GPT系列简介与gpt训练(nanoGPT)
generateivelt pre-trained transformer ,GPT使用transformer做特征提取行,单项语言模型作为训练任务
gpt 1.0
通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果
gpt2.0
GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据(表1)。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(Prompt Learning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为“AI界最危险的武器”,很多门户网站也命令禁止使用GPT-2生成的新闻。
gpt3.0
GPT-3除了能完成常见的NLP任务外,研究者意外的发现GPT-3在写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
gpt3.5
2022.3.15
text-davinci-003,code-davinci-002
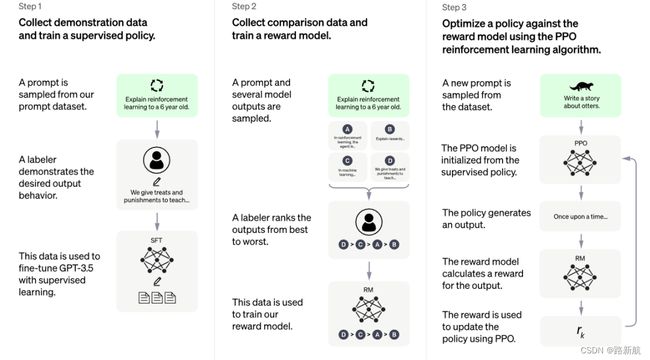
InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。
InstructGPT
2022.3,InstructGPT 利用了人类反馈的强化学习方法(RLHF)对 GPT-3 进行微调,使得该模型的输出更加符合人类偏好。
chatgpt
AI chatbot,2022.10.30
ChatGPT是一种基于人工智能技术的自然语言生成模型,具有广泛的应用。
可以编程,debug程序,编音乐,电视剧,童话,论文。回答问题(有时取决于用户水平),写诗写歌。模仿linux程序,模仿聊天室,玩游戏,模仿ATM
具体:
以下是ChatGPT的20种用法:
智能客服:ChatGPT可以用于模拟人类客服的对话,为用户提供个性化的客户服务。
聊天机器人:ChatGPT可以与用户进行自然流畅的对话,提供各种服务和帮助。
语音助手:ChatGPT可以用于语音助手的对话生成和处理。
智能问答系统:ChatGPT可以用于自动回答问题,提供快速和准确的答案。
机器翻译:ChatGPT可以用于自动翻译不同语言之间的文本和对话。
摘要生成:ChatGPT可以根据文章的主题和内容生成简洁的摘要。
文本生成:ChatGPT可以用于生成各种文本,包括新闻、小说、诗歌等。
文档自动生成:ChatGPT可以自动为用户生成各种文档,如报告、论文、合同等。
垃圾邮件过滤:ChatGPT可以识别和过滤垃圾邮件,提高邮件的质量。
电子商务推荐:ChatGPT可以根据用户的购买历史和兴趣推荐相应的产品。
金融风险评估:ChatGPT可以根据财经数据和市场趋势预测金融风险。
医疗辅助诊断:ChatGPT可以根据患者的病症和病史提供诊断建议。
舆情分析:ChatGPT可以根据社交媒体和新闻等来源分析公众舆情。
知识图谱构建:ChatGPT可以通过自然语言理解和知识图谱技术构建大规模的知识库。
智能家居控制:ChatGPT可以通过语音识别和对话生成技术控制智能家居设备。
游戏AI:ChatGPT可以用于游戏AI的对话生成和决策。
媒体内容生成:ChatGPT可以生成各种媒体内容,如图片、音频和视频等。
职业培训:ChatGPT可以用于职业培训的自动问答和知识点解析。
情感分析:ChatGPT可以根据对话和文本内容进行情感分析。
智能广告推荐:ChatGPT可以根据用户的兴趣生成广告内容。
2023.3发布插件
-
ChatGPT for Google
-
WebChatGPT
这个插件可以帮助 ChatGPT 获取最新的网络资讯。
由于chatGPT 的数据只到2021年,缺失了之后的数据,这款插件就很好的弥补了这个缺陷
-
Luna:
这个插件可以帮助你理解专有名词和术语。看到不懂的直接在网页上右键,就能进入chatgpt 进行查询 -
ChatGPT Prompt Genius:
这个插件可以让你将 ChatGPT 的回复存储为 PNG 图像和 MD 或 PDF 文件。
限制:
会一本正经编造事实
2021.9月后的事情就不知道了
不被允许表达政治立场
更倾向使用长文本回答,不管问题是否复杂
还是有一定偏见(数据和算法偏见)
visual chatgpt
微软亚洲研究院
(将 Transformers、ControlNet 和 Stable Diffusion 等视觉基础模型 (VFM) 与 ChatGPT 相结合)
使用户能够通过聊天发送消息并在聊天期间接收图像。它还允许他们通过添加一系列视觉模型提示来编辑图像。
GPT-3.5-turbo
costs $0.002 per 1000 tokens (that’s about 750 words)
付费帐号可以享受:
- 高流量时拥有优先使用权
- 更快的回应速度
- 优先享受新功能
- 可选用Turbo model 加快回应速度
gpt4
2023.3.14 ChatGPT Plus发布
“more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5.
two versions of GPT-4 with context windows of 8,192 and 32,768 tokens”
GPT4是多模态模型,可以处理文本和图片
与ChatGPT最初使用的GPT-3.5模型相比,GPT-4在几个方面实现了跨越式改进:强大的图像识别能力;文本输入限制增加到 25,000 字;回答准确率显着提高;生成歌词的能力,创意文本,实现风格变化。
others
OpenAI:
DALL-E2
Whisper AI
GPT实践
naroGPT实践
https://github.com/karpathy/nanoGPT.git
git clone https://github.com/karpathy/nanoGPT.git
python train.py
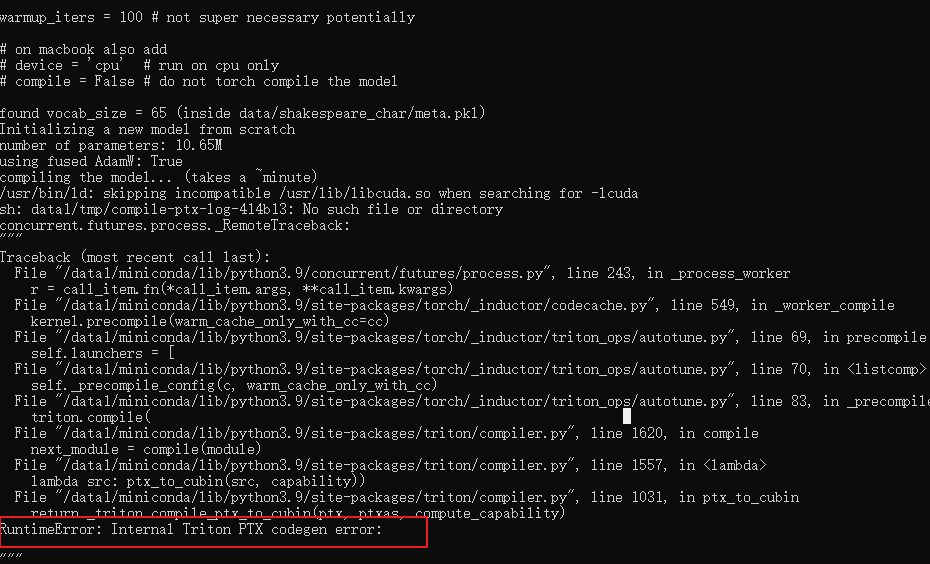
第二次执行就欧克了
默认迭代次数max_iters = 600000 ,可以自行修改
val loss先减小,后增大
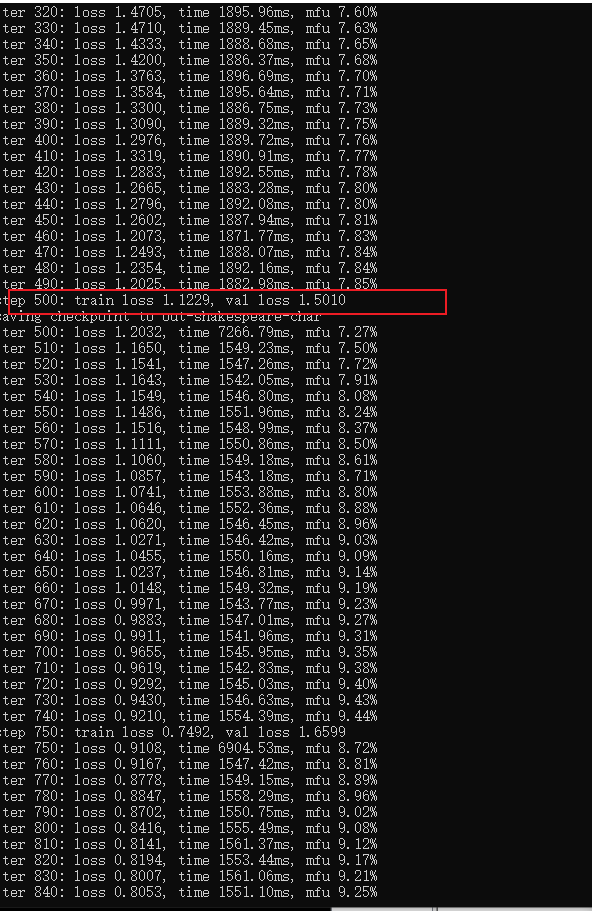
本次测试迭代了3000次,
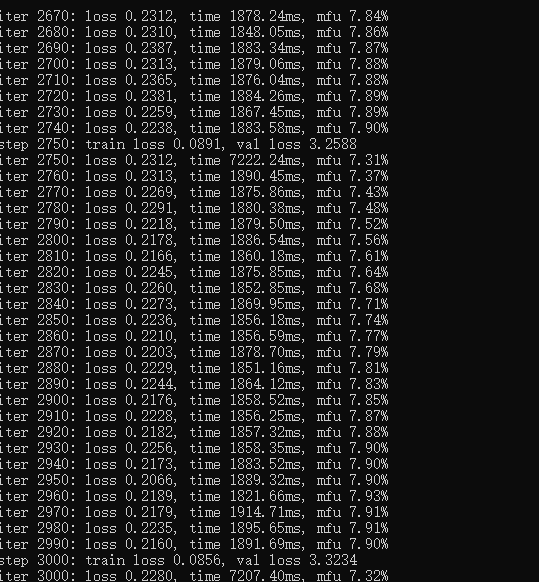
结果: python sample.py --out_dir=out-shakespeare-char
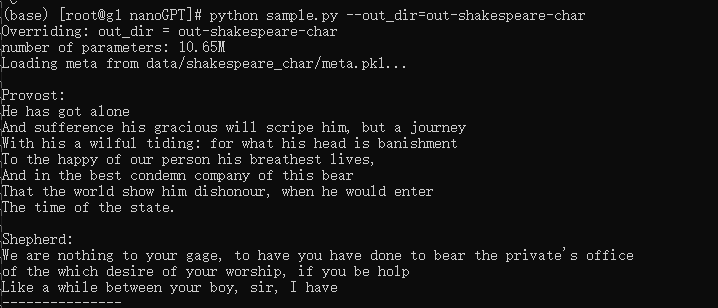
训练数据由莎士比亚更换成小王子
mkdir little_price
mkdir little_price_char
prepare.py文件内容:
"""
Prepare the Shakespeare dataset for character-level language modeling.
So instead of encoding with GPT-2 BPE tokens, we just map characters to ints.
Will save train.bin, val.bin containing the ids, and meta.pkl containing the
encoder and decoder and some other related info.
"""
import os
import pickle
import requests
import numpy as np
# download the tiny shakespeare dataset
input_file_path = os.path.join(os.path.dirname(__file__), '../little_price/input.txt')
if not os.path.exists(input_file_path):
data_url = 'https://linguabooster.com/en/en/book/download/little-prince'
with open(input_file_path, 'w') as f:
f.write(requests.get(data_url).text)
# UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 2921: illegal multibyte sequence
with open(input_file_path, 'r', encoding= 'utf8') as f:
data = f.read()
print(f"length of dataset in characters: {len(data):,}")
# get all the unique characters that occur in this text
chars = sorted(list(set(data)))
vocab_size = len(chars)
print("all the unique characters:", ''.join(chars))
print(f"vocab size: {vocab_size:,}")
# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
def encode(s):
return [stoi[c] for c in s] # encoder: take a string, output a list of integers
def decode(l):
return ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
# create the train and test splits
n = len(data)
train_data = data[:int(n*0.9)]
val_data = data[int(n*0.9):]
# encode both to integers
train_ids = encode(train_data)
val_ids = encode(val_data)
print(f"train has {len(train_ids):,} tokens")
print(f"val has {len(val_ids):,} tokens")
# export to bin files
train_ids = np.array(train_ids, dtype=np.uint16)
val_ids = np.array(val_ids, dtype=np.uint16)
train_ids.tofile(os.path.join(os.path.dirname(__file__), '../little_price_char/train.bin'))
val_ids.tofile(os.path.join(os.path.dirname(__file__), '../little_price_char/val.bin'))
# save the meta information as well, to help us encode/decode later
meta = {
'vocab_size': vocab_size,
'itos': itos,
'stoi': stoi,
}
with open(os.path.join(os.path.dirname(__file__), '../little_price_char/meta.pkl'), 'wb') as f:
pickle.dump(meta, f)
# 10倍小
# length of dataset in characters: 91,897
# all the unique characters:
# !"$'(),-.0123456789:;?ABCDEFGHIJKLMNOPRSTUVWXYZabcdefghijklmnopqrstuvwxyzï—…
# vocab size: 78
# train has 82,707 tokens
# val has 9,190 tokens
vim config/train_the_little_prince_char.py
# train a miniature character-level little_price model
# good for debugging and playing on macbooks and such
out_dir = 'out-little_price-char'
eval_interval = 250 # keep frequent because we'll overfit
eval_iters = 200
log_interval = 10 # don't print too too often
# we expect to overfit on this small dataset, so only save when val improves
always_save_checkpoint = False
wandb_log = False # override via command line if you like
wandb_project = 'little_price-char'
wandb_run_name = 'mini-gpt'
dataset = 'little_price_char'
batch_size = 64
block_size = 256 # context of up to 256 previous characters
# baby GPT model :)
n_layer = 6
n_head = 6
n_embd = 384
dropout = 0.2
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
max_iters = 5000
lr_decay_iters = 5000 # make equal to max_iters usually
min_lr = 1e-4 # learning_rate / 10 usually
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
warmup_iters = 100 # not super necessary potentially
# on macbook also add
device = 'cpu' # run on cpu only
compile = False # do not torch compile the model
train cpu训练
python train.py config/train_little_prince_char.py --compile=False --eval_iters=20 --log_interval=1 --block_size=64 --batch_size=12 --n_layer=4 --n_head=4 --n_embd=128 --max_iters=2000 --lr_decay_iters=2000 --dropout=0.0
250次
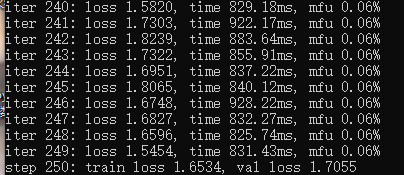
500次
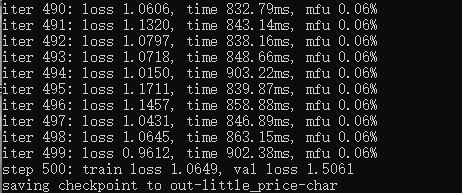
之后loss一直在变大
![]()
![]()
效果
python sample.py --out_dir=out-little_prince-char
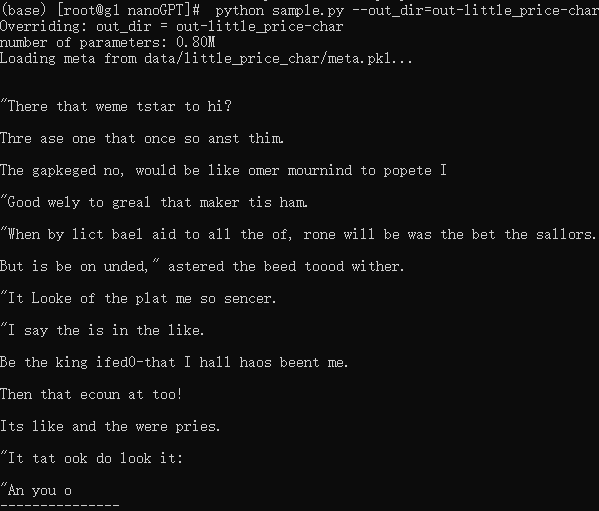
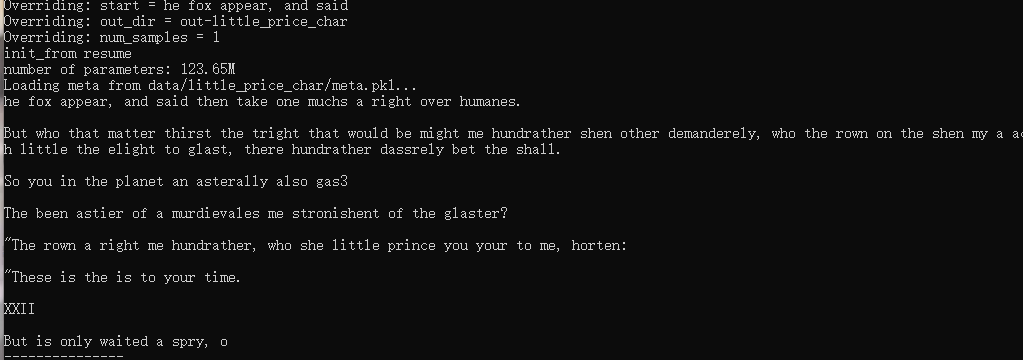
python sample.py --start="the fox appear, and said" --out_dir="out-little_price-char"

与gpt2对比
python sample.py --start="the fox appear, and said" --init_from=gpt2-xl
报错
Can't load config for 'gpt2'. If you were trying to load it from 'https://huggingface.co/models'
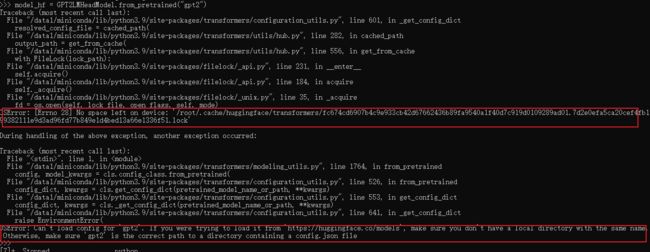
1.磁盘不足
2.不是第一次下载 文件名重复(?)
清除缓存文件 rm -rf /root/.cache/huggingface/transformers
或者更改缓存目录export HF_DATASETS_CACHE="/data1/tmp" https://huggingface.co/docs/datasets/cache
from transformers import GPT2LMHeadModel
model_hf = GPT2LMHeadModel.from_pretrained("gpt2")

执行中会下载模型,下载模型是单线程,不要同时下载huggingface多个模型

finetune
finetune_little_prince.py
import time
out_dir = 'out-little_prince'
eval_interval = 5
eval_iters = 40
wandb_log = False # feel free to turn on
wandb_project = 'little_prince'
wandb_run_name = 'ft-' + str(time.time())
dataset = 'little_prince'
init_from = 'gpt2-xl' # this is the largest GPT-2 model
# only save checkpoints if the validation loss improves
always_save_checkpoint = False
# the number of examples per iter:
# 1 batch_size * 32 grad_accum * 1024 tokens = 32,768 tokens/iter
# little_prince has 301,966 tokens, so 1 epoch ~= 9.2 iters
batch_size = 1
gradient_accumulation_steps = 32
max_iters = 20
# finetune at constant LR
learning_rate = 3e-5
decay_lr = False
python train.py config/finetune_little_prince.py
发现磁盘空间不足 cd / && du -h -x --max-depth=1
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
Cannot create temporary file in /tmp/: No space left on device
,发现是docker磁盘炸裂,清理磁盘
开始训练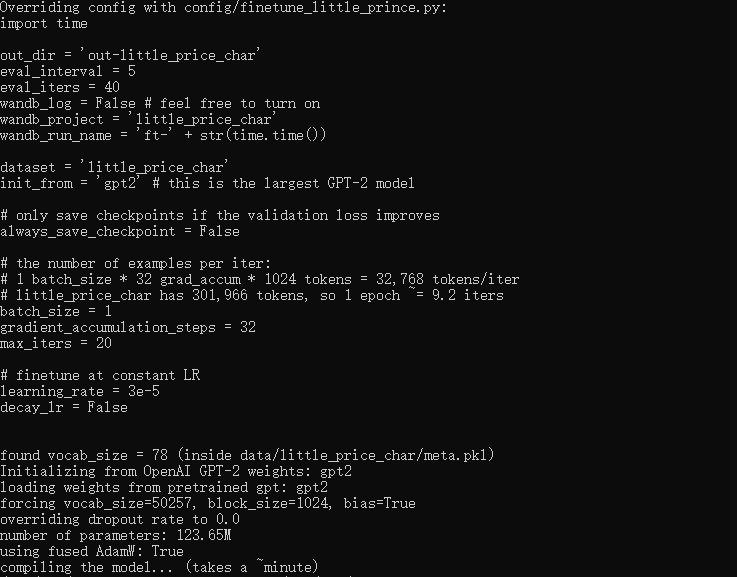
20次结果
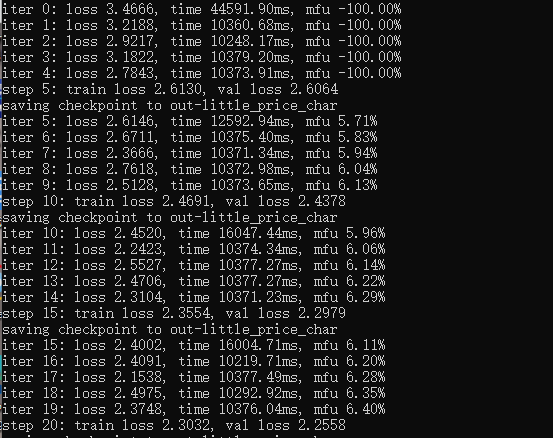
检验:
执行sample报错可能是因为cuda被两个文件同时访问,报错RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling cublasCreate(handle)
python sample.py --start="the fox appear, and said" --out_dir="out-little_price_char"
报错
decode = lambda l: ''.join([itos[i] for i in l])
KeyError
更改prompt 参考:https://github.com/karpathy/nanoGPT/issues/169
原始GPT结果,参考:https://huggingface.co/gpt2
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator("the fox appear, and said,", max_length=100, num_return_sequences=5)
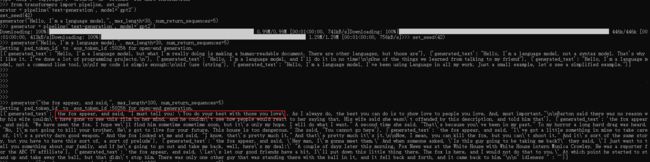
200轮迭代后,val less 不再下降 1.4643
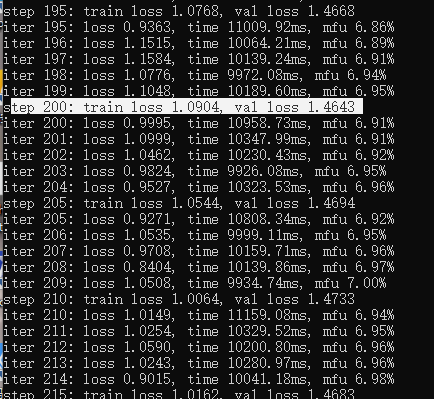
测试结果:不太有逻辑,微调效果不好,待改进