PyTorch随笔 - 生成对抗网络的改进cGAN和LSGAN
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/129939225
本文介绍GAN的两个常见改进,cGAN和LSGAN,两者一般结合使用。
- cGAN: Conditional Generative Adversarial Nets,条件GAN
- LSGAN: Least Squares Generative Adversarial Networks,最小平方GAN
GAN
GAN,即生成对抗网络,是一种基于博弈论的生成模型,由两个神经网络组成:生成器(G)和判别器(D)。生成器的目标是从一个随机噪声向量生成与真实数据分布相似的样本,而判别器的目标是区分输入的样本是真实的还是生成的。两者相互竞争,最终达到一个纳什均衡,即生成器可以欺骗判别器,而判别器无法区分真假样本。
在训练GAN的过程中,建议使用 Spectral Normalization 优化网络层。
- Spectral Normalization,即谱正则化,可以有效地控制网络的 Lipschitz 常数,从而,提高网络的泛化能力和稳定性。Spectral Normalization 的基本思想是在每一层的权重矩阵W上施加一个谱范数约束,使得其最大奇异值不超过一个预设的阈值,例如1。这样,可以避免网络在训练过程中出现梯度爆炸或消失的问题,也可以防止生成对抗网络中的模式崩溃现象。Spectral Normalization 可以很容易地应用于各种类型的神经网络,包括卷积神经网络、循环神经网络和生成对抗网络,只需要在每一层的前向传播和反向传播中增加一些简单的计算步骤,而不需要改变网络的结构或超参数。
标准GAN源码:
#!/usr/bin/env python
# -- coding: utf-8 --
"""
Copyright (c) 2022. All rights reserved.
Created by C. L. Wang on 2023/4/3
"""
import os
import time
import numpy as np
import torch
import torch.nn as nn
import torchvision
image_size = [1, 28, 28]
latent_dim = 96
batch_size = 1024
use_gpu = torch.cuda.is_available()
save_dir = "gan_images"
os.makedirs(save_dir, exist_ok=True)
class Generator(nn.Module):
"""
生成器
数据torchvision.datasets.MNIST
"""
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.BatchNorm1d(128),
nn.GELU(),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.GELU(),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.GELU(),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.GELU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
# nn.Tanh(),
nn.Sigmoid(),
)
def forward(self, z):
"""
shape of z: [batchsize, latent_dim]
随机高斯分布z生成图像
"""
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
class Discriminator(nn.Module):
"""
判别器
"""
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32), 512),
nn.GELU(),
# nn.Linear(512, 256),
nn.utils.spectral_norm(nn.Linear(512, 256)), # 谱归一化
nn.GELU(),
# nn.Linear(256, 128),
nn.utils.spectral_norm(nn.Linear(256, 128)),
nn.GELU(),
# nn.Linear(128, 64),
nn.utils.spectral_norm(nn.Linear(128, 64)),
nn.GELU(),
# nn.Linear(64, 32),
nn.utils.spectral_norm(nn.Linear(64, 32)),
nn.GELU(),
# nn.Linear(32, 1),
nn.utils.spectral_norm(nn.Linear(32, 1)),
nn.Sigmoid()
)
def forward(self, img):
"""
shape of img: [batchsize, 1, 28, 28]
"""
prob = self.model(img.reshape(img.shape[0], -1)) # 只保留第0维
return prob
# Training
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(28),
torchvision.transforms.ToTensor(), # [0, 1]
# torchvision.transforms.Normalize(mean=[0.5], std=[0.5]) # [-1, 1]
])
dataset = torchvision.datasets.MNIST(
"mnist_data", train=True, download=True, transform=transform)
print(f"[Info] dataset: {len(dataset)}")
# for i in range(len(dataset)):
# if i < 5:
# print(dataset[i][0].shape)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=20)
generator = Generator()
discriminator = Discriminator()
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
loss_fn = torch.nn.BCELoss()
labels_one = torch.ones(batch_size, 1)
labels_zero = torch.zeros(batch_size, 1)
if use_gpu:
print("use gpu for training!")
generator = generator.cuda()
discriminator = discriminator.cuda()
loss_fn = loss_fn.cuda()
labels_one = labels_one.to("cuda")
labels_zero = labels_zero.to("cuda")
num_epoch = 1000
for epoch in range(num_epoch):
s_time = time.time()
for idx, mini_batch in enumerate(dataloader):
gt_images, _ = mini_batch
# print(f"[Info] gt_images.shape: {gt_images.shape}")
z = torch.randn(batch_size, latent_dim)
if use_gpu:
gt_images = gt_images.cuda()
z = z.cuda()
pred_images = generator(z)
g_optimizer.zero_grad() # 生成器的优化
recons_loss = torch.abs(pred_images - gt_images).mean() # 重构loss
# 预测为真实数据1
g_loss = recons_loss * 0.05 + loss_fn(discriminator(pred_images), labels_one)
g_loss.backward()
g_optimizer.step()
d_optimizer.zero_grad()
real_loss = loss_fn(discriminator(gt_images), labels_one)
fake_loss = loss_fn(discriminator(pred_images.detach()), labels_zero) # 生成照片
d_loss = real_loss + fake_loss
d_loss.backward()
d_optimizer.step()
# 判别器的优化
if idx % 50 == 0:
print(f"step: {len(dataloader)*epoch + idx}, recons_loss: {recons_loss.item()}, "
f"g_loss: {g_loss.item()}, d_loss: {d_loss.item()}, real_loss: {real_loss}, fake_loss: {fake_loss}")
if idx % 800 == 0:
image = pred_images[:64].data
# 保存照片
torchvision.utils.save_image(image, f"{save_dir}/image_{str(len(dataloader)*epoch + idx).zfill(6)}.png")
输出image_030044.png,训练效果如下:

cGAN
论文:cGAN - Conditional Generative Adversarial Nets,条件GAN
- 引用量4000多次
- cGAN的作者是Mehdi Mirza和Simon Osindero,加拿大蒙特利尔大学的博士生和博士后。在2014年发表了一篇论文,介绍了CGAN的原理和应用,他们的研究受到了Yann LeCun和Yoshua Bengio等人的指导和支持。
其中,cGAN 与 GAN 的差别是,cGAN 在生成和判别的过程中都加入了条件变量,比如类别标签、图像特征等。这样可以使得生成器能够根据指定的条件生成相应的数据,而判别器能够根据条件判断数据的真实性。cGAN 可以解决 GAN 的一些问题,比如模式崩溃、生成数据的多样性不足等。cGAN 也可以应用于更多的领域,比如图像转换、文本生成、语音合成等。
GAN的公式,如下:

cGAN的公式,如下:

源码如下:
#!/usr/bin/env python
# -- coding: utf-8 --
"""
Copyright (c) 2022. All rights reserved.
Created by C. L. Wang on 2023/4/3
"""
import os
import time
import numpy as np
import torch
import torch.nn as nn
import torchvision
image_size = [1, 28, 28]
latent_dim = 96
label_emb_dim = 32 # 标签的嵌入维度
batch_size = 1024
use_gpu = torch.cuda.is_available()
save_dir = "cgan_images" # 输出文件夹
os.makedirs(save_dir, exist_ok=True)
class Generator(nn.Module):
"""
生成器
数据torchvision.datasets.MNIST
"""
def __init__(self):
super(Generator, self).__init__()
self.embedding = nn.Embedding(10, label_emb_dim) # 将10维标签映射为嵌入表征
self.model = nn.Sequential(
nn.Linear(latent_dim + label_emb_dim, 128), # 输入维度增加
nn.BatchNorm1d(128),
nn.GELU(),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.GELU(),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.GELU(),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.GELU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
# nn.Tanh(),
nn.Sigmoid(),
)
def forward(self, z, labels):
"""
shape of z: [batchsize, latent_dim]
随机高斯分布z生成图像
"""
label_embedding = self.embedding(labels)
z = torch.cat([z, label_embedding], dim=-1) # 将条件也作为输入
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
class Discriminator(nn.Module):
"""
判别器
"""
def __init__(self):
super(Discriminator, self).__init__()
self.embedding = nn.Embedding(10, label_emb_dim)
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32) + label_emb_dim, 512), # 输入维度增加
nn.GELU(),
# nn.Linear(512, 256),
nn.utils.spectral_norm(nn.Linear(512, 256)), # 谱归一化
nn.GELU(),
# nn.Linear(256, 128),
nn.utils.spectral_norm(nn.Linear(256, 128)),
nn.GELU(),
# nn.Linear(128, 64),
nn.utils.spectral_norm(nn.Linear(128, 64)),
nn.GELU(),
# nn.Linear(64, 32),
nn.utils.spectral_norm(nn.Linear(64, 32)),
nn.GELU(),
# nn.Linear(32, 1),
nn.utils.spectral_norm(nn.Linear(32, 1)),
nn.Sigmoid()
)
def forward(self, img, labels):
"""
shape of img: [batchsize, 1, 28, 28]
"""
label_embedding = self.embedding(labels) # 离散变量转换为连续变量
model_input = torch.cat([img.reshape(img.shape[0], -1), label_embedding], dim=-1)
prob = self.model(model_input) # 只保留第0维
return prob
# Training
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(28),
torchvision.transforms.ToTensor(), # [0, 1]
# torchvision.transforms.Normalize(mean=[0.5], std=[0.5]) # [-1, 1]
])
dataset = torchvision.datasets.MNIST(
"mnist_data", train=True, download=True, transform=transform)
print(f"[Info] dataset: {len(dataset)}")
# for i in range(len(dataset)):
# if i < 5:
# print(dataset[i][0].shape)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=20)
generator = Generator()
discriminator = Discriminator()
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
loss_fn = torch.nn.BCELoss()
labels_one = torch.ones(batch_size, 1)
labels_zero = torch.zeros(batch_size, 1)
if use_gpu:
print("use gpu for training!")
generator = generator.cuda()
discriminator = discriminator.cuda()
loss_fn = loss_fn.cuda()
labels_one = labels_one.to("cuda")
labels_zero = labels_zero.to("cuda")
num_epoch = 1000
for epoch in range(num_epoch):
s_time = time.time()
for idx, mini_batch in enumerate(dataloader):
gt_images, labels = mini_batch # 需要输入标签
# print(f"[Info] gt_images.shape: {gt_images.shape}")
z = torch.randn(batch_size, latent_dim)
if use_gpu:
gt_images = gt_images.cuda()
labels = labels.cuda()
z = z.cuda()
pred_images = generator(z, labels)
g_optimizer.zero_grad() # 生成器的优化
recons_loss = torch.abs(pred_images - gt_images).mean() # 重构loss
# 预测为真实数据1
g_loss = recons_loss * 0.05 + loss_fn(discriminator(pred_images, labels), labels_one)
g_loss.backward()
g_optimizer.step()
d_optimizer.zero_grad()
real_loss = loss_fn(discriminator(gt_images, labels), labels_one)
fake_loss = loss_fn(discriminator(pred_images.detach(), labels), labels_zero) # 生成照片
d_loss = real_loss + fake_loss
d_loss.backward()
d_optimizer.step()
# 判别器的优化
if idx % 50 == 0:
print(f"step: {len(dataloader)*epoch + idx}, recons_loss: {recons_loss.item()}, "
f"g_loss: {g_loss.item()}, d_loss: {d_loss.item()}, real_loss: {real_loss}, fake_loss: {fake_loss}")
if idx % 800 == 0:
image = pred_images[:64].data
# 保存照片
torchvision.utils.save_image(image, f"{save_dir}/image_{str(len(dataloader)*epoch + idx).zfill(6)}.png")
输出image_030044.png,cGAN优于GAN,训练效果如下:

LSGAN
论文:LSGAN - Least Squares Generative Adversarial Networks,最小平方GAN
- 引用量3000多次
其中,LSGAN 和 GAN 是两种生成对抗网络的变体,都可以用于生成逼真的图像。主要区别在于损失函数的设计,GAN 使用了交叉熵损失函数,要求判别器输出生成图像和真实图像的概率。这样的损失函数,可能导致梯度消失的问题,使得生成器难以学习。LSGAN 使用了最小二乘损失函数,要求判别器输出生成图像和真实图像的分数,这样的损失函数可以提供更多的梯度信息,使得生成器更容易学习。LSGAN 还可以减少模式崩溃的现象,即生成器只能生成有限种类的图像。总之,LSGAN 是一种改进了 GAN 的损失函数的方法,可以提高生成图像的质量和多样性。
LSGAN的公式,如下

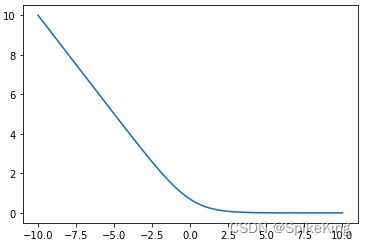
由于Sigmoid+交叉熵损失导致梯度消失,因此替换为L2损失,即:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# sigmoid ce 图像
logits = torch.linspace(-10, 10, 2000)
loss = []
loss_fn = nn.BCELoss()
for lgs in logits:
loss.append(loss_fn(torch.sigmoid(lgs), torch.ones_like(lgs)))
plt.plot(logits, loss)
plt.show()
Sigmoid+交叉熵损失的效果:
其中,LSGAN公式中,a、b、c的数值约束:

约束:b - c = 1,b - a = 2,例如:a = -1、b = 1、c = 0 或者 b = c = 1,a = 0,第二种方案更优,也更常见。
同时使用LSGAN + cGAN的源码,如下:
#!/usr/bin/env python
# -- coding: utf-8 --
"""
Copyright (c) 2022. All rights reserved.
Created by C. L. Wang on 2023/4/3
"""
import os
import time
import numpy as np
import torch
import torch.nn as nn
import torchvision
image_size = [1, 28, 28]
latent_dim = 96
label_emb_dim = 32 # 标签的嵌入维度
batch_size = 1024
use_gpu = torch.cuda.is_available()
save_dir = "ls_cgan_images" # 输出文件夹
os.makedirs(save_dir, exist_ok=True)
class Generator(nn.Module):
"""
生成器
数据torchvision.datasets.MNIST
"""
def __init__(self):
super(Generator, self).__init__()
self.embedding = nn.Embedding(10, label_emb_dim) # 将10维标签映射为嵌入表征
self.model = nn.Sequential(
nn.Linear(latent_dim + label_emb_dim, 128), # 输入维度增加
nn.BatchNorm1d(128),
nn.GELU(),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.GELU(),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.GELU(),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.GELU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
# nn.Tanh(),
nn.Sigmoid(),
)
def forward(self, z, labels):
"""
shape of z: [batchsize, latent_dim]
随机高斯分布z生成图像
"""
label_embedding = self.embedding(labels)
z = torch.cat([z, label_embedding], dim=-1) # 将条件也作为输入
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
class Discriminator(nn.Module):
"""
判别器
"""
def __init__(self):
super(Discriminator, self).__init__()
self.embedding = nn.Embedding(10, label_emb_dim)
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32) + label_emb_dim, 512), # 输入维度增加
nn.GELU(),
# nn.Linear(512, 256),
nn.utils.spectral_norm(nn.Linear(512, 256)), # 谱归一化
nn.GELU(),
# nn.Linear(256, 128),
nn.utils.spectral_norm(nn.Linear(256, 128)),
nn.GELU(),
# nn.Linear(128, 64),
nn.utils.spectral_norm(nn.Linear(128, 64)),
nn.GELU(),
# nn.Linear(64, 32),
nn.utils.spectral_norm(nn.Linear(64, 32)),
nn.GELU(),
# nn.Linear(32, 1),
nn.utils.spectral_norm(nn.Linear(32, 1)),
nn.Sigmoid()
)
def forward(self, img, labels):
"""
shape of img: [batchsize, 1, 28, 28]
"""
label_embedding = self.embedding(labels) # 离散变量转换为连续变量
model_input = torch.cat([img.reshape(img.shape[0], -1), label_embedding], dim=-1)
prob = self.model(model_input) # 只保留第0维
return prob
# Training
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(28),
torchvision.transforms.ToTensor(), # [0, 1]
# torchvision.transforms.Normalize(mean=[0.5], std=[0.5]) # [-1, 1]
])
dataset = torchvision.datasets.MNIST(
"mnist_data", train=True, download=True, transform=transform)
print(f"[Info] dataset: {len(dataset)}")
# for i in range(len(dataset)):
# if i < 5:
# print(dataset[i][0].shape)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=20)
generator = Generator()
discriminator = Discriminator()
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
# loss_fn = torch.nn.BCELoss()
loss_fn = torch.nn.MSELoss() # LSGAN Least Squares
labels_one = torch.ones(batch_size, 1)
labels_zero = torch.zeros(batch_size, 1)
if use_gpu:
print("use gpu for training!")
generator = generator.cuda()
discriminator = discriminator.cuda()
loss_fn = loss_fn.cuda()
labels_one = labels_one.to("cuda")
labels_zero = labels_zero.to("cuda")
num_epoch = 1000
for epoch in range(num_epoch):
s_time = time.time()
for idx, mini_batch in enumerate(dataloader):
gt_images, labels = mini_batch # 需要输入标签
# print(f"[Info] gt_images.shape: {gt_images.shape}")
z = torch.randn(batch_size, latent_dim)
if use_gpu:
gt_images = gt_images.cuda()
labels = labels.cuda()
z = z.cuda()
pred_images = generator(z, labels)
g_optimizer.zero_grad() # 生成器的优化
recons_loss = torch.abs(pred_images - gt_images).mean() # 重构loss
# 预测为真实数据1
g_loss = recons_loss * 0.05 + loss_fn(discriminator(pred_images, labels), labels_one)
g_loss.backward()
g_optimizer.step()
d_optimizer.zero_grad()
real_loss = loss_fn(discriminator(gt_images, labels), labels_one)
fake_loss = loss_fn(discriminator(pred_images.detach(), labels), labels_zero) # 生成照片
d_loss = real_loss + fake_loss
d_loss.backward()
d_optimizer.step()
# 判别器的优化
if idx % 50 == 0:
print(f"step: {len(dataloader)*epoch + idx}, recons_loss: {recons_loss.item()}, "
f"g_loss: {g_loss.item()}, d_loss: {d_loss.item()}, real_loss: {real_loss}, fake_loss: {fake_loss}")
if idx % 800 == 0:
image = pred_images[:64].data
# 保存照片
torchvision.utils.save_image(image, f"{save_dir}/image_{str(len(dataloader)*epoch + idx).zfill(6)}.png")
输出image_030044.png,训练效果如下:

That’s all!