Unity3D关于ComputeShader
由于最近在实验中需要大量循环计算产生网格,所以可能需要GPU的加速。
对于compute shader学习下,可能对于做GPU加速有帮助。以下补充修改了转载文章的内容
原文链接:https://blog.csdn.net/csharpupdown/article/details/79385544
https://blog.csdn.net/weixin_38884324/article/details/80570160
目录
一、简介
二、使用方法
三、关于numthreads
四、C#代码解析
五、注意事项
一、简介
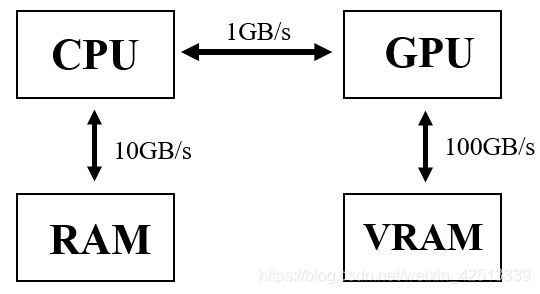
从此图可以看出 CPU和GPU之间的数据传输是瓶颈。故当使用GPU时,对Texture的逐像素处理不需要传回CPU,因而速度比较快。
ComputeShader就是这样的可称为GPGPU编程的东西。顾名思义,它是一段shader程序。它有shader的特性,比如是在GPU上运行的,但它又是脱离于正常的渲染管线之外的,即不对渲染结果造成影响。这跟我们普通的shader不同。
这种shader扩展名为.compute,是DX11的HLSL风格的shader,当然,也可以转为GLSL,使其能兼容OpenGL(目前还没测试,只在DX11上测试过)。ComputeShader目前能运行的图形库包括DX11、DX12、OpenGL4.3+、OpenGLES3.
那么它的好处就是只要是涉及到大量的数学计算,并且是可以并行的没有很多分支的计算,都可以采用ComputeShader。它的缺点就是,如上图所示的,我们需要把数据从CPU传到GPU,然后GPU运算完之后,又从GPU传到CPU,这样的话可能会有点延迟,而且他们之间的传输速率也是一个瓶颈。
不过,如果你真的有大量的计算需求的话,还是不要犹豫地使用ComputeShader,它能带来的性能提升绝对是值得的。
二、使用方法
我们通过一个例子来逐渐地解释ComputeShader的用法。这个例子是在Unity平台下实现的,是计算两个相等大小的Vector3数组相加的结果,得到另一个大小一样的Vector3数组。
我们先贴出ComputeShader的代码:
//shader脚本
// Each #kernel tells which function to compile; you canhave many kernels
#pragma kernel CSMain
#define thread_group_x 2
#define thread_group_y 2
#define thread_x 2
#define thread_y 2
RWStructuredBuffer Result;
RWStructuredBuffer preVertices;
RWStructuredBuffer nextVertices;
//单个线程组包含的线程数
[numthreads(2,2,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
int index = id.x + (id.y * thread_x * thread_group_x) +(id.z * thread_group_x * thread_group_y * thread_x * thread_y);
Result[index] = preVertices[index] + nextVertices[index];
}
代码行数不多,我们一句句来。
首先第一句,#pragma kernel CSMain 定义了该shader的入口函数。这也是C#文件访问该kernel的接口,下面会提到。当然,一个.compute文件可以包含多个kernel,只需要写多个#pragma kernel xxx即可。但是必须至少包含一个kernel,否则会报编译错误。
接下来的四句#define 宏定义,跟C++没什么两样,至于它们的意思,前面说了,shader都是运行在多线程上的。而这里又多一个线程与线程组的概念。先按字面意思记一下,后面我们细讲。
然后三句RWStructuredBuffer
//C#脚本
struct MyVector
{
float x;
float y;
float z;
};
RWStructuredBuffer data;
然后在C#端创建一个同等类型的结构体。
[numthreads(2,2,1)] 这句话就比较重要,也能解释了上面的那四句宏定义。我们就来说说这个线程是怎么切分的。
numthreads的意思就是单个线程组中线程数有多少,并且是怎么分割的。它指定的就是上图中右下的格子。那么线程组的分割又是在哪里指定的呢?这是在C#代码里指定的,下一节会说明。
然后是函数的签名。这里说一下参数uint3 id :SV_DispatchThreadID 。它是指该线程所在的总的线程结构中的索引,还是以上面这个例子来说。如果我们把单个线程组的线程都压缩到这个线程组中,那么就会成为一个4*4的线程方格矩阵。所以id的取值范围就(0,0,0)~(3,3,0)。
其实id的取值范围为(0,0,0)~(threadx*thread_groupx-1,thready*thread_groupy-1,threadz*thread_groupz-1)其中numthreads指定的就是(threadx,thready,threadz).(thread_groupx,thread_groupy,thread_groupz)是在C#脚本里指定的。
三、关于numthreads
在C#脚本中我们会用到一个 Dispatch 函数,这个函数就是定义线程组的数量。
在二维中,如果图片的解析度是(256*128),那么Dispatch和numthreads的分配可以如下:
- Dispatch (k, 256, 128, 1) [numthreads (1, 1, 1)]
- Dispatch (k, 32, 16, 1) [numthreads (8, 8, 1)]
- Dispatch (k, 256/8, 128/8, 1) [numthreads (8, 8, 1)]
- Dispatch (k, 8, 4, 1) [numthreads (32, 32, 1)]
从中我们可以发现 Dispatch.x * numthreads.x = 256 ( 图片宽度 ),Dispatch.y * numthreads.y = 128 ( 图片高度 ),只要 Dispatch * numthreads 是图片大小,那么图片就能完全显示,不会少漏一个像素。
(但是numthreads有上限,numthreads.x * numthreads.y * numthreads.z 必须小于等于 1024)
PS:关于Group 与 Thread 的关系如下图
假设有一张 4X4的图像,使用参数 Dispatch(k, 2, 2, 1) 与 [numthreads(2, 2, 1)]

Group 的 长、宽、高 是由 numthreads 所设定的,同理一个Group的大小是不能超过 1024 。
同理 [numthreads(32, 32, 1)] 的 Group 大小就是 32 * 32 * 1 ( 32 * 32 像素 )
然而如果你的 GPU 有 64 核心,而你的 Group 也有 64 个,那么每个核心将能处理一个 Group。
假设 ThreadSize = ( numthreads.x * numthreads.y * numthreads.z )
那么不同的 ThreadSize 在不同硬件厂下分配的资源是不同的
建议:
AMD:ThreadSize 使用 64 的倍数 ( wavefront 架构 )
NVIDIA:ThreadSize 使用 32 的倍数 ( SIMD32 (Warp) 架构 )
另外使用 Group 有个好处,就是可以等待所有 Thread 同步。不过不同的 Group 是无法同步的。
如果你要在一个 Group 中同步所有 Thread,你可以用下面这语法
GroupMemoryBarrierWithGroupSync();
四、C#代码解析
using UnityEngine;
public class TestCalcMesh:MonoBehaviour
{
public ComputeShader calcMeshShader;
private ComputeBuffer preBuffer;
private ComputeBuffer nextBuffer;
private ComputeBuffer resultBuffer;
public Vector3[] array1;
public Vector3[] array2;
public Vector3[] resultArr;
public int length = 16;
private int kernel;
// Use this for initialization
void Start ()
{
array1 = new Vector3[length];
array2 = new Vector3[length];
resultArr = new Vector3[length];
for (int i = 0; i < length; i++)
{
array1[i] = Vector3.one;
array2[i] = Vector3.one * 2;
}
InitBuffers();
kernel = calcMeshShader.FindKernel("CSMain");
calcMeshShader.SetBuffer(kernel, "preVertices", preBuffer);
calcMeshShader.SetBuffer(kernel, "nextVertices", nextBuffer);
calcMeshShader.SetBuffer(kernel, "Result", resultBuffer);
}
void InitBuffers()
preBuffer = new ComputeBuffer(array1.Length, 12);
preBuffer.SetData(array1);
nextBuffer = new ComputeBuffer(array2.Length, 12);
nextBuffer.SetData(array2);
resultBuffer = new ComputeBuffer(resultArr.Length, 12);
}
// Update is called once per frame
void Update ()
{
if(Input.GetKeyDown(KeyCode.KeypadEnter))
{
calcMeshShader.Dispatch(kernel,2,2,1);
resultBuffer.GetData(resultArr);
//do something with resultArr.
resultBuffer.Release();
}
}
void OnDestroy()
{
preBuffer.Release();
nextBuffer.Release();
}
}
其实C#的代码能说的地方不多,只要用Visual Studio的智能感知就知道大概的意思了。
首先是变量定义部分,定义了一个Compute Shader,还有三个Compute Buffer,Compute Buffer就是在shader计算时传入传出数据的缓存。可以存储任何的数据类型,对应shader中的RWStruceturedBuffer,因为我们没有指定传入传出的类型,所以在初始化这个buffer的时候,我们需要指定stride的值,在这个例子中,stride=12,因为Vector3有3个float值,每个float值是4个字节。所以这里stride的值是指单个类型的字节数。
然后就是ComputeShader.SetBuffer函数,这个其实比较好理解。
比较重要的是ComputeShader.Dispatch函数,它就是指定线程组是如何划分的,即指定(thread_groupx,thread_groupy,thread_groupz)。
最后记得在使用完之后,将Buffer释放掉。
五、注意事项
1、numthreads的数值是有大小限制的,具体如下表所示:
| Compute Shader |
Maximum Z |
Maximum Threads (X*Y*Z) |
| cs_4_x |
1 |
768 |
| cs_5_0 |
64 |
1024 |
你可以选中一个ComputeShader,然后点击Show CompiledShader,里面有说明是哪个版本。即是cs_4_x还是cs_5_0.
2、DX和OpenGL是有不同的布局规则的,如果将compute shader自动转换成GLSL的compute shader的话,用的是std430标准。因此如果是用float3数组的话,在DX里是会自动对齐位数的,而在OpenGL里的话,则会强制转成float4.所以就有可能产生兼容的问题,但是标量、二维、四维的数组就不会有这个问题。所以在使用float3数组时,需要注意一下。
3、main函数里,索引不能是常数,会报编译错误。比如
int a = 0;
Result[a] = preVertices[0] +nextVertices[0];
它这样的规则可能是为了线程的安全性,毕竟ComputeShader是多线程的。不能写入一个常数索引里,估计是担心多线程会有数据的冲突问题。
4、Don't use get data in real time! (took me 2months to find the reason, which I can explain another time if you like)
Instead:
Make an array of compute buffers, aminimum of 2: one for read, one for write.
Do a rw structure in compute, filledwith junk data to be overridden in the compute
On the next frame (this is import - Isuggest doing an enum to 'waitforenfoframe' yield )
Lastly copy the Contents of the writebuffer into read.
Then use these cloned buffers withwhatever you need - get data does work on static buffers in this case.
这段话描述的问题,我还没有碰到过,所以还不太清楚,暂且留着
来源网址 https://forum.unity.com/threads/check-if-a-computeshader-dispatch-command-is-completed-on-gpu-before-doing-second-kernel-dispatch.369631/