机器学习笔记之降维(三)从最大投影方差角度观察主成分分析
机器学习笔记之降维——从最大投影方差角度观察主成分分析
- 引言
-
- 回顾:样本均值与样本方差的矩阵表示
- 主成分分析
-
- 最大投影方差
- 基于最大投影方差的最优特征方向求解过程
- 总结
引言
上一节介绍了高维空间中样本均值和样本方差的矩阵表示。本节将介绍主成分分析,并从最大投影方差角度观察主成分分析。
回顾:样本均值与样本方差的矩阵表示
已知包含 N N N个样本的数据集合 X \mathcal X X,集合中各元素 x ( i ) ( i = 1 , 2 , ⋯ , N ) ∈ X x^{(i)} (i=1,2,\cdots,N)\in \mathcal X x(i)(i=1,2,⋯,N)∈X是 p p p维向量:
X = ( x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) ) T = ( x 1 ( 1 ) , x 2 ( 1 ) , ⋯ , x p ( 1 ) x 1 ( 2 ) , x 2 ( 2 ) , ⋯ , x p ( 2 ) ⋮ x 1 ( N ) , x 2 ( N ) , ⋯ , x p ( N ) ) N × p ; x ( i ) ∈ R p , i = 1 , 2 , ⋯ , N \mathcal X = \left(x^{(1)},x^{(2)},\cdots,x^{(N)}\right)^{T} = \begin{pmatrix}x_1^{(1)},x_2^{(1)},\cdots,x_p^{(1)} \\ x_1^{(2)},x_2^{(2)},\cdots,x_p^{(2)} \\ \vdots \\ x_1^{(N)},x_2^{(N)},\cdots,x_p^{(N)}\end{pmatrix}_{N \times p};x^{(i)} \in \mathbb R^p,i=1,2,\cdots,N X=(x(1),x(2),⋯,x(N))T=⎝ ⎛x1(1),x2(1),⋯,xp(1)x1(2),x2(2),⋯,xp(2)⋮x1(N),x2(N),⋯,xp(N)⎠ ⎞N×p;x(i)∈Rp,i=1,2,⋯,N
- 数据集合 X \mathcal X X的样本均值 X ˉ \bar {\mathcal X} Xˉ表示如下:
X ˉ p × 1 = 1 N ∑ i = 1 N x ( i ) = 1 N X T ⋅ I N \bar {\mathcal X}_{p \times 1} = \frac{1}{N} \sum_{i=1}^N x^{(i)} = \frac{1}{N} \mathcal X^{T} \cdot \mathcal I_N Xˉp×1=N1i=1∑Nx(i)=N1XT⋅IN
其中 I N \mathcal I_N IN表示各元素均为1的 N N N维列向量;样本均值 X ˉ \bar {\mathcal X} Xˉ是一个 p p p维向量;
I N = ( 1 , 1 , ⋯ , 1 ) N × 1 T \mathcal I_N = \left(1,1,\cdots,1\right)^{T}_{N \times 1} IN=(1,1,⋯,1)N×1T - 数据集合 X \mathcal X X的样本方差 S \mathcal S S表示如下:
S p × p = 1 N ∑ i = 1 N ( x ( i ) − X ˉ ) ( x ( i ) − X ˉ ) T = 1 N X T ⋅ H ⋅ X \begin{aligned} \mathcal S_{p \times p} & = \frac{1}{N} \sum_{i=1}^N (x^{(i)} - \bar {\mathcal X})(x^{(i)} - \bar {\mathcal X})^{T} \\ & = \frac{1}{N} \mathcal X^{T} \cdot \mathcal H \cdot \mathcal X \end{aligned} Sp×p=N1i=1∑N(x(i)−Xˉ)(x(i)−Xˉ)T=N1XT⋅H⋅X
其中 H \mathcal H H表示中心矩阵(Centering Matrix); E N \mathcal E_N EN表示 N N N阶单位向量;样本方差 S \mathcal S S是一个 p p p阶矩阵。
H = E N − 1 N I N I N T \mathcal H = \mathcal E_N - \frac{1}{N} \mathcal I_N\mathcal I_N^{T} H=EN−N1ININT
主成分分析
主成分分析(Principle Component Analysis),其核心是将一组可能线性相关的特征通过正交变换得到一组相互正交的 特征。换句话说,它是对 原始特征空间的重构:
假设样本集合 X \mathcal X X在样本空间中的表示如下:

import matplotlib.pyplot as plt
import random
import numpy as np
random.seed(1)
def f(x,y):
z = x + y + random.uniform(-0.75,0.75)
return [z,x + y]
x = list(np.linspace(0,1.5,100))
y = list(np.linspace(0,1.5,100))
z = [f(i,j)[0] for _,(i,j) in enumerate(zip(x,y))]
fig = plt.figure()
ax = fig.add_subplot(111,projection="3d")
plot_im = ax.plot(x,[f(i,j)[1] for _,(i,j) in enumerate(zip(x,y))],y,c="tab:orange")
im = ax.scatter(x,z,y,s=2,c="tab:blue")
plt.show()
从运行图像可知,上述图像中的样本点均在同一平面内,是否可以将该平面通过旋转,平移等操作将样本点所在平面与样本空间中的任一平面重合,重合后意味着 可以省略一个维度,并且不会丢失样本的特征信息。
上述图像描述的是一个‘极特殊情况’——所有样本点均在同一平面内,因而没有丢失信息。但一般情况下,如果噪声向其他维度延伸,导致降维操作在核心信息保留的基础上,依然会损失一定信息。
换句话说, z z z轴信息可以通过 x , y x,y x,y轴信息进行表示,即 z z z轴对于 x , y x,y x,y之间存在线性相关的情况;
而特征空间重构是基于样本内部维度特征之间可能存在线性相关的情况,从而通过正交变换,使可能存在线性相关的一组特征转换成相互正交的(必然也是线性无关的) 的一组新特征。
最大投影方差
最大投影方差是针对原始特征空间重构的一种角度的方法,其本质上是选择某一特征方向(轴),使得样本点在该轴上投影结果的方差达到最大。
依然以上图为例,在上述图像中增加一条线:
plot_im_2 = ax.plot([-1 * i + 2 for i in x],[f(i, j)[1] for _,(i,j) in enumerate(zip(x,y))],[-1 * i + 2 for i in y],c="tab:green")
对应图像结果如下图:

可以明显观察得到:蓝色样本点在绿色线上投影结果够成的范围明显小于橙色线上的范围。即样本点在绿色线上的投影方差更小。
可能橙色线也并不是最优特征方向,但相比于绿色线,它更接近最优特征方向。
假设橙色线就是要找的最优特征方向,我们称该特征方向为主成分(Principle Component)。
与该特征方向相垂直的特征方向与该特征方向组成一组正交基(2个);同理,我们同样可以找到与该正交基均垂直的第三个特征方向,从而构成一组新的正交基(3个),以此类推。
区别于原始的 x , y , z x,y,z x,y,z三轴,这组正交基就是重构后新的特征空间。
我们发现,这组新的正交基中每个特征方向的权重截然不同:
- 权重最高的是 橙色线对应的特征方向,因为其投影方差结果最大;
- 权重次之的是与橙色线相垂直条件下,投影方差最大的特征方向;
- 权重最小的是与上述两特征方向相垂直的其他特征方向,由于上述样本点均在同一平面内,但该特征方向已经垂直于样本点所在平面,因此其投影方差基本可以忽略不计。
同理,在高维空间中也会得到一组正交基,即两两相互正交的特征方向的集合。并且这些特征方向都是主成分。
在找到这些主成分之后,如果需要降维至 Q \mathcal Q Q维,仅需要找到前 Q \mathcal Q Q个权重最高的主成分,剩余的主成分被忽略掉。
降维过程中可能出现特征信息丢失的原因。
基于最大投影方差的最优特征方向求解过程
如何找到最优特征方向?具体步骤描述如下:
-
将当前数据集合中的样本中心化:将所有样本点平移至样本空间的中心位置,而样本之间的相对位置不发生变化。
针对数据集合 X \mathcal X X中的任意样本点 x ( i ) ∈ X x^{(i)} \in \mathcal X x(i)∈X,中心化后的样本点结果表示如下:
x ^ ( i ) = x ( i ) − X ˉ \hat {x}^{(i)} = x^{(i)} - \bar {\mathcal X} x^(i)=x(i)−Xˉ -
针对中心化后的样本,计算 x ^ ( i ) \hat {x}^{(i)} x^(i)关于 某向量 u ⃗ \vec {u} u(某特征方向) 的投影结果 x S ( i ) x^{(i)}_{\mathcal S} xS(i):
令向量 u ⃗ \vec {u} u的模 ∣ u ⃗ ∣ = 1 |\vec {u}| = 1 ∣u∣=1, x ^ ( i ) \hat {x}^{(i)} x^(i)关于 u ⃗ \vec {u} u的投影结果及对应图像表示如下:
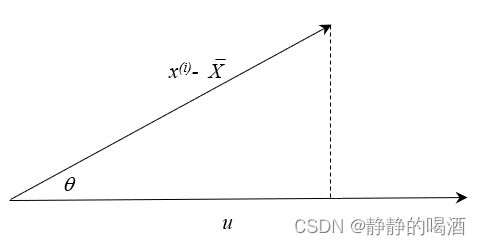
x S ( i ) = ∣ x ^ ( i ) ∣ ⋅ ∣ u ⃗ ∣ ⋅ cos θ = ∣ x ^ ( i ) ∣ ⋅ cos θ \begin{aligned} x^{(i)}_{\mathcal S} & = |\hat {x}^{(i)}| \cdot |\vec u| \cdot \cos \theta \\ & = |\hat {x}^{(i)}| \cdot \cos \theta \end{aligned} xS(i)=∣x^(i)∣⋅∣u∣⋅cosθ=∣x^(i)∣⋅cosθ
其中 ∣ x ^ ( i ) ∣ |\hat {x}^{(i)}| ∣x^(i)∣表示中心化后向量 x ^ ( i ) \hat {x}^{(i)} x^(i)的模; θ \theta θ表示 x ^ ( i ) \hat {x}^{(i)} x^(i)和 u ⃗ \vec {u} u之间的夹角。
而根据向量的乘法公式,向量 x ^ ( i ) \hat {x}^{(i)} x^(i)与向量 u ⃗ \vec {u} u之间的乘法结果表示如下:
x ^ ( i ) \hat {x}^{(i)} x^(i)在u ⃗ \vec{u} u的投影结果就是x ^ ( i ) \hat {x}^{(i)} x^(i)和u ⃗ \vec{u} u的向量乘积结果。
x ^ ( i ) ⋅ u ⃗ = ∣ x ^ ( i ) ∣ ⋅ ∣ u ⃗ ∣ ⋅ cos θ = ∣ x ^ ( i ) ∣ ⋅ cos θ = x S ( i ) \begin{aligned} \hat {x}^{(i)} \cdot \vec {u} & = |\hat {x}^{(i)}| \cdot |\vec u| \cdot \cos \theta \\ & = |\hat {x}^{(i)}| \cdot \cos \theta \\ & = x^{(i)}_{\mathcal S} \end{aligned} x^(i)⋅u=∣x^(i)∣⋅∣u∣⋅cosθ=∣x^(i)∣⋅cosθ=xS(i)
由于投影结果是一个标量,因此,更容易将投影结果表示为如下形式:
x S ( i ) = [ x ^ ( i ) ] T ⋅ u ⃗ = ( x ( i ) − X ˉ ) 1 × p T ⋅ u ⃗ p × 1 \begin{aligned} x^{(i)}_{\mathcal S} & = \left[\hat x^{(i)}\right]^{T} \cdot \vec u \\ & = \left(x^{(i)} - \bar {\mathcal X}\right)^{T}_{1 \times p} \cdot \vec u_{p \times 1} \end{aligned} xS(i)=[x^(i)]T⋅u=(x(i)−Xˉ)1×pT⋅up×1
注意,此时的 u ⃗ \vec {u} u存在约束条件,即 ∣ u ⃗ ∣ = 1 |\vec {u}| = 1 ∣u∣=1:
向量的模可以随意变化,但方向不会。这里为简化运算,设定其模为1。
s . t . ∣ u ⃗ ∣ = u ⃗ T ⋅ u ⃗ = 1 s.t.\quad |\vec {u}| = \vec {u} ^{T} \cdot \vec {u} = 1 s.t.∣u∣=uT⋅u=1 -
当投影结果计算结束后,继续计算投影结果的方差:
- 由于 x ( i ) x^{(i)} x(i)中心化后 投影的均值为 0 0 0:
其中μ S \mu_{\mathcal S} μS表示‘投影均值’。
μ S = 1 N ∑ i = 1 N x S ( i ) = 1 N ∑ i = 1 N [ ( x ( i ) − X ˉ ) T ⋅ u ⃗ ] \begin{aligned} \mu_{\mathcal S} & = \frac{1}{N} \sum_{i=1}^N x_{\mathcal S}^{(i)} \\ & = \frac{1}{N} \sum_{i=1}^N \left[\left(x^{(i)} - \bar {\mathcal X}\right)^{T} \cdot \vec {u}\right] \end{aligned} μS=N1i=1∑NxS(i)=N1i=1∑N[(x(i)−Xˉ)T⋅u]
并且上述每一项中均含 u ⃗ \vec {u} u,并且 u ⃗ \vec {u} u与 N N N无关,因此,将 u ⃗ \vec {u} u提出来:
μ S = [ 1 N ∑ i = 1 N ( x ( i ) − X ˉ ) T ] ⋅ u ⃗ \mu_{\mathcal S} = \left[\frac{1}{N} \sum_{i=1}^N \left(x^{(i)} - \bar {\mathcal X}\right)^{T}\right] \cdot \vec u μS=[N1i=1∑N(x(i)−Xˉ)T]⋅u
观察中括号内的项:
X ˉ \bar {\mathcal X} Xˉ和N N N无关。
1 N ∑ i = 1 N ( x ( i ) − X ˉ ) T = 1 N ∑ i = 1 N x ( i ) − 1 N ⋅ N ⋅ X ˉ = X ˉ − X ˉ = 0 \begin{aligned} \frac{1}{N} \sum_{i=1}^N \left(x^{(i)} - \bar {\mathcal X}\right)^{T} & = \frac{1}{N} \sum_{i=1}^N x^{(i)} - \frac{1}{N} \cdot N \cdot \bar {\mathcal X} \\ & = \bar {\mathcal X} - \bar {\mathcal X} \\ & = 0 \end{aligned} N1i=1∑N(x(i)−Xˉ)T=N1i=1∑Nx(i)−N1⋅N⋅Xˉ=Xˉ−Xˉ=0
从而有:
μ S = 0 ⋅ u ⃗ = 0 \mu_{\mathcal S} = 0 \cdot \vec{u} = 0 μS=0⋅u=0 - 投影结果的方差表示如下:
S S ( i ) \mathcal S_{\mathcal S}^{(i)} SS(i)表示'投影结果'x S ( i ) x_{\mathcal S}^{(i)} xS(i)的方差结果。
S S ( i ) = ( x S ( i ) − μ S ) ⋅ ( x S ( i ) − μ S ) T = ( x S ( i ) ) 2 = [ ( x ( i ) − X ˉ ) T ⋅ u ⃗ ] 2 \begin{aligned} \mathcal S_{\mathcal S}^{(i)} & = \left(x_{\mathcal S}^{(i)} - \mu_{\mathcal S}\right)\cdot \left(x_{\mathcal S}^{(i)} - \mu_{\mathcal S}\right)^{T} \\ & = \left(x_{\mathcal S}^{(i)}\right)^2 \\ & = \left[(x^{(i)} - \bar {\mathcal X})^{T} \cdot \vec {u}\right]^2 \end{aligned} SS(i)=(xS(i)−μS)⋅(xS(i)−μS)T=(xS(i))2=[(x(i)−Xˉ)T⋅u]2
- 由于 x ( i ) x^{(i)} x(i)中心化后 投影的均值为 0 0 0:
-
由于 S S ( i ) \mathcal S_{\mathcal S}^{(i)} SS(i)仅是中心化后的样本点 x ( i ) − X x^{(i)} - \mathcal X x(i)−X在 u ⃗ \vec {u} u上的投影方差,因而 样本空间中所有样本点在 u ⃗ \vec {u} u中投影方差总和 J \mathcal J J表示如下:
J = 1 N ∑ i = 1 N S S ( i ) = 1 N ∑ i = 1 N [ ( x ( i ) − X ˉ ) T ⋅ u ⃗ ] 2 = 1 N ∑ i = 1 N [ ( x ( i ) − X ˉ ) T ⋅ u ⃗ ] T ⋅ [ ( x ( i ) − X ˉ ) T ⋅ u ⃗ ] = 1 N ∑ i = 1 N u ⃗ T ( x ( i ) − X ˉ ) ⋅ ( x ( i ) − X ˉ ) T u ⃗ \begin{aligned} \mathcal J & = \frac{1}{N}\sum_{i=1}^N \mathcal S_{\mathcal S}^{(i)} \\ & = \frac{1}{N} \sum_{i=1}^N \left[(x^{(i)} - \bar {\mathcal X})^{T} \cdot \vec {u}\right]^2 \\ & = \frac{1}{N} \sum_{i=1}^N \left[(x^{(i)} - \bar {\mathcal X})^{T} \cdot \vec {u}\right]^{T} \cdot \left[(x^{(i)} - \bar {\mathcal X})^{T} \cdot \vec {u}\right] \\ & = \frac{1}{N} \sum_{i=1}^N \vec {u}^{T} \left(x^{(i)} - \bar {\mathcal X}\right) \cdot \left(x^{(i)} - \bar {\mathcal X}\right)^{T}\vec {u} \end{aligned} J=N1i=1∑NSS(i)=N1i=1∑N[(x(i)−Xˉ)T⋅u]2=N1i=1∑N[(x(i)−Xˉ)T⋅u]T⋅[(x(i)−Xˉ)T⋅u]=N1i=1∑NuT(x(i)−Xˉ)⋅(x(i)−Xˉ)Tu
因为 u ⃗ \vec {u} u是特征方向,与 N N N无关;因此上式可以继续化简:
J = u ⃗ T ⋅ [ 1 N ∑ i = 1 N ( x ( i ) − X ˉ ) ( x ( i ) − X ˉ ) T ] ⋅ u ⃗ \mathcal J = \vec {u}^{T} \cdot \left[\frac{1}{N} \sum_{i=1}^N \left(x^{(i)} - \bar {\mathcal X}\right)\left(x^{(i)} - \bar {\mathcal X}\right)^{T}\right] \cdot \vec {u} J=uT⋅[N1i=1∑N(x(i)−Xˉ)(x(i)−Xˉ)T]⋅u
中括号内的项是样本集合 X \mathcal X X的协方差矩阵,最终样本投影方差总和 J \mathcal J J可化简为:
J = u ⃗ T ⋅ S ⋅ u ⃗ \mathcal J = \vec {u}^{T} \cdot \mathcal S \cdot \vec {u} J=uT⋅S⋅u -
至此,将最大投影方差思想总结为如下 优化问题:
{ u ^ = arg max u ⃗ J s . t . u ⃗ T ⋅ u ⃗ = 1 \begin{cases} \hat {u} = \mathop{\arg\max}\limits_{\vec u} \mathcal J \\ s.t. \quad \vec {u} ^{T} \cdot \vec {u} = 1 \end{cases} ⎩ ⎨ ⎧u^=uargmaxJs.t.uT⋅u=1
使用拉格朗日乘数法处理该问题:
L ( u ⃗ , λ ) = u ⃗ T ⋅ S ⋅ u ⃗ + λ ( 1 − u ⃗ T ⋅ u ⃗ ) \mathcal L(\vec u,\lambda) = \vec {u}^{T} \cdot \mathcal S \cdot \vec {u} + \lambda (1 - \vec {u} ^{T} \cdot \vec {u}) L(u,λ)=uT⋅S⋅u+λ(1−uT⋅u)
对 u ⃗ \vec {u} u求解偏导,并令导数结果为 0 0 0:
这里依然用到矩阵的求导公式~
∂ L ( u ⃗ , λ ) ∂ u ⃗ ≜ 0 → 2 S ⋅ u ⃗ − 2 λ ⋅ u ⃗ = 0 → S ⋅ u ⃗ = λ ⋅ u ⃗ \frac{\partial \mathcal L(\vec u,\lambda)}{\partial \vec u} \triangleq 0 \to 2\mathcal S \cdot \vec u - 2\lambda \cdot \vec u = 0 \\ \to \mathcal S \cdot \vec u = \lambda \cdot \vec u ∂u∂L(u,λ)≜0→2S⋅u−2λ⋅u=0→S⋅u=λ⋅u
观察该式, λ \lambda λ求解结果就是样本集合 X \mathcal X X的协方差矩阵 S \mathcal S S的特征值(Engen Value),当求得协方差矩阵 S \mathcal S S的最大特征值时,样本投影方差总和 J \mathcal J J达到最大。此时,最大特征值对应的特征向量就是最优特征方向,即第一个主成分;
同理,第二个主成分是 第一个主成分正交的特征向量,也就是第二大特征值对应的特征向量;第三个主成分就是分别与第一、第二主成分两两正交的特征向量,以此类推。
总结
- 在极特殊(样本分布足够简单)的条件下,利用特征空间重构降维不会损失特征信息,一般情况下,混损失部分特征信息;
- 主成分并非代表一个特征方向,而是一组正交基,可以看成一组两两相互正交的向量构成的新的特征空间;
- 只需要求出最优的特征方向,后续的主成分均可通过上一个特征向量的正交空间中找到。并满足新特征向量与之前找出的特征量两两相互正交。
相关参考:
降维算法-从最大化投影方差角度看主成分分析
机器学习-降维3-主成分分析(PCA)-最大投影方差角度