使用 Amazon SageMaker 构建机器学习应用

随着社会的发展和科技进步,人工智能变得无处不在,然而,人工智能广泛应用仍然面临着巨大的挑战:一是掌握人工智能专业知识的人才不足;二是构建和扩展人工智能的技术产品有难度;三是在生产经营中部署人工智能应用费时且成本高。最终导致缺乏低成本、易使用、可扩展的人工智能产品和服务。
开发者和数据科学家首先必须对数据进行可视化、转换和预处理,这些数据才能变成算法可以使用的格式,用以训练模型。即使是简单的模型,企业也需要花费庞大的算力和大量的训练时间,并可能需要招聘专门的团队来管理包含多台 GPU 服务器的训练环境。从选择和优化算法,到调节影响模型准确性的数百万个参数,训练模型的所有阶段都需要大量的人力和猜测。然后,在应用程序中部署训练好的模型时,算法工程师又需要另一套应用设计和分布式系统方面的专业技能。并且,随着数据集和变量数的增加,模型会过时,算法工程师又必须一次又一次地重新训练模型,让模型从新的信息中学习和进化。所有这些工作都需要大量的专业知识,并耗费庞大的算力、数据存储和时间成本。而且,由于没有集成化的工具用于整个机器学习的工作流,机器学习模型的传统开发方式是复杂、繁复和昂贵的。
自从2018年起,亚马逊云科技发布了一系列的产品和服务,例如 Amazon SageMaker、Amazon Aurora ML、Amazon Redshift ML 和2021年 reInvent 发布的 Amazon SageMaker Canvas,使得不同角色的工程师越来越容易构建机器学习应用,降低应用机器学习的门槛,以实现普惠机器学习。本系列文章将以上述产品为核心,从不同的角度帮助企业中不同部门的人员构建机器学习应用。
Amazon SageMaker:
https://aws.amazon.com/cn/sagemaker/
Amazon Aurora ML:
https://aws.amazon.com/cn/rds/aurora/machine-learning/
Amazon Redshift ML:
https://aws.amazon.com/cn/redshift/features/redshift-ml/
Amazon SageMaker Canvas:
https://aws.amazon.com/cn/sagemaker/canvas/

本普惠机器学习系列文章包含以下5篇:
篇一:使用 Amazon SageMaker 构建机器学习应用(本篇)
在本篇文章中,我们将介绍如何在 Amazon SageMaker 上开展机器学习模型训练,我们将在 Notebook 上面分别演示针对同一个数据集,分别使用 XGBoost、SageMaker 内置算法和 AutoGluon 进行模型训练。
Amazon SageMaker:
https://aws.amazon.com/cn/sagemaker/
XGBoost:
https://xgboost.readthedocs.io/en/stable/
AutoGluon:
https://auto.gluon.ai/
篇二:使用数据可视化工具加载 Amazon Redshift 数仓数据完成机器学习数据准备和模型快速验证
https://aws.amazon.com/cn/blogs/china/use-the-visualization-tool-to-load-amazon-redshift-data-warehouse-data-to-complete-machine-learning-data/
在本篇文章中,我们将会为您展示一个简单的2分类预测的机器学习场景,通过加载存放于数据仓库 Amazon Redshift 中的银行客户画像和业务行为特征,来完成建模前特征的快速准备和预测是否办理存款业务模型的快速验证。
Amazon Redshift:
https://aws.amazon.com/cn/redshift/
篇三:使用 Amazon Redshift ML 构建机器学习应用
https://aws.amazon.com/cn/blogs/china/building-machine-learning-applications-using-amazon-redshift-ml/
在本篇文章中,我们将介绍使用标准 SQL 在 Amazon Redshift 集群上快速应用机器学习。从数据导入,到模型训练,到模型编译和部署,最后通过 Redshift Function 调用模型进行预测。
篇四:如何在数据库里面使用 SQL 语句直接调用 Amazon 机器学习服务进行推理
https://aws.amazon.com/cn/blogs/china/how-to-use-sql-statements-in-the-database-to-directly-call-amazon-machine-learning-service-for-reasoning/
在本篇文章中,我们将介绍如何在 Amazon Aurora 数据库里面使用 SQL 语句直接调用 Amazon Comprehend 和 Amazon SageMaker 机器学习服务进行推理,让业务后端开发人员即使没有机器学习知识,也可以快速使用最熟悉的 SQL 语句调用机器学习服务,为业务提升价值。
Amazon Aurora:
https://aws.amazon.com/cn/rds/aurora/
Amazon Comprehend:
https://aws.amazon.com/cn/comprehend/
篇五:基于 Amazon SageMaker Canvas 无代码构建分类模型
https://aws.amazon.com/cn/blogs/china/build-a-classification-model-without-code-based-on-amazon-sagemaker-canvas/
在本篇文章中,我们将介绍如何无需写代码即可构建机器学习应用,Amazon SageMaker Canvas 提供无代码、可视化的工作环境,即使没有机器学习背景知识,也可以基于自己业务需要构建机器学习模型。
01
介绍
本文作为该系列文章的第一篇,我们将介绍数据科学家和算法工程师训练机器学习模型时常采用的方式,即在单台主机上安装 Jupyter Notebook,并安装相关的依赖包,然后在其上进行代码编写与测试。
Amazon SageMaker 是一个端到端的机器学习平台,SageMaker 支持您的模型开发全流程,从数据准备,数据处理,算法构建,模型训练,超参调优,模型部署与监控等环节,SageMaker 都提供了相应的功能帮助算法工程师们专注于业务和模型本身,提高开发效率。
Amazon SageMaker:
https://aws.amazon.com/cn/sagemaker/
接下来我们将介绍在 Amazon SageMaker Notebook 实例上面训练机器学习模型的过程,我们将展示三种方式:基于开源算法 XGBoost,基于 AutoGluon 和基于 SageMaker 内置算法 XGBoost。
02
创建 SageMaker Notebook 实例
Amazon SageMaker 提供了两种方式的 Jupyter Notebook、Notebook 实例和 SageMaker Studio Notebook。不管哪种方式,SageMaker 都提供了预置的开发环境,如 TensorFlow、PyTorch、Numpy、Pandas 等等,算法工程师无需自行安装,而且 SageMaker 也支持自定义环境,充分保证了灵活性。
Notebook 实例:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/nbi.html
SageMaker Studio Notebook:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/notebooks.html
接下来我们将创建一个 SageMaker Notebook 实例。
在 SageMaker 控制台左侧边栏上找到 Notebook,在 Notebook instances 界面下,右上角点击 Create notebook instance。
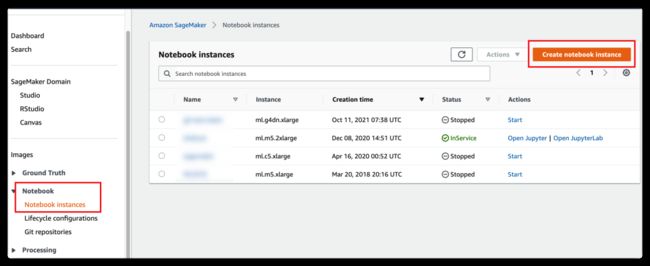
在新的界面下,输入该 Notebook 实例的名称,并在 Notebook instance type 处选择实例的类型。实例的类型是可以后期更换的,一般我们用 Notebook 实例针对少量数据做测试,无需太大的实例类型,当然您也可以为了保持和之前使用习惯的一致,选取合适的机型。同时,您可以设置该实例的存储磁盘大小,默认是 5GB,截图中我们手动改为 30GB,该容量后期同样可以调大。

接下来在 Permissions and encryption 中设置 IAM role。在 SageMaker 上进行模型开发的最佳实践中会涉及 Amazon S3、Amazon Elastic Container Registry (Amazon ECR),此处设置的将保证 SageMaker 具备访问这些服务的权限。
Amazon S3:
https://aws.amazon.com/cn/s3/
Amazon Elastic Container Registry (Amazon ECR):
https://aws.amazon.com/cn/ecr/
如果是首次使用 SageMaker,您将需要选择 Create a new role,在弹出的界面中,可以设置允许 SageMaker 访问哪些 S3 存储桶。如果之前已经创建过 Notebook 实例,此处在 Use existing role 中将出现之前创建的 role,可以根据情况决定是否新建 role。


最后在 Network 部分,可选是否启用 Amazon VPC 连接。如果选择了某一个您自己的 VPC,则继续设置子网和安全组,以及是否允许该 Notebook 直接访问外网资源或是通过 VPC 内的 NAT 网关访问外网资源。
Amazon VPC:
https://aws.amazon.com/cn/vpc/
如果设置了 VPC 该 Notebook 实例将获取一个该 VPC 对应子网下的弹性网卡及其内网 IP、Notebook 实例将具备访问 VPC 内其他资源的可能(如 EC2,RDS 等)。
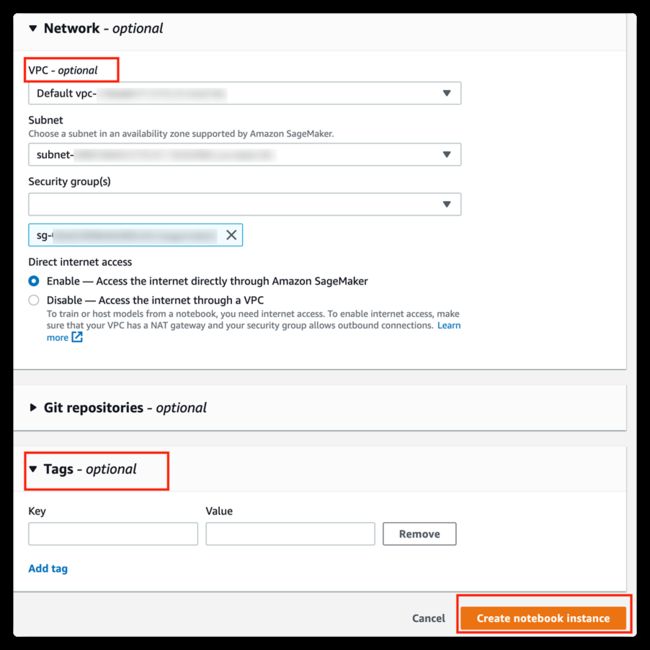
设置 Tag(可选),以方便 Notebook 实例的管理以及成本的追踪(通过费用详单)。
通过费用详单:
https://docs.aws.amazon.com/zh_cn/awsaccountbilling/latest/aboutv2/cost-alloc-tags.html
最后选择 Create notebook instance,SageMaker 就将创建该 Notebook 实例。在 Notebook instances 界面您可以看到您当前的实例列表及其状态,如果状态为 InService (新建的 Notebook 实例通常有5分钟左右的创建时间),在 Actions 列有 Open Jupyter | Open JupyterLab 的选项。

点击 Open Jupyter,将自动弹出一个新的页面,加载完成后,出现我们熟悉的 Jupyter Notebook 界面。
其中在 SageMaker Examples 页面下,在右侧 New 下拉菜单中,您可以选择创建的开发环境,此处我们选择 conda_python3 以进行后面的内容。

03
数据集探索
在本文示例中,我们将用 UCI 机器学习数据集中的 Bank Makerting Data Set。该数据与一家葡萄牙银行机构的直接营销活动有关。营销活动是基于电话,通常,同一客户需要多次联系,以便了解其对产品(如银行定期存款)是否加入(“yes”或“no”)。
UCI 机器学习数据:
https://archive.ics.uci.edu/ml/index.php
Bank Makerting Data Set:
https://archive.ics.uci.edu/ml/datasets/bank+marketing
该数据集中有四个数据集:
1) bank-additional-full.csv 包含所有样本(41188),每个样本有20个特征,按日期排序(从2008年5月到2010年11月),非常接近 [Moro 等人,2014] 分析的数据。
2) bank-additional.csv 中有10%的样本(4119),从1)所述的全量数据集中随机采样,同样有20个特征。
3) bank-full.csv 包含所有的样本,每个样本17个特征,按日期排序(旧版本的数据集,特征较少)。
4) bank.csv 中有10%的样本,每个样本17个特征,从3)中所述数据集中随机采样。
分类目标是预测客户是否会加入定期存款(标签为 y,取值为 yes 或 no)。
3.1
数据集下载
在第二节中新建的 Notebook 中新建 cell,输入如下代码,下载数据集并解压:
!wget -N https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip
!unzip -o bank-additional.zip左滑查看更多
3.2
数据集一览
我们将使用 bank-additional-full.csv 数据集文件,将其通过 pandas 读入并展示:
import numpy as np # For matrix operations and numerical processing
import pandas as pd # For munging tabular data
import os
data = pd.read_csv("./bank-additional/bank-additional-full.csv", sep=";")
pd.set_option("display.max_columns", 500) # Make sure we can see all of the columns
pd.set_option("display.max_rows", 50) # Keep the output on one page
data左滑查看更多
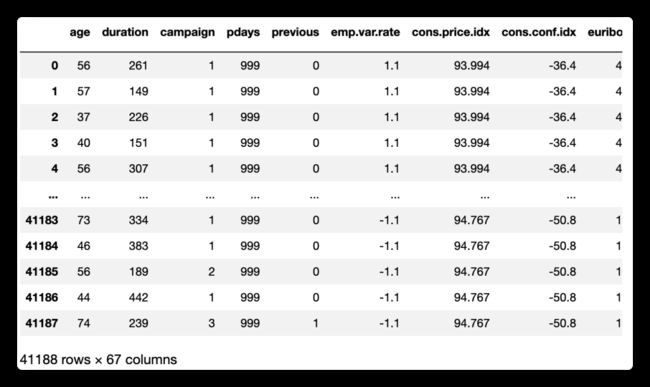
得到如下数据预览图:

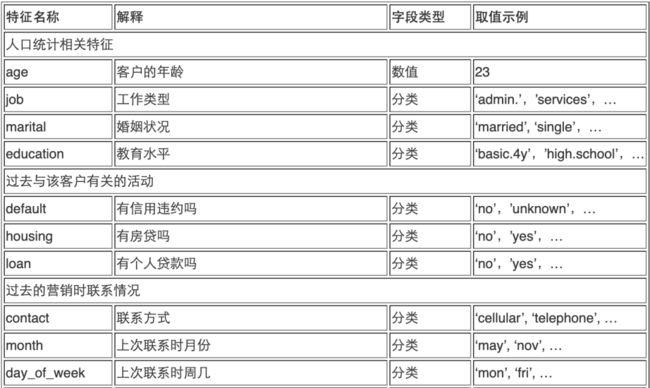
由此可知:
● 我们有 40K 多一点的样本(客户记录),每个样本有20个特征;
● 这些特征的类型有些数字类型,有些分类类型;
● 这些数据似乎是按时间和联系方式排序的;
每个特征的简单解释如下:

3.3
数据预处理
数据清洗是机器学习中重要一环,常见方法有:
(1)处理缺失值:一些机器学习算法能够处理缺失值,但大多数并不能自动处理。方法包括:
● 删除具有缺失值的样本:如果只有一小部分样本具有不完整的信息,则此方法效果很好。
● 删除具有缺失值的特征:如果有少量特征具有大量缺失值,则此方法效果很好。
● 估算缺失值:关于这个主题有人已经写了本书,但常见的选择是用该列的非缺失值的众数或平均值替换缺失值。
(2)将分类转换为数字表示:最常见的方法是一种独热编码(one hot encoding),其方法是使用 N 位状态寄存器来对 N 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
(3)异常分布的数据:虽然对于像梯度提升树这样的非线性模型影响有限,但像回归这样的模型在输入高度倾斜的数据时会产生非常不准确的估计。在某些情况下,简单地取特征的自然对数就足以产生更正态分布的数据。在其他情况下,可以将值分桶到离散范围。然后,这些分桶后的数据可以被视为分类类型的特征,并应用在独热编码中。
(4)处理更复杂的数据类型:以不同的粒度对图像、文本或数据进行处理。
在本数据集中,许多样本的 pdays 值为“999”,即最后一次联系客户后经过的天数。这很可能是一个特定的数字,表示之前没有联系过。考虑到这一点,我们创建一个名为“no_previous_contact”的新特征列,然后在 pdays 为999时赋值“1”,否则赋值“0”。
在“job”特征列中,有表示客户没有工作的类别,例如“student”、“retire”和“unemployed”。由于客户是否在工作很可能会影响他/她加入定期存款的决定,因此我们生成一个新特征列以根据“job”列显示客户是否在工作。
最后我们将分类类型数据通过独热编码转换为数字。
Python
data["no_previous_contact"] = np.where(
data["pdays"] == 999, 1, 0
) # Indicator variable to capture when pdays takes a value of 999
data["not_working"] = np.where(
np.in1d(data["job"], ["student", "retired", "unemployed"]), 1, 0
) # Indicator for individuals not actively employed
model_data = pd.get_dummies(data) # Convert categorical variables to sets of indicators
model_data左滑查看更多
在构建模型之前要问自己的另一个问题是某些特征是否会在您的最终用例中增加价值。下雨与雨伞销售具有高度相关性,但是预测足够远的天气情况以计划雨伞库存可能与在不了解天气的情况下预测雨伞销售一样困难。按照这个逻辑,我们将删除数据中当前季度经济相关的特征和 duration 特征,因为这些特征需要进行高精度预测才能用作未来预测的输入。即使我们使用上一季度的经济指标值,这个值对于下个季度早期接触到的潜在客户和季度晚期接触到的客户的影响可能并不一样。
Python
model_data = model_data.drop(
["duration", "emp.var.rate", "cons.price.idx", "cons.conf.idx", "euribor3m", "nr.employed"], axis=1)
model_data = model_data.drop(["y_no"], axis=1)
model_data左滑查看更多


然后,我们将数据集拆分为训练(90%)和测试(10%)数据集,并将数据集转换为算法期望的正确格式。 我们将在训练期间使用训练数据集。 测试数据集将在模型训练完成后用于评估模型性能。
Python
train_data, test_data = np.split(
model_data.sample(frac=1, random_state=1729),
[int(0.9 * len(model_data)),],
)
train_x = train_data.iloc[:,:-1]
train_y = train_data.iloc[:,59]
test_x = test_data.iloc[:,:-1]
test_y = test_data.iloc[:,59]左滑查看更多
04
使用 XGBoost 训练模型
XGBoost 是一个优化的分布式梯度提升库,它是在 Gradient Boosting 框架下实现的机器学习算法。XGBoost 提供了一种并行提升树(也称为 GBDT、GBM),可以快速准确地解决许多数据科学问题,相同的代码可以在主流的分布式环境(Hadoop、SGE、MPI)上运行,是算法工程师广泛应用的机器学习算法之一。
XGBoost:
https://xgboost.readthedocs.io/en/stable/
接下来我们将采用 XGBoost 来训练模型。
4.1
XGBoost 安装:
!pip install xgboost
4.2
XGBoost Python API
XGBoost 提供了多种开发语言包,这里我们继续使用 Python 开发语言。
Python
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
# 用sklearn.cross_validation进行训练数据集划分,这里训练集和交叉验证集比例为8:2,可以自己根据需要设置
X, val_X, y, val_y = train_test_split(
train_x,
train_y,
test_size=0.2,
random_state=2022,
stratify=train_y
)
# xgb矩阵赋值
xgb_val = xgb.DMatrix(val_X, label=val_y)
xgb_train = xgb.DMatrix(X, label=y)
xgb_test = xgb.DMatrix(test_x)
# xgboost模型 #####################
params = {
'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc', #logloss
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2
'max_depth': 8, # 构建树的深度,越大越容易过拟合
'alpha': 0, # L1正则化系数
'lambda': 10, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.5, # 生成树时进行的列采样
'min_child_weight': 3,
# 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言
# ,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
# 这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
'silent': 0, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.03, # 如同学习率
'seed': 1000,
'nthread': -1, # cpu 线程数
'missing': 1,
'scale_pos_weight': (np.sum(y==0)/np.sum(y==1)) # 用来处理正负样本不均衡的问题,通常取:sum(negative cases) / sum(positive cases)
}
plst = list(params.items())
num_rounds = 500 # 迭代次数
watchlist = [(xgb_train, 'train'), (xgb_val, 'val')]
# 训练模型并保存
# early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练
model = xgb.train(plst, xgb_train, num_rounds, watchlist, early_stopping_rounds=200)
model.save_model('./xgb.model') # 用于存储训练出的模型
preds = model.predict(xgb_test)
# 导出结果
threshold = 0.5
ypred = np.where(preds > 0.5, 1, 0)
from sklearn import metrics
print ('AUC: %.4f' % metrics.roc_auc_score(test_y,ypred))
print ('ACC: %.4f' % metrics.accuracy_score(test_y,ypred))
print ('Recall: %.4f' % metrics.recall_score(test_y,ypred))
print ('F1-score: %.4f' %metrics.f1_score(test_y,ypred))
print ('Precesion: %.4f' %metrics.precision_score(test_y,ypred))
print(metrics.confusion_matrix(test_y,ypred))左滑查看更多
执行如上代码,将在该 Notebook 上面启动模型训练,并在完成后保存模型。然后将前面预留出的测试数据集送入模型中进行推理,我们将推理结果大于阈值(0.5)的认为是1,否则为0,然后与测试集中的标签进行对比来评估模型效果。
当然我们也可以输出模型中不同特征的重要性,这通常帮忙我们更好的理解模型行为。
Python
from xgboost import plot_importance
from matplotlib import pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 8.0) #
# 显示重要特征
plot_importance(model)
plt.show()左滑查看更多
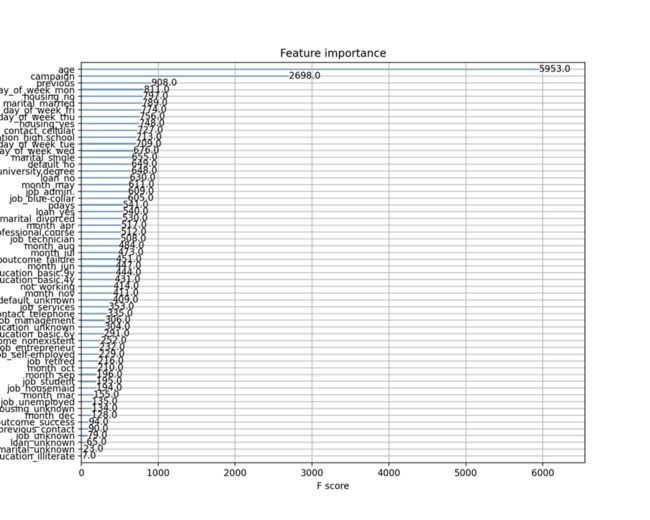
4.3
XGBoost Scikit-Learn 接口
XGBoost 同时还提供了Scikit Learn 风格的 API 封装,如下示例:
Python
# Scikit-Learn style API
from xgboost import XGBClassifier
model = XGBClassifier(**params,n_estimators=500)
eval_set = [(val_X, val_y)]
model.fit(X, y, early_stopping_rounds=200, eval_set=eval_set, eval_metric='auc', verbose=True)
#输出概率
preds = model.predict(test_x)
# 导出结果
y_pred = [round(pred) for pred in preds]
from sklearn import metrics
print ('AUC: %.4f' % metrics.roc_auc_score(test_y,ypred))
print ('ACC: %.4f' % metrics.accuracy_score(test_y,y_pred))
print ('Recall: %.4f' % metrics.recall_score(test_y,y_pred))
print ('F1-score: %.4f' %metrics.f1_score(test_y,y_pred))
print ('Precesion: %.4f' %metrics.precision_score(test_y,y_pred))
print(metrics.confusion_matrix(test_y,y_pred))左滑查看更多
这样,我们在 SageMaker Notebook 实例上训练出一个预测银行客户是否会加入定期存款计划的二分类模型。XGBoost 在训练模型时会将训练数据载入到内存中,考虑到实际很多机器学习项目中,数据集规模庞大,这将需要大内存的实例类型,如果长期运行一台高配置的 Notebook 实例其成本也会较高,如何节省成本呢,下一节我们将介绍使用 SageMaker Training API 的方式节省训练模型的成本。
05
使用 SageMaker 内置算法训练模型
SageMaker 除了提供 Notebook 实例之外,还提供了模型训练和模型部署等功能,算法工程师可以高效、经济的开展机器学习项目。在模型训练方面,SageMaker 提供了 Training 相关的 API,在该 API 调用中,指定模型训练需要的实例类型,数量,运行环境容器镜像以及数据集在 S3 中的位置等参数,SageMaker 将创建相应的实例资源,自动将数据集从 S3 下载到新建的实例资源中,并自动启动模型训练脚本,训练完成后(生成模型),自动将模型文件上传回 S3,并自动终止训练实例资源,以停止计费。训练实例的计费是按秒计费,并且支持 Spot 实例,节省高达90%的费用。
Spot 实例:
https://aws.amazon.com/cn/ec2/spot/
SageMaker Training API 的调用脚本可以在前面介绍的 SageMaker Notebook 实例上执行,此时您只需要一个小型号的实例即可,无需使用大机型,甚至可以在您的云端 EC2 实例,本地个人电脑 IDE 等等,并且可以使用 Java、.NET 等开发语言进行 SageMaker Training API 的调用。
本地个人电脑 IDE:
https://aws.amazon.com/cn/blogs/machine-learning/run-your-tensorflow-job-on-amazon-sagemaker-with-a-pycharm-ide/

除此之外,SageMaker 在训练环节还提供了17种内置算法,您无需编写算法脚本,而只需要准备好数据集然后调用 API 即可。SageMaker 还提供了用于实验追踪管理的功能 — SageMaker Experiments,实时捕获训练过程中的指标并分析训练作业功能 – SageMaker Debugger,超参自动调优、分布式训练等等。
内置算法:
https://docs.amazonaws.cn/sagemaker/latest/dg/algos.html
SageMaker Experiments:
https://docs.amazonaws.cn/sagemaker/latest/dg/experiments.html
SageMaker Debugger:
https://docs.amazonaws.cn/sagemaker/latest/dg/train-debugger.html
超参自动调优:
https://docs.amazonaws.cn/sagemaker/latest/dg/automatic-model-tuning.html
分布式训练:
https://docs.amazonaws.cn/sagemaker/latest/dg/distributed-training.html
5.1
使用 SageMaker Training API
开展模型训练
接下来我们看下如何使用 SageMaker Training API 开展模型训练。
初始化:
Python
import sagemaker
import boto3
import numpy as np # For matrix operations and numerical processing
import pandas as pd # For munging tabular data
from time import gmtime, strftime
import os
region = boto3.Session().region_name
smclient = boto3.Session().client("sagemaker")
role = sagemaker.get_execution_role()
bucket = sagemaker.Session().default_bucket()
prefix = "sagemaker/DEMO-hpo-xgboost-dm"左滑查看更多
加载数据,数据处理过程同4.2中。
Python
data = pd.read_csv("./bank-additional/bank-additional-full.csv", sep=";")
pd.set_option("display.max_columns", 500) # Make sure we can see all of the columns
data["no_previous_contact"] = np.where(
data["pdays"] == 999, 1, 0
) # Indicator variable to capture when pdays takes a value of 999
data["not_working"] = np.where(
np.in1d(data["job"], ["student", "retired", "unemployed"]), 1, 0
) # Indicator for individuals not actively employed
model_data = pd.get_dummies(data) # Convert categorical variables to sets of indicators
model_data = model_data.drop(
["duration", "emp.var.rate", "cons.price.idx", "cons.conf.idx", "euribor3m", "nr.employed"],
axis=1,
)左滑查看更多
这里我们将数据集拆分为训练(70%)、验证(20%)和测试(10%)数据集,并将数据集转换为 SageMaker 内置 XGBoost 算法期望的正确格式。 我们将在训练期间使用训练和验证数据集。测试数据集将在部署到端点后用于评估模型性能。
SageMaker 内置 XGBoost 算法:
https://docs.amazonaws.cn/sagemaker/latest/dg/xgboost.html
Python
train_data, validation_data, test_data = np.split(
model_data.sample(frac=1, random_state=1729),
[int(0.7 * len(model_data)), int(0.9 * len(model_data))],
)
pd.concat([train_data["y_yes"], train_data.drop(["y_no", "y_yes"], axis=1)], axis=1).to_csv(
"train.csv", index=False, header=False
)
pd.concat(
[validation_data["y_yes"], validation_data.drop(["y_no", "y_yes"], axis=1)], axis=1
).to_csv("validation.csv", index=False, header=False)
pd.concat([test_data["y_yes"], test_data.drop(["y_no", "y_yes"], axis=1)], axis=1).to_csv(
"test.csv", index=False, header=False
)左滑查看更多
将生成的数据集上传到 S3,供下一步模型训练时使用。
Python
boto3.Session().resource("s3").Bucket(bucket).Object(
os.path.join(prefix, "train/train.csv")
).upload_file("train.csv")
boto3.Session().resource("s3").Bucket(bucket).Object(
os.path.join(prefix, "validation/validation.csv")
).upload_file("validation.csv")
from sagemaker.inputs import TrainingInput
s3_input_train = TrainingInput(
s3_data="s3://{}/{}/train".format(bucket, prefix), content_type="csv"
)
s3_input_validation = TrainingInput(
s3_data="s3://{}/{}/validation/".format(bucket, prefix), content_type="csv"
)左滑查看更多
对于 SageMaker XGBoost 训练任务,SageMaker Debugger 提供了自动生成 XGBoost 模型训练报告的功能,该报告中有数据集样本标签分布,损失曲线变化,特征重要性,混淆矩阵等内容。我们可以在模型训练完成后,在 S3 中下载该报告。
XGBoost 模型训练报告:
https://docs.amazonaws.cn/en_us/sagemaker/latest/dg/debugger-training-xgboost-report.html
Python
from sagemaker.debugger import Rule, rule_configs
rules=[
Rule.sagemaker(rule_configs.create_xgboost_report())
]
sess = sagemaker.Session()
container = sagemaker.image_uris.retrieve("xgboost", boto3.Session().region_name, "1.2-1")
xgb = sagemaker.estimator.Estimator(
container,
role,
instance_count=1,
instance_type="ml.m4.xlarge",
base_job_name="bank-dm-xgboost-report",
output_path="s3://{}/{}/output".format(bucket, prefix),
sagemaker_session=sess,
rules=rules
)
xgb.set_hyperparameters(
max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective="binary:logistic",
num_round=500,
)
xgb.fit({"train": s3_input_train, "validation": s3_input_validation})左滑查看更多
执行如上代码,从输出的日志可以看到如下日志(示例):
2022-02-18 09:16:46 Starting - Starting the training job...
2022-02-18 09:17:09 Starting - Launching requested ML instancesCreateXgboostReport: InProgress
ProfilerReport-1645175806: InProgress
......
2022-02-18 09:18:15 Starting - Preparing the instances for training...............
2022-02-18 09:20:38 Downloading - Downloading input data...
2022-02-18 09:21:10 Training - Downloading the training image..
2022-02-18 09:21:30 Training - Training image download completed. Training in progress.
.........等等训练过程日志左滑查看更多
在日志最后有本次训练的用时,可以看到启用 SPOT 实例功能后,此次训练成本可以节省59.2%。
2022-02-18 09:22:16 Uploading - Uploading generated training model
2022-02-18 09:22:16 Completed - Training job completed
Training seconds: 98
Billable seconds: 40
Managed Spot Training savings: 59.2%左滑查看更多
5.2
训练任务管理
您也可以在 SageMaker 控制台 Training – Training Jobs 中看到此次训练任务,并可以进一步的查看详情(任务启动时间,持续时间,超参,训练数据集,实例资源使用监控,模型输出位置等信息)。
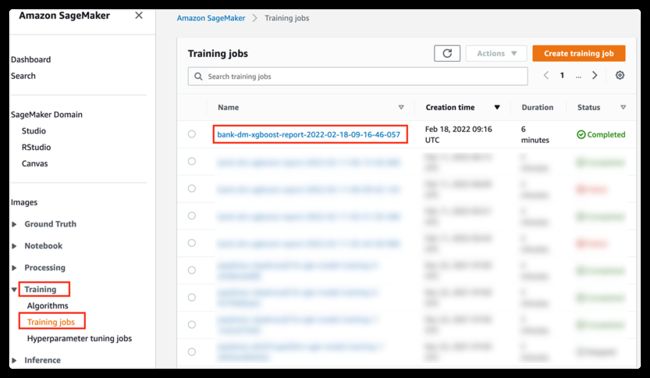

在详情页下方,您可以在 S3 中找到该次训练模型存储在 S3 中的位置,点击该链接可以跳转到 S3 存储桶中该文件页面。

5.3
SageMaker XGBoost 训练报告
在如上 S3 存储桶对象路径(model.tar.gz)上一级目录下可以看到 rule-output 目录,在该目录下,即可找到 SageMaker Debugger 生成的 XGBoost 报告
(CreateXgboostReport/xgboost_report.html)。

下载到本地即可阅读该报告。

06
使用 AutoGluon 训练模型
AutoGluon 是一个流行的开源易用的 AutoML 模型训练包,支持文本、图像和表格数据的应用场景,AutoGluon 面向 ML 初学者和专家,使您能够:
AutoGluon:
https://auto.gluon.ai/stable/index.html
● 只需几行代码,即可为您的原始数据快速构建深度学习和传统机器学习模型原型。
● 在没有专业知识的情况下自动利用最先进的技术(在适当的情况下)。
● 自动超参数调整、模型选择/集成、架构搜索和数据处理。
● 轻松改进/调整您的定制模型和数据管道,或为您的用例定制 AutoGluon。
接下来我们将介绍如何在前面创建的 SageMaker Notebook 上面使用 AutoGluon 来自动化训练出模型。
6.1
AutoGluon 安装
# Install AutoGluon
!pip install -U setuptools wheel
!pip install -U "mxnet<2.0.0"
!pip install autogluon左滑查看更多
6.2
使用 AutoGluon Tabular 训练模型
针对本用例,我们将使用 AutoGluon.Tabular 训练一个二分类模型,只需通过一个简单的 fit()调用,AutoGluon 可以生成高度精确的模型,根据数据表中其他列的值来预测其中一列中的值,您可以使用 AutoGluon 解决表格数据分类和回归问题。
Python
from autogluon.tabular import TabularDataset, TabularPredictor
ag_data = pd.read_csv("./bank-additional/bank-additional-full.csv", sep=";")
label = 'y'
print("Summary of y variable: \n", ag_data[label].describe())
ag_train_data, ag_test_data = np.split(
ag_data.sample(frac=1, random_state=1729),
[int(0.9 * len(model_data)),],
)左滑查看更多
使用 AutoGluon,我们无需像3.3小节中做数据处理(缺失值处理,独热编码等),AutoGloun 会自动帮我们做这些工作。
Python
ag_test_data_X = ag_test_data.iloc[:,:-1]
ag_test_data_y =ag_test_data.iloc[:,20]
save_path = 'agModels-predictClass' # specifies folder to store trained models
learner_kwargs = {'ignored_columns':[["duration", "emp.var.rate", "cons.price.idx", "cons.conf.idx", "euribor3m", "nr.employed"]]}
predictor = TabularPredictor(label=label, path=save_path,
eval_metric='recall', learner_kwargs=learner_kwargs
).fit(ag_train_data)
predictor = TabularPredictor.load(save_path) # unnecessary, just demonstrates how to load previously-trained predictor from file
ag_y_pred = predictor.predict(ag_test_data_X)
ag_y_pred_proa = predictor.predict_proba(ag_test_data_X)
print("Predictions: \n", ag_y_pred)
perf = predictor.evaluate_predictions(y_true=ag_test_data_y, y_pred=ag_y_pred, auxiliary_metrics=True)
# perf = predictor.evaluate_predictions(y_true=ag_test_data_y, y_pred=ag_y_pred_proa, auxiliary_metrics=True) #when eval_metric='auc' in TabularPredictor()左滑查看更多
从上面代码可见,使用 AutoGluon 可以以少量代码即可完成机器学习任务,无需进行数据处理,算法挑选等复杂工作,非常适合机器学习领域初学者也能帮助机器学习专家节省大量调试时间。
07
总结
本文作为普惠机器学习系列文章的第一篇,介绍了如何创建 SageMaker Notebook 实例,并基于 UCI 机器学习数据集中的 Bank Makerting Data Set 介绍了如何使用开 XGBoost、SageMaker 内置算法以及 AutoGluon 开展机器学习任务,针对数据库工程师,大数据工程师亚马逊云科技同样提供了相应的产品和功能帮助数据工程师快速、高效的应用机器学习,也推荐您继续阅读本系列的其他文章。
08
参考资料
● XGBoost Python API
https://xgboost.readthedocs.io/en/stable/python/python_api.html
● XGBoot XGBClassifier
https://xgboost.readthedocs.io/en/stable/python/python_api.html#xgboost.XGBClassifier
● XGBoost 代码示例
https://www.cnblogs.com/nxf-rabbit75/p/9748345.html
● SageMaker Python SDK
https://sagemaker.readthedocs.io/en/stable/api/training/estimators.html
● SageMaker 内置算法示例1
https://github.com/aws/amazon-sagemaker-examples/blob/c7ffabe26e873803c2cdf5b66c9a7c36f493ea39/introduction_to_applying_machine_learning/xgboost_customer_churn/xgboost_customer_churn.ipynb
● SageMaker 内置算法示例2
https://github.com/aws/amazon-sagemaker-examples/blob/c7ffabe26e873803c2cdf5b66c9a7c36f493ea39/hyperparameter_tuning/xgboost_direct_marketing/hpo_xgboost_direct_marketing_sagemaker_python_sdk.ipynb
● AutoGluon Quickstart
https://auto.gluon.ai/stable/tutorials/tabular_prediction/tabular-quickstart.html
● AutoGluon TabularPredictor
https://auto.gluon.ai/stable/_modules/autogluon/tabular/predictor/predictor.html#TabularPredictor
本篇作者

王世帅
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,对于云端深度学习模型分布式训练,NLP 等领域有丰富经验,多次面向开发者进行云端机器学习产品的介绍与最佳实践经验分享。


听说,点完下面4个按钮
就不会碰到bug了!
