【2023年第十一届泰迪杯数据挖掘挑战赛】C题:泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一

更新时间:2023-4-6
相关链接
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题二
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题三
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题四
1 题目
一、问题背景
在新时代背景下,随着大学生毕业人数不断增加,大学生求职问题已成为广泛关注的社 会热点。而且受疫情影响,诸多企业的招聘都改为线上进行,脱离时间和空间的限制,招聘 需求不断上涨,有近六成企业招聘需求增加,其中需求量较大的科技研发、数字化、蓝领技 能岗位都存在不同程度的人才短缺。但从人才供给来看,应届生数量增加,2022 年高校毕 业生达到创纪录的 1076 万人,而且部分企业校招开展暂缓或推迟,因此出现校招需求缩减 或冻结,这些因素都加剧了应届生就业的严峻形势。基于种种因素,出现就业竞争压力大、 招聘与求职信息不对称等现象。
泰迪内推平台是聚焦于“大数据+”和“人工智能“领域的求职招聘网站,该平台融合了多家企业发布的招聘信息,同时平台也为求职者提供求职信息的展示。为缓解毕业生就业 压力,同时满足企业对人才的需求,泰迪内推平台会定期为高校学生提供优质岗位推荐,解 决毕业生就业的同时也缓解企业用人难的问题,为校企之间搭建起资源互换的桥梁,力求实 现人才的供需对接和教育资源转化,通过深化产教融合,促进教育链、人才链、产业链与创 新链有机衔接。
因此,对招聘信息进行分析研究,了解不同职业领域的需求特点,挖掘兴起的数据类行 业相应的人才需求现状及发展趋势,为广大求职者提供正确的就业指导有着重要意义。
二、解决问题
1.招聘信息爬取
从泰迪内推平台(https://www.5iai.com/#/index)的“找工作“页面和“找人才”页面,爬取所有招聘与求职信息并整理,依据招聘信息ID记录每条招聘信息并保存为“result1 - 1.csv”文件,求职信息则依据求职者ID记录并保存为“result1-2.csv”文件,涉及的招聘信息ID和求职者ID均来自网址路径后端的数字串,如图1所示。(模板文件见附件1中的CSV文件)

图1 某招聘信息网页
2.招聘与求职信息分析
应用问题 1 的招聘信息与求职信息构建画像:根据采集的企业招聘信息,从招聘岗位、 学历要求、岗位需求量、公司类型、薪资待遇、岗位技能、企业工作地点等多个方向建立招 聘信息画像;根据采集求职者求职信息,从预期岗位、薪资需求、知识储备、学历、工作经 验等多个方向建立求职者画像。
3.构建岗位匹配度和求职者满意度的模型
在招聘和求职过程中,企业面对多位优质求职者,将会考虑求职者能力要求、技能掌握 等多方面,岗位匹配度是体现求职者满足企业招聘要求的匹配程度;同样,求职者对于多种 招聘信息,也会依据自身条件和要求,选取符合自己心意的岗位,因此求职者满意度指标可 客观体现求职者对企业招聘岗位的满意程度。对于不满足岗位最低要求的求职者,企业可定 义其岗位匹配度为 0。同样,对于不满足求职者最低要求的岗位,求职者可定义其求职者满 意度为 0。
根据问题2的招聘信息与求职者信息,构建岗位匹配度和求职者满意度的模型,基于该模型,为每条招聘信息提供岗位匹配度非0的求职者,将结果进行降序排序存放在“resul3 - 1. csv”文件中,以及为每位求职者提供求职者满意度非0的招聘信息,将结果进行降序排序存放在“result3 - 2. csv”文件中。(模板文件见附件1中的CSV文件)
4.招聘求职双向推荐模型
假设招聘流程如下:设某岗位拟聘人,泰迪内推平台向企业推荐岗位匹配度非0的n位求职者发出第一轮报价,求职者如果收到多于1个岗位的报价,则求职者选取满意度最高的岗位签约,每个求职者只允许选择1个岗位签了约。第一轮结束后,平台根据当前各招聘信息的剩余岗位数,向后续被推荐求职者发出第二轮报价,如此继续,直到招聘人数已满或者向所有拟推荐求职者均已发出提供为止。
在上述招聘流程中,由于条件优秀的岗位求职者都愿意去,而条件优秀的求职者各岗位 都愿意录用,很难做到履约率达到百分之百,因此履约率高低是评价平台的推荐系统优劣的 重要指标。这里的履约率定义为:
履约率=所有岗位的签约人数之和/所有拟聘岗位人数之和
请为平台设计招聘求职双向推荐模型,使得履约率指标达到最高。并将招聘岗位与求职者签约成功的结果存放在“resul4.csv”文件中。
三、附件说明
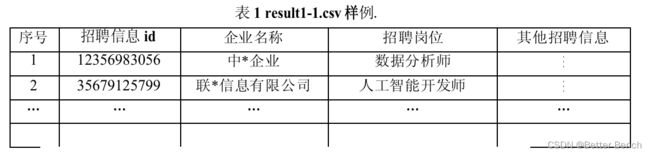
附件1是问题1,问题3和问题4的模板文件,文件均为csv文件,采用ANSI编码。Result1-1.csv:从泰迪内推平台爬取的招聘信息,文件参考表1格式。
Result1-2.csv:从泰迪内推平台爬取的求职信息,文件参考表2格式。表2 result1-2.csv样例.

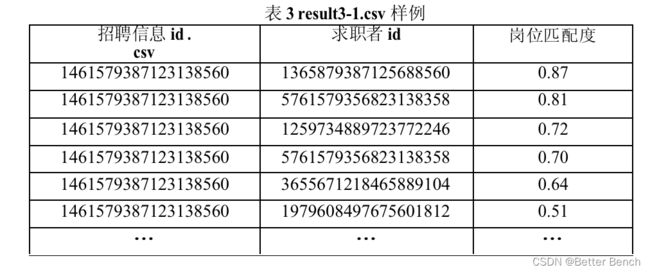
result3 - 1. - csv:该文档存储每条招聘信息中岗位匹配度非0的求职者,需将结果进行降序排序,具体字段名和样例见表3。
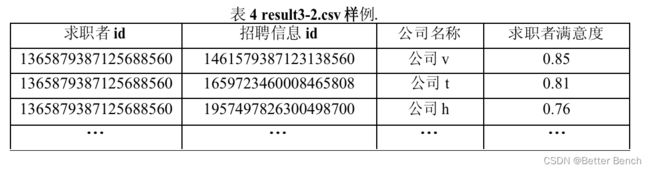
result3 - 2. - csv:该文档存储每位求职者满意度非0的招聘信息,需将结果进行降序排序,具体字段名和样例见表4。
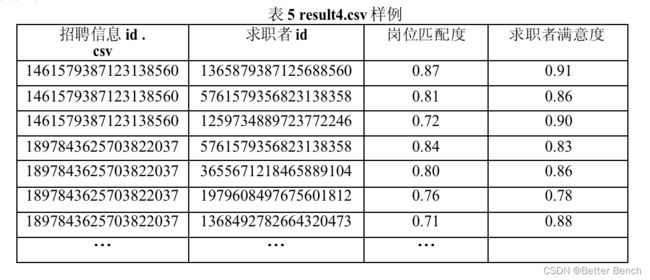
result4.csv:根据履约率最高的模型,提供招聘岗位签约成功后的求职者ID。该结果需对招聘信息ID进行排序,并对每个招聘信息的数据按岗位匹配度降序排序,具体字段名和样例见表5。
2 问题一思路分析及python代码实现
(1)爬取招聘信息
import requests
import pandas as pd
import json
data = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
def print_hi(page):
。。。略,请下载完整代码
response = requests.get(url, headers=headers)
html = json.loads(response.text)
for i in html["data"]["content"]:
item = {'招聘信息id': i["id"], '公司地址': i["enterpriseAddress"]["detailedAddress"].replace('\xa0', ''),
'招聘岗位': i["positionName"], '公司类型': i["enterpriseExtInfo"]["personScope"],
'最低薪资': i["minimumWage"], '最高薪资': i["maximumWage"],
'员工数量': i["enterpriseExtInfo"]["econKind"], '学历': i["educationalRequirements"],
'岗位经验': i["exp"], '企业名称': i["enterpriseExtInfo"]["shortName"],
'企业类型': i["enterpriseExtInfo"]["industry"]}
print(item)
data.append(item)
def main():
for j in range(1, 159):
print_hi(page=j)
df = pd.DataFrame(data)
。。。略
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
main()
(2)爬取人才信息
import requests
import pandas as pd
import json
data = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
def print_hi(page):
。。。略,请下载完整代码
response = requests.get(url, headers=headers)
html = json.loads(response.text)
for i in html["data"]["content"]:
item = {'求职者id': i["id"], '姓名': i["username"],
'预期岗位': i["expectPosition"], '预期最低薪资': i["willSalaryStart"],
'预期最高薪资': i["willSalaryEnd"],
'地区': i["city"]}
ite = []
for j in i["keywordList"]:
ite.append(j['labelName'])
item['技能'] = ite
print(item)
data.append(item)
def main():
for j in range(1, 1093):
print_hi(page=j)
df = pd.DataFrame(data)
。。。略
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
main()
3 下载后的数据及代码

(1)招聘信息
有1575个样本
(2)人才信息
有10916个样本