本文主要介绍常见的锁,以及synchronized、NSLock、递归锁、条件锁的底层分析
锁
借鉴一张锁的性能数据对比图,如下所示
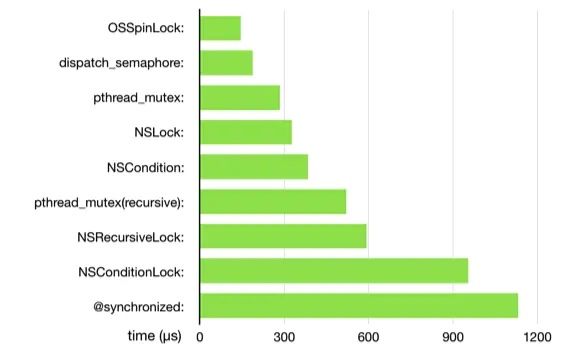
可以看出,图中锁的性能从高到底依次是:OSSpinLock(自旋锁) -> dispatch_semaphone(信号量) -> pthread_mutex(互斥锁) -> NSLock(互斥锁) -> NSCondition(条件锁) -> pthread_mutex(recursive 互斥递归锁) -> NSRecursiveLock(递归锁) -> NSConditionLock(条件锁) -> synchronized(互斥锁)
图中锁大致分为以下几类:
-
【1、
自旋锁】:在自旋锁中,线程会反复检查变量是否可用。由于线程这个过程中一直保持执行,所以是一种忙等待。 一旦获取了自旋锁,线程就会一直保持该锁,直到显式释放自旋锁。自旋锁避免了进程上下文的调度开销,因此对于线程只会阻塞很短时间的场合是有效的。对于iOS属性的修饰符atomic,自带一把自旋锁OSSpinLock
atomic
-
【2、
互斥锁】:互斥锁是一种用于多线程编程中,防止两条线程同时对同一公共资源(例如全局变量)进行读写的机制,该目的是通过将代码切成一个个临界区而达成@synchronized
NSLock
pthread_mutex
-
【3、
条件锁】:条件锁就是条件变量,当进程的某些资源要求不满足时就进入休眠,即锁住了,当资源被分配到了,条件锁打开了,进程继续运行NSCondition
NSConditionLock
-
【4、
递归锁】:递归锁就是同一个线程可以加锁N次而不会引发死锁。递归锁是特殊的互斥锁,即是带有递归性质的互斥锁pthread_mutex(recursive)
NSRecursiveLock
-
【5、
信号量】:信号量是一种更高级的同步机制,互斥锁可以说是semaphore在仅取值0/1时的特例,信号量可以有更多的取值空间,用来实现更加复杂的同步,而不单单是线程间互斥- dispatch_semaphore
-
【6、
读写锁】:读写锁实际是一种特殊的自旋锁。将对共享资源的访问分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。这种锁相对于自旋锁而言,能提高并发性一个读写锁同时只能有一个写者或者多个读者,但不能既有读者又有写者,在读写锁保持期间也是抢占失效的如果
读写锁当前没有读者,也没有写者,那么写者可以立刻获得读写锁,否则它必须自旋在那里, 直到没有任何写者或读者。如果读写锁没有写者,那么读者可以立刻获得读写锁
其实基本的锁就包括三类:自旋锁、互斥锁、读写锁,其他的比如条件锁、递归锁、信号量都是上层的封装和实现。
1、OSSpinLock(自旋锁)
自从OSSpinLock出现安全问题,在iOS10之后就被废弃了。自旋锁之所以不安全,是因为获取锁后,线程会一直处于忙等待,造成了任务的优先级反转。
其中的忙等待机制可能会造成高优先级任务一直running等待,占用时间片,而低优先级的任务无法抢占时间片,会造成一直不能完成,锁未释放的情况
在OSSpinLock被弃用后,其替代方案是内部封装了os_unfair_lock,而os_unfair_lock在加锁时会处于休眠状态,而不是自旋锁的忙等状态
2、atomic(原子锁)
atomic适用于OC中属性的修饰符,其自带一把自旋锁,但是这个一般基本不使用,都是使用的nonatomic
在前面的文章中,我们提及setter方法会根据修饰符调用不同方法,其中最后会统一调用reallySetProperty方法,其中就有atomic和非atomic的操作
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
...
id *slot = (id*) ((char*)self + offset);
...
if (!atomic) {//未加锁
oldValue = *slot;
*slot = newValue;
} else {//加锁
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
}
...
}
从源码中可以看出,对于atomic修饰的属性,进行了spinlock_t加锁处理,但是在前文中提到OSSpinLock已经废弃了,这里的spinlock_t在底层是通过os_unfair_lock替代了OSSpinLock实现的加锁。同时为了防止哈希冲突,还是用了加盐操作
using spinlock_t = mutex_tt;
class mutex_tt : nocopy_t {
os_unfair_lock mLock;
...
}
getter方法中对atomic的处理,同setter是大致相同的
id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) {
if (offset == 0) {
return object_getClass(self);
}
// Retain release world
id *slot = (id*) ((char*)self + offset);
if (!atomic) return *slot;
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();//加锁
id value = objc_retain(*slot);
slotlock.unlock();//解锁
// for performance, we (safely) issue the autorelease OUTSIDE of the spinlock.
return objc_autoreleaseReturnValue(value);
}
3、synchronized(互斥递归锁)
-
开启汇编调试,发现
@synchronized在执行过程中,会走底层的objc_sync_enter和objc_sync_exit方法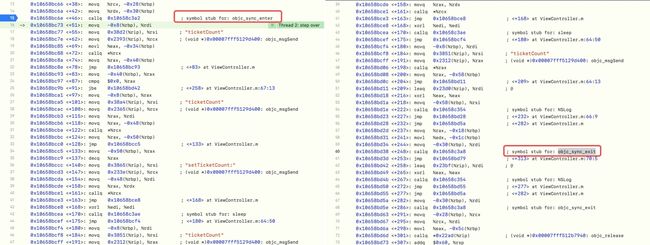
也可以通过clang,查看底层编译代码
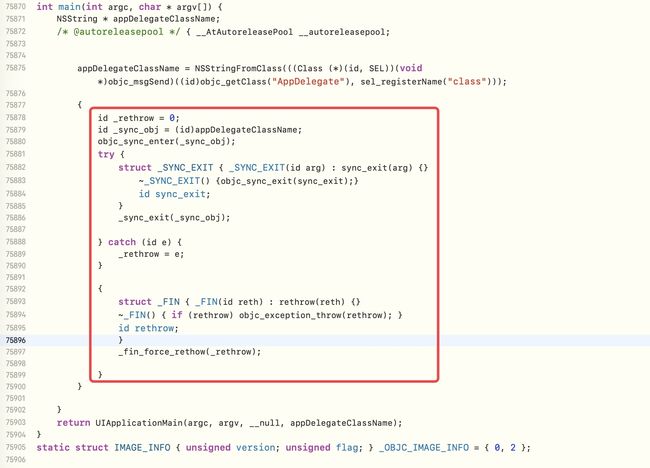
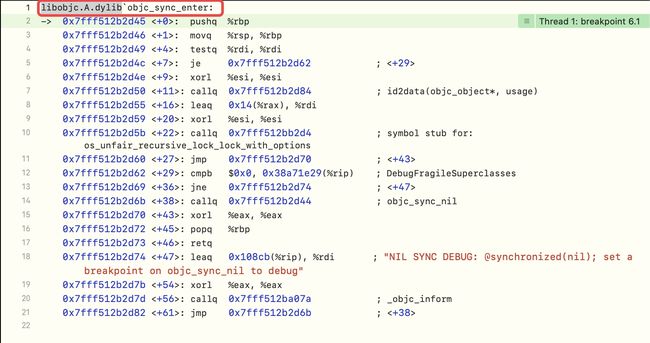
通过对objc_sync_enter方法符号断点,查看底层所在的源码库,通过断点发现在objc源码中,即libobjc.A.dylib
objc_sync_enter & objc_sync_exit 分析
- 进入
objc_sync_enter源码实现- 如果obj存在,则通过
id2data方法获取相应的SyncData,对threadCount、lockCount进行递增操作 - 如果obj不存在,则调用
objc_sync_nil,通过符号断点得知,这个方法里面什么都没做,直接return了
- 如果obj存在,则通过
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {//传入不为nil
SyncData* data = id2data(obj, ACQUIRE);//重点
ASSERT(data);
data->mutex.lock();//加锁
} else {//传入nil
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
- 进入
objc_sync_exit源码实现- 如果obj存在,则调用
id2data方法获取对应的SyncData,对threadCount、lockCount进行递减操作 - 如果obj为
nil,什么也不做
- 如果obj存在,则调用
// End synchronizing on 'obj'. 结束对“ obj”的同步
// Returns OBJC_SYNC_SUCCESS or OBJC_SYNC_NOT_OWNING_THREAD_ERROR
int objc_sync_exit(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {//obj不为nil
SyncData* data = id2data(obj, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock();//解锁
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else {//obj为nil时,什么也不做
// @synchronized(nil) does nothing
}
return result;
}
通过上面两个实现逻辑的对比,发现它们有一个共同点,在obj存在时,都会通过id2data方法,获取SyncData
- 进入
SyncData的定义,是一个结构体,主要用来表示一个线程data,类似于链表结构,有next指向,且封装了recursive_mutex_t属性,可以确认@synchronized确实是一个递归互斥锁
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;//类似链表结构
DisguisedPtr object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;//递归锁
} SyncData;
- 进入
SyncCache的定义,也是一个结构体,用于存储线程,其中list[0]表示当前线程的链表data,主要用于存储SyncData和lockCount
typedef struct {
SyncData *data;
unsigned int lockCount; // number of times THIS THREAD locked this block
} SyncCacheItem;
typedef struct SyncCache {
unsigned int allocated;
unsigned int used;
SyncCacheItem list[0];
} SyncCache;
id2data 分析
- 进入
id2data源码,从上面的分析,可以看出,这个方法是加锁和解锁都复用的方法
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
#if SUPPORT_DIRECT_THREAD_KEYS //tls(Thread Local Storage,本地局部的线程缓存)
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
//通过KVC方式对线程进行获取 线程绑定的data
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
//如果线程缓存中有data,执行if流程
if (data) {
fastCacheOccupied = YES;
//如果在线程空间找到了data
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
//通过KVC获取lockCount,lockCount用来记录 被锁了几次,即 该锁可嵌套
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
case ACQUIRE: {
//objc_sync_enter走这里,传入的是ACQUIRE -- 获取
lockCount++;//通过lockCount判断被锁了几次,即表示 可重入(递归锁如果可重入,会死锁)
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);//设置
break;
}
case RELEASE:
//objc_sync_exit走这里,传入的why是RELEASE -- 释放
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
#endif
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);//判断缓存中是否有该线程
//如果cache中有,方式与线程缓存一致
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {//遍历总表
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE://加锁
item->lockCount++;
break;
case RELEASE://解锁
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache 从cache中清除使用标记
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
//第一次进来,所有缓存都找不到
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {//cache中已经找到
if ( p->object == object ) {//如果不等于空,且与object相似
result = p;//赋值
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);//对threadCount进行++
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object 没有与当前对象关联的SyncData
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it 第一次进来,没有找到
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));//创建赋值
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) { //判断是否支持栈存缓存,支持则通过KVC形式赋值 存入tls
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);//lockCount = 1
} else
#endif
{
// Save in thread cache 缓存中存一份
if (!cache) cache = fetch_cache(YES);//第一次存储时,对线程进行了绑定
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
-
【第一步】首先在
tls即线程缓存中查找。在
tls_get_direct方法中以线程为key,通过KVC的方式获取与之绑定的SyncData,即线程data。其中的tls(),表示本地局部的线程缓存,判断获取的data是否存在,以及判断data中是否能找到对应的
object如果都找到了,在
tls_get_direct方法中以KVC的方式获取lockCount,用来记录对象被锁了几次(即锁的嵌套次数)如果data中的
threadCount小于等于0,或者lockCount小于等于0时,则直接崩溃-
通过传入的
why,判断是操作类型如果是
ACQUIRE,表示加锁,则进行lockCount++,并保存到tls缓存如果是
RELEASE,表示释放,则进行lockCount--,并保存到tls缓存。如果lockCount等于0,从tls中移除线程data如果是
CHECK,则什么也不做
-
【第二步】如果tls中没有,则在
cache缓存中查找通过
fetch_cache方法查找cache缓存中是否有线程如果有,则遍历
cache总表,读取出线程对应的SyncCacheItem从
SyncCacheItem中取出data,然后后续步骤与tls的匹配是一致的
-
【第三步】如果cache中也没有,即
第一次进来,则创建SyncData,并存储到相应缓存中- 如果在cache中找到线程,且与object相等,则进行
赋值、以及threadCount++ - 如果在cache中没有找到,则
threadCount等于1
- 如果在cache中找到线程,且与object相等,则进行
所以在id2data方法中,主要分为三种情况
-
【第一次进来,没有锁】:
threadCount = 1lockCount = 1存储到
tls
-
【不是第一次进来,且是同一个线程】
tls中有数据,则
lockCount++存储到
tls
-
【不是第一次进来,且是不同线程】
全局线程空间进行查找线程threadCount++lockCount++存储到
cache
tls和cache表结构
针对tls和cache缓存,底层的表结构如下所示
-
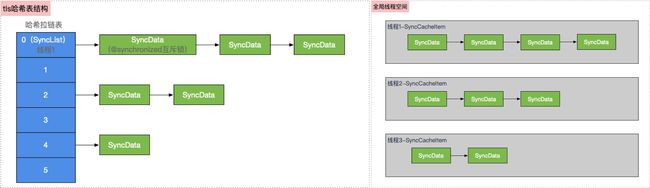
哈希表结构中通过SyncList结构来组装多线程的情况SyncData通过链表的形式组装当前可重入的情况下层通过
tls线程缓存、cache缓存来进行处理底层主要有两个东西:
lockCount、threadCount,解决了递归互斥锁,解决了嵌套可重入
@synchronized 坑点
下面代码这样写,会有什么问题?
- (void)cjl_testSync{
_testArray = [NSMutableArray array];
for (int i = 0; i < 200000; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
@synchronized (self.testArray) {
self.testArray = [NSMutableArray array];
}
});
}
}
运行结果发现,运行就崩溃
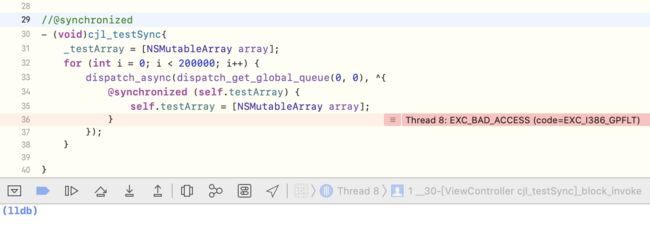
崩溃的主要原因是testArray在某一瞬间变成了nil,从@synchronized底层流程知道,如果加锁的对象成了nil,是锁不住的,相当于下面这种情况,block内部不停的retain、release,会在某一瞬间上一个还未release,下一个已经准备release,这样会导致野指针的产生
_testArray = [NSMutableArray array];
for (int i = 0; i < 200000; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
_testArray = [NSMutableArray array];
});
}
可以根据上面的代码,打开edit scheme -> run -> Diagnostics中勾选Zombie Objects ,来查看是否是僵尸对象,结果如下所示
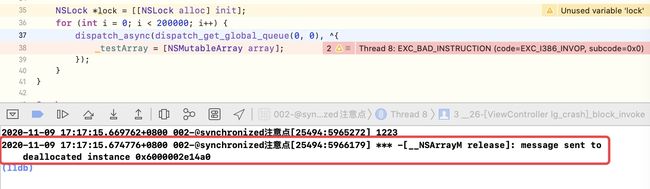
我们一般使用@synchronized (self),主要是因为_testArray的持有者是self
注意:野指针 vs 过渡释放
野指针:是指由于过渡释放产生的指针还在进行操作过渡释放:每次都会retain 和 release
总结
@synchronized在底层封装的是一把递归互斥锁@synchronized的可重入,即可嵌套,主要是由于lockCount和threadCount的搭配@synchronized使用链表的原因是链表方便下一个data的插入,但是由于底层中
链表查询、缓存的查找以及递归,是非常耗内存以及性能的,导致性能低,所以在前文中,该锁的排名在最后但是目前该锁的使用频率仍然很高,主要是因为
方便简单,且不用解锁不能使用
非OC对象作为加锁对象,因为其object的参数为引用类型@synchronized (self)这种适用于嵌套次数较少的场景。这里锁住的对象也并不永远是self,这里需要读者注意如果锁嵌套次数较多,即
锁self过多,会导致底层的查找非常麻烦,因为其底层是链表进行查找,所以会相对比较麻烦,所以此时可以使用NSLock、信号量等
4、NSLock
NSLock是对下层pthread_mutex的封装,使用如下
NSLock *lock = [[NSLock alloc] init];
[lock lock];
[lock unlock];
直接进入NSLock定义查看,其遵循了NSLocking协议,下面来探索NSLock的底层实现
NSLock 底层分析
-
通过加符号断点
lock分析,发现其源码在Foundation框架中
-
由于OC的
Foundation框架不开源,所以这里借助Swift的开源框架Foundation来 分析NSLock的底层实现,其原理与OC是大致相同的
通过源码实现可以看出,底层是通过
pthread_mutex互斥锁实现的。并且在init方法中,还做了一些其他操作,所以在使用NSLock时需要使用init初始化
回到前文的性能图中,可以看出NSLock的性能仅次于 pthread_mutex(互斥锁),非常接近
使用弊端
请问下面block嵌套block的代码中,会有什么问题?
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
testMethod = ^(int value){
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
};
testMethod(10);
});
}
-
在未加锁之前,其中的current=9、10有很多条,导致数据混乱,主要原因是多线程导致的

如果像下面这样加锁,会有什么问题?
NSLock *lock = [[NSLock alloc] init];
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
testMethod = ^(int value){
[lock lock];
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
};
testMethod(10);
[lock unlock];
});
}
其运行结果如下

会出现一直等待的情况,主要是因为嵌套使用的递归,使用NSLock(简单的互斥锁,如果没有回来,会一直睡觉等待),即会存在一直加lock,等不到unlock 的堵塞情况
所以,针对这种情况,可以使用以下方式解决
- 使用
@synchronized
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
testMethod = ^(int value){
@synchronized (self) {
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
}
};
testMethod(10);
});
}
- 使用递归锁
NSRecursiveLock
NSRecursiveLock *recursiveLock = [[NSRecursiveLock alloc] init];
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
[recursiveLock lock];
testMethod = ^(int value){
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
[recursiveLock unlock];
};
testMethod(10);
});
}
pthread_mutex
pthread_mutex就是互斥锁本身,当锁被占用,其他线程申请锁时,不会一直忙等待,而是阻塞线程并睡眠
使用
// 导入头文件
#import
// 全局声明互斥锁
pthread_mutex_t _lock;
// 初始化互斥锁
pthread_mutex_init(&_lock, NULL);
// 加锁
pthread_mutex_lock(&_lock);
// 这里做需要线程安全操作
// 解锁
pthread_mutex_unlock(&_lock);
// 释放锁
pthread_mutex_destroy(&_lock);
6、NSRecursiveLock
NSRecursiveLock在底层也是对pthread_mutex的封装,可以通过swift的Foundation源码查看

对比NSLock 和 NSRecursiveLock,其底层实现几乎一模一样,区别在于init时,NSRecursiveLock有一个标识PTHREAD_MUTEX_RECURSIVE,而NSLock是默认的
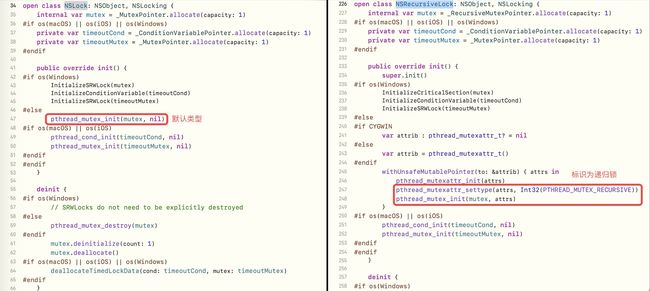
递归锁主要是用于解决一种嵌套形式,其中循环嵌套居多
7、NSCondition
NSCondition 是一个条件锁,在日常开发中使用较少,与信号量有点相似:线程需要满足条件才会往下走,否则会堵塞等待,直到条件满足。经典模型是生产消费者模型
NSCondition的对象实际上作为一个锁 和 一个线程检查器
锁主要 为了当检测条件时保护数据源,执行条件引发的任务线程检查器主要是根据条件决定是否继续运行线程,即线程是否被阻塞
使用
//初始化
NSCondition *condition = [[NSCondition alloc] init]
//一般用于多线程同时访问、修改同一个数据源,保证在同一 时间内数据源只被访问、修改一次,其他线程的命令需要在lock 外等待,只到 unlock ,才可访问
[condition lock];
//与lock 同时使用
[condition unlock];
//让当前线程处于等待状态
[condition wait];
//CPU发信号告诉线程不用在等待,可以继续执行
[condition signal];
底层分析
通过swift的Foundation源码查看NSCondition的底层实现
open class NSCondition: NSObject, NSLocking {
internal var mutex = _MutexPointer.allocate(capacity: 1)
internal var cond = _ConditionVariablePointer.allocate(capacity: 1)
//初始化
public override init() {
pthread_mutex_init(mutex, nil)
pthread_cond_init(cond, nil)
}
//析构
deinit {
pthread_mutex_destroy(mutex)
pthread_cond_destroy(cond)
mutex.deinitialize(count: 1)
cond.deinitialize(count: 1)
mutex.deallocate()
cond.deallocate()
}
//加锁
open func lock() {
pthread_mutex_lock(mutex)
}
//解锁
open func unlock() {
pthread_mutex_unlock(mutex)
}
//等待
open func wait() {
pthread_cond_wait(cond, mutex)
}
//等待
open func wait(until limit: Date) -> Bool {
guard var timeout = timeSpecFrom(date: limit) else {
return false
}
return pthread_cond_timedwait(cond, mutex, &timeout) == 0
}
//信号,表示等待的可以执行了
open func signal() {
pthread_cond_signal(cond)
}
//广播
open func broadcast() {
// 汇编分析 - 猜 (多看多玩)
pthread_cond_broadcast(cond) // wait signal
}
open var name: String?
}
其底层也是对下层pthread_mutex的封装
NSCondition是对mutex和cond的一种封装(cond就是用于访问和操作特定类型数据的指针)wait操作会阻塞线程,使其进入休眠状态,直至超时signal操作是唤醒一个正在休眠等待的线程broadcast会唤醒所有正在等待的线程
8、NSConditionLock
NSConditionLock是条件锁,一旦一个线程获得锁,其他线程一定等待
相比NSConditionLock而言,NSCondition使用比较麻烦,所以推荐使用NSConditionLock,其使用如下
//初始化
NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:2];
//表示 conditionLock 期待获得锁,如果没有其他线程获得锁(不需要判断内部的 condition) 那它能执行此行以下代码,如果已经有其他线程获得锁(可能是条件锁,或者无条件 锁),则等待,直至其他线程解锁
[conditionLock lock];
//表示如果没有其他线程获得该锁,但是该锁内部的 condition不等于A条件,它依然不能获得锁,仍然等待。如果内部的condition等于A条件,并且 没有其他线程获得该锁,则进入代码区,同时设置它获得该锁,其他任何线程都将等待它代码的 完成,直至它解锁。
[conditionLock lockWhenCondition:A条件];
//表示释放锁,同时把内部的condition设置为A条件
[conditionLock unlockWithCondition:A条件];
// 表示如果被锁定(没获得 锁),并超过该时间则不再阻塞线程。但是注意:返回的值是NO,它没有改变锁的状态,这个函 数的目的在于可以实现两种状态下的处理
return = [conditionLock lockWhenCondition:A条件 beforeDate:A时间];
//其中所谓的condition就是整数,内部通过整数比较条件
NSConditionLock,其本质就是NSCondition + Lock,以下是其swift的底层实现,
open class NSConditionLock : NSObject, NSLocking {
internal var _cond = NSCondition()
internal var _value: Int
internal var _thread: _swift_CFThreadRef?
public convenience override init() {
self.init(condition: 0)
}
public init(condition: Int) {
_value = condition
}
open func lock() {
let _ = lock(before: Date.distantFuture)
}
open func unlock() {
_cond.lock()
_thread = nil
_cond.broadcast()
_cond.unlock()
}
open var condition: Int {
return _value
}
open func lock(whenCondition condition: Int) {
let _ = lock(whenCondition: condition, before: Date.distantFuture)
}
open func `try`() -> Bool {
return lock(before: Date.distantPast)
}
open func tryLock(whenCondition condition: Int) -> Bool {
return lock(whenCondition: condition, before: Date.distantPast)
}
open func unlock(withCondition condition: Int) {
_cond.lock()
_thread = nil
_value = condition
_cond.broadcast()
_cond.unlock()
}
open func lock(before limit: Date) -> Bool {
_cond.lock()
while _thread != nil {
if !_cond.wait(until: limit) {
_cond.unlock()
return false
}
}
_thread = pthread_self()
_cond.unlock()
return true
}
open func lock(whenCondition condition: Int, before limit: Date) -> Bool {
_cond.lock()
while _thread != nil || _value != condition {
if !_cond.wait(until: limit) {
_cond.unlock()
return false
}
}
_thread = pthread_self()
_cond.unlock()
return true
}
open var name: String?
}
通过源码可以看出
NSConditionLock是NSCondition的封装NSConditionLock可以设置锁条件,即condition值,而NSCondition只是信号的通知
调试验证
以下面代码为例,调试NSConditionLock底层流程
- (void)cjl_testConditonLock{
// 信号量
NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:2];
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
[conditionLock lockWhenCondition:1]; // conditoion = 1 内部 Condition 匹配
// -[NSConditionLock lockWhenCondition: beforeDate:]
NSLog(@"线程 1");
[conditionLock unlockWithCondition:0];
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
[conditionLock lockWhenCondition:2];
sleep(0.1);
NSLog(@"线程 2");
// self.myLock.value = 1;
[conditionLock unlockWithCondition:1]; // _value = 2 -> 1
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[conditionLock lock];
NSLog(@"线程 3");
[conditionLock unlock];
});
}
-
在
conditionLock部分打上响应断点,运行(需要在真机上运行:模拟器上运行的是Intel指令,而真机上运行的是arm指令)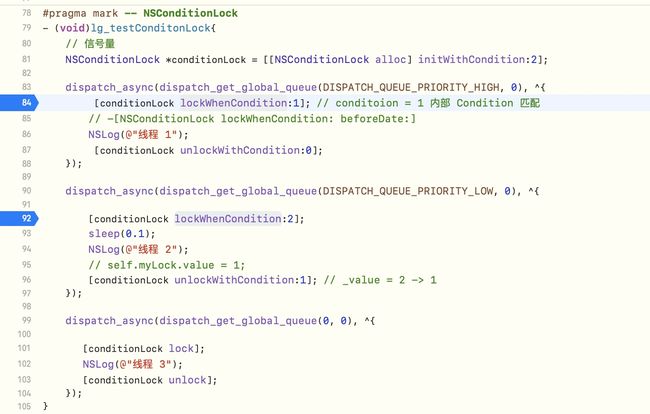
断住,开启汇编调试
-
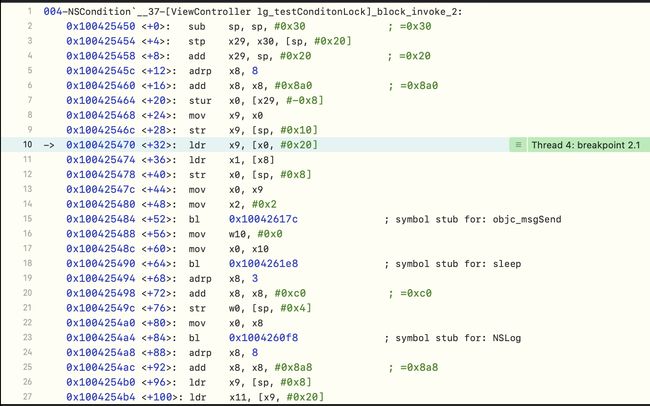
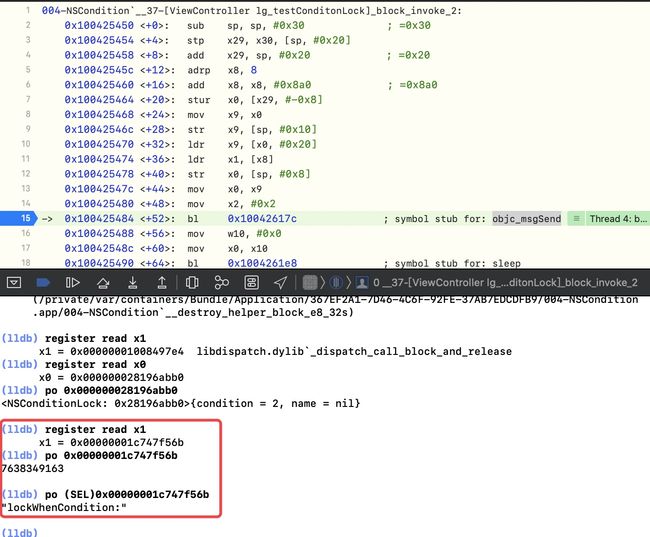
register read读取寄存器,其中x0是接收者self,x1是cmd-
在
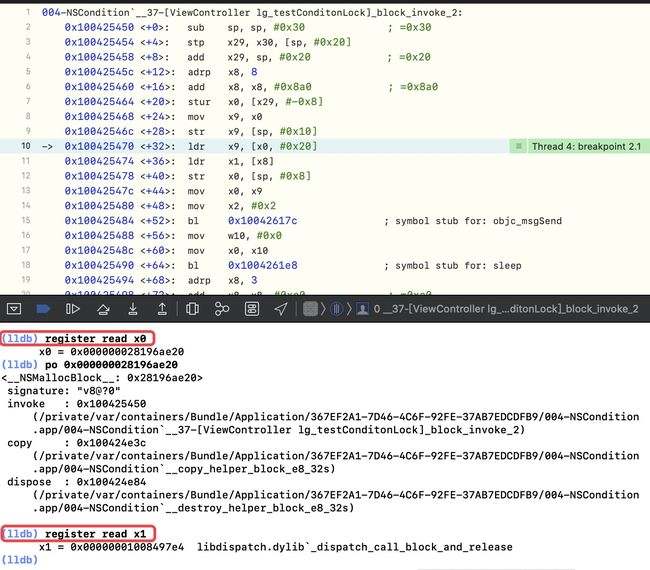
objc_msgSend处加断点,再次读寄存器 x0 --register read x0,此时执行到了[conditionLock lockWhenCondition:2];-
读x1,即
register read x1,然后发现读不出来,因为x1存储的是sel,并不是对象类型,可以通过进行强转为SEL读取-
加符号断点
-[NSConditionLock lockWhenCondition:]、-[NSConditionLock lockWhenCondition:beforeDate:],然后查看bl、b等跳转-
读取寄存器 x0、x2是当前的
lockWhenCondition:beforeDate:的参数,实际走的是[conditionLock lockWhenCondition:1];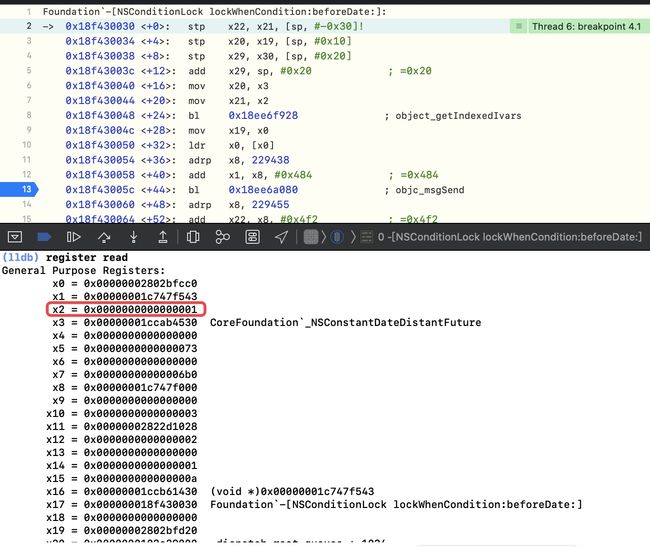 image
image -
通过汇编可知,
x2移动到了x21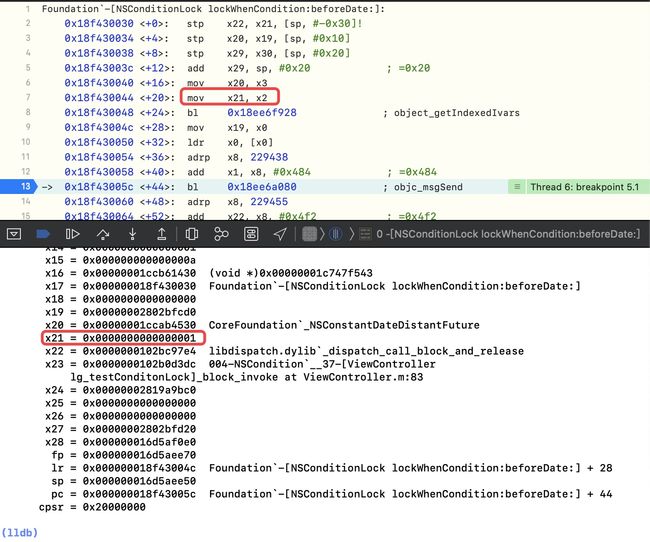
到这里后,我们调试的目的主要有两个:
NSCondition + lock以及condition与value的值匹配
NSCondition + lock验证
-
继续执行,在bl处断住,读取寄存器
x0,此时是跳转至NSCondition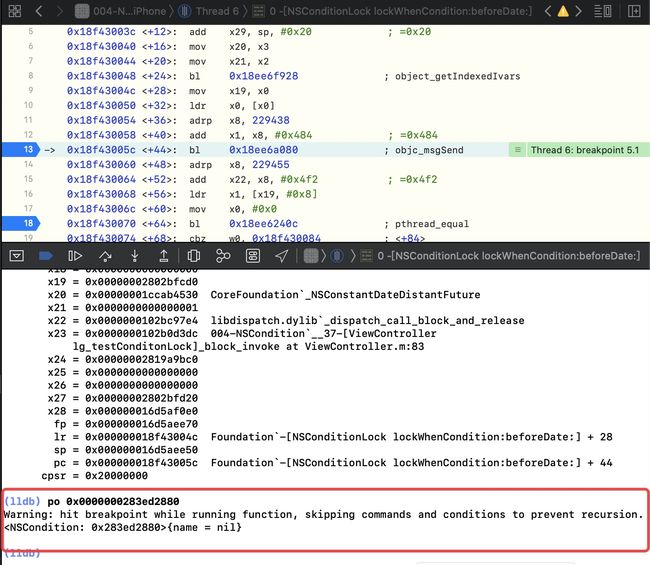
-
读取 x1,即
po (SEL)0x00000001c746e484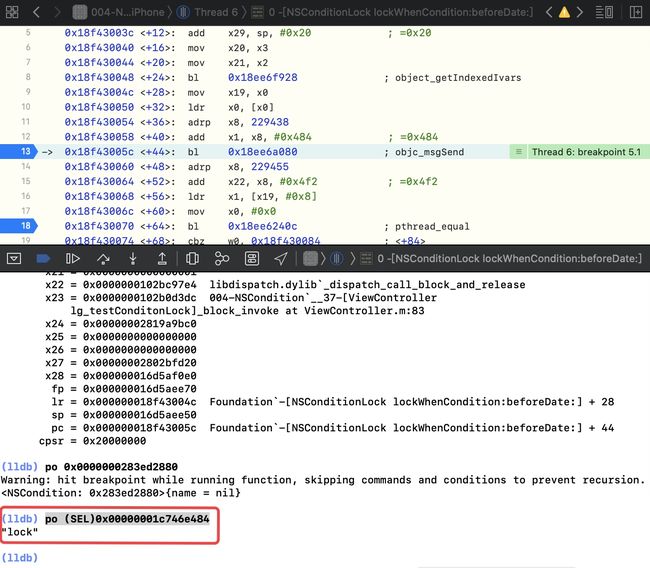
所以可以验证NSConditionLock在底层调用的是NSCondition的lock方法
condition与value的值匹配
-
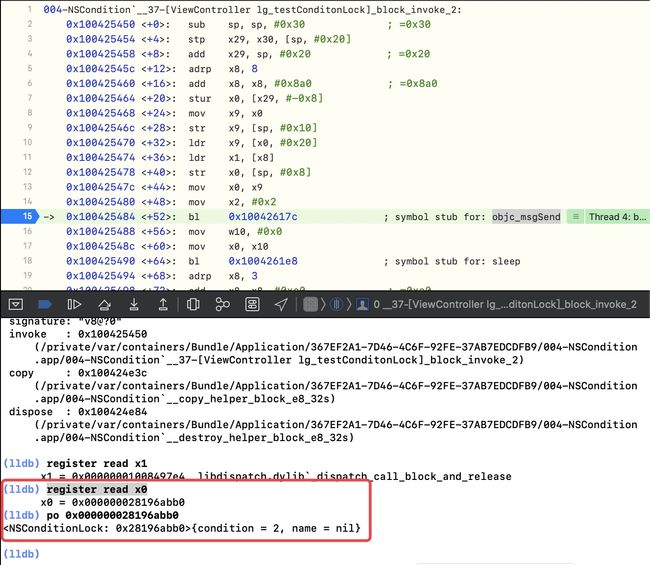
继续执行,跳到
ldr,即通过一个方法,拿到了 condition 2 的属性值,存储到x8中register read x19
-
po (SEL)0x0000000283d0d220 -- x19的地址+0x10
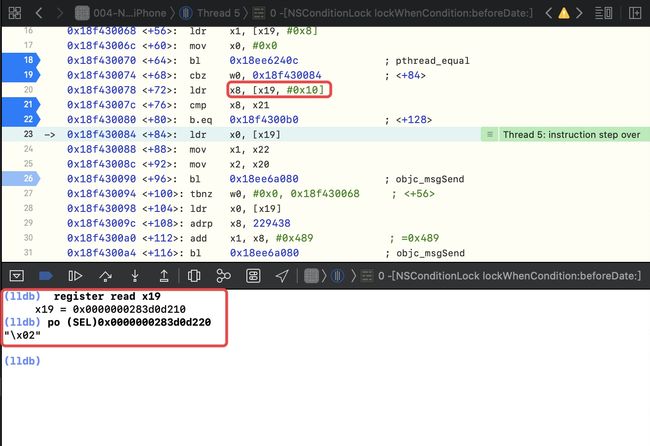
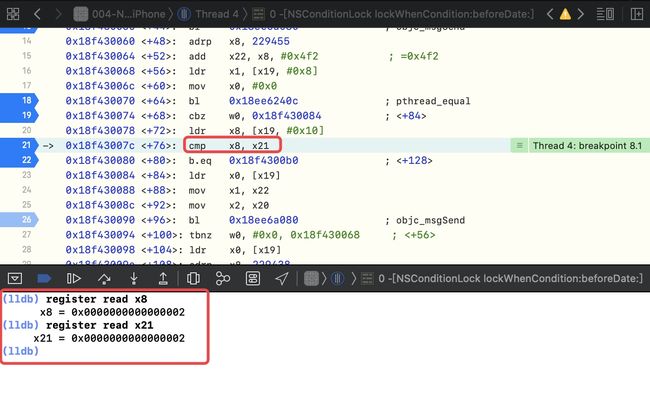
register read x8,此时的x8中存储的是 2
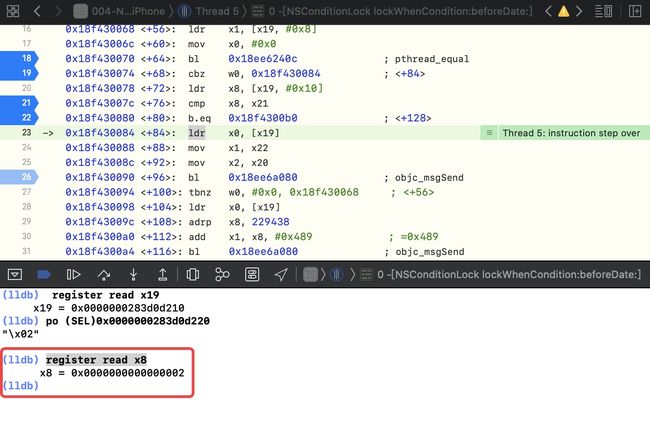
cmp x8, x21,意思是将 x8和 x21匹配,即 2 和 1匹配,并不匹配
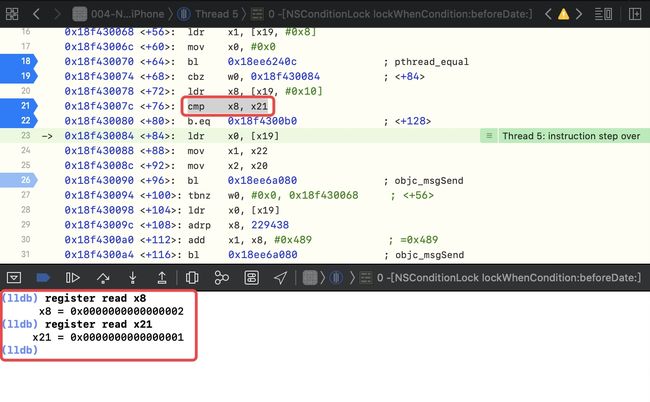
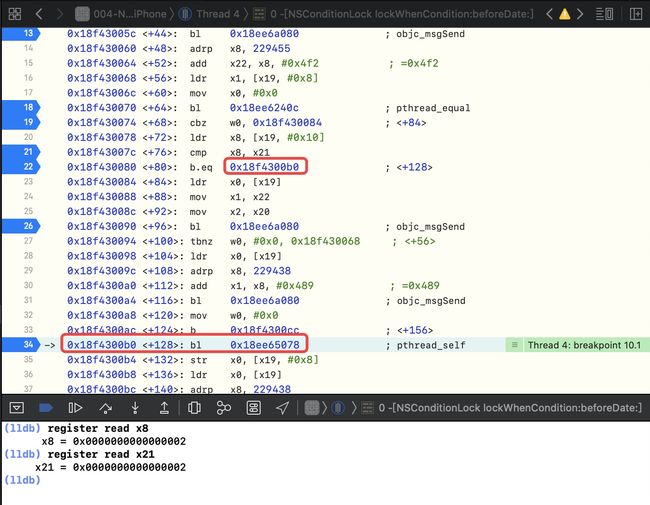
第二次来到cmp x8, x21,此时的x8、x21 是匹配的 ,即[conditionLock lockWhenCondition:2];
-
-
此时是x8 和 x21 是匹配的,通过断点也可以体现
demo分析汇总
线程 1调用[NSConditionLock lockWhenCondition:],此时此刻因为不满足当前条件,所以会进入 waiting 状态,当前进入到 waiting 时,会释放当前的互斥锁。此时当前的
线程 3 调用[NSConditionLock lock:],本质上是调用 [NSConditionLock lockBeforeDate:],这里不需要比对条件值,所以线程 3 会打印接下来
线程 2 执行[NSConditionLock lockWhenCondition:],因为满足条件值,所以线程2 会打印,打印完成后会调用[NSConditionLock unlockWithCondition:],这个时候将value 设置为 1,并发送 boradcast, 此时线程 1 接收到当前的信号,唤醒执行并打印。自此当前打印为
线程 3->线程 2 -> 线程 1[NSConditionLock lockWhenCondition:];这里会根据传入的condition 值和 Value 值进行对比,如果不相等,这里就会阻塞,进入线程池,否则的话就继续代码执行[NSConditionLock unlockWithCondition:]: 这里会先更改当前的 value 值,然后进行广播,唤醒当前的线程
性能总结
-
OSSpinLock自旋锁由于安全性问题,在iOS10之后已经被废弃,其底层的实现用os_unfair_lock替代使用
OSSpinLock及所示,会处于忙等待状态而
os_unfair_lock是处于休眠状态
-
atomic原子锁自带一把自旋锁,只能保证setter、getter时的线程安全,在日常开发中使用更多的还是nonatomic修饰属性atomic:当属性在调用setter、getter方法时,会加上自旋锁osspinlock,用于保证同一时刻只能有一个线程调用属性的读或写,避免了属性读写不同步的问题。由于是底层编译器自动生成的互斥锁代码,会导致效率相对较低nonatomic:当属性在调用setter、getter方法时,不会加上自旋锁,即线程不安全。由于编译器不会自动生成互斥锁代码,可以提高效率
@synchronized在底层维护了一个哈希表进行线程data的存储,通过链表表示可重入(即嵌套)的特性,虽然性能较低,但由于简单好用,使用频率很高NSLock、NSRecursiveLock底层是对pthread_mutex的封装NSCondition和NSConditionLock是条件锁,底层都是对pthread_mutex的封装,当满足某一个条件时才能进行操作,和信号量dispatch_semaphore类似
锁的使用场景
如果只是
简单的使用,例如涉及线程安全,使用NSLock即可在
循环嵌套中,如果对递归锁掌握的很好,则建议使用递归锁,因为性能好如果是
循环嵌套,并且还有多线程影响时,例如有等待、死锁现象时,建议使用@synchronized(因为在synchronized中无论怎么重入,都没有关系,而NSRecursiveLock可能会出现崩溃现象)