# 在线教育项目——数仓实战(三)之访问咨询主题看板(全量流程)
文章目录
-
- 1. 需求分析
- 2. 业务数据准备
- 3. 建模分析
- 4. 建模操作
-
- 4.1 数据存储格式和压缩方案
- 4.2 全量和增量
- 4.3 Hive分区
- 4.4 建模操作
- 5. Hive的基础优化(目前无需更改)
-
- 5.1 HDFS的副本数量
- 5.2 yarn的基础配置
- 5.3 MapReduce基础配置
- 5.4 Hive的基础配置
- 5.5 Hive压缩的配置
- 5.6 Hive的执行引擎切换
- 6. 数据采集
- 7. 数据清洗转换
- 8. 数据分析
- 9. 数据导出
1. 需求分析
-
将调研需求转换为开发需求
-
如何转换?
将每一个需求中涉及到维度以及涉及到指标从需求中分析出来, 同时找到涉及到那些表, 以及那些字段 -
目的:
涉及维度
涉及指标
涉及表
涉及字段
在此基础上, 还需要找到需要清洗那些数据, 需要转换那些数据, 如果有多个表, 表与表关联条件是什么…
-
-
需求一: 统计指定时间段内,访问客户的总数量。能够下钻到小时数据
-
涉及维度:
时间维度 : 年 季度 月 天 小时 -
涉及指标:
访问量 -
涉及表:
web_chat_ems_2019_12 (事实表) -
涉及字段:
-
时间维度: create_time
转换操作: 将create_time后期转换为 yearinfo , quarterinfo,monthinfo,dayinfo,hourinfo
思想: 当发现一个字段中涵盖多个字段的数据时候, 可以尝试将其拆分出来
-
指标字段: sid
说明: 先去重再进行统计操作
-
-
-
需求二: 统计指定时间段内,访问客户中各区域人数热力图。能够下钻到小时数据。
- 涉及维度:
时间维度: 年 季度 月 天 小时
区域维度 - 涉及指标:
访问量 - 涉及表:
web_chat_ems_2019_12 - 涉及字段:
- 时间维度: create_time
- 区域维度: area
- 指标字段: sid
- 涉及维度:
-
需求三: 统计指定时间段内,不同地区(省、市)访问的客户中发起咨询的人数占比;
咨询率=发起咨询的人数/访问客户量;客户与网咨有说一句话的称为有效咨询。
- 涉及维度:
时间维度: 年 季度 月 天
地区维度 - 涉及指标:
咨询人数
访问量 (在需求二中已经计算完成了, 此处可以省略) - 涉及表:
web_chat_ems_2019_12 - 涉及字段:
- 时间维度: create_time
- 地区维度: area
- 指标字段: sid
- 区分咨询人数: msg_count 必须 >= 1
- 说明:
当遇到指标需要计算比率问题的, 一般的处理方案是只需要计算其分子和分母的指标, 在最后DWS以及DA层进行统计计算
- 涉及维度:
-
需求四: 统计指定时间段内,每日客户访问量/咨询率双轴趋势图。能够下钻到小时数据。
- 涉及维度:
时间维度: 年 季度 月 天 小时 - 涉及指标:
访问量 (需求一, 已经计算完成, 不需要关心)
咨询人数 - 涉及表:
web_chat_ems_2019_12 - 涉及字段:
- 时间维度: create_time
- 指标字段: sid
- 区分咨询人数: msg_count 必须 >= 1
- 涉及维度:
-
需求五: 统计指定时间段内,1-24h之间,每个时间段的访问客户量。
横轴:1-24h,间隔为一小时,纵轴:指定时间段内同一小时内的总访问客户量。
- 涉及维度:
时间维度: 天 小时 - 涉及指标:
访问量 (需求一, 已经实现了)
- 涉及维度:
-
需求六: 统计指定时间段内,不同来源渠道的访问客户量占比。能够下钻到小时数据。
占比:
各个渠道访问量 / 总访问量
各个渠道下 咨询量/访问量占比
- 涉及维度:
时间维度: 年 季度 月 天 小时
各个渠道 - 涉及指标:
咨询量
访问量 - 涉及表:
web_chat_ems_2019_12 - 涉及字段:
- 各个渠道字段: origin_channel
- 时间维度: create_time
- 指标: sid
- 访问量和咨询量的划分:
msg_count >= 1
- 涉及维度:
-
需求七: 统计指定时间段内,不同搜索来源的访问客户量占比。能够下钻到小时数据。
占比:
各个搜索来源访问量 / 总访问量
各个搜索来源下 咨询量 / 各个搜索来源访问量
- 涉及维度:
时间维度: 年 季度 月 天 小时
不同搜索来源 - 涉及指标:
访问量 - 涉及表:
web_chat_ems_2019_12 - 涉及字段:
- 搜索来源: seo_source
- 时间维度: create_time
- 指标字段: sid
- 涉及维度:
-
需求八: 统计指定时间段内,产生访问客户量最多的页面排行榜TOPN。能够下钻到小时数据。
- 涉及维度:
时间维度: 年 季度 月 天 小时
各个页面 - 涉及指标:
访问量 - 涉及表:
web_chat_text_ems_2019_11(事实表) - 涉及字段:
- 各个页面: from_url
- 指标字段: count(1)
- 缺失: 时间维度字段
- 解决方案:
1) 查看这个表中是否有时间字段
2) 如果没有, 这个表是否与另一个表有关联
3) 如果都解决不了, 找需求方
- 解决方案:
- 涉及维度:
-
汇总:
-
涉及维度:
- 固有维度:
时间维度: 年 季度 月 天 小时 - 产品属性维度:
地区维度
来源渠道
搜索来源
受访页面
- 固有维度:
-
涉及指标:
- 访问量
- 咨询量
-
涉及表 :
- 事实表: web_chat_ems_2019_12 和 web_chat_text_ems_2019_11
- 维度表: 没有 (数仓建模, 不需要DIM层)
-
涉及字段:
- 时间维度:
web_chat_ems: create_time - 地区维度:
web_chat_ems: area - 来源渠道:
web_chat_ems: origin_channel - 搜索来源:
web_chat_ems: seo_source - 受访页面:
web_chat_text_ems: from_url - 指标字段:
访问量: sid
咨询量: sid
- 时间维度:
-
区分访问和咨询:
web_chat_ems: msg_count >= 1 即为咨询数据
-
是否需要清洗数据: 不需要
-
需要转换的字段: 时间字段
需要将create_time 转换为 yearinfo, quarterinfo,monthinfo,dayinfo,hourinfo -
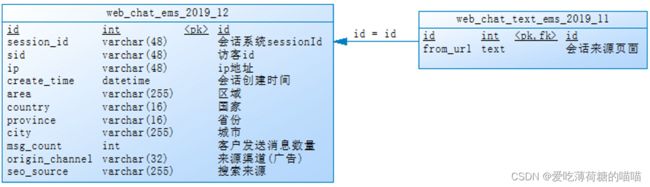
一对一关系 : id = id
一对一关系其实本质就是一张表
-
2. 业务数据准备
-
两个表关系图:
-
第一步: 在hadoop01的mysql中建一个数据库
create database nev default character set utf8mb4 collate utf8mb4_unicode_ci;
-
第二步: 将项目资料中 nev.sql 脚本数据导入到nev数据库中(mysql)
此准备工作在实际生产环境中是不存在的
3. 建模分析
建模: 如何在hive中构建各个层次的表
-
ODS层: 源数据层
-
作用: 对接数据源, 一般和数据源保持相同的粒度(将数据源数据完整的拷贝到ODS层)
-
建表比较简单:
业务库中对应表有那些字段, 需要在ODS层建一个与之相同字段的表即可, 额外在建表的时候, 需要构建为分区表, 分区字段为时间字段, 用于标记在何年何月何日将数据抽取到ODS层 -
此层会有两个表
-
-
DIM层: 维度层
- 作用: 存储维度表数据
- 此时不需要, 因为当前主题, 压根没有维度表
-
DWD层: 明细层
-
作用: 1) 清洗转换 2) 少量维度退化
-
当前需要做什么清洗操作?
不需要进行清洗 -
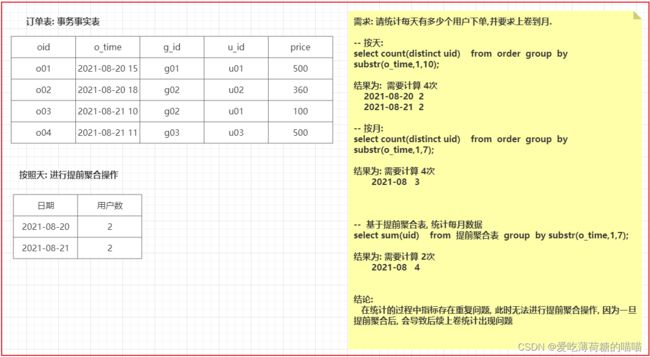
当前需要进行什么提前聚合操作?
可以尝试先对小时进行提前聚合操作, 以便于后统计方便 -
当前主题是否可以按照小时提前聚合呢?
目前不可以, 因为数据存在重复的问题, 无法提前聚合, 一旦聚合后, 会导致后续的统计出现不精确问题sid,session_id,ip,create_time,area,origin_channel,seo_source,
from_url,msg_count,yearinfo,quarterinfo,monthinfo,dayinfo,
hourinfo,referrer,landing_page_url,url_title,
platform_description,other_params,history -
思想:
当合并多个表的时候, 获取抽取的数据时, 处理方案有三种:- 当表中字段比较多的时候, 只需要抽取需要用的字段
- 当无法确定需要用那些字段的时候, 采用全部抽取
- 如果表中字段比较少, 不管用得上, 还是用不上, 都抽取
-
-
DWM层: 中间层 (省略)
- 作用: 1) 维度退化操作 2) 提前聚合
- 当前需要进行什么维度退化操作?
没有任何维度退化操作, 压根都没有DIM层 - 当前需要进行什么提前聚合操作?
可以尝试先对小时进行提前聚合操作, 以便于后统计方便 - 当前主题是否可以按照小时提前聚合呢?
目前不可以, 因为数据存在重复的问题, 无法提前聚合, 一旦聚合后, 会导致后续的统计出现不精确问题
-
DWS层: 业务层
-
作用: 细化维度统计操作
-
一般是一个指标会对应一个统计结果表
-
访问量:
-
涉及维度:
- 固有维度:
时间维度: 年 季度 月 天 小时 - 产品属性维度:
地区维度
来源渠道
搜索来源
受访页面
- 固有维度:
-
建表字段: 指标统计字段 + 各个维度字段 + 三个经验字段(time_type,group_time,time_str)
sid_total,sessionid_total,ip_total,yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,
area,origin_channel,seo_source,from_url, time_type,group_time,time_str
-
-
咨询量:
-
涉及维度:
- 固有维度:
时间维度: 年 季度 月 天 小时 - 产品属性维度:
地区维度
来源渠道
- 固有维度:
-
建表字段: 指标统计字段 + 各个维度字段 + 三个经验字段(time_type,group_time,time_str)
sid_total,sessionid_total,ip_total,yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,
area,origin_channel, time_type,group_time,time_str
-
注意: 如果不存在的维度字段的值, 设置为 -1 (业务指定, 表示没有这个维度)
-
-
DA层:
- 作用: 对接应用, 应用需要什么数据, 从DWS层获取什么数据即可
此层目前不做任何处理, 已经全部需要都细化统计完成了, 后续具体用什么, 看图表支持了
4. 建模操作
思考: 在创建表的时候, 需要考虑那些问题呢?
- 表需要采用什么存储格式
- 表需要采用什么压缩格式
- 表需要构建什么类型表
4.1 数据存储格式和压缩方案
-
存储格式选择:
- 情况一: 如果数据不是来源于普通文本文件的数据, 一般存储格式选择为列式的ORC存储
- 情况二: 如果数据来源于普通文本文件的数据, 一般存储格式选择为行式的textFile格式
当前项目: 数据是存储在mysql中, 选择为ORC存储格式
-
压缩方案选择:
- 写多,读少: 优先考虑压缩比 建议选择 zlib gz
- 写多,读多: 优先考虑解压缩性能 建议选择 snappy LZO
- 如果空间比较充足, 建议各个层次都选择snappy压缩方案
- 一般情况下:
hive中ODS层, 选择 zlib 压缩方案
hive中其他层次, 选择 snappy - 当前项目:
ODS: zlib
其他层次: snappy
最终:
ODS: orc + zlib
其他层次: orc + snappy
4.2 全量和增量
在进行数据统计分析的时候, 一般来说, 第一次统计分析都是全量统计分析 而后续的操作, 都是在结果基础上进行增量化统计操作
-
全量统计
需要面对公司所有的数据进行统计分析, 数据体量一般比较大的
解决方案: 采用分批次执行(比如按年) -
增量统计
一般是以T+1模式统计, 当天的数据, 在第二天才会进行统计操作
每一天都是统计上一天的数据
4.3 Hive分区
思考: 分区表有什么作用呢?
当查询的时候, 指定分区字段, 可以减少查询表数据扫描量, 从而提升效率
-
回顾: 内部表和外部表如何选择呢?
判断当前这份数据是否具有绝对的控制权
-
如何向分区表添加数据呢?
-
静态分区:
格式:
load data [local] inpath ‘路径’ into table 表名 partition(分区字段=值…)
insert into table 表名 partition(分区字段=值…) + select语句 -
动态分区:
格式:
insert into table 表名 partition(分区字段1,分区字段2…) + select语句注意事项:
1) 必须开启hive对动态分区的支持:
2) 必须开启hive的非严格模式
3) 保证select语句的最后的字段必须是分区字段数据(保证顺序)
insert into table order partition(yearinfo,monthinfo,dayinfo)
select … yearinfo,monthinfo,dayinfo from xxx; -
动静混合:
格式:
insert into table 表名 partition(分区字段1,分区字段2=值1,分区字段3…) + select语句注意事项:
1) 必须开启hive对动态分区的支持:
2) 必须开启hive的非严格模式
3) 保证select语句的最后的字段必须是动态分区字段数据(保证顺序)
insert into table order partition(yearinfo,monthinfo=‘05’,dayinfo)
select … yearinfo,dayinfo from xxx; -
-
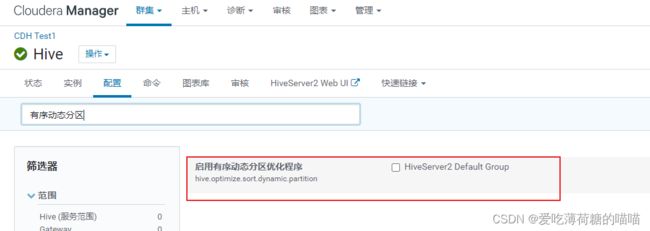
动态分区的优化点: 有序动态分区
- 什么时候需要优化?
有时候表中动态分区比较多, hive提升写入效率, 会启动多个reduce程序进行并行写入操作, 此时对内存消耗比较大, 有可能会出现内存溢出问题 - 解决方案: 开启有序动态分区
开启后, reduce不会再并行运行了, 只会运行一个, 大大降低了内存消耗, 从而能够正常的运行完成,但是效率会降低 - 需要在CM的hive的配置窗口下, 开启此配置
- 注意: 目前不改, 后续出现动态分区问题后, 再尝试开启
- 通过CM更改, 是全局更改, 是全局有效的, 相当于直接在hive-site.xml中更改
- 什么时候需要优化?
4.4 建模操作
- ODS层
CREATE DATABASE IF NOT EXISTS `itcast_ods`;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 访问咨询表
CREATE EXTERNAL TABLE IF NOT EXISTS itcast_ods.web_chat_ems (
id INT comment '主键',
create_date_time STRING comment '数据创建时间',
session_id STRING comment '七陌sessionId',
sid STRING comment '访客id',
create_time STRING comment '会话创建时间',
seo_source STRING comment '搜索来源',
seo_keywords STRING comment '关键字',
ip STRING comment 'IP地址',
area STRING comment '地域',
country STRING comment '所在国家',
province STRING comment '省',
city STRING comment '城市',
origin_channel STRING comment '投放渠道',
user_match STRING comment '所属坐席',
manual_time STRING comment '人工开始时间',
begin_time STRING comment '坐席领取时间 ',
end_time STRING comment '会话结束时间',
last_customer_msg_time_stamp STRING comment '客户最后一条消息的时间',
last_agent_msg_time_stamp STRING comment '坐席最后一下回复的时间',
reply_msg_count INT comment '客服回复消息数',
msg_count INT comment '客户发送消息数',
browser_name STRING comment '浏览器名称',
os_info STRING comment '系统名称')
comment '访问会话信息表'
PARTITIONED BY(starts_time STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orc
location '/user/hive/warehouse/itcast_ods.db/web_chat_ems_ods'
TBLPROPERTIES ('orc.compress'='ZLIB');
-- 访问咨询附属表
CREATE EXTERNAL TABLE IF NOT EXISTS itcast_ods.web_chat_text_ems (
id INT COMMENT '主键来自MySQL',
referrer STRING comment '上级来源页面',
from_url STRING comment '会话来源页面',
landing_page_url STRING comment '访客着陆页面',
url_title STRING comment '咨询页面title',
platform_description STRING comment '客户平台信息',
other_params STRING comment '扩展字段中数据',
history STRING comment '历史访问记录'
) comment 'EMS-PV测试表'
PARTITIONED BY(start_time STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orc
location '/user/hive/warehouse/itcast_ods.db/web_chat_text_ems_ods'
TBLPROPERTIES ('orc.compress'='ZLIB');
- DWD层:
CREATE DATABASE IF NOT EXISTS `itcast_dwd`;
create table if not exists itcast_dwd.visit_consult_dwd(
session_id STRING comment '七陌sessionId',
sid STRING comment '访客id',
create_time bigint comment '会话创建时间',
seo_source STRING comment '搜索来源',
ip STRING comment 'IP地址',
area STRING comment '地域',
msg_count int comment '客户发送消息数',
origin_channel STRING COMMENT '来源渠道',
referrer STRING comment '上级来源页面',
from_url STRING comment '会话来源页面',
landing_page_url STRING comment '访客着陆页面',
url_title STRING comment '咨询页面title',
platform_description STRING comment '客户平台信息',
other_params STRING comment '扩展字段中数据',
history STRING comment '历史访问记录',
hourinfo string comment '小时'
)
comment '访问咨询DWD表'
partitioned by(yearinfo String,quarterinfo string, monthinfo String, dayinfo string)
row format delimited fields terminated by '\t'
stored as orc
location '/user/hive/warehouse/itcast_dwd.db/visit_consult_dwd'
tblproperties ('orc.compress'='SNAPPY');
- DWS层
CREATE DATABASE IF NOT EXISTS `itcast_dws`;
-- 访问量统计结果表
CREATE TABLE IF NOT EXISTS itcast_dws.visit_dws (
sid_total INT COMMENT '根据sid去重求count',
sessionid_total INT COMMENT '根据sessionid去重求count',
ip_total INT COMMENT '根据IP去重求count',
area STRING COMMENT '区域信息',
seo_source STRING COMMENT '搜索来源',
origin_channel STRING COMMENT '来源渠道',
hourinfo STRING COMMENT '创建时间,统计至小时',
time_str STRING COMMENT '时间明细',
from_url STRING comment '会话来源页面',
groupType STRING COMMENT '产品属性类型:1.地区;2.搜索来源;3.来源渠道;4.会话来源页面;5.总访问量',
time_type STRING COMMENT '时间聚合类型:1、按小时聚合;2、按天聚合;3、按月聚合;4、按季度聚合;5、按年聚合;')
comment 'EMS访客日志dws表'
PARTITIONED BY(yearinfo STRING,quarterinfo STRING,monthinfo STRING,dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orc
location '/user/hive/warehouse/itcast_dws.db/visit_dws'
TBLPROPERTIES ('orc.compress'='SNAPPY');
-- 咨询量统计结果表
CREATE TABLE IF NOT EXISTS itcast_dws.consult_dws
(
sid_total INT COMMENT '根据sid去重求count',
sessionid_total INT COMMENT '根据sessionid去重求count',
ip_total INT COMMENT '根据IP去重求count',
area STRING COMMENT '区域信息',
origin_channel STRING COMMENT '来源渠道',
hourinfo STRING COMMENT '创建时间,统计至小时',
time_str STRING COMMENT '时间明细',
groupType STRING COMMENT '产品属性类型:1.地区;2.来源渠道',
time_type STRING COMMENT '时间聚合类型:1、按小时聚合;2、按天聚合;3、按月聚合;4、按季度聚合;5、按年聚合;'
)
COMMENT '咨询量DWS宽表'
PARTITIONED BY (yearinfo string,quarterinfo STRING, monthinfo STRING, dayinfo string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/user/hive/warehouse/itcast_dws.db/consult_dws'
TBLPROPERTIES ('orc.compress'='SNAPPY');
5. Hive的基础优化(目前无需更改)
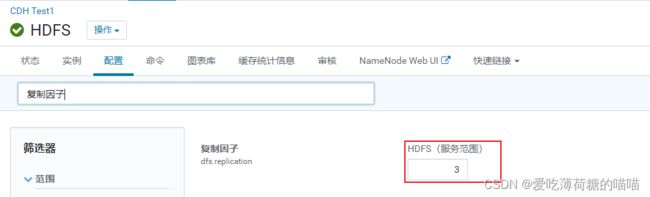
5.1 HDFS的副本数量
-
默认情况HDFS的副本有 3 个副本
实际生产环境中, 一般HDFS副本也是以3个
如果数据不是特别重要, 也可以设置为只有2个副本如果使用hadoop3.x以上的版本, 支持设置副本数量为 1.5
其中 0.5 不是指的存储了一半, 而是采用纠删码来存储这一份数据的信息, 而纠删码只占用数据的一半 -
如何配置副本数量: 直接在CM上HDFS的配置目录下配置
5.2 yarn的基础配置
yarn: 用于资源的分配 (资源: 内存 CPU)
其中 nodemanager 用于出内存和CPU
其中datanode 用于出磁盘
-
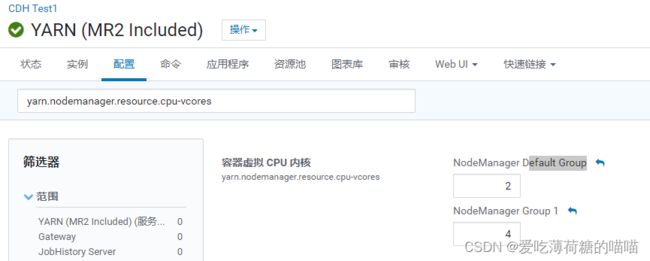
cpu的配置
- 注意: 每一个nodemanager 会向resourcemanager报告自己当前节点有多少核心数
- 默认: 8核 yarn不会自动校验每一个节点有多少核CUP
- 推荐调整配置: 当前节点有多少核, 就要向resourcemanager汇报多少核
- 如何查看当前这个节点有多少核呢?
方式一: 通过CM的主机目录来查看每一节点有多少核
方式二: 通过命令的方式来查看
grep ‘processor’ /proc/cpuinfo | sort -u | wc -l - 如何在yarn中配置各个节点的核心数呢?
直接在cm的yarn的配置目录下搜索: yarn.nodemanager.resource.cpu-vcores
-
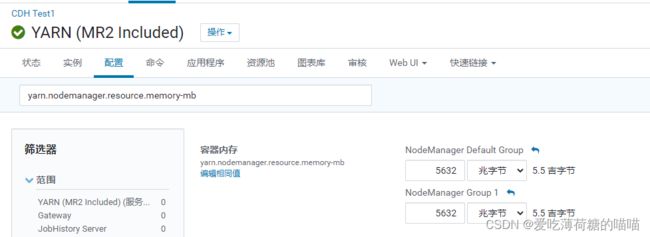
内存配置
- 注意: 每一个nodemanager 会向resourcemanager报告自己当前节点有多少内存
- 默认: 8GB yarn不会自动校验每一个节点有多少内存
- 推荐配置: 剩余内存 * 80%
- 如何知道当前节点内存还剩余多少呢?
- 通过CM的主机目录来查看每一节点有多少剩余内存
- 通过命令方式查看:
free -m
- 如何配置各个节点内存:
直接在cm的yarn的配置目录下搜索:
yarn.nodemanager.resource.memory-mb
yarn.scheduler.maximum-allocation-mb : 与第一个保持一致
yarn.app.mapreduce.am.command-opts : 略小于第一个配置的值(0.9) - 注意,要同时设置yarn.scheduler.maximum-allocation-mb为一样的值,yarn.app.mapreduce.am.command-opts(JVM内存)的值要同步修改为略小的值(-Xmx1024m)。
-
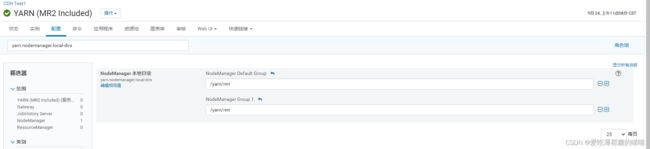
yarn本地目录的配置
- 配置项:yarn.nodemanager.local-dirs
- 推荐配置: 当前服务器挂载了几块磁盘, 就需要配置几个目录
- 目的: yarn在运行的过程中, 会产生一些临时文件, 这些临时文件应该存储在那些位置呢? 由这个本地目录配置决定
- 如何查看每一个磁盘挂载到了linux的什么目录下:
df -h 查看对应磁盘挂载点即可
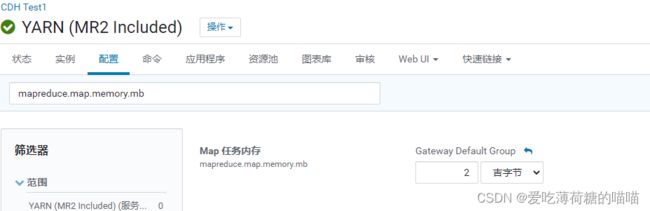
5.3 MapReduce基础配置
- mapreduce.map.memory.mb : 在运行MR的时候, 一个mapTask需要占用多大内存
- mapreduce.map.java.opts : 在运行MR的时候, 一个mapTask对应jvm需要占用多大内容
- mapreduce.reduce.memory.mb: 在运行MR的时候, 一个reduceTask需要占用多大内存
- mapreduce.reduce.java.opts : 在运行MR的时候, 一个reduceTask对应jvm需要占用多大内容
注意:
jvm的内存配置要略小于对应内存
所有内存配置大小, 不要超过nodemanager的内存大小此处推荐:
一般不做任何修改 默认即可
5.4 Hive的基础配置
-
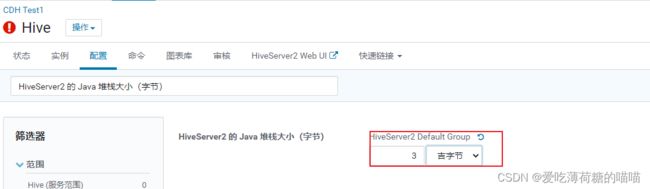
hiveserver2的内存大小配置
配置项: HiveServer2 的 Java 堆栈大小(字节)
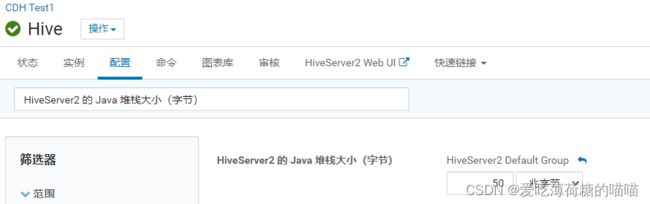
说明: 如果这个配置比较小, 在执行SQL的时候, 就会出现以下的问题:
此错误, 说明hiveserver2已经宕机了, 此时需要调整hiveserver2的内存大小,调整后, 重启

-
动态生成分区的线程数
- 配置: hive.load.dynamic.partitions.thread
- 说明:
在执行动态分区的时候, 最多允许多少个线程来运行动态分区操作, 线程越多 , 执行效率越高, 但是占用资源越大 - 默认值: 15
- 推荐:
先采用默认, 如果动态分区执行慢, 而且还有剩余资源, 可以尝试调大 - 调整位置:
直接在cm的hive的配置目录下调整
-
监听输入文件的线程数量
- 配置项: hive.exec.input.listing.max.threads
- 说明:
在运行SQL的时候, 可以使用多少个线程读取HDFS上数据, 线程越多, 读取效率越高, 占用资源越大 - 默认值: 15
- 推荐:
先采用默认, 如果读取数据执行慢, 而且还有剩余资源, 可以尝试调大
5.5 Hive压缩的配置
map中间结果压缩配置:
建议: 在hive的会话窗口配置 (set 配置=true;)
hive.exec.compress.intermediate: 是否hive对中间结果压缩以下两个建议直接在cm上yarn的配置目录下直接配置
mapreduce.map.output.compress : 是否开启map阶段的压缩
mapreduce.map.output.compress.codec : 选择什么压缩方案
推荐配置:
org.apache.hadoop.io.compress.SnappyCodec
reduce最终结果压缩配置:
建议: 在hive的会话窗口配置 (set 配置=true;)
hive.exec.compress.output: 是否开启对hive最终结果压缩配置以下建议直接在cm上yarn的配置目录下直接配置
- mapreduce.output.fileoutputformat.compress: 是否开启reduce端压缩配置
- mapreduce.output.fileoutputformat.compress.codec: 选择什么压缩方案
推荐配置:
org.apache.hadoop.io.compress.SnappyCodec- mapreduce.output.fileoutputformat.compress.type : 压缩方案
推荐配置:
BLOCK
说明:
如果hive上没有开启压缩, 即使配置MR的压缩, 那么也不会生效
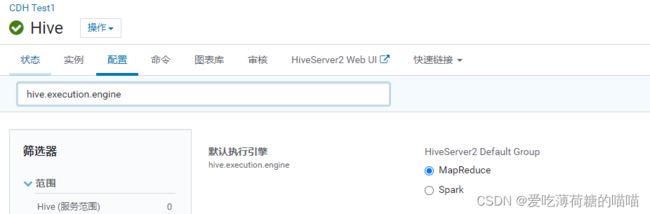
5.6 Hive的执行引擎切换
配置项: hive.execution.engine
6. 数据采集
目的: 将业务端的数据导入到ODS层对应表中
- 业务端数据: mysql
- ODS层表: hive
- 如何将mysql的数据灌入到hive中: apache sqoop
导入数据的SQL语句(无需执行)
-- 访问咨询主表:
SELECT
id,create_date_time,session_id,sid,create_time,seo_source,seo_keywords,ip,
AREA,country,province,city,origin_channel,USER AS user_match,manual_time,begin_time,end_time,
last_customer_msg_time_stamp,last_agent_msg_time_stamp,reply_msg_count,
msg_count,browser_name,os_info, '2021-09-24' AS starts_time
FROM web_chat_ems_2019_07
-- 访问咨询附属表
SELECT
*, '2021-09-24' AS start_time
FROM web_chat_text_ems_2019_07
执行sqoop脚本, 完成数据采集
-- 访问咨询主表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/nev \
--username root \
--password 123456 \
--query 'SELECT
id,create_date_time,session_id,sid,create_time,seo_source,seo_keywords,ip,
AREA,country,province,city,origin_channel,USER AS user_match,manual_time,begin_time,end_time,
last_customer_msg_time_stamp,last_agent_msg_time_stamp,reply_msg_count,
msg_count,browser_name,os_info, "2021-09-24" AS starts_time
FROM web_chat_ems_2019_07 where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_ems \
-m 1
-- 访问咨询附属表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/nev \
--username root \
--password 123456 \
--query 'SELECT
*, "2021-09-24" AS start_time
FROM web_chat_text_ems_2019_07 where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_text_ems \
-m 1
校验数据是否导入成功
1) 查看mysql共计有多少条数据
SELECT COUNT(1) FROM web_chat_ems_2019_07; 211197
SELECT COUNT(1) FROM web_chat_text_ems_2019_07; 105599
2) 到hive中对表查询一下一共多少条数据
SELECT COUNT(1) FROM itcast_ods.web_chat_ems; 211197
SELECT COUNT(1) FROM itcast_ods.web_chat_text_ems; 105599
3) 查询其中一部分数据, 观察数据映射是否OK
select * from itcast_ods.web_chat_ems limit 10;
SELECT * FROM itcast_ods.web_chat_text_ems limit 10;
可能报出以下错误:

从cm上查看hive的hiveserver2的服务, 服务给出的报错信息为:
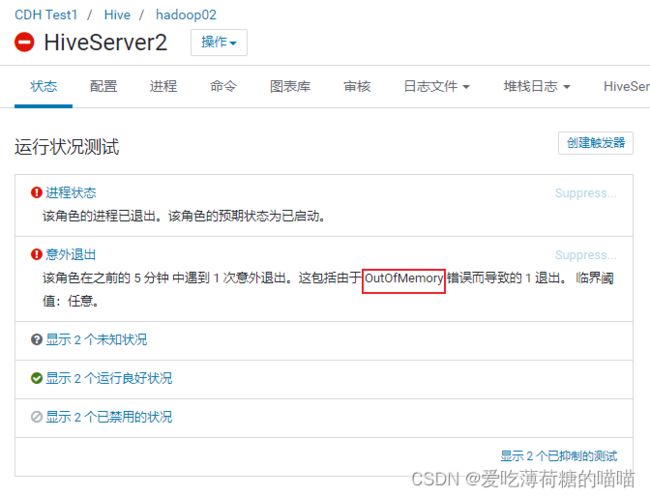
解决方案:
调整 hiveserver2的内存大小
直接在cm的hive的配置目录下, 寻找此配置: 调整为3GB
配置项: HiveServer2 的 Java 堆栈大小(字节)调整后, 重启服务
7. 数据清洗转换
如何进行转换操作:
转换1: 将create_time 转换为 int类型的数据 (说白: 转换为时间戳)
方案: 日期 转换时间戳的函数 unix_timestamp(string date, string pattern)
案例:
select unix_timestamp(‘2019-07-01 23:45:00’, ‘yyyy-MM-dd HH:mm:ss’)转换2: 将create_time转换为 yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo:
方案一: 通过 **year() quarter() month() day() hour() quarter() **
select year(‘2019-07-01 23:45:00’) ; – 2019
select month(‘2019-07-01 23:45:00’) ; – 7
select day(‘2019-07-01 23:45:00’) ; – 1
select hour(‘2019-07-01 23:45:00’) ; – 23
select quarter(‘2019-07-01 23:45:00’); – 3
方案二: 通过字符串的截取操作 substr(‘字符串’,从第几个截取, 截取多少个)
select substr(‘2019-07-01 23:45:00’,1,4); --2019
select substr(‘2019-07-01 23:45:00’,6,2); – 07
select substr(‘2019-07-01 23:45:00’,9,2); – 01
select substr(‘2019-07-01 23:45:00’,12,2); – 23
实现最终转换的SQL
select
wce.session_id,
wce.sid,
unix_timestamp(wce.create_time) as create_time,
wce.seo_source,
wce.ip,
wce.area,
wce.msg_count,
wce.origin_channel,
wcte.referrer,
wcte.from_url,
wcte.landing_page_url,
wcte.url_title,
wcte.platform_description,
wcte.other_params,
wcte.history,
substr(wce.create_time,12,2) as hourinfo,
substr(wce.create_time,1,4) as yearinfo,
quarter(wce.create_time) as quarterinfo,
substr(wce.create_time,6,2) as monthinfo,
substr(wce.create_time,9,2) as dayinfo
from itcast_ods.web_chat_ems wce join itcast_ods.web_chat_text_ems wcte
on wce.id = wcte.id;
可能出现报错:

注意:
在执行转换操作的时候, 由于需要进行二表联查操作, 其中一个表数据量比较少, 此时hive会对其优化, 采用map join的方案进行处理, 而map join需要将小表的数据加载到内存中, 但是内存不足, 导致出现内存溢出错误, 此错误的报错可能会两个信息:
第一个错误信息: return code 1
第二个错误信息: return code -137 (等待一会会爆出来)
解决方案:
关闭掉map join 让其采用reduce join即可
如何关闭呢?
set hive.auto.convert.join= false;
接下来: 将结果数据灌入到DWD层的表中
--动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
insert into table itcast_dwd.visit_consult_dwd partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
wce.session_id,
wce.sid,
unix_timestamp(wce.create_time) as create_time,
wce.seo_source,
wce.ip,
wce.area,
wce.msg_count,
wce.origin_channel,
wcte.referrer,
wcte.from_url,
wcte.landing_page_url,
wcte.url_title,
wcte.platform_description,
wcte.other_params,
wcte.history,
substr(wce.create_time,12,2) as hourinfo,
substr(wce.create_time,1,4) as yearinfo,
quarter(wce.create_time) as quarterinfo,
substr(wce.create_time,6,2) as monthinfo,
substr(wce.create_time,9,2) as dayinfo
from itcast_ods.web_chat_ems wce join itcast_ods.web_chat_text_ems wcte
on wce.id = wcte.id;
8. 数据分析
目的: 将DWD层数据灌入到DWS层
DWS层作用: 细化维度统计操作
- 如何计算访问量:
访问量:
固有维度:
时间维度: 年 季度 月 天 小时
产品属性维度:
地区维度
来源渠道
搜索来源
受访页面
总访问量
以时间为基准, 统计总访问量
-- 统计每年的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
'-1' as from_url,
'5' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo;
-- 统计每年每季度的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo;
-- 统计每年每季度每月的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo;
-- 统计每年每季度每月每天的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo;
-- 统计每年每季度每月每天每小时的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo;
基于时间统计各个受访页面的访问量
-- 统计每年各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
from_url,
'4' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,from_url;
-- 统计每年,每季度各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
from_url,
'4' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,from_url;
-- 统计每年,每季度,每月各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
from_url,
'4' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,from_url;
-- 统计每年,每季度,每月.每天各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
from_url,
'4' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo,from_url;
-- 统计每年,每季度,每月.每天,每小时各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
from_url,
'4' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,from_url;
- 咨询量
咨询量
维度:
固有维度:
时间: 年 季度 月 天 小时
产品属性维度:
地区
来源渠道
总咨询量
咨询和访问的区别:
msg_count >=1 即为咨询数据
基于时间统计总咨询量
-- 统计每年的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
'3' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo;
-- 统计每年每季度的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
'3' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo;
-- 统计每年每季度每月的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
'3' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo;
-- 统计每年每季度每月每天的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
'3' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo;
-- 统计每年每季度每月每天每小时的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
'3' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo;
基于时间,统计各个地区的咨询量
-- 统计每年各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
'1' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,area;
-- 统计每年每季度各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
'1' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,area;
-- 统计每年每季度每月各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
'1' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,area;
-- 统计每年每季度每月每天各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
'1' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo,area;
-- 统计每年每季度每月每天每小时各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
'1' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,area;
9. 数据导出
目的: 从hive的DWS层将数据导出到mysql中对应目标表中
技术:
Apache sqoop
-
第一步:在MySQL中创建目标表
create database scrm_bi default character set utf8mb4 collate utf8mb4_general_ci; -- 访问量的结果表: CREATE TABLE IF NOT EXISTS scrm_bi.visit_dws ( sid_total INT COMMENT '根据sid去重求count', sessionid_total INT COMMENT '根据sessionid去重求count', ip_total INT COMMENT '根据IP去重求count', area varchar(32) COMMENT '区域信息', seo_source varchar(32) COMMENT '搜索来源', origin_channel varchar(32) COMMENT '来源渠道', hourinfo varchar(32) COMMENT '创建时间,统计至小时', time_str varchar(32) COMMENT '时间明细', from_url varchar(32) comment '会话来源页面', groupType varchar(32) COMMENT '产品属性类型:1.地区;2.搜索来源;3.来源渠道;4.会话来源页面;5.总访问量', time_type varchar(32) COMMENT '时间聚合类型:1、按小时聚合;2、按天聚合;3、按月聚合;4、按季度聚合;5、按年聚合;', yearinfo varchar(32) COMMENT '年' , quarterinfo varchar(32) COMMENT '季度', monthinfo varchar(32) COMMENT '月', dayinfo varchar(32) COMMENT '天' )comment 'EMS访客日志dws表'; -- 咨询量的结果表: CREATE TABLE IF NOT EXISTS scrm_bi.consult_dws ( sid_total INT COMMENT '根据sid去重求count', sessionid_total INT COMMENT '根据sessionid去重求count', ip_total INT COMMENT '根据IP去重求count', area varchar(32) COMMENT '区域信息', origin_channel varchar(32) COMMENT '来源渠道', hourinfo varchar(32) COMMENT '创建时间,统计至小时', time_str varchar(32) COMMENT '时间明细', groupType varchar(32) COMMENT '产品属性类型:1.地区;2.来源渠道', time_type varchar(32) COMMENT '时间聚合类型:1、按小时聚合;2、按天聚合;3、按月聚合;4、按季度聚合;5、按年聚合;', yearinfo varchar(32) COMMENT '年' , quarterinfo varchar(32) COMMENT '季度', monthinfo varchar(32) COMMENT '月', dayinfo varchar(32) COMMENT '天' )COMMENT '咨询量DWS宽表'; -
第二步:执行sqoop的数据导出
-
- 先导出 咨询量数据
sqoop export \ --connect jdbc:mysql://192.168.52.150:3306/scrm_bi \ --username root \ --password 123456 \ --table consult_dws \ --hcatalog-database itcast_dws \ --hcatalog-table consult_dws \ -m 1可能会出现乱码问题
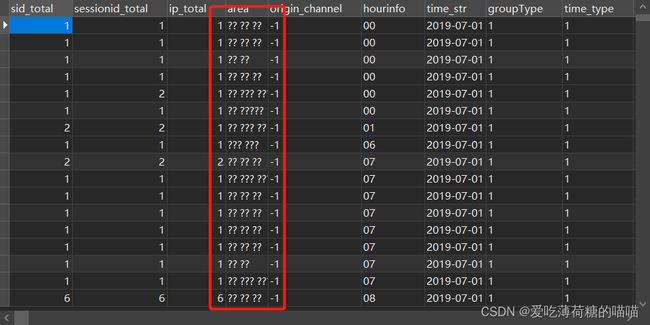
解决方法:(指定编码格式)
sqoop export \ --connect "jdbc:mysql://192.168.52.150:3306/scrm_bi?useUnicode=true&characterEncoding=utf-8" \ --username root \ --password 123456 \ --table consult_dws \ --hcatalog-database itcast_dws \ --hcatalog-table consult_dws \ -m 1-
- 完成访问量数据导出
sqoop export \ --connect "jdbc:mysql://192.168.52.150:3306/scrm_bi?useUnicode=true&characterEncoding=utf-8" \ --username root \ --password 123456 \ --table visit_dws \ --hcatalog-database itcast_dws \ --hcatalog-table visit_dws \ -m 1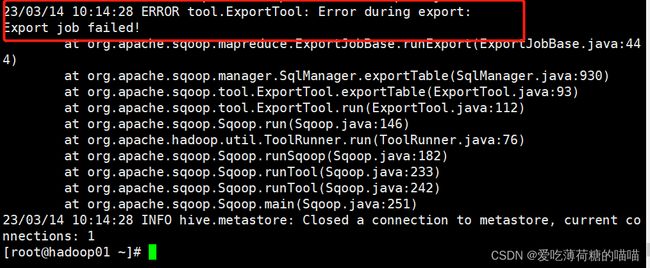
此错误是sqoop在运行导出的时候, 一旦执行MR后, 能够报出的唯一的错误: 标识导出失败
而具体因为什么导出失败, sqoop不知道
如何查阅具体报了什么错误呢? 必须查看MR的运行日志
如何查看MR的日志呢? jobHistory(19888)
查看日志
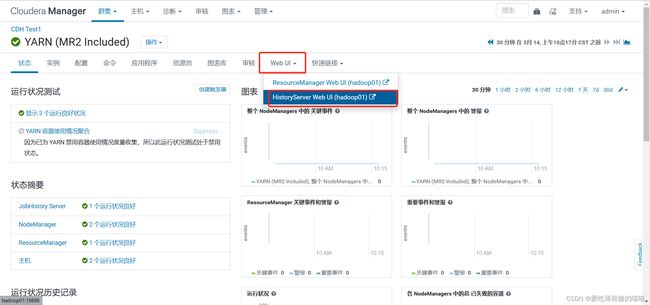
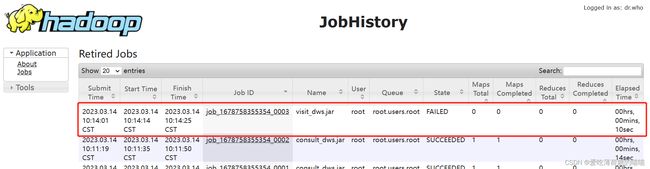
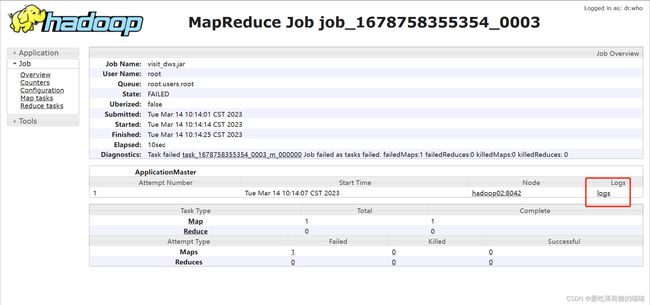
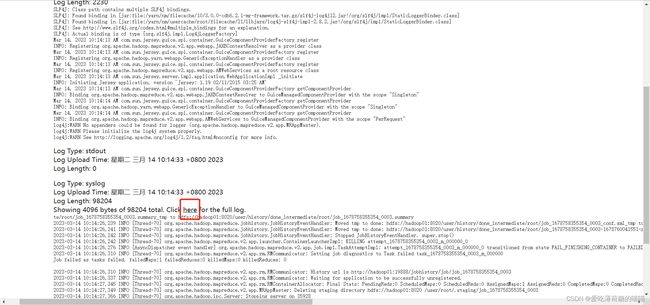
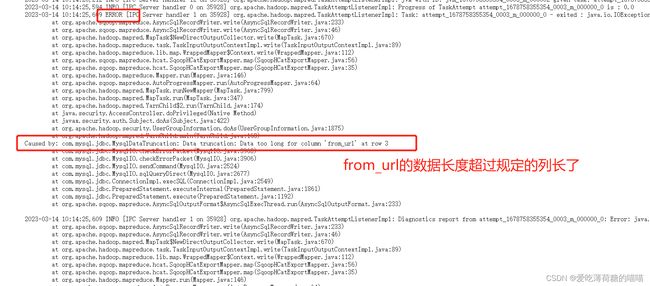
解决方案:
将mysql中的from_url字段的varchar长度改的更长一些即可
-