盘点Hadoop生态中 6 个核心的大数据组件
大数据生态圈中有很多优秀的组件,可谓琳琅满目,按组件类别可分为存储引擎、计算引擎,消息引擎,搜索引擎等;按应用场景可分为在线分析处理OLAP型,在线事务处理OLTP型,以及混合事务与分析处理HTAP型等。有些组件主要存储日志数据或者只允许追加记录,有些组件可更好的支持CDC或者upsert数据。有些组件是为离线分析或批处理而生,有些则更擅长实时计算或流处理。本文整理了几个笔者认为非常重要且仍然主流的核心组件,供参考。
1
Hadoop 第一代分布式存储计算框架
Hadoop是一个分布式系统基础架构,由Apache基金会开发,它允许用户在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。Hadoop包含丰富的生态组件,有我们耳熟能详的分布式文件系统HDFS,分布式计算框架MapReduce,以及分布式调度系统YARN。
HDFS是一个高容错、高吞吐的分布式存储系统,可以被广泛部署在低价的硬件设备之上。基本架构:
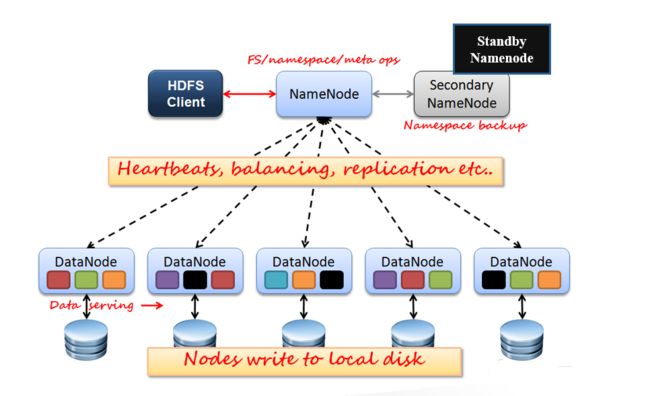
有几个概念值得记住:
数据块(Block)
大文件被切分成多个block存储,默认大小为128M。为了保证数据可靠性,每个block分布式存储在多个datanode节点上,默认3副本。
NameNode
NameNode是HDFS的主节点,主要作用是维护文件系统的目录结构,管理文件与block之间关系,block与datanode之间关系。
DataNode
DataNode是HDFS的数据节点,主要作用是存储与管理数据块,并将信息上报给NameNode。
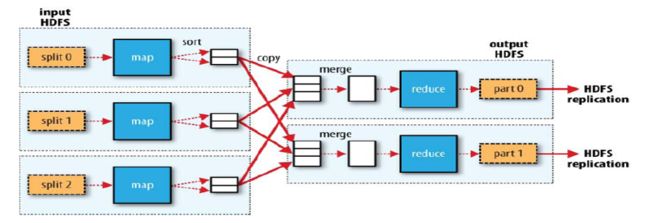
MapReduce是Hadoop体系中的并行计算框架, 也是一种编程模型,分成Map和Reduce两个阶段,在Map阶段对数据进行提取,得到有效的键值对,然后在Reduce阶段进行计算,得到最终的结果。流程图如:
YARN是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入在集群利用率、资源统一管理和数据共享等方面具有重大意义。这里不做详细介绍。
2
Hive 基于Hadoop的数据仓库
Hive是构建在Hadoop之上的数据仓库工具,由facebook开源,最初用于解决海量结构化的日志数据统计问题。Hive 定义了一种类 SQL 查询语言 HQL,提供SQL查询功能,可以将SQL语句转换为MapReduce任务运行。
Hive是一个SQL on Hadoop组件,主要特点是高吞吐、高延时,学习成本低(SQL),通常用于海量结构化数据离线分析;Hive支持TextFile、RCFile、ORC、Parquet等多种文件格式,Gzip、LZO、Snappy等多种压缩格式;支持用户自定义函数。数据模型如下:

Hive是大家比较熟知的开源组件,多数情况下我们只要解决如何更好、稳定、高效的使用问题即可。涉及Hive MetaStore相关的属于高阶使用。
3
HBase 主流的分布式NoSQL数据库
HBase(Hadoop database)是一个分布式、可扩展、面向列的NoSQL数据库,本质上是一个Key-Value系统,底层数据存储在文件系统HDFS上,原生支持 MapReduce计算框架,具有高吞吐、低延时的读写特点。
HBase周边生态成熟,具有很多丰富的特性,比如强一致性读写、自动分区、自动故障转移、面向列等。HBase主要用于海量数据永久性存储与超大规模并发访问场景,目前应用非常广泛。生态架构如:

HBase相关的概念主要有:
HMaster
HBase主节点,负责节点的管理。
RegionServer
HBase从节点,数据节点;负责数据的读写。
Region
HBase表的分区,水平方向分布式存储的单元。
Namespace
Table
Rowkey
ColumnFamily
ColumnQualifier
4
Spark 一站式的分布式计算引擎
Spark是一个快速通用的、一站式的分布式计算引擎,它是开源的类Hadoop MapReduce的通用并行框架,拥有Hadoop MapReduce所具有的优点,但又不同于MapReduce,其中间输出结果可以保存在内存中,从而不再需要频繁读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce算法。
Spark提供了大量的库,主要包括Spark Core、Spark SQL 、Spark Streaming 、MLlib、GraphX等。开发者可以在同一个应用程序中无缝组合使用这些库。框架图如:

总结Spark的技术优势,主要有以下几点:
强大的RDD模型
先进的DAG架构
高效的Cache机制
丰富的算子操作类型
多语言支持
统一完整的解决方案
5
Kafka 分布式消息引擎及流处理平台
Kafka是一个分布式消息引擎与流处理平台,经常用做企业的消息总线、实时数据管道,甚至还可把它看作存储系统。早期Kafka 的定位是一个高吞吐的分布式消息系统,目前则演变成了一个成熟的分布式消息引擎,以及流处理平台。
高吞吐、低延时是Kafka 显著的特点,Kafka能够达到百万级的消息吞吐量,延迟可达毫秒级。Kafka是典型的生产者-消费者模型,如下:

Kafka生产端发送消息到集群Broker节点上,具体是发到某一个topic的partition中,消息在同一partition中保证顺序;消费端拉取消息进行消费处理,通常是sink到其他引擎如另一个kafka、存储系统、NoSQL数据库等。涉及主要概念有:
Producer
生产者,即消息产生和发送的一方。
Consumer
消费者,即拉取消息进行处理的一方。
Broker
Kafka实例或角色,一个Kafka集群由多个broker构成,通常一台机器部署一个Kafka实例,一个实例挂了不影响其他实例。
Topic
即主题,服务端消息的逻辑存储单元。一个topic通常包含若干个Partition即分区。
Partition
Topic的分区,分布式存储在各个broker中, 实现发布与订阅的负载均衡。
Message
消息,或称日志消息,是Kafka服务端实际存储的数据。
6
Elasticsearch 主流的分布式搜索引擎
Elasticsearch,简称ES,是当下主流的分布式全文搜索,它允许用户快速的进行存储、搜索和分析海量数据,底层是开源库Lucene,开箱即用。
ES通常为具有复杂的搜索要求或多维度查询的应用程序提供底层数据存储、搜索能力,不仅仅是全文搜索。基本架构图:

总结主要有以下关键词或特点:
全文或结构化搜索
ES是一个搜索引擎,可用于全文搜索或结构化搜索。
分布式
如上图示,ES数据在水平方向是以分片(shard)以及副本分片(replica)的形式分布式存储在不同节点。
Restful API
对外主要以Rest API或接口的形式提供服务。
近实时搜索与更新
主要能够提供近实时的写入与搜索能力,不太适用于那些对实时性要求比较高的应用。
面向文档
ES还是一个文档型引擎,数据在ES中被称为document,用户可指定document id,否则ES会自动生成一个document id。
Schema free
ES是一个Schema free的组件,我们可以提前定义schema结构,也可以不定义,ES会自动帮我们创建schema结构,动态添加字段。
// 阅读原文可查看本文视频