python(29):struct模块
前言
不同类型的语言支持不同的数据类型,比如 Go 有 int32、int64、uint32、uint64 等不同的数据类型,这些类型占用的字节大小不同,而同样的数据类型在其他语言中比如 Python 中,又是完全不同的处理方式,比如 Python 的 int 既可以是有符号的,也可以是无符号的,这样一来 Python 和 Go 在处理同样大小的数字时存储方式就有了差异。
除了语言之间的差别,不同的计算机硬件存储数据的方式也有很大的差异,有的 32 bit 是一个 word,有的 64 bit 是一个 word,而且他们存储数据的方式或多或少都有些差异。
当这些不同的语言以及不同的机器之间进行数据交换,比如通过 network 进行数据交换,他们需要对彼此发送和接受的字节流数据进行 pack 和 unpack 操作,以便数据可以正确的解析和存储。
大端与小端:计算机如何存储整型
可以把计算机的内存看做是一个很大的字节数组,一个字节包含 8 bit 信息可以表示 0-255 的无符号整型,以及 -128—127 的有符号整型。当存储一个大于 8 bit 的值到内存时,这个值常常会被切分成多个 8 bit 的 segment 存储在一个连续的内存空间,一个 segment 一个字节。有些处理器会把高位存储在内存这个字节数组的头部,把低位存储在尾部,这种处理方式叫 大端,有些处理器则相反,低位存储在头部,高位存储在尾部,称之为 小端 。
一般情况下,主机字节序 是 小端模式,网络字节序 是 大端模式
假设一个寄存器想要存储 0x12345678 到内存中,大端和 小端 分别存储到内存 1000 的地址表示如下
| address | 大端 | 小端 |
|---|---|---|
| 1000 | 0x12 | 0x78 |
| 1001 | 0x34 | 0x56 |
| 1002 | 0x56 | 0x34 |
| 1003 | 0x78 | 0x12 |
计算机如何存储 character
和存储 number 的方式类似,character 通过一定的编码格式进行编码比如 unicode,然后以字节的方式存储。
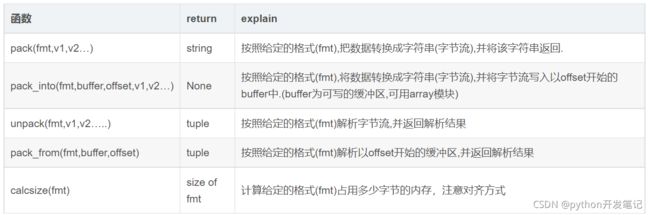
Python 中的 struct 模块
struct的pack函数把任意数据类型变成bytes
pack 操作
Pack 操作必须接受一个 template string 以及需要进行 pack 一组数据,这就意味着 pack 处理操作 定长 的数据
a = struct.pack("2I3sI", 12, 34, b"abc", 56)
b = struct.unpack("2I3sI", a)
print('a:',a)
print('b:',b)
》》》》
a: b'\x0c\x00\x00\x00"\x00\x00\x00abc\x008\x00\x00\x00'
b: (12, 34, b'abc', 56)
注意:输出中的“b”代表二进制。
上面的代码将两个整数 12 和 34,一个字符串 “abc” 和一个整数 56 一起打包成为一个字节字符流,然后再解包。其中打包格式中明确指出了打包的长度: "2I" 表明起始是两个 unsigned int , "3s" 表明长度为 4 的字符串,最后一个 "I" 表示最后紧跟一个 unsigned int ,所以上面的打印 b 输出结果是:(12, 34, ‘abc', 56)
struct将数字和使用的是哪种编码 -- ASCII(“美国信息交换标准代码”)
#一段MAC地址解析的实例
import struct
eth_header = b'E\x00\x00UC\x83@\x00>\x06\xd0\x03\n\x01'
eth_d = struct.unpack("!6s6sH",eth_header)
print(eth_d)
def eth_addr(a):
print('in eth_addr start==============')
print(a)
print(a[0], a[1], a[2], a[3], a[4], a[5])
bb = "%.2X:%.2X:%.2X:%.2X:%.2X:%.2X" % (a[0], a[1], a[2], a[3], a[4], a[5])
print(bb)
print('in eth_addr end==================\n')
return bb
print(eth_header[0:6])
print(eth_header[6:12])
print('Destination MAC : ' + eth_addr(eth_header[0:6]) + \
' Source MAC : ' + eth_addr(eth_header[6:12]) + ' Protocol : ' + str(eth_d[2]))
》》》》》
(b'E\x00\x00UC\x83', b'@\x00>\x06\xd0\x03', 2561)
b'E\x00\x00UC\x83'
b'@\x00>\x06\xd0\x03'
in eth_addr start==============
b'E\x00\x00UC\x83'
69 0 0 85 67 131
45:00:00:55:43:83
in eth_addr end==================
in eth_addr start==============
b'@\x00>\x06\xd0\x03'
64 0 62 6 208 3
40:00:3E:06:D0:03
in eth_addr end==================
Destination MAC : 45:00:00:55:43:83 Source MAC : 40:00:3E:06:D0:03 Protocol : 2561
Process finished with exit code 0
以上编码解析:
1.编码后的第一个字符"E" ,单独打印时python直接显示69(ascii 中E对应的十进制是69);UC字符同理.
2.\x为转移字符,其后面长度一个字节表示十六进制所代表的大小
标准库中整型与字节互转
a = (52).to_bytes(1,byteorder='big')
print(a)
b = b'4'
b1 = int.from_bytes(b,byteorder='big')
print(b1)
c = b'E'
c1 = int.from_bytes(c,byteorder='big')
print(c1)
d = b'E4'
d1 = int.from_bytes(d,byteorder='big')
print(d1)
》》》》》
b'4'
52
69
17716ASCII表
计算字节大小
可以利用 calcsize 来计算模式 “2I3sI” 占用的字节数
print struct.calcsize("2I3sI") # 16可以看到上面的三个整型加一个 3 字符的字符串一共占用了 16 个字节。为什么会是 16 个字节呢?不应该是 15 个字节吗?1 个 int 4 字节,3 个字符 3 字节。
但是在 struct 的打包过程中,根据特定类型的要求,必须进行字节对齐(关于字节对齐详见 https://en.wikipedia.org/wiki/Data_structure_alignment) 。
由于默认 unsigned int 型占用四个字节,因此要在字符串的位置进行4字节对齐,因此即使是 3 个字符的字符串也要占用 4 个字节。
再看一下不需要字节对齐的模式
print struct.calcsize("2Is") # 9由于单字符出现在两个整型之后,不需要进行字节对齐,所以输出结果是 9。
大小端对其
为了同c中的结构体交换数据,还要考虑有的c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下:
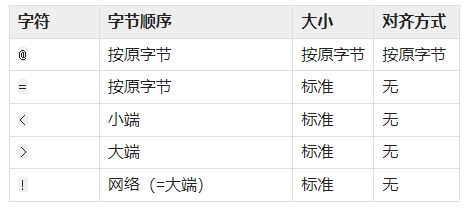
使用方法是放在fmt的第一个位置,就像’@5s6sif’
不定长数据 pack
如果打包的数据长度未知该如何打包,这样的打包在网络传输中非常常见。处理这种不定长的内容的主要思路是把长度和内容一起打包,解包时首先解析内容的长度,然后再读取正文。
打包变长字符串
对于变长字符在处理的时候可以把字符的长度当成数据的内容一起打包。
| 1 2 |
|
上面代码把字符 s 的长度打包成内容,可以在进行内容读取的时候直接读取。
解包变长字符串
| 1 2 |
|
解包变长字符时首先解包内容的长度,在根据内容的长度解包数据
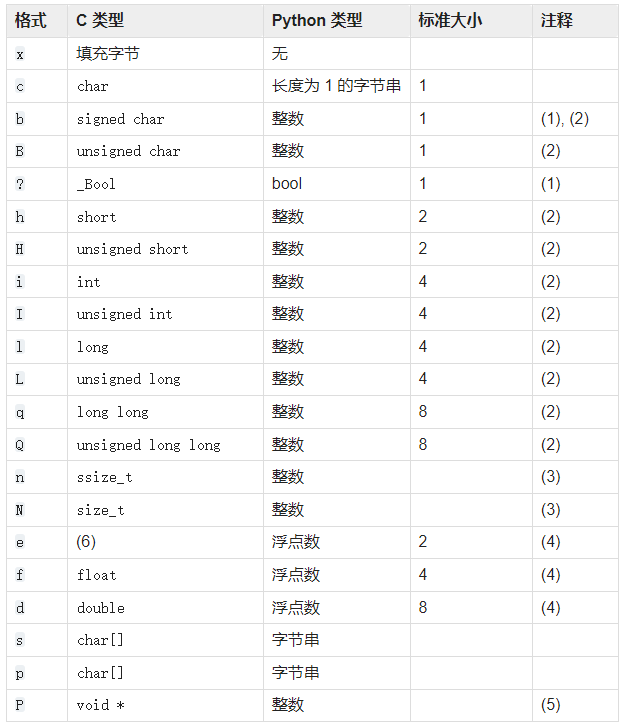
完整的 Python pack 操作支持的数据类型:
struct — Interpret bytes as packed binary data — Python 3.10.0 documentation https://docs.python.org/3/library/struct.html
https://docs.python.org/3/library/struct.html
网络协议的打包与解包
pack_into(format, buffer, offset, v1, v2, ...)
unpack_from(format, buffer, offset=0)
它们在组包拆包时,可以指定所需的偏移量,这让组包拆包变得更加灵活。
假设,网络协议由消息id(unsigned short类型)、消息size(unsigned int类型)及可变长度的消息payload(若干个unsigned int类型)组成。如何进行打包与解包
import struct
import ctypes
def load_packet(msg_id, msg_size, msg_payload):
packet = ctypes.create_string_buffer(msg_size)
struct.pack_into('>HI', packet, 0, msg_id, msg_size)
struct.pack_into('>%dH' % (int(msg_size-6)/2), packet, 6, *msg_payload)
return packet
def unload_packet(packet):
msg_id, msg_size = struct.unpack_from('>HI', packet, 0)
msg_payload = struct.unpack_from('>%dH' % (int(msg_size-6)/2), packet, 6)
return msg_id, msg_size, msg_payload
if __name__ == '__main__':
packet = load_packet(0x1002, 12, (0x1003, 0x1004, 0x1005))
print("packet: %s" % packet.raw)
msg_id, msg_size, msg_payload = unload_packet(packet)
print(hex(msg_id), msg_size, [hex(item) for item in msg_payload])
》》》》》
packet: b'\x10\x02\x00\x00\x00\x0c\x10\x03\x10\x04\x10\x05'
0x1002 12 ['0x1003', '0x1004', '0x1005']网络编程常用库socket可参考
python(42): socket 自定义私有协议_python开发笔记的博客-CSDN博客
参考:
struct — Interpret bytes as packed binary data — Python 3.10.0 documentation
https://www.jb51.net/article/136226.htm
[转]Python使用struct处理二进制(pack和unpack用法) | 四号程序员
Python之struct模块 - 酌三巡 - 博客园