CVPR 2023 | 单阶段半监督目标检测SOTA:ARSL
本文提出了针对单阶段半监督目标检测任务的Ambiguity-Resistant Semi-supervised Learning(ARSL)算法,创新地提出了两个通用的单阶段半监督检测模块:Joint-Confidence Estimation(JCE)和Task-Separation Assignment(TSA)。JCE通过联合分类和定位任务的置信度评估伪标签质量。TSA基于教师模型预测的联合置信度将样本划分为正样本、负样本和模棱两可的候选样本,并进一步在候选样本中分别为分类、定位任务挑选潜在正样本。
 背景及动机
背景及动机
基于深度学习的目标检测算法通常依赖大规模标注数据才能发挥出最大的威力。为了节省标注人力,降低数据标注成本,半监督目标检测(SSOD)应运而生。半监督目标检测旨在利用少量的标注数据和大量的无标注数据进行模型训练,在最新进展中,其主要依赖于Mean-Teacher框架以及Pseudo-labeling技术,即用教师模型在无标注数据上生成的伪标签(Pseudo labels)训练学生模型,再基于学生模型在时序上的权重均值来更新教师模型。
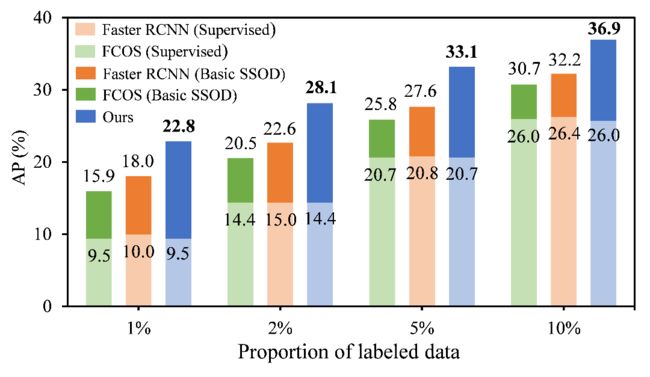 图1.在基础半监督框架下,单阶段检测器(FCOS)的提升弱于两阶段方法(Faster RCNN)
图1.在基础半监督框架下,单阶段检测器(FCOS)的提升弱于两阶段方法(Faster RCNN)
然而基于该流程,我们发现相比于两阶段检测器(如Faster RCNN),单阶段检测算法(如 FCOS)仅能取得相对有限的提升。是什么限制了单阶段检测器的半监督训练?通过定量分析,我们发现单阶段检测器的伪标签中存在严重的筛选歧义性(Selection Ambiguity)及样本分配歧义性(Assignment Ambiguity)。
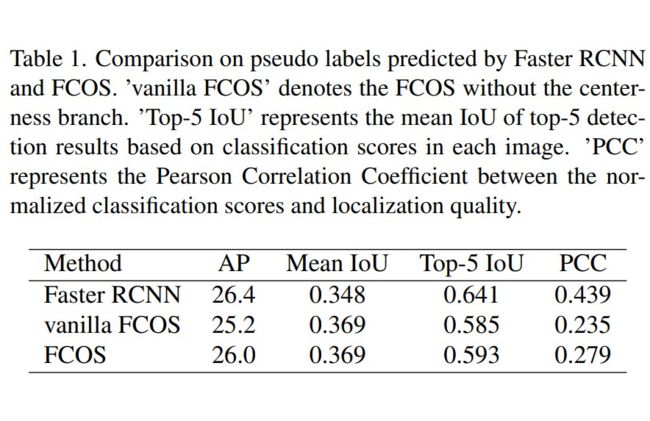 表1. (筛选歧义性) 伪标签的质量分析
表1. (筛选歧义性) 伪标签的质量分析
 图2. (分配歧义性) 不同阈值下,样本分配的正确性
图2. (分配歧义性) 不同阈值下,样本分配的正确性
筛选歧义性是指,由于检测结果的分类置信度和定位质量并不匹配,使得基于分类得分筛选的伪标签不够准确。这一点在单阶段检测器中更加严重。表1中可以看到,相比于Faster RCNN,FCOS预测的检测结果中,分类得分和定位质量的相关性更低。换句话说,FCOS筛选高质量伪标签的能力更弱。
分配歧义性是指,基于伪标签的样本分配中,大量样本被分配了错误的标签。问题的根源在于,FCOS的分配策略直接将边界框内部(或中心区域)的样本划分为正样本,而忽略了伪标签的边界框并不准确。这使得大量的背景区域被当成了正样本(False Positive),同时被阈值过滤掉的物体也被划分为了负样本(False Negative)。如图2所示,不管伪标签的筛选阈值如何设置,分配结果中均存在大量的false positive和false negative。可以看出,基于边界框的样本分配策略(如 FCOS 的 center sampling)在伪标签分配上存在着天然的劣势。另外,相比于Faster RCNN,FCOS等单阶段检测器需要像素级的样本标签,因此对分配歧义性更加敏感。

算法简介
为了解决上述问题,我们提出了Ambiguity-Resistant Semi-supervised Learning(ARSL),包括Joint-Confidence Estimation(JCE)和Task-Separation Assignment(TSA),通用于单阶段半监督目标检测任务。
 图3. ARSL 框架图。对于无标签数据,教师模型首先通过JCE预测样本的联合置信度。然后,TSA基于置信度将样本划分为正样本、负样本和模棱两可的候选样本,并进一步为分类、定位任务挑选潜在正样本。
图3. ARSL 框架图。对于无标签数据,教师模型首先通过JCE预测样本的联合置信度。然后,TSA基于置信度将样本划分为正样本、负样本和模棱两可的候选样本,并进一步为分类、定位任务挑选潜在正样本。
针对伪标签的筛选歧义性,JCE基于分类任务和定位任务的联合置信度来评估伪标签的质量。更为具体地,JCE通过双分支结构,同时预测分类得分和定位质量,并将两者的乘积作为联合置信度。为了避免两个分支单独训练所导致的次优状态,对于标注数据,两者使用IoU-based soft label进行联合训练;对于无标注数据,直接使用教师模型联合置信度的最大响应值进行训练。
 图4. JCE 示意图
图4. JCE 示意图
 图5. 正负样本在联合置信度区间中的分布
图5. 正负样本在联合置信度区间中的分布
针对伪标签的分配歧义性,TSA摒弃了box-based assignment,基于教师模型在每个样本点上预测的联合置信度,直接对其进行正负样本划分。然而如上图5所示,处于置信度中间区域的样本依然是难以抉择的。为此,TSA首先使用基于统计信息的双阈值将样本分为负样本、正样本和模棱两可的候选样本,然后在候选样本中分别为分类任务和定位任务进一步筛选潜在正样本。候选样本主要由低置信度的正样本和困难负样本组成,并不是单纯的背景区域(平均IoU为0.369)。对于分类任务,这些样本都值得学习,因此所有候选样本都参与教师模型的一致性学习,直接模仿教师模型预测的概率分布。而定位任务对样本的选择更加苛刻,差异性过大会导致定位任务不收敛。因此,TSA通过评估候选样本于正样本的相似性来筛选潜在正样本(类别相似性、定位相似性、几何位置相似性),并使用正样本边界框的加权值作为潜在正样本的学习目标。

实验效果
与半监督检测SOTA 的对比


在COCO-Standard 1%,2%,5%,10% split中(使用1%,2%, 5%,10% 的COCO_train2017标注数据进行监督训练,剩余作为无标注数据进行半监督训练,每个split均采样5组数据),ARSL均高于当前的SOTA算法,增加大尺度抖动(large-scale jittering)后进一步拉大了差距。
在COCO-Full中(使用全部的COCO_train2017标注数据进行监督训练,COCO_unlabel2017作为无标注数据),ARSL在较短的训练周期下取得了更加显著的提升。
消融性分析


表5.可以看到,FCOS在基础的半监督框架下仅取得了4.7%AP的提升(26.0%->30.7%),而基于ARSL则进一步提升了6.2%AP达到了36.9%AP。其中,JCE和TSA分别涨点4.0%AP,2.2%AP。表6为JCE中各个策略的提升效果。
歧义性消除的验证分析
 表8. 筛选歧义性
表8. 筛选歧义性
 图6. 分配歧义性
图6. 分配歧义性
表8.通过定量分析验证了JCE可以筛选出更高质量的伪标签,从而提升半监督学习的效果。图6.分析验证了TSA中样本标签分配的正确性。具体来说,TSA w/o mining将True Positive的数量提升了111.4%,还额外减少23.4%的False Positive。进一步挑选潜在正样本(Mining)可以将True Positive的数量提升至169.8%。
关于本篇ARSL欢迎大家入群讨论,也欢迎大家在GitHub点star支持我们的工作!
相关链接

-
论文地址
https://arxiv.org/abs/2303.14960
-
代码地址
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/semi_det