【实用算法教学】——Apriori算法,教你使用亲和性分析方法推荐电影
一 亲和性分析
二 亲和性分析算法
三 选择参数
挖掘亲和性分析所用的关联规则之前,我们先用Apriori算法生成频繁项集。接着,通过检测频繁项集中前提和结论的组合,生成关联规则(例如,如果用户喜欢电影X,那么他很可能喜欢电影Y)。
四 电影推荐问题
六 获取数据集
import os
import pandas as pd
data_folder = os.path.join(os.path.expanduser("~"), "Data",
"ml-100k")
ratings_filename = os.path.join(data_folder, "u.data")七 用 pandas 加载数据
MovieLens数据集非常规整,但是有几点跟pandas.read_csv方法的默认设置有出入,所以要调整参数设置。第一个问题是数据集每行的几个数据之间用制表符而不是逗号分隔。其次,没有表头,这表示数据集的第一行就是数据部分,我们需要手动为各列添加名称。
all_ratings = pd.read_csv(ratings_filename, delimiter="\t",
header=None, names = ["UserID", "MovieID", "Rating", "Datetime"])all_ratings["Datetime"] = pd.to_datetime(all_ratings['Datetime'],
unit='s')all_ratings[:5]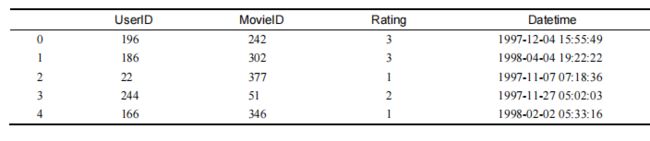
八 稀疏数据格式
这是一个稀疏数据集,我们可以将每一行想象成巨大特征矩阵的一个格子,在这个矩阵中,每一行表示一个用户,每一列为一部电影。第一列为每一个用户给第一部电影打的分数,第二列为每一个用户给第二部电影打的分数,以此类推。
九 Apriori 算法的实现
all_ratings["Favorable"] = all_ratings["Rating"] > 3all_ratings[10:15]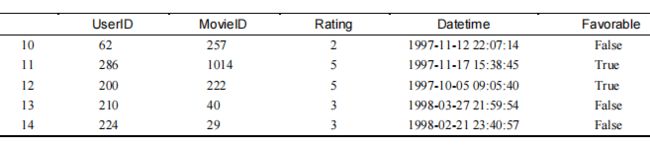
从数据集中选取一部分数据用作训练集,这能有效减少搜索空间,提升Apriori算法的速度。 我们取前200名用户的打分数据。
ratings = all_ratings[all_ratings['UserID'].isin(range(200))]favorable_ratings = ratings[ratings["Favorable"]]favorable_reviews_by_users = dict((k, frozenset(v.values))
for k, v in favorable_ratings
groupby("UserID")["MovieID"])num_favorable_by_movie = ratings[["MovieID", "Favorable"]].
groupby("MovieID").sum()num_favorable_by_movie.sort("Favorable", ascending=False)[:5]
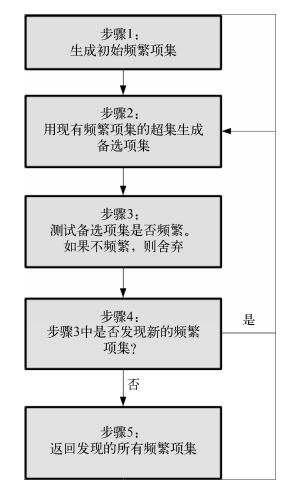
十 Apriori 算法
十一 实现
Apriori算法第一次迭代时,新发现的项集长度为2,它们是步骤(1)中创建的项集的超集。第二次迭代(经过步骤(4))中,新发现的项集长度为3。这有助于我们快速识别步骤(2)所需的项集。
我们把发现的频繁项集保存到以项集长度为键的字典中,便于根据长度查找,这样就可以找到最新发现的频繁项集。下面的代码初始化一个字典。
frequent_itemsets = {}min_support = 50frequent_itemsets[1] = dict((frozenset((movie_id,)),
row["Favorable"])
for movie_id, row in num_favorable_
by_movie.iterrows()
if row["Favorable"] > min_support)from collections import defaultdict
def find_frequent_itemsets(favorable_reviews_by_users, k_1_itemsets,
min_support):
counts = defaultdict(int)经验告诉我们,要尽量减少遍历数据的次数,所以每次调用函数时,再遍历数据。这样做效果不是很明显(因为数据集相对较小),但是数据集更大的情况下,就很有必要。我们来遍历所有用户和他们的打分数据。
for user, reviews in favorable_reviews_by_users.items():for itemset in k_1_itemsets:
if itemset.issubset(reviews):for other_reviewed_movie in reviews - itemset:
current_superset = itemset | frozenset((other_
reviewed_movie,))
counts[current_superset] += 1return dict([(itemset, frequency) for itemset, frequency in
counts.items() if frequency >= min_support])for k in range(2, 20):
cur_frequent_itemsets =
find_frequent_itemsets(favorable_reviews_by_users,
frequent_itemsets[k-1],
min_support)
frequent_itemsets[k] = cur_frequent_itemsetsif len(cur_frequent_itemsets) == 0:
print("Did not find any frequent itemsets of length {}".
format(k))
sys.stdout.flush()
breakelse:
print("I found {} frequent itemsets of length
{}".format(len(cur_frequent_itemsets), k))
sys.stdout.flush()del frequent_itemsets[1]十二 抽取关联规则
Apriori算法结束后,我们得到了一系列频繁项集,这还不算是真正意义上的关联规则,但是很接近了。频繁项集是一组达到最小支持度的项目,而关联规则由前提和结论组成。 我们可以从频繁项集中抽取出关联规则,把其中几部电影作为前提,另一部电影作为结论组成如下形式的规则:
如果用户喜欢前提中的所有电影,那么他们也会喜欢结论中的电影。
candidate_rules = []
for itemset_length, itemset_counts in frequent_itemsets.items():
for itemset in itemset_counts.keys():for conclusion in itemset:
premise = itemset - set((conclusion,))
candidate_rules.append((premise, conclusion))print(candidate_rules[:5])[(frozenset({79}), 258), (frozenset({258}), 79), (frozenset({50}),
64), (frozenset({64}), 50), (frozenset({127}), 181)]correct_counts = defaultdict(int)
incorrect_counts = defaultdict(int)for user, reviews in favorable_reviews_by_users.items():
for candidate_rule in candidate_rules:
premise, conclusion = candidate_rule测试每条规则的前提对用户是否适用。换句话说,用户是否喜欢前提中的所有电影。代码如下:
if premise.issubset(reviews):if premise.issubset(reviews):
if conclusion in reviews:
correct_counts[candidate_rule] += 1
else:
incorrect_counts[candidate_rule] += 1rule_confidence = {candidate_rule: correct_counts[candidate_rule]
/ float(correct_counts[candidate_rule] +
incorrect_counts[candidate_rule])
for candidate_rule in candidate_rules}Rule #1
Rule: If a person recommends frozenset({64, 56, 98, 50, 7}) they will
also recommend 174
- Confidence: 1.000
Rule #2
Rule: If a person recommends frozenset({98, 100, 172, 79, 50, 56})
they will also recommend 7
- Confidence: 1.000
Rule #3
Rule: If a person recommends frozenset({98, 172, 181, 174, 7}) they
will also recommend 50
- Confidence: 1.000
Rule #4
Rule: If a person recommends frozenset({64, 98, 100, 7, 172, 50}) they
will also recommend 174
- Confidence: 1.000
Rule #5
Rule: If a person recommends frozenset({64, 1, 7, 172, 79, 50}) they
will also recommend 181
- Confidence: 1.000输出结果中只显示电影编号,而没有显示电影名字,很不友好。我们下载的数据集中的u.items文件里存储了电影名称和编号(还有体裁等信息)。
用pandas从u.items文件加载电影名称信息。关于该文件和类别的更多信息请见数据集中的 README文件。u.items文件为CSV格式,但是用竖线分隔数据。读取时需要指定分隔符,设置表 头和编码格式。每一列的名称是从README文件中找到的。
movie_name_filename = os.path.join(data_folder, "u.item")
movie_name_data = pd.read_csv(movie_name_filename, delimiter="|",
header=None, encoding = "mac-roman")
movie_name_data.columns = ["MovieID", "Title", "Release Date",
"Video Release", "IMDB", "", "Action", "Adventure",
"Animation", "Children's", "Comedy", "Crime", "Documentary",
"Drama", "Fantasy", "Film-Noir",
"Horror", "Musical", "Mystery", "Romance", "Sci-Fi", "Thriller",
"War", "Western"]
def get_movie_name(movie_id):title_object = movie_name_data[movie_name_data["MovieID"] ==
movie_id]["Title"]title = title_object.values[0]return title
for index in range(5):
print("Rule #{0}".format(index + 1))
(premise, conclusion) = sorted_confidence[index][0]
premise_names = ", ".join(get_movie_name(idx) for idx
in premise)
conclusion_name = get_movie_name(conclusion)
print("Rule: If a person recommends {0} they will
also recommend {1}".format(premise_names, conclusion_name))
print(" - Confidence: {0:.3f}".format(confidence[(premise,
conclusion)]))
print("")Rule #1
Rule: If a person recommends Shawshank Redemption, The (1994), Pulp
Fiction (1994), Silence of the Lambs, The (1991), Star Wars (1977),
Twelve Monkeys (1995) they will also recommend Raiders of the Lost Ark
(1981)
- Confidence: 1.000
Rule #2
Rule: If a person recommends Silence of the Lambs, The (1991), Fargo
(1996), Empire Strikes Back, The (1980), Fugitive, The (1993), Star
Wars (1977), Pulp Fiction (1994) they will also recommend Twelve
Monkeys (1995)
- Confidence: 1.000
Rule #3
Rule: If a person recommends Silence of the Lambs, The (1991), Empire
Strikes Back, The (1980), Return of the Jedi (1983), Raiders of the
Lost Ark (1981), Twelve Monkeys (1995) they will also recommend Star
Wars (1977)
- Confidence: 1.000
Rule #4
Rule: If a person recommends Shawshank Redemption, The (1994), Silence
of the Lambs, The (1991), Fargo (1996), Twelve Monkeys (1995), Empire
Strikes Back, The (1980), Star Wars (1977) they will also recommend
Raiders of the Lost Ark (1981)
- Confidence: 1.000
Rule #5
Rule: If a person recommends Shawshank Redemption, The (1994), Toy
Story (1995), Twelve Monkeys (1995), Empire Strikes Back, The (1980),
Fugitive, The (1993), Star Wars (1977) they will also recommend Return
of the Jedi (1983)
- Confidence: 1.000十三 小结
我们是Greaterwms软件开发团队。
项目介绍:
我们的产品是开源仓储管理软件,荣获gitee最有价值开源项目奖,评选为GVP项目
产品支持多仓,波次发货,合并拣货,Milk-Run等业务模型。前后端分离为完全开源项目。
软件著作权编号:2018SR517685
GitHub地址:github
Gitee地址: gitee
视频教程: bilibili
Demo地址:DEMO
商务联系:[email protected]
技术交流:GreaterWMS-01(加微信进群)