掌握顺序表,成为数据结构和算法的高手
文章目录
- 1. 线性结构与线性表
- 2. 线性表的顺序存储
- 3. 顺序表的基础操作
-
- 顺序表接口总览
- 初始化顺序表
- 销毁链表
- 插入操作
- 删除操作
- 获取元素操作
-
- 按位置获取
- 按元素值获取
- 打印操作
- 获取表的长度
- 翻转顺序表
- 判断顺序表是否为空
- 扩容操作
- 头插操作
- 尾插操作
- 头删操作
- 尾删操作
- 4. 总结
1. 线性结构与线性表
线性结构是一种数据结构,其中保存的数据像一条线一样按顺序排列,数据之间是一对一的关系,也就是每个数据只有一个直接前驱和一个直接后继。不过,第一个数据没有前趋,最后一个数据没有后继,这意味着数据之间只有简单的前后(相邻)次序关系。可以想象一下排队的情景,这就是线性结构。
线性表是一种线性结构,是具有相同数据类型的 n(n≥0)个数据的有限序列,其中 n 是线性表的长度。其一般表示为( a 1 , a 2 , … a i , a i + 1 , … , a n a1,a2,…ai,ai+1,…,an a1,a2,…ai,ai+1,…,an)。当 n=0 时,线性表就是一个空表。
在一般表示中,a1 是第一个数据,ai 是第 i 个数据,an 是最后一个数据,这表示线性表中的数据是有先后次序的。除 a1 外,每个数据有且仅有一个直接前驱数据,除 an 外,每个数据有且仅有一个直接后继数据。
这表示什么呢?我们可以发现,除第一个数据外总有办法根据当前数据找到其直接前驱,除最后一个数据外,总有办法根据当前数据找到其直接后继。要注意的是,每个数据所占用的存储空间大小相同。数组、链表、栈、队列等都属于线性表中的一种,或者也可以理解成,数组、链表、栈、队列等都可以用来表达线性表。
如下图所示,就是一个线性表

这里延伸一下,与线性表的概念相对应的,还有非线性表。非线性表里的数据之间并不是简单的一对一关系,可能是一对多或多对多关系。树、图、堆等都属于非线性表中的一种,后面都会进行详细讲解。
在有了一种数据结构之后(包括线性表、非线性表),一般还需要实现在该数据结构上的一些基本操作,才能够方便地操作其中的数据。我们习惯将这些基本操作封装成函数或接口,方便自己或团队其他成员使用,这样不但可以避免重复的工作,更可以在很大程度上减少对数据操作出错的可能性。
2. 线性表的顺序存储
线性表的顺序存储指的是用一段连续的内存空间依次存储线性表中的数据,而数组正好具有内存空间连续的特性,因此,线性表的顺序存储是采用一维数组来实现的(回忆一下 STL 中 vector 容器也是用一段连续的内存空间来保存数据),采用一维数组实现的线性表也叫做顺序表。
一维数组的存储结构如下:

如图所示,一维数组(简称数组)的下标从 0 开始,最大的数组下标为 n,这意味着整个数组能容纳 n+1 个元素。这里要注意,在实现顺序表时,有两点需要说明。
(1)随机访问
因为内存空间连续且数据类型相同,因此,随机访问数组中的任意元素(数据)就非常方便快捷。
那么什么是随机访问呢?它指的是通过数组首地址和所给元素下标就可以在最短的时间内找到任意的数组元素。另外,想一想,通过下标随机访问数组元素的时间复杂度是多少呢?
没错就是O(1)。
我们再来说说随机访问的地址又是怎么得到的。比如有一个长度为 10 的整型数组 a,首地址为是 1000,那么这个数组中第 3 个元素,也就是数组元素 a[2] 的地址,就可以直接用 a[i]地址 = 数组首地址 + 下标 *sizeof(整型) 得到。
举个例子,如果假设整型数据所占用的内存空间是 4 字节,那么数组元素 a[2] 的地址是 1000+2*4=1008。同理,数组元素 a[5] 的地址是 1000+5*4=1020。
(2)插入或删除元素
在顺序存储中,插入或者删除元素可能会碰到的情况就是要求数据之间彼此要紧挨在一起,数据之间不允许有空位,也就是说必须保证数据之间内存的连续性,所以当向数组中插入元素或删除数组中元素时,必须要做大量的数据搬运工作,所以插入或删除元素的效率会变得很低。这一点,你在后续进行代码实现的时候,会体会得更加深刻。
顺序表的第一种实现方式:为一维数组静态分配内存。
比如,定义如下的 SeqList 结构来表示顺序表。
typedef struct
{
int _data[10]; //静态数组来保存顺序表中的元素,一共10个位置(最多存入10个元素)
int _length; //顺序表当前实际长度(当前顺序表中已经存入了多少个元素)
}SeqList;
上述代码中,数组 _data 的大小在编译时就已经确定,后续无法改变,这意味着该顺序表最多只能保存 10 个元素。
顺序表的第二种实现方式:为一维数组动态分配内存。比如,定义如下的 SeqList 结构来表示顺序表。
typedef struct
{
int* data; // 顺序表中的元素保存在m_data所指向的动态数组内存中
int length; // 顺序表当前实际长度
int MaxSize; // 动态数组最大容量,因动态数组可以扩容,因此要记录该值
}SeqList;
上述代码中,数组 data 的大小事先是不确定的,在程序执行过程中,用 new 的方式为 data 指针(一维数组)分配一定数量的内存。当顺序表中数据元素逐渐增多,当前分配的内存无法容纳时,可以用 new 新开辟一块更大的内存,并将当前内存中的数据拷贝到新内存中去,同时把旧的内存释放掉。
通过静态分配内存方式与动态分配内存方式实现顺序表的过程,在程序代码上大同小异,但后者代码实现起来要更加复杂一些。因此,后续我会采用动态分配内存的方式来实现顺序表。
3. 顺序表的基础操作
了解整体框架之后,下面我们就来看一看顺序表的具体实现代码,包括基本框架、插入、删除、获取以及其它的一些常用操作。
顺序表接口总览
首先,要把顺序表相关的类的基本框架实现出来。
#define InitSize 10 //动态数组的初始尺寸
#define IncSize 5 //当动态数组存满数据后每次扩容所能多保存的数据元素数量
// 顺序表的定义
template<class T> // T代表数组中元素的类型
class SeqList
{
public:
//构造函数,参数可以有默认值
SeqList(int length = InitSize);
//析构函数
~SeqList();
public:
//在第i个位置插入指定元素e
bool ListInsert(int i, const T& e);
//删除第i个位置的元素
bool ListDelete(int i);
//获得第i个位置的元素值
bool GetElem(int i, T& e);
//按元素值查找其在顺序表中第一次出现的位置
int LocateElem(const T& e);
//输出顺序表中的所有元素
void DispList();
//获取顺序表的长度
int ListLength();
//翻转顺序表
void ReverseList();
//判断是否为空表
bool Empty();
//头插
bool ListPushFront(const T& e);
//尾插
bool ListPushBack(const T& e);
//头删
bool ListPopFront();
//尾删
bool ListPopBack();
private:
// 当顺序表存满数据后可以调用此函数为顺序表扩容
void IncreaseSize();
private:
T* _data; // 存放顺序表中的元素
int _length; // 存放顺序表中的元素
int _maxsize; // 存放顺序表中的元素
};
我们在 main 主函数中,加入下面的代码就可以创建一个初始大小为 10 的顺序表对象了。
SeqList<int> sl(10);
初始化顺序表
通过构造函数对顺序表进行初始化
代码如下:
// 通过构造函数对顺序表进行初始化
template<class T>
SeqList<T>::SeqList(int length)
{
_data = new T[length]; // 为一维数组动态分配内存
_length = 0; // 顺序表当前实际长度为0,表示还未向其中存入任何数据元素
_maxsize = length; // 顺序表最多可以存储maxsize个数据元素
}
销毁链表
通过析构函数对顺序表进行资源释放。
代码如下:
// 通过析构函数对顺序表进行资源释放
template <class T>
SeqList<T>::~SeqList()
{
delete[] _data; // 删除new出来的空间
_length = 0; // 把length的长度置为0
}
插入操作
还记得我们刚刚说的顺序存储的特点吗?因为顺序表中每个数据元素在内存中是连续存储的,所以如果要在某个位置插入一个元素,则需要把原来该位置的元素依次向后移动。如下图所示:

仔细观察,如果我要将元素 10 插入到顺序表的第 3 个位置,为了保证元素之间内存的连续性,就需要将原来第 3 个位置以及第 3 个位置之后的所有元素依次向后移动 1 个位置,为新插入的元素腾出地方。
那么这里就有几点需要考虑的问题了。
(1)数组下标是多少?
这里所谈的插入位置是从编号 1 开始的,而数组下标是从 0 开始的,所以在写代码将插入的位置转换成数组下标时,需要减 1。
(2)先从谁开始移动呢?
在移动 3、4、5 这几个元素时,需要先把元素 5 移动到第 6 个位置,再把元素 4 移动到第 5 个位置,最后把元素 3 移动到第 4 个位置。也就是先从数组中最后一个元素开始依次向后移动。如果先把元素 3 移动到第 4 个位置了,那么就会把原来第 4 个位置的元素 4 直接覆盖掉。
(3)插入位置和原有长度有什么关系吗?
如果在第 3 个位置插入元素,则顺序表中必须至少要有 2 个元素。试想一下,如果顺序表为空或只有 1 个元素,那么它的第 2 个位置肯定是空的。因为顺序表中各个元素的内存必须是连续的,我们不可以隔着一个或者多个空位置向顺序表中插入元素。
(4)最后,如果顺序表已经满了,则不应该允许插入数据。
插入操作的实现代码如下:
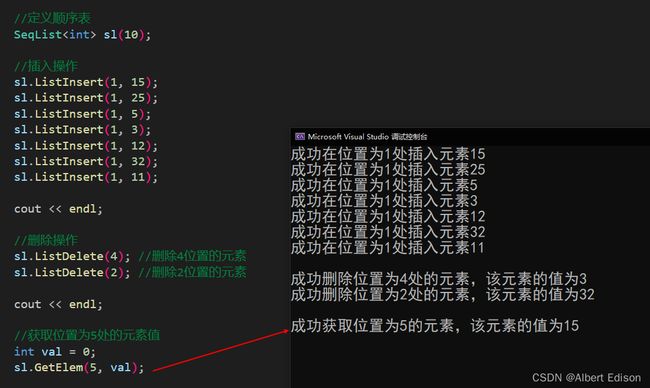
// 在第i个位置(位置编号从1开始)插入指定元素e
// 时间复杂度:O(n),时间开销主要源于元素的移动
template<class T>
bool SeqList<T>::ListInsert(int i, const T& e)
{
// 如果顺序表已经存满了数据,则不允许再插入新数据了
if (_length >= _maxsize) {
cout << "顺序表已满,不能再进行插入!" << endl;
return false;
}
// 判断插入位置i是否合法,i的合法值应该是1到m_length+1之间
if (i < 1 || i > (_length + 1)) {
cout << "元素" << e << "插入的位置" << i << "不合法,合法的位置是1到" << _length + 1 << "之间!" << endl;
return false;
}
// 从最后一个元素开始向前遍历到要插入新元素的第i个位置,分别将这些位置中原有的元素向后移动一个位置
for (int j = _length; j >= i; --j) {
_data[j] = _data[j - 1];
}
_data[i - 1] = e; // 在指定位置i处插入元素e,因为数组下标从0开始,所以这里用i-1表示插入位置所对应的数组下标
cout << "成功在位置为" << i << "处插入元素" << _data[i - 1] << endl;
_length++; // 实际表长+1
return true;
}
我们可以给出一组数据测试一下:

删除操作
因为顺序表中每个数据元素在内存中是连续存储的,所以如果删除某个位置的元素,则需要依次把该位置后面的元素依次向前移动。
如下图所示:

现在如果要将第 3 个位置的元素 10 删除,为了保证元素之间内存的连续性,需要将原来第 4 个位置以及第 4 个位置之后的所有元素依次向前移动 1 个位置,以保证元素之间的内存紧密相连。
那么这里就有几个需要考虑的问题了。
(1)先从谁开始移动呢?
在移动 3、4、5 这几个元素时,需要先把元素 3 移动到第 3 个位置,再把元素 4 移动到第 4 个位置,最后把元素 5 移动到第 5 个位置,也就是先从数组中要删除元素位置的后面一个位置的元素开始依次向前移动,且不可先把元素 5 移动到第 5 个位置,因为这样会把本来在第 5 个位置的元素 4 直接覆盖掉。
(2)另一方面,所要删除的位置必须有元素才可以删除。
我们看一下删除操作的实现代码:
// 删除第i个位置的元素
template<class T>
bool SeqList<T>::ListDelete(int i)
{
// 当顺序表为空时,不能被删除
if (_length < 1) {
cout << "当前顺序表为空,不能删除任何数据!" << endl;
return false;
}
// 当删除位置不合法时,不能被删除
if (i < 1 || i > _length) {
cout << "删除的位置" << i << "不合法,合法的位置是1到" << _length << "之间" << endl;
return false;
}
// 删除i位置的元素
// 注意删除i位置的元素,实际上该元素的下标是i-1
cout << "成功删除位置为" << i << "处的元素,该元素的值为" << _data[i - 1] << endl;
for (int j = i; j < _length; ++j) {
_data[j - 1] = _data[j]; // 依次往前挪动
}
_length--; // 表长度-1
return true;
}
我们可以给出一组数据测试一下:

获取元素操作
关于元素获取操作,我们分为两种情况来讨论:按位置获取和按元素值获取。
按位置获取
首先看一下如何按位置获取顺序表中元素值
代码如下:
// 获取第i个位置的元素值
template<class T>
bool SeqList<T>::GetElem(int i, T& e)
{
//
if (_length < 1) {
cout << "当前顺序表为空,不能获取任何数据!" << endl;
return false;
}
if (i < 1 || i > _length) {
cout << "获取元素的位置" << i << "不合法,合法的位置是1到" << _length << "之间!" << endl;
return false;
}
// 参数e是引用类型参数,我们可以将该值带回,并对其进行修改
e = _data[i - 1];
cout << "成功获取位置为" << i << "的元素,该元素的值为" << _data[i - 1] << endl;
return true;
}
给出一组数据测试一下:
按元素值获取
再来看一看按元素值查找其在顺序表中第一次出现的位置
代码如下:
//按元素值查找其在顺序表中第一次出现的位置
template<class T>
int SeqList<T>::LocateElem(const T& e)
{
for (int i = 0; i < _length; ++i)
{
if (_data[i] == e)
{
cout << "值为" << e << "的元素在顺序表中第一次出现的位置为" << i + 1 << endl;
return i + 1; //返回的位置应该用数组下标值+1
}
}
cout << "值为" << e << "的元素在顺序表中没有找到" << endl;
return -1; //返回-1表示查找失败
}
给出一组数据测试一下:

打印操作
输出顺序表中的所有元素。
代码如下:
//输出顺序表中的所有元素,时间复杂度为O(n)
template<class T>
void SeqList<T>::DispList()
{
for (int i = 0; i < _length; ++i)
{
cout << _data[i] << " "; //每个数据之间以空格分隔
}
cout << endl; //换行
}
获取表的长度
获取顺序表的长度
代码如下:
//获取顺序表的长度,时间复杂度为O(1)
template<class T>
int SeqList<T>::ListLength()
{
return _length;
}
翻转顺序表
所谓翻转顺序表,就是把顺序表中元素的排列顺序反过来,比如原来存放的元素是 1、2、3、4、5,那么翻转后存放的元素就是 5、4、3、2、1。
如下图所示:

解决这种问题并不难,只需要将第 1 个元素和第 5 个(最后一个)元素交换位置,第 2 个元素跟第 4 个(倒数第二个)元素交换位置,第 3 个元素保持不动即可。
判断顺序表是否为空
如果顺序表为空,返回 true,如果不为空,返回 false。
//判断是否为空表
template<class T>
bool SeqList<T>::Empty()
{
//如果顺序表为空,则为true(1)
//如果顺序表不为空,则为false(0)
return _length == 0;
}
扩容操作
扩容是什么意思呢?比如在前面针对插入函数 ListInsert 的代码实现中,如果顺序表已经存满了数据,那就不允许再插入新数据了,这造成了一些使用中的不便,这个时候,我们当然希望顺序表能够自动扩容。
具体的实现思路,就是重新 new 一块比原顺序表所需内存更大一些的内存以便容纳更多的元素,然后把原来内存中的元素拷贝到新内存(这一步动作如果元素很多将很耗费时间)并把原内存释放掉(当然,这样做也是比较影响程序执行效率的)。
为此,引入成员函数 IncreaseSize,代码如下:
//当顺序表存满数据后可以调用此函数为顺序表扩容,时间复杂度为O(n)
template<class T>
void SeqList<T>::IncreaseSize()
{
T* p = _data;
_data = new T[_maxsize + IncSize]; //重新为顺序表分配更大的内存空间
for (int i = 0; i < _length; i++)
{
_data[i] = p[i]; //将数据复制到新区域
}
_maxsize = _maxsize + IncSize; //顺序表最大长度增加IncSize
delete[] p; //释放原来的内存空间
}
现在,就可以修改插入函数 ListInsert 的代码,以达到当顺序表满之后再插入数据时能够自动扩容的目的,只需要对 if 判断语句进行简单修改,其他代码不变,代码如下:
// 如果顺序表已经存满了数据,则不允许再插入新数据了
if (_length >= _maxsize) {
IncreaseSize(); //扩容操作
}
头插操作
也就是在顺序表的头部插入元素
代码如下:
//头插
template<class T>
bool SeqList<T>::ListPushFront(const T& e)
{
// 如果顺序表已经存满了数据,那么需要进行扩容
if (_length >= _maxsize) {
IncreaseSize();
}
int end = _length - 1;
while (end >= 0) {
_data[end + 1] = _data[end]; // 将数据 从后往前 依次 向后挪动
--end;
}
_data[0] = e;
_length++;
return true;
}
给出一组数据进行测试:

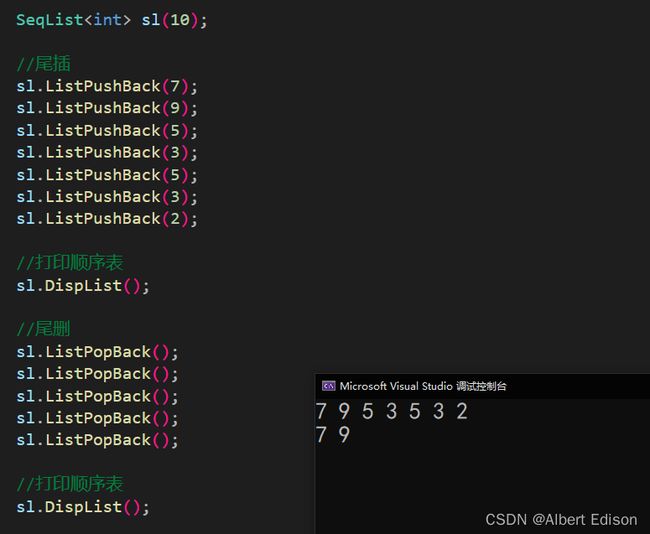
尾插操作
尾插相对于头插就比较简单了,首先检查容量是否足够,如果不够,先扩容;如果够,直接 顺序表尾部插入数据即可
代码如下:
//尾插
template<class T>
bool SeqList<T>::ListPushBack(const T& e)
{
// 如果顺序表已经存满了数据,那么需要进行扩容
if (_length >= _maxsize) {
IncreaseSize();
}
_data[_length] = e;
_length++; // 插入完以后,顺序表元素个数加一
return true;
}
给出一组数据进行测试:

头删操作
要删除顺序表头部的数据,我们可以从下标为 1 的位置开始,依次将数据 向前覆盖 即可
代码如下:
//头删
template<class T>
bool SeqList<T>::ListPopFront()
{
// 当顺序表为空时,不能被删除
if (_length < 1) {
cout << "当前顺序表为空,不能删除任何数据!" << endl;
return false;
}
int begin = 1;
while (begin < _length) {
_data[begin - 1] = _data[begin]; // 将数据依次向前覆盖
++begin;
}
_length--; // 顺序表元素个数减一
return true;
}
给出一组数据进行测试:

尾删操作
从顺序表 尾部 删除数据的话,就更简单了,因为我们的顺序表是动态内存开辟的,所以直接将 顺序表的元素个数减一 即可。
代码如下:
//尾删
template<class T>
bool SeqList<T>::ListPopBack()
{
// 当顺序表为空时,不能被删除
if (_length < 1) {
cout << "当前顺序表为空,不能删除任何数据!" << endl;
return false;
}
_length--;
return true;
}
给出一组数据进行测试:
4. 总结
总结一下顺序表的几个重要的特点
- 通过下标随机访问数组元素的时间复杂度仅为 O(1)。
- 存储的数据紧凑,表中的元素在内存中紧密相连,无须为维持表中元素之间的前后关系而增加额外的存储空间(后面学习到链表时会看到增加额外存储空间来维持表中元素前后关系的情形)。
- 插入和删除操作可能会移动大量元素导致这两个动作效率不高。
- 需要大片连续的内存空间来存储数据。
- 动态分配内存的方式实现的顺序表在扩展顺序表容量时扩展的空间大小不好确定,分配太多内存容易造成浪费,分配太少内存就会导致 new 和 delete 被频繁调用,影响程序执行效率。而且扩展顺序表容量操作的时间复杂度也比较高。
正如我们所见,顺序表要求内存中数据连续存储,这既带来了定位元素的便利,同时也拖慢了插入和删除元素的速度。
值得说明的是,对于多数需要使用顺序表的场合,直接使用标准模板库中的 vector 容器即可,其丰富的接口会给开发带来更多的便利。
如果是对于性能要求极其严苛的底层开发,而且通过测试确定了自己编写的代码执行效率比 vector 容器更高,也可以自行实现顺序表。