Git仓库---分布式版本控制系统
目录
一:基本概念---版本控制
1:本地版本控制系统
2: 集中化的版本控制系统
3:分布式版本控制系统
4:git的诞生
二:git config配置文件
三:创建本地git仓库
1:ubuntu安装git:sudo apt-get install git,之后就可以在命令行使用git了
2:创建本地git仓库:
四:git仓库工作原理的基本理解---git add / git commit
1:工作区和版本库基本概念
2:工作区和版本库的交互
五:git仓库工作原理的深入理解---git add / git commit(不care的同学,这一节可以不看,不影响)
1:重新理解git仓库
2:git add操作
3:git commit操作
第五节总结如下:
六:关于分支
1:什么是分支
2:分支的新建与合并
2:分支合并中出现的如下问题:
There isn’t anything to compare.
3:git remote add 别名 远程仓库: git remote就是给本地仓库连接一个远程仓库
4:对于git fetch和git pull的区别:网上很多说git fetch是把远程仓库分支取回本地,但是没有合并到本地分支,而git pull是取回后合并了,所以git pull = git fetch + git merge
一:基本概念---版本控制
详细可参考:Git学习笔记一:Git仓库结构及版本管理流程 (qq.com)
参考自:1.1:小调查: 你了解版本控制系统吗? | Git 简介-CSDN社区
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。在CODE CHINA 中,我们对保存着软件源代码的文件作版本控制,但实际上,你可以对任何类型的文件进行版本控制。
如果你是位图形或网页设计师,可能会需要保存某一幅图片或页面布局文件的所有修订版本(这或许是你非常渴望拥有的功能),采用版本控制系统(VCS)是个明智的选择。 有了它你就可以将选定的文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因,又是谁在何时报告了某个功能缺陷等等。 使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先的样子。 但额外增加的工作量却微乎其微。
接下来,我们将要回顾版本控制系统的发展历史。
版本控制系统发展可以分为 本地版本控制系统、集中式版本控制系统以及分布式版本控制系统三个阶段。
版本控制发展历程:
1:本地版本控制系统
参考自:1.2:本地版本控制系统 | Git 简介-CSDN社区
许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。 这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。
其中最流行的一种叫做 RCS,现今许多计算机系统上都还看得到它的踪影。 RCS 的工作原理是在硬盘上保存补丁集(补丁是指文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
2: 集中化的版本控制系统
参考自:1.3:什么是集中化的版本控制系统| Git 简介-CSDN社区
接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作?
于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。 这类系统,诸如
CVS、Subversion以及Perforce等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。多年以来,这已成为版本控制系统的标准做法。这种做法带来了许多好处,特别是相较于老式的本地
VCS来说。 现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。但这么做也有一个显而易见的缺点,那就是是中央服务器的单点故障。
- 如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作
- 如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问你将丢失所有数据——包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。
本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
3:分布式版本控制系统
参考自:1.4:什么是分布式版本控制系统 | Git 简介-CSDN社区
上节说到本地版本控制系统也存在中央服务器的单点故障问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险
于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。
在这类系统中,像
Git、Mercurial、Bazaar以及Darcs等,客户端并不只提取最新版本的文件快照, 而是把代码仓库完整地镜像下来,包括完整的历史记录。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。不仅如此,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。这样一来,你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
4:git的诞生
简单说了下git是再什么背景下提出来的,不重要!
参考自:1.5:Git 诞生的故事 | Git简介-CSDN社区
二:git config配置文件
config配置文件其实相当于git的环境变量,它用于设置git的一些基本属性,比如:

还有一个比较重要的配置信息是用户名和密码,
git config --global user.name 命令可以用来设置 Git 客户端的用户名。这个命令将设置 Git 客户端的全局用户名称,无论是在哪个目录下进行 Git 操作,这个用户名都会被使用。
这个用户名的作用是告诉 Git 服务器你的身份,并且在与他人协作时,可以用来标识你的身份。在 Git 仓库中,每个分支和提交都包含一个用户名和电子邮件地址,这些信息可以被其他 Git 客户端访问和使用。
如果你希望使用不同的用户名来标识你的身份,可以通过 git config --global user.name 命令设置它,该命令接受一个字符串参数,表示你想设置的用户名。
首先,配置用户名和密码这里,每一个仓库只会有一个用户名和密码,什么意思呢?我们知道又3个级别的用户名和密码,对应 git config --system / --global /--local,优先级最高的是--local,也就是当前工作区的用户名密码,每一个工作区的用户名密码,都只会有一个,后面的会复写前面的,比如最开始,你git config --local user.name "xiaoming",之后再git config --local user.name "dahon",那么你当前工作区下面的.git里面的config里面只会记住dahon,global和system是一样的。
三:创建本地git仓库
1:ubuntu安装git:sudo apt-get install git,之后就可以在命令行使用git了
2:创建本地git仓库:
a: 任意位置新建文件夹learngit

b:vscode下打开该文件夹,或者shell下直接定位到该文件夹下也可以,执行命令:git init,则将该文件夹转换为git可以管理得仓库,此时,该文件夹下会出现隐藏文件夹.git,该文件夹所包含信息如下:

可以看到这里有config文件,这个就是local级别得config文件,它只对当前工作区,也就是这个learngit文件夹有效,它只记录learngit文件夹下得内容变动情况。
此时我们看一下三个级别得config信息如下:

其中gloabl和system得config配置信息是我以前设置好的,在当前工作区依然可见;而对于local的配置信息则还没有进行手动设置,目前local下是没有用户名的,所以是没法通过local来讲当前工作区的内容上传github的,因为别人不知道你是谁,现在来手动设置一下local的config,命令如下:

设置system和global的时候,只需要将--local改成对应的名称即可。
而对于core.xxxx信息

c:上传文件到本地git仓库,我们首先在learngit这个文件夹下新建一个py文件learn1.py如下:

此时,这个文件还没有更新到git仓库,我们先用git status查看一下当前git仓库的状态:

可以看到,此时git还没有提交,接下来我们将新创建的这个文件跟踪并提交到仓库:
首先是git add :
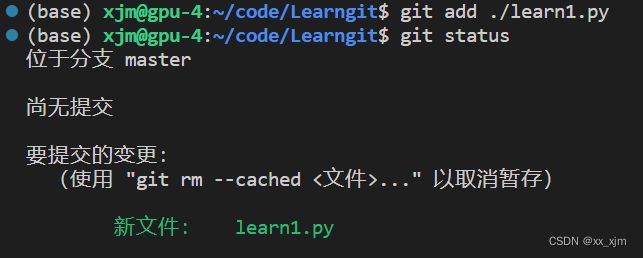
可以看到,该命令之后,在使用git status查看仓库状态,显示learn1.py为绿色了,表明这个文件已经被仓库跟踪了;接下来,将这个文件提交到仓库:
命令 git commit -m '说明‘, 一般来说,这个说明是必须要写的;此时再git status,则显示工作区没有变动的内容,是很干净的。

四:git仓库工作原理的基本理解---git add / git commit
git仓库可以理解为工作区+版本库
1:工作区和版本库基本概念
- 工作区比较好理解,就是我们写的代码呀乱七八杂的,在我们上面的例子里,工作区就指代learngit这个文件夹;
- 版本库:更好理解了,就是我们在learngit下生成的.git文件夹。
两者之间的关系如下:参考自(18条消息) Git之中git add与git commit的区别与关系_PS_Xie的博客-CSDN博客
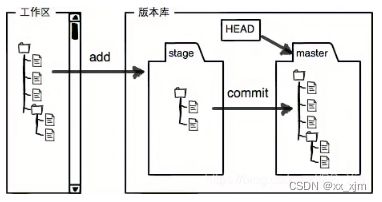
也可以看成这样:
参考自:git之commit - igoodful - 博客园 (cnblogs.com)
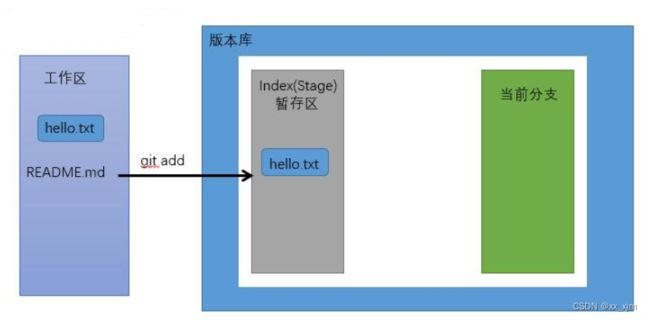
2:工作区和版本库的交互
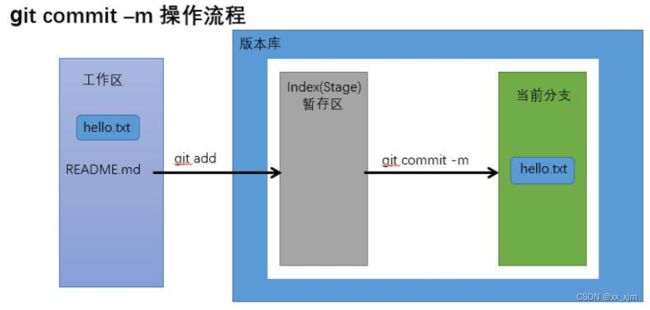
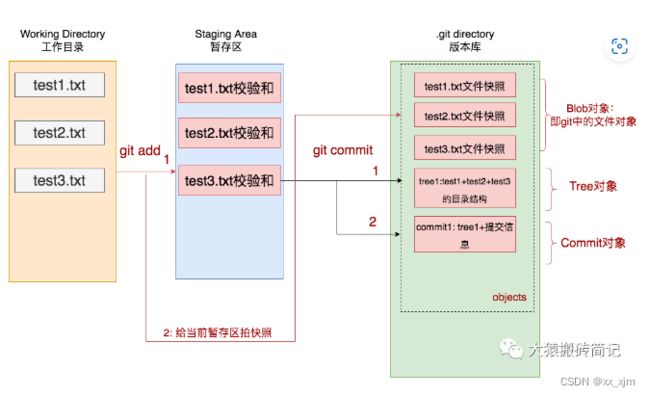
- 工作区内容提交到版本库,我们知道版本库是用来记录工作区内容变更的历史信息,方便工作人员回溯历史信息。但是版本库当然不会每时每刻都记录你的变更,这样得需要多大得内核操作才行呀,而且会占用大量资源,没有必要。所以针对你改动的内容,都需要工作人员手动得告诉版本库,“嗯,现在得内容该记录啦”。
- 现在你在工作区改动了一个内容,比如上面这样,你新建了一个README文件,首先,你需要通过git add将这个文件写入到缓存区;然后再通过git commit的方式将暂存区的内容写入当前分支(很好,又来了一个新概念,后面会讲,暂时先不深入)。这样,版本库就存好了你提交的内容。
五:git仓库工作原理的深入理解---git add / git commit(不care的同学,这一节可以不看,不影响)
参考自:Git学习笔记一:Git仓库结构及版本管理流程 (qq.com)
第五节部分图片无特殊说明,皆来自以上参考文件
上面,我们对git仓库工作原理进行了基本了解,也是现在网上主流的一个理解,但其实,这是一个很粗浅的解释,实际的工作原理其实是有一些差别的。接下来我们进行深入理解
1:重新理解git仓库
我们再上一节说git仓库= 工作区+版本库,在这里我们对这一概念进行进一步的理解:
git仓库 = 工作区+暂存区+版本库;大概可以理解为如下结构:

工作区:就是上诉learngit文件夹
暂存区:再工作区内,可以通过命令:git ls-files --stage查看
版本库,就是工作区的.git文件夹,也可以通过ls .git查看内容
2:git add操作
接下来,我们来说git add命令它实际做了哪些工作:为了不重复讲解,这里直接引用参考文章的内容:也就是在工作区内新建了3个txt文件;然后对三个文件执行了git add命令。结果如下,执行add操作以后,暂存区,版本库都出现了新的三个文件。也就是说,add操作不只是将文件提交从工作区提交到缓存区,也修改了版本库的内容。



git add操作总结如下:

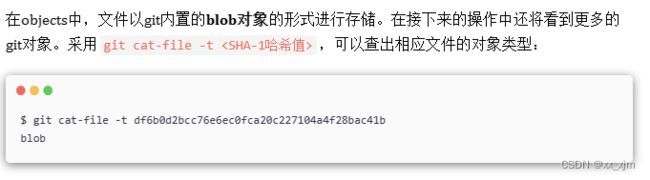
3:git commit操作
执行commit操作,不会修改工作区和暂存区的内容,只会修改版本库的内容,即增加一个tree对象和一个commit对象:

至此,git的三大对象就都出现了,分别是blob对象,tree对象,commit对象

接下来看看tree对象和commit对象:

第五节总结如下:
1:git add做了两部操作
-
一是在暂存区内:计算三个文件的SHA-1哈希值作为三个文件的唯一索引,将这三个唯一索引和文件原始信息添加至暂存区
-
二是在版本库内,对暂存区拍一张照片(快照),将此刻暂存区的索引,和索引所指向的原始文件的完整内容,一起添加到版库的objects文件中,生成对应的blob对象。
2:git commit也是做了两步操作
- 一是根据add生成的版本库中的快照文件生成tree对象,该对象用于存储文件目录结构
- 二是根据tree对象生成对应的commit对象,用于仓库管理
补充,关于为什么一定要先add在commit:参考:
(68 封私信 / 75 条消息) 为什么要先 git add 才能 git commit ? - 知乎 (zhihu.com)



六:关于分支
1:什么是分支
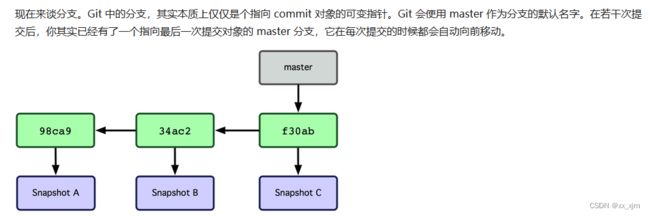
我们上面说了,git commit之后会在版本库中生成一个commit对象,每个对象包含一个指向暂存内容快照的指针,包含本次提交的作者等相关附属信息,包含零个或多个指向该提交对象的父对象指针:首次提交是没有直接祖先的,普通提交有一个祖先,由两个或多个分支合并产生的提交则有多个祖先。另外每个commit对象都有属于自己的唯一的id,也就是commit id。
所谓分支,其实就是一个指向commit对象的指针,只不过,这个指针再一般情况下都是指向最新的commit对象。我们也是通过这个指针来回溯以往的记录,因为每个commit对象其实都完整的记录了当时所提交的工作区的内容。在我们初始化仓库之后,仓库内还没有commit对象,此时若新建一个文件,并进行提交,就会生成一个commit对象,也会生成对应的一个指针,默认情况下,这个指针名就是master,也就是我们常说的master分支。
如下,每个commit对象指向了一个快照,快照里面存储着原始工作区的内容
参考自:Git 何谓分支_w3cschool
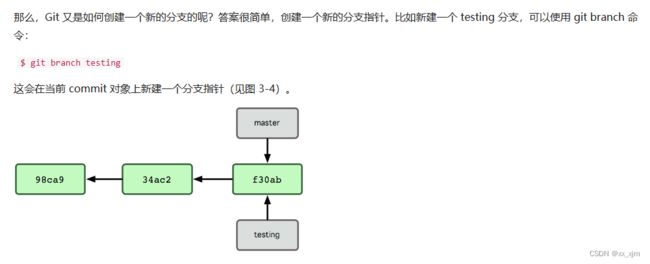
那么所谓分支呢,就是再当前分支的指针处,再建立一个分支:
那么git如何确定当前处于哪个分支呢?这里引出head的概念,它也是一个指针:

指针之间的切换:git checkout 目标分支名
比如下方这里:

2:分支的新建与合并
2:分支合并中出现的如下问题:
There isn’t anything to compare.
master and main are entirely different commit histories.
原因是,两个分支完全没有关系,所以git不允许它们合并,为什么?
我们知道分支的创建其实是在当前支路的基础之上的,也就是说分支刚创建的时候,其实和主支是一样的,指向的同样的commit,记录的commit历史信息啥的都一样,这一点可以再理解一下git中主支分支,以及head的概念。所以这这个时候,分支合并到主支路,就是把主支的master指针,调到了分支当前的指针。
而当两个完全无关的支路进行合并时,两个支路实际上是没有互相的信息的,也就是说其实是不存在主次关系的,那么git把这两个分支认为是完全无关的分支,所以不让合并。
最典型的例子就是,github上我们自建了一个空仓库,并建立了一个readme文件,此时github上这个仓库默认的分支是main分支,此时,如果我们想把本地的一个仓库推到github上这个建立的仓库,往往会产生一个新的分支master,所以我们github上就出现了两个分支,一个main,一个master,此时,这两个分支是无法合并的。
3:git remote add 别名 远程仓库: git remote就是给本地仓库连接一个远程仓库
这个别名实际上就是这个远程仓库,比如:
git remote add origin [email protected]:Xjmengnieer/Fundamental.git
我们则例远程仓库是[email protected]:Xjmengnieer/Fundamental.git,在这里我们给他取了一个别名叫做origin。
直接运行git remote,会显示目前已经连接的远程仓库,比如这里,如果运行了上面一行代码,那么此时会显示origin
直接运行git remote -v,可以看看我们本地配置的远程仓库信息,比如这里是这样的。

可以看出我们的远程仓库已经配置好了,分为两个地址,一个是 fetch 地址,用于从远程仓库拉取内容,一个是 push 地址,用于向远程仓库推送内容。
git remote rm 别名:删除别名对应的远程连接库
git remote rename old_name new_name: 修改仓库别名
git fetch 别名:取回别名对应的仓库的所有分支到本地
git fetch 别名 分支名:取回对应仓库对应分支到本地
4:对于git fetch和git pull的区别:网上很多说git fetch是把远程仓库分支取回本地,但是没有合并到本地分支,而git pull是取回后合并了,所以git pull = git fetch + git merge
但这里也有一篇文章指出,git fetch并没有把远程仓库的内容拉取下来,而只是在本都仓库中更新了远程仓库的最新commid。也就是说git fetch告诉本地仓库,远程仓库有更新了,你可以准备取合并啦。
参考自:(14条消息) git fetch和git pull之间的区别_git fetch 和git pull区别_sean-zou的博客-CSDN博客
未完待续......
如何删除远程分支 / 如何免密登录 / 多分支如何合并