Mysql的架构及常见优化问题
一、Mysql的架构
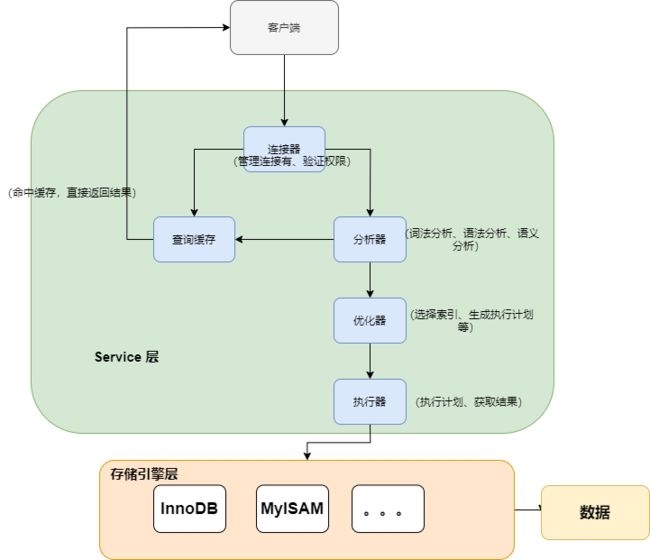
Mysql的架构主要有两层:Service层和存储引擎层。
Service层:包括 连接器、查询缓存、分析器、优化器、执行器等。包括了很多的 MySQL 功能服务、内置函数(时间、日期、数学等)。
存储引擎层:用于负责数据的存储和提取。支持多种存储引擎,早期是 MyISAM,MySQL 5.5 之后默认是 InnoDB 引擎(还有MEMORY引擎,基于内存,数据易丢失。Archive引擎)。从图中我们可以知道,不同的存储引擎共用一个 Server 层。
二、sql中select的执行底层过程
- 连接器: 当客户端连接 MySQL 时,server层会对其进行身份认证和权限校验。
- 查询缓存: 执行查询语句的时候,会先查询缓存,先校验这个 sql 是否执行过,如果有缓存这个 sql,就会直接返回给客户端,如果没有命中,就会执行后续的操作。
- 分析器: 没有命中缓存的话,SQL 语句就会经过分析器,主要分为两步,词法分析和语法分析,先看 SQL 语句要做什么,再检查 SQL 语句语法是否正确。
- 优化器: 优化器对查询进行优化,包括重写查询、决定表的读写顺序以及选择合适的索引等,生成执行计划。
- 执行器: 首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会根据执行计划去调用引擎的接口进行读取,返回结果。
三、sql语句中各个字段的执行顺序
1.你要有主表,也就要先执行from,这个是根基
2-3.然后辅助表的数据关联,关联的时候先有join,要连接什么表,然后就有了这么连接on;
这个是要排在group by,order by,where前面的,因为在group,order,where中你可以使用join中的数据,所以join肯定在前面
4.再然后就是where了,你要获取的全部数据在上面通过from和join都获取到了,要做第一步筛选,得到你想要的数据
5.再之后就是使用Group by进行分组,这个的顺序考虑从语义上,你现有你要分组的数据才能分组,前面的from,join,where等都是为了确定获取数据的
6.而后的having就是对你分组的数据再一次筛选,肯定是要在分组数据之后的(注意:虽然执行顺序是having之后才执行select,但经过实践发现:having后面也可以使用select中的字段别名。)
7.再往后select排在order by前面是因为order by的数据排序是要根据select中的内容来的,平时你可能没感觉,但是当你使用group by分组后,你会发现,select中没有字段是不能用来排序的,验证了select在order by之前
8.然后就是order by了对获取的数据进行指定规则的排序,前面的过程都完成才能对总数据进行排序,否则也没法排序
9.limit排在最后原因是,limit是要获取当前数据中指定范围内的数据,所以数据要先有序才能进行指定范围内数据获取,所以limit要在orderby之后
总结:首先执行 from 子句,选择student数据库表;------->然后进行join操作,因为在where中可以使用join中的数据------>然后执行where 子句基于指定的条件对记录行进行筛选,上述代码中给的条件选出来的是所有信息;------->然后执行group by 子句将数据划分为多个分组,sex组;------->使用聚集函数进行计算;将计算出来的count(sex)结果重命名为total------->使用having 子句筛选分组,选出数量>1的;-------->计算所有的表达式;------>select 的字段;------->使用order by 对结果集进行排序------>使用limit对输出数据进行限制。
四、一条sql语句慢,你会怎么优化,有什么思路
一:Mysql角度
(1)索引角度
先使用explain+sql查询语句查看是否有索引,以及是否使用了。没有索引,给该字段加上索引;有索引没用上,查看sql书写是否没命中。执行explain后,有一个字段是type,如果为all,就说明进行了全表扫描;有一个key字段,指命中索引的名字。
索引失效:1)模糊查询的%放在了前面;2)联合索引没有遵循最左匹配原则;3)is null或者!=操作,可以使用默认值0来操作;4)对索引列进行了表达式操作c+1=2;5)使用了or操作符,可使用union all代替;6)varchar类型的字段筛选时没有加引号。
注:select count(*) from artist where name like '%Queen%' 替换为:
select count(*) from artist a join (select aritst_id from artist where name like '%Queen%') b on a.artist_id = b.artist_id
aritst_id 为主键索引。
(2)sql操作角度
1)避免select *,需要什么选什么;
2)union all代替union;
3) join/left join操作代替in子查询,因为子查询需要创建临时表,查询完毕之后再销毁,多了一个临时表的创建和销毁;
4)能否使用small int (2)代替int(4),varchar代替char。
二、Hive的角度
mysql的优化手段有的同样适用。
优化的核心思想:配置优化、SQL语句优化、任务优化等方案。
主要是sql语句的优化:减少数据量,避免数据倾斜,减少job数。
减少数据量
1、分区裁剪
适用分区过滤,并且有left join操作时,要把过滤写在on中,防止全表扫描,并且过滤null值,防止数据倾斜。
2、用group by +count代替count(distinct ),虽然多了一个job,但是可取的;
3、除了shuffle耗时外,子查询也耗时,使用with aa as语句将子查询先提取出来,类似于临时表,别的查询模块都可以调用这个结果,并且有利于避免该子查询的重复计算;
4、列裁剪
只选取自己需要的列。
5、多个表join时,join的key一样的话,只产生一个job;
避免数据倾斜
1、Key值分布不均匀
(1)join的时候,有null值,要提前过滤或者nvl(a, rand())随机值的方式打散;(inner join自动过滤null;
(2)join的时候,本身key值分布不均匀:开启两端聚合。
2、参考另一篇博客;