是医学图像分割中比较由说服力的一个指标。
ok,继续来说没标签的数据咋求损失呢?
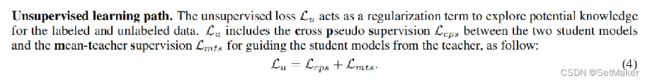
这里他又说了,Lu是总的没标签的数据,他由Lcps和Lmts组成,那先看Lcps是啥,
首先,Lcps的目的是促进两个学生互相学习,并加强他们之间的一致性。Lcps = Lcps1 + Lcps2 Lcps1/2分别是鼓励两个学生子网络f(θ1)和f(θ2)的双向交互。这个说白了就是用最开始那三个之前论文中的方法,对两个学生交叉求损失。也比较好理解。
实在不好理解就看下面这个图,看蓝色线和黄色线,对应求损失。
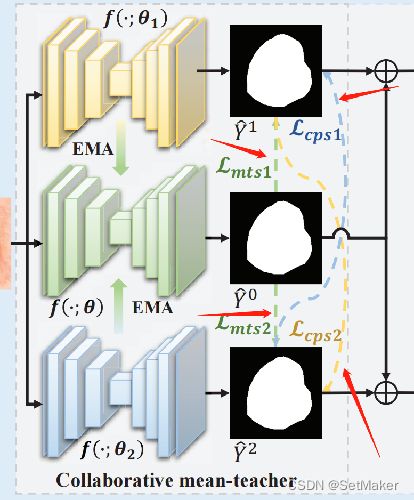
上图的绿线便是第二个损失Lmts,这个就是老师损失了,他的目的是啥呢?
mean-teacher监督。为了避免两个学生在错误的方向上进行交叉监督,引入了一个教师模型来指导学生模型的优化。
就像前面说的,老师是他俩权重的组合,所以老师推理的结果应该是最稳定的,以老师为参照以防止学生学习到错误的信息。
原文是这样说的:

其实看上面图里的绿线就知道了,第一个损失是学生之间互相求损失,这个便是学生和老师求损失。很好理解。
至此为止,模型的不一致性得到了充分的构成。接下来考虑另一个因素:伪标签的不确定性。
作者不是说两个因素可以让模型质量更好吗,一个是子模型间的不一致性,上面已经说了,接下来便是第二个因素,伪标签的不确定性。
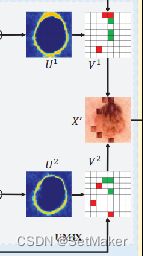
把这个块放大一下,简单来说:
虽然CMT可以促进共同训练的模型不一致,但它也略微增加了伪标签的不确定性。一个子网络可能会向其他子网络提供一些不正确的伪标签,从而降低它们的性能。为了克服这些限制,提出了UMIX,在CMT产生的不确定性图的指导下操作图像斑块。UMIX的主要思想是通过将输入图像中最k个最不确定(低置信度)区域替换为最确定(高置信度)区域来构建一个新的样本。例如,从不确定性图u中获得最不确定区域(红色网格)和最确定区域(绿色网格)。然后,我们将输入图像X中的红色区域替换为绿色区域,构建一个新的样本X‘。
至此生成了X‘,这个X’是带有不确定性的伪标签,生成X‘之后,会进入一个循环,把X’
作为当初的X输入,再走一遍这个网络,更新损失,循环往复,模型拟合好之后,只取中间的老师层作为最终的网络。
最后就是实验结果了:
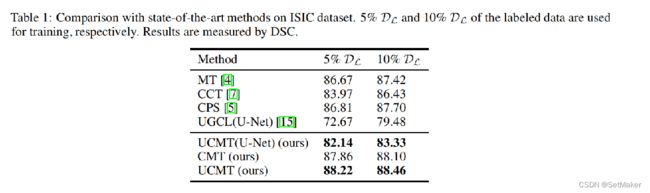
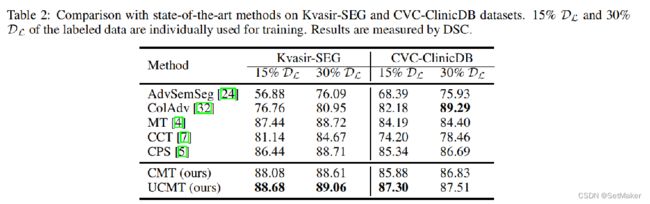
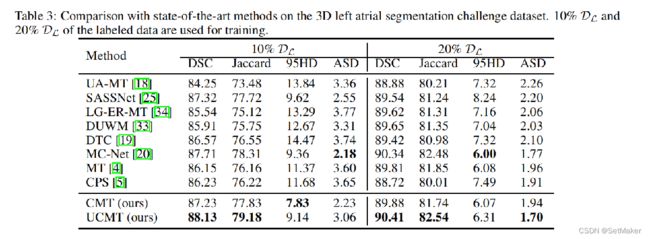

上面的都比较容易理解,一些对比实验,以及消融实验。
下面这个实验就是作者最开始也说的,用那种在原始图上加入噪声或者使用图像增强的方式来生成伪标签的方法,这个对比的cutmix就是用一种混合的方式来训练的,作者对比了这个网络,证明自己的想法是正确的。
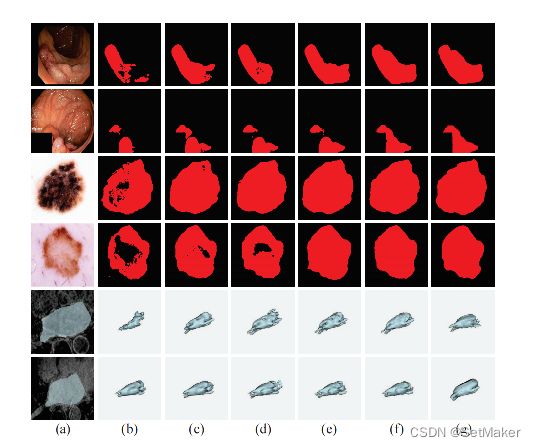
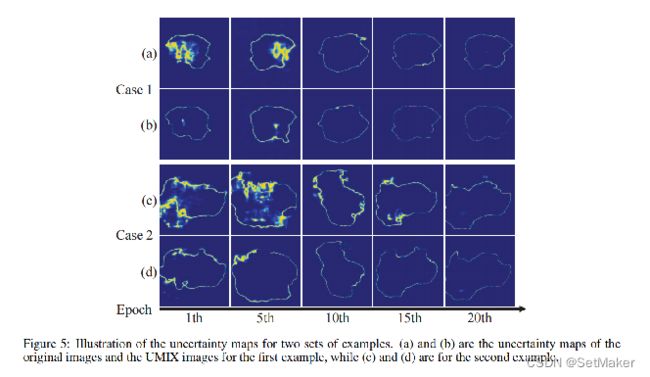
 效果图,和一个不确定性图,不仔细说了。
效果图,和一个不确定性图,不仔细说了。