我的机器学习笔记(三)--- 分类问题与K近邻算法
文章目录
- 一、分类问题的定义
- 二、分类问题的类型
-
- 2.1 二分类问题
- 2.2 多分类问题
- 三、常用的分类算法
- 四、模型分类器的实现
-
- 4.1 模型的构建
- 4.2 模型的使用
- 五、K近邻算法
-
- 5.1 K近邻算法的概念
- 5.2 K近邻算法的伪代码
- 5.3 K近邻算法的原理
- 5.4 K近邻算法的举例
- 5.5 K近邻模型的特点
- 5.6 K近邻模型的语法
- 六、K近邻算法案例 --- 鸢尾花分类
-
- 6.1 案例背景
- 6.2 案例实现
我的机器学习笔记(三)— 分类问题与K近邻算法
一、分类问题的定义;
二、分类问题的类型;
三、常用的分类算法;
四、模型分类器的实现;
五、K近邻算法;
六、K近邻算法案例 — 鸢尾花分类。
一、分类问题的定义
分类问题是监督学习的一个核心问题,它从数据中学习一个分类决策函数或分类模型分类器(classifier),对新的输入进行输出预测,输出变量取有限个离散值。
二、分类问题的类型
两种类型
- 二分类问题
- 多分类问题
2.1 二分类问题
- 银行根据客户以往贷款记录情况,学习得到分类器,将客户分为低风险客户和高风险客户。
- 对一个新来的申请者,根据分类器计算风险,决定接受或拒绝该申请。
2.2 多分类问题
- 分析影响变压器正常运行的因素,预测变压器是否有故障,若有故障,故障为放电故障、过热故障、短路故障的哪一种。
三、常用的分类算法
- K近邻 – KNN
- 决策树
- 支持向量机模型 – SVM
四、模型分类器的实现
两个步骤
- 模型的构建
- 类别标记 — 预测变量、目标值
- 训练模型
- 表示
- 模型的使用
- 识别目标值
- 正确性评价
- 避免过拟合
4.1 模型的构建
- 对每个样本进行类别标记
- 训练集构成分类模型
- 分类模型可表示为
- 分类规则
- 决策树
- 数据公式

4.2 模型的使用
- 识别未知对象的所属类别
- 模型正确性评价
- 已标记分类的测试样本与模型的实际分类结果进行比较。
- 模型的正确率是指测试集中被正确分类的样本数与样本总数的百分比。
- 注意:测试集与训练集相分离,否则将出现**过拟合(over-fitting)**现象。
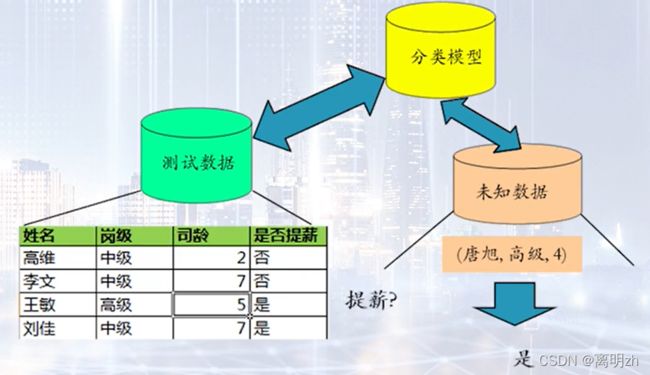
五、K近邻算法
5.1 K近邻算法的概念
K近邻算法(K Nearest Neighbors,简称KNN)通过计算每个训练数据到待分类元组的举例,取和待分类元组距离最近的K个训练数据,K个数据中哪个类别的训练数据占多数,则待分类元组就属于哪个类别。
5.2 K近邻算法的伪代码

5.3 K近邻算法的原理
-
给定一个训练数据集,无需训练
-
对新的输入实例,在训练数据集中找到与该实例最近邻的K个实例
-
根据这K个实例的类别做投票,哪个类的实例最多,就把该输入实例分到这个类中
5.4 K近邻算法的举例
- 例1

- 如果K=3,绿点最邻近的3个点分别是2红、1蓝,投票后判断绿点属于红色类。
- 如果K=5,绿点最邻近的5个点分别是2红、3蓝,投票后判定绿点属于蓝色类。
- 由此可见,K值的选择,对分类结果有很大影响!
- 例2
-
身高与脚码作为特征,判断性别。现有数据如下:
- A[(179,42),男]
- B[(178,43),男]
- C[(165,36),女]
- D[(177,42),男]
- E[(160,35),女]
-
现在测试样本F[(167,43)]。
-
令K=3,分别算出F离训练样本距离(欧式距离)

-
选取最近的3个为C,D,E,2女1男,因此判断为女性。
-
-
很不合理!!! 理由:特征”身高“的绝对值太大,很容易主导数据波动,从而影响结果。 —>通常需要做数据的 “归一化” 处理。
5.5 K近邻模型的特点
- 建模快 — 只是简单地存储数据
- 运行速度慢 — 需要计算很多的距离
- 占用内存多 — 数据集大时
5.6 K近邻模型的语法
-
导入 包含分类方法的 类:
from sklearn.neighbors import KNeighborsClassifier
-
创建 该类的一个 对象:
KNN = KNeighborsClassifier(n_neighbors=3)
-
拟合 数据集,即训练KNN模型,并用训练好的模型预测数据的标签:
KNN = KNN.fit(x_train,y_train)
y_predict = KNN.predict(x_test)
- 具体含义可参见文档:
- https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
六、K近邻算法案例 — 鸢尾花分类
6.1 案例背景
-
150株鸢尾花样例
-
来自3个不同的属种
- Setosa,Versicolor,Virginica
- 每种50株样例
-
用4个特征度量
-
花萼的长度和宽度,花瓣的长度和宽度

-
-
分类问题:给定一株鸢尾花,判定其属种
-
鸢尾花案例数据如下:
- Machine_Learning/iris.csv at master · itliming2000/Machine_Learning (github.com)
6.2 案例实现
-
导包
import numpy as np import matplotlib.pyplot as plt import pandas as pd -
数据预处理
- 特征抽取
- 特征选择
- 降维
- 抽样
读取文件:
url = "iris.csv" # iris.csv放在与案例.ipynb同级目录下
# Assign colum names to the dataset --- #为数据集指定列名
names = ['sepal-length','sepal-width','petal-length','petal-width','Class']
# Read dataset to pandas dataframe --- 读取数据集以接收数据帧
dataset = pd.read_csv(url,names=names) # 读取文件,添加别名给列
dataset.head() # 取数据的前n行数据,默认是前5行
运行后,显示结果:

切片:
x = dataset.iloc[:,:-1].values # [:,:-1],切片所有行,从0到倒数第1列,不包括倒数第一列
y = dataset.iloc[:,4].values # [:,:-1],切片所有行,第4列
随机划分训练集和测试集:
# 用train_test_split函数随机划分出训练集和测试集,测试集占比0.20
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.20)
归一化和标准化处理:
# StandardScaler函数处理数据归一化和标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# fit() -- 方法计算参数μ和σ,并将它们保存为内部对象。
scaler.fit(x_train) # 即求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性
# transform() -- 方法使用这些计算参数将转换应用于特定的数据集。
x_train = scaler.transform(x_train) # 在fit的基础上,进行标准化,降维,归一化等操作
x_test = scaler.transform(x_test)
- 学习
训练模型:
# KNeighborsClassifier类 --- KNN算法
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5) # 创建一个对象,设置近邻数为5的
classifier.fit(x_train,y_train) # 使用x_train作为训练数据,y_train作为目标值(类似于标签)来拟合KNN模型
运行后,显示结果:
![]()
测试:
y_pred = classifier.predict(x_test) # 给提供的测试数据集x_test预测对应的标签
- 评价
对测试结果进行评价:
# 使用混淆矩阵和文本报告进行评价
from sklearn.metrics import classification_report,confusion_matrix
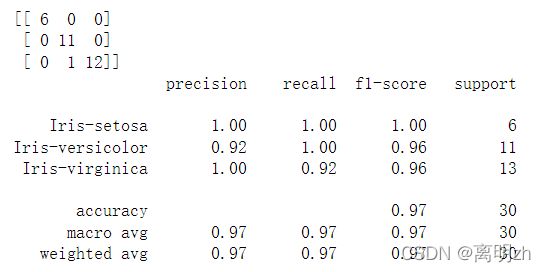
print(confusion_matrix(y_test,y_pred)) # 混淆矩阵 -- 通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的
print(classification_report(y_test,y_pred)) # 显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息
运行后,显示结果:
对不同的K取值评价:
# 对不同的K取值评价
error = []
# Calculating error for K values between 1 and 40 --- K值在1到40之间的计算误差
for i in range(1,40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train,y_train)
pred_i = knn.predict(x_test)
error.append(np.mean(pred_i != y_test)) # 比较两数组对应值,满足条件取true(1),否则取false(0),最后取平均值
error
运行后,显示结果:

- 可视化
# 使用matplotlib绘图库实现可视化
plt.figure(figsize=(12,6)) # 指定figure的宽和高,单位为英寸
plt.plot(range(1,40),error,color='red',linestyle='dashed',marker='o',
markerfacecolor='blue',markersize=10)
plt.title('Error Rate K Value') # 标题
plt.xlabel('K Value') # x轴坐标
plt.ylabel('Mean Error') # y轴坐标
运行后,显示结果:
