run_demo.py+main.py
README
使用<作者提供的预训练模型 in ```/pretrained_ckpt```>
模型:SpixelNet_bsd_ckpt.tar
网格大小:16x16
输入数据的路径:/demo/inputs
输出数据的路径:/demo/spixel_viz
python run_demo.py --data_dir=./demo/inputs --data_suffix=jpg --output=./demo Code
1.
model_names = sorted(name for name in models.__dict__
if name.islower() and not name.startswith("__"))sorted()函数:对所有可迭代的对象进行排序操作。
models.__dict__: 运行
import models
modelsname=sorted(name for name in models.__dict__)
print(modelsname)输出结果是:
['SpixelNet1l', 'SpixelNet1l_bn', 'Spixel_single_layer', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'model_util']
这些都是网络模型,除了以'__'开头的。
name.islower(): islower()方法检测字符串是否由小写字母组成。如果都是小写,则返回True, 否则返回False.把'SpixelNet1l', 'SpixelNet1l_bn', 'Spixel_single_layer',排除掉。
name.startwith("__"): 查看字符串是否以"__"开头,是返回True, 否返回False。把 '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'model_util'排除掉。
june:是小写且不以_开头。即,model_util
2.
parser = argparse.ArgumentParser(description='PyTorch SPixelNet inference on a folder of imgs',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)argparse.ArgumentParser():创建一个解析器,ArgumentParser对象包含将命令行解析成Python数据类型所需要的全部信息。
description参数简要描述这个程序做什么以及怎么做。此处说的是PyTorch SPixelNet inference on a folder of imgs。
formatter_class参数:定义帮助文档格式。
parser = argparse.ArgumentParser(description='PyTorch SPixelNet inference on a folder of imgs',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--data_dir', metavar='DIR', default='./demo/inputs', help='path to images folder')
parser.add_argument('--data_suffix', default='jpg', help='suffix of the testing image')
parser.add_argument('--pretrained', metavar='PTH', help='path to pre-trained model',
default= './pretrain_ckpt/SpixelNet_bsd_ckpt.tar')
parser.add_argument('--output', metavar='DIR', default= './demo' , help='path to output folder')
parser.add_argument('--downsize', default=16, type=float,help='superpixel grid cell, must be same as training setting')
parser.add_argument('-nw', '--num_threads', default=1, type=int, help='num_threads')
parser.add_argument('-b', '--batch-size', default=1, type=int, metavar='N', help='mini-batch size')parser.add_argument():添加程序参数。
type:命令行参数应当被转换成的类型;
choices: 可用的参数;
help: 对添加的程序的参数作用做一个简单的描述;
metavar: 帮助信息中显示的参数名称,使用 print(parser.print_help()) 结果会输出 --arch ARCH 。
default:默认值
别人使用网络中还常常出现:
'arch' : 使用哪个网络。
parser.add_argument('--arch', metavar='ARCH', default='resnet18', choices=model_names, help='model architecture:' + '|'.join(model_names) + '(default: resnext29_8_64)')'momentum': 动量是为了加速学习的过程,用在权值更新的时候,为了防止网络陷入局部最小值,达不到全局最优解。Momentum不仅会使用当前的梯度,还会积累之前的梯度以确定走向。
未引入momentum权值更新公式:
引入momentum 权值更新公式:
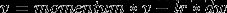
,其中
是上一次迭代的梯度。
parser.add_argument('--momentum', type=float, default=0.9, help='Momentum.')'decay' : 权重衰减,这里用的L2 正则化。L2正则化的目的是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题。公式:
,其中loss表示损失,
表示真实值,
表示 网络的预测值,
是权值衰减系数,这里定义的是0.0005。
parser.add_argument('--decay', type=float, default=0.0005, help='weight decay(L2 penalty).')'schedule': 在第几个epoch改变学习率,改变方法:
parser.add_argument('--schedule', type=int, nargs='+', default=[150, 225], help='Decrease learning rate at these epochs.') parser.add_argument('--gamms', type=float, nargs='+', default=[0.1,0.1], help='LR is multiplied by gamma on schedule, number of gammas should be equal to schedule')'nargs='+'' : 因为'schedule' 和 'gamms'情况特殊,默认都各有两个值,shedule是[150, 225], gamms是[0.1, 0.1]。需要从命令行读取不止一个参数。
'start_epoch': 第几个epoch开始,用于继续训练,例如,一共10个epoch, 运行到第6个停止了,可以继续从第6个开始训练。
'evaluate': 是训练模型还是测试/验证模型。
parser.add_argument('--evaluate', dest='evaluate', action='store_true', help='evaluate model on validation set')action='store_true':运行时给‘--evalute’传参数,就将'--evalute'设为True。
'--ngpu':gpu的标号。
parser.add_argument('--ngpu', type=int, default=1, help='0 = CPU.')'--workers': 线程数。
parser.add_argument('--workers', type=int, default=2, help='number of data loading workers(default:2)')
'--data_suffix':后缀名
'--pretrained':到预训练模型的路径,demo使用的是作者跑出来的模型'./pretrain_ckpt/SpixelNet_bsd_ckpt.tar'
'--downsize':作者设置为16并声明必须和训练设置的大小一样'superpixel grid cell, must be same as training setting'
'-nw', '--num_threads':线程设置『参考链接:torch.set_num_threads(args.thread)
ps.是否可以改进为:
torch.set_num_threads(args.thread) # 设置pytorch并行线程数
if torch.cuda.is_available() and args.gpu >= 0:
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
device = torch.device('cuda:' + str(args.gpu))
else:
device = torch.device('cpu')3.
args = parser.parse_args()把parser中设置的所有"add_argument"给返回到args子类实例当中, 那么parser中增加的属性内容都会在args实例中,使用即可。 与parser.add_argument()配套使用。
4.
def test(args, model, img_paths, save_path, idx):
# Data loading code
input_transform = transforms.Compose([
flow_transforms.ArrayToTensor(),
transforms.Normalize(mean=[0,0,0], std=[255,255,255]),
transforms.Normalize(mean=[0.411,0.432,0.45], std=[1,1,1])
])
img_file = img_paths[idx]
load_path = img_file
imgId = os.path.basename(img_file)[:-4]
# may get 4 channel (alpha channel) for some format
#june:img_ = imread(load_path)[:, :, :3]
img_ = imageio.imread(load_path)[:, :, :3]
H, W, _ = img_.shape
H_, W_ = int(np.ceil(H/16.)*16), int(np.ceil(W/16.)*16)
# get spixel id
n_spixl_h = int(np.floor(H_ / args.downsize))
n_spixl_w = int(np.floor(W_ / args.downsize))
spix_values = np.int32(np.arange(0, n_spixl_w * n_spixl_h).reshape((n_spixl_h, n_spixl_w)))
spix_idx_tensor_ = shift9pos(spix_values)
spix_idx_tensor = np.repeat(
np.repeat(spix_idx_tensor_, args.downsize, axis=1), args.downsize, axis=2)
spixeIds = torch.from_numpy(np.tile(spix_idx_tensor, (1, 1, 1, 1))).type(torch.float).cuda()
n_spixel = int(n_spixl_h * n_spixl_w)
img = cv2.resize(img_, (W_, H_), interpolation=cv2.INTER_CUBIC)
img1 = input_transform(img)
ori_img = input_transform(img_)
# compute output
tic = time.time()
output = model(img1.cuda().unsqueeze(0))
toc = time.time() - tic
# assign the spixel map
curr_spixl_map = update_spixl_map(spixeIds, output)
ori_sz_spixel_map = F.interpolate(curr_spixl_map.type(torch.float), size=( H_,W_), mode='nearest').type(torch.int)
mean_values = torch.tensor([0.411, 0.432, 0.45], dtype=img1.cuda().unsqueeze(0).dtype).view(3, 1, 1)
spixel_viz, spixel_label_map = get_spixel_image((ori_img + mean_values).clamp(0, 1), ori_sz_spixel_map.squeeze(), n_spixels= n_spixel, b_enforce_connect=True)
# ************************ Save all result********************************************
# save img, uncomment it if needed
# if not os.path.isdir(os.path.join(save_path, 'img')):
# os.makedirs(os.path.join(save_path, 'img'))
# spixl_save_name = os.path.join(save_path, 'img', imgId + '.jpg')
# img_save = (ori_img + mean_values).clamp(0, 1)
# imsave(spixl_save_name, img_save.detach().cpu().numpy().transpose(1, 2, 0))
# save spixel viz
if not os.path.isdir(os.path.join(save_path, 'spixel_viz')):
os.makedirs(os.path.join(save_path, 'spixel_viz'))
spixl_save_name = os.path.join(save_path, 'spixel_viz', imgId + '_sPixel.png')
#june:图片矩阵变换。opencv读入图片的矩阵格式是:(height,width,channels)。而在深度学习中,因为要对不同通道应用卷积,所以会采取另一种方式:(channels,height,width)
imageio.imsave(spixl_save_name, spixel_viz.transpose(1, 2, 0))
# save the unique maps as csv, uncomment it if needed
# if not os.path.isdir(os.path.join(save_path, 'map_csv')):
# os.makedirs(os.path.join(save_path, 'map_csv'))
# output_path = os.path.join(save_path, 'map_csv', imgId + '.csv')
# # plus 1 to make it consistent with the toolkit format
# np.savetxt(output_path, (spixel_label_map + 1).astype(int), fmt='%i',delimiter=",")
if idx % 10 == 0:
print("processing %d"%idx)
return tocmain.py
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',help='number of data loading workers')
#可以改成8以下num_workers=args.workers, pin_memory=False, shuffle=False, drop_last=True)
#pin_memory当时怕gpu跑不起来改为False了,保持batch_size=2的情况下把这个改成True