nnU-Net团队新作MedNeXt:新一代医学图像分割之王,刷新多项榜单记录!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【医疗影像和Transformer】微信技术交流群
转载自:CVHub

Title: MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
Paper: https://arxiv.org/abs/2303.09975
导读
ConvNeXT是一种纯卷积模型,其灵感来自Vision Transformers的设计,性能出众。本文对此进行了改进,以设计一个现代化且可扩展的卷积架构——MedNeXt,该架构针对医学图像分割领域进行了针对性的优化。
MedNeXt是一种受Transformer启发的大卷积核分割网络,其基于类 ConvNeXt 风格的纯 3D 编解码架构(Encoder-Decoder Architecture)。在这项工作中,作者设计了一种带残差的ConvNeXt上采样和下采样块,以保持跨尺度的语义丰富性,同时应用了一种新技术通过对小卷积核网络进行上采样来迭代增加kernel大小,以防止有限医疗数据的性能饱和。
最后,通过对MedNeXt架构的不同尺度(depth, width, kernel size)进行缩放,本文方法在 CT 和 MRI 模态以及不同数据集大小的 4 个任务上均实现了最先进的性能,可谓是医学图像分割领域的现代化深度架构之王!
值得一提的是,本文是由原
nnUNet研究团队打造,其结论必将极具说服力和观赏性!
背景
难点与挑战
目前深度学习的算法在较为特定、具体的任务上能够获得较好的表现(如脑肿瘤的分割),但是并不一定能够在一些未见过的任务上(如肝脏血管分割)获得较好的泛化性能。如果有一种算法,能够在给定一定的训练数据的情况下,自适应地完成所有未曾处理过的任务的分割而不需要人工干预,对于医学辅助诊断系统是具有重大意义的。
下面,首先让我们来看下医学图像分割任务中较为常见的难点和挑战:
由于数据标签获取的成本较大,因此往往数据量较少
由于疾病的特点(如发病率,病灶通常只占器官的较小部分),样本不均衡的问题较为常见
小目标的分割精度对临床价值更大但同时也更难准确分割
不同采集设备对数据产生的影响
虽然医学图像分割领域每年产生数以万计的新SOTA,但由于以上种种原因,导致现有的应用于医学图像分割领域的网络架构很多时候并不具备通用性和鲁棒性。而一个真正的SOTA架构应当具备以下条件:
最先进的算法能够准确地完成医学图像分割任务,并且在新的、未进行过训练的数据集上能够获得较好的泛化性能
算法能够在多种不同的分割任务中获得一致的先进的性能
目前准确的训练好的模型已经能够进行商业化提供给非AI专业人员使用
nnUNet
nnUNet早期被众人所熟知是有一年参加了医学图像分割领域的十项全能比赛(MSD)并获得了冠军:
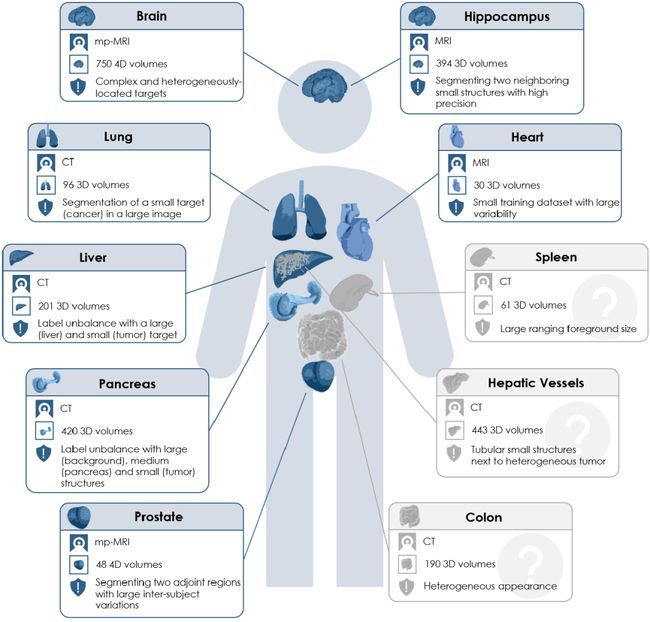 MSD 挑战赛
MSD 挑战赛
MSD 挑战赛一共包含十个数据集,其中第一阶段为:脑、心脏、海马体、肝脏、肺部、胰腺以及前列腺的分割,而第二阶段则是包含了结肠、肝脏血管以及脾脏的分割。
应该来说,nnU-Net其实并不是一个新的网络架构,而是一个集成了多种Trick和数据预处理以及后处理的医学图像分割框架。其核心思想是基于对训练数据集的分析,使用全自动动态适应的分割综合解决方案,以更好的完成每个任务。作者认为,图像预处理、网络拓扑和后处理比网络结构更重要,而这些最重要的部分nnU-Net框架能够自动确定(自适应调参)。
nnU-Net网络结构是基于U-Net架构,并进行了以下修改:
使用
leaky ReLU替代ReLU;实例归一化替代常规的
BN;步长卷积进行下采样;
此外,在数据增强方面,主要是用到了仿射变换、非线性形变、强度变换(类似于伽马校正)、沿所有轴镜像和随机裁剪等。而在损失函数方面,则结合Dice和交叉熵作为一个组合,同时使用了Adam优化器。最后,作者设计了一种集成策略,通过使用四种不同的架构,利用对训练集的交叉验证自动找到特定任务的最佳组合选择。
当然,以上所述都是非常早期的改进,经过这几年的不断迭代,相信
nnUNet已经发展得更加强大了。值得欣慰的是,作者们也一直在更新和维护该仓库。
在本次挑战赛后的两年中,nnU-Net总共参加了几十上百项项分割任务。该方法在多个任务中赢得了前几名的成绩。例如,笔者印象深刻的是获得了 2020 年著名的 BraTS 挑战冠军。nnU-Net的成功证实了我们的假设,即在多个任务上表现良好的方法将能够很好地推广到以前未见过的任务,并有可能胜过定制设计的解决方案。在后续的发展中,nnU-Net已然成为最先进的医学图像分割方法,并被其他研究人员用于多项分割挑战。例如,在 2019 年肾脏和肾脏肿瘤分割挑战赛的前 15 名算法中,有 8 种是基于 nnU-Net 改进的方法。在COVID-19肺 CT 病变分割挑战中,前十名中有九种算法是基于nnU-Net设计的。而 2020 年的各种挑战赛获胜者中有 90% 都是在nnU-Net之上构建了解决方案。等等。
因此,如此完美的千里马(nnUNet),必然需要一个伯乐(MedNeXt)才能与之匹配。下面就让我们正式介绍本文方法。
方法
Fully ConvNeXt 3D Segmentation Architecture
众所周知,ConvNeXt继承了Transformers的许多重要设计思想,其核心理念旨在限制计算成本,同时增加网络的感受野以学习全局特征。在这项工作中,作者基于ConvNeXt的设计模式,提出了一个类似于3D-UNet的新型网络架构——MedNeXt:
 MedNeXt macro and block architecture
MedNeXt macro and block architecture
上图为MedNeXt的整体网络架构图。如图所示,该网络各有 4 个对称编码器和解码器层(果然很U-Net),中间还嵌入一个瓶颈层。其中,MedNeXt块也包含在每个上采样层和下采样层中。每个解码器层都使用深监督,在较低的分辨率下具有较低的损失权重。
关于深监督的思想,请参考 CVHub 官方精选的
Multi-task learning一文:
 LibMTL: 用于多任务学习的 PyTorch 库
LibMTL: 用于多任务学习的 PyTorch 库
可见,作者的深监督机制设计思路同笔者此前所提出的设想如出一辙。下面重点介绍下MedNeXt模块(如上述框架图黄色部分),这是一个类似于ConvNeXt block的新模块,其包含以下三大重要组件,即Depthwise Convolution Layer、Expansion Layer以及Compression Layer。下面分别介绍下这三部分。
Depthwise Convolution Layer
DW层主要包含一个卷积核大小为 k × k × k 的深度卷积,随后接上归一化,具有 C 个输出通道。此处,作者使用channel-wise GroupNorm来稳定较小BatchSize所带来的的潜在影响,而不是使用ConvNeXt或者说大部分Transformer架构中常用的LayerNorm。这是由于卷积的深度性质必将允许该层中的大卷积核复制Swin-Transformers的大注意力窗口,同时又能够有效的限制计算量。
Expansion Layer
对标Transformers的类似设计,扩展层主要用于通道缩放,其中 R 是扩展比,同时引入了GELU激活函数。需要注意的是,大的 R 值允许网络横向扩展,并采用 1 × 1 × 1 的卷积核限制计算量。因此,该层有效地将宽度缩放与上一层中的感受野进行了深度绑定。
Compression Layer
模块的最后便是采用具有 1 × 1 × 1 卷积核和 C 个输出通道的卷积层执行特征图的逐通道压缩。
总的来说,MedNeXt是基于纯卷积架构的,其保留了ConvNets固有的归纳偏置(inductive bias),可以更轻松地对稀疏医学数据集进行训练。此外,同ConvNeXt一样,为了更好的对整体网络架构进行伸缩和扩展,本文设计了一种 3 种正交类型的缩放策略,以针对不同数据集实现更有效和鲁邦的医学图像分割性能。
Resampling with Residual Inverted Bottlenecks
最初的ConvNeXt架构利用由标准步长卷积组成的独立下采样层。与之相反的便是应用转置卷积来进行上采样操作。然而,这种朴素的设计并未能充分该架构的优势。因此,本文通过将倒置的瓶颈层扩展到MedNeXt中的重采样块来改进这一点。
具体实现上,可以通过在第一个DW层中分别插入步长卷积或转置卷积来完成,以实现可以完成上、下采样的MedNeXt块,如上图绿色和蓝色部分所示。此外,为了使梯度流更容易,作者添加了具有 1 × 1 × 1 卷积或步长为 2 的转置卷积的残差连接。如此一来。便可以充分利用类似 Transformer 的倒置瓶颈的优势,以更低的计算代价保留更丰富的语义信息和所需的空间分辨率,这非常有利于密集预测型的医学图像分割任务。
UpKern: Large Kernel Convolutions without Saturation
大家都知道,提高卷积核的大小意味着增大网络的感受野从而有效提升网络的性能。然而,需要注意的是,这仅仅是理论感受野,而非实际感受野。So sad~~~
因此,最近有许多工作都在探索大卷积核的魔力,据笔者有限的知识储备,目前看到过最高的极限是扩展到61 x 61,有兴趣的读者可以自行去翻阅『CVHub』。讨论回ConvNeXt本身,其卷积核的极限只到7 x 7,根据原著所述再往上增大就“饱和”了。所以,针对医学图像分割这类本身数据就很稀缺的任务来说,如何才能有效的应用和发挥该架构的优势呢?下面看看作者是如何做的。
为了解决这个问题,作者们首先借鉴了Swin Transformer V2的灵感,其中一个大的注意力窗口网络是用另一个较小的注意力窗口训练的网络进行初始化的。此外,作者提议将现有的偏差矩阵空间插值到更大的尺寸作为预训练步骤,而不是从头开始训练,后续的实验也充分验证了此方法的有效性。
 Upsampled Kernel (UpKern) & Performance
Upsampled Kernel (UpKern) & Performance
如上图所示,作者对针对卷积核进行了相应的“定制化”,以克服性能饱和问题。其中,UpKern允许我们通过对大小不兼容的卷积核(表示为张量)进行三维线性上采样来初始化具有兼容的预训练小卷积核网络的大卷积核网络,从而迭代地增加卷积核大小。所有其他具有相同张量大小的层(包括归一化层)都通过复制未更改的预训练权重来初始化。
综上所述,以上操作为 MedNeXt 带来了一种简单但有效的初始化技术,可帮助大卷积核网络克服医学图像分割常见的相对有限的数据场景中的性能饱和。
Compound Scaling of Depth, Width and Receptive Field
下表展示的是作者针对不同的维度采用复合缩放策略来最大化性能的表现:

可以看到,相较于常规的上采样和下采样模块,本文方法能够更好的适应不同的任务。
实验
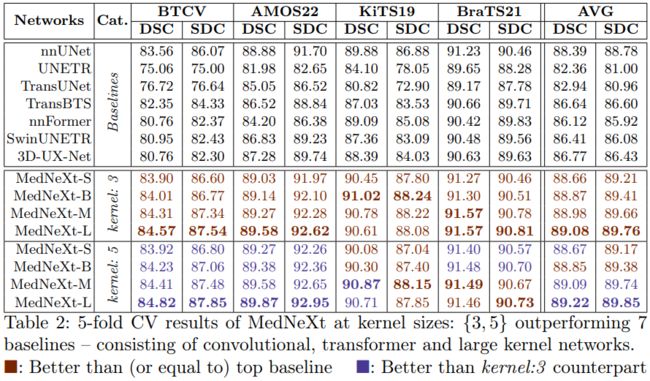
本文在AMOS22和BTCV数据集上进行了相关的实验,以展示所提方法的有效性,同时也证明了直接应用普通的ConvNeXt架构连现有的分割基线(如nnUNet)都打不过。
从上表可以看出,MedNeXt针对现有的四个主流的医学图像分割数据集均取得了SOTA的性能,而无需额外的训练数据。尽管存在任务异质性(脑和肾肿瘤、器官)、模态(CT、MRI)和训练集大小(BTCV:18 个样本 vs BraTS21:1000 个样本),但 MedNeXt-L 始终优于当前最先进的算法,如nnUNet。此外,借助 UpKern 和 5 × 5 × 5 的卷积核,MedNeXt 利用完全复合缩放进一步改进其自身网络,在器官分割(BTCV、AMOS)和肿瘤分割(KiTS19、BraTS21)方面进行全面改进。
此外,在官方的Leaderboard上,MedNeXt 在 BTCV 任务上轻松击败nnUNet。值得注意的是,这是目前为止仅受监督训练且没有额外训练数据的领先方法之一(DSC:88.76,HD95:15.34)。同样地,对于AMOS22数据集,MedNeXt不仅超过了nnUNet,而且一直占据榜首(DSC:91.77,NSD:84.00)!最后,MedNeXt在另外两个数据集,即KITS19和BraTS21均获得了不错的表现,这一切得益于其优秀的架构设计。
总结
与自然图像任务相比,由于有限的训练数据等固有的领域挑战,医学图像分割缺乏受益于缩放网络的架构(如ConvNeXt)。本文提出了一种具备高度可扩展性的类ConvNeXt的 3D 分割架构,其在有限的医学图像数据集上优于其它 7 个顶流方法,当中就包含了非常强的nnUNet。MedNeXt设计作为标准卷积块的有效替代,完全可作为医学图像分割领域的新网络架构标杆之作!
点击进入—>【医疗影像和Transformer】微信技术交流群
MedNeXt 论文PDF下载
后台回复:MedNeXt,即可下载上面论文
医疗影像和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-医疗影像或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看