- 写于2012年6月30日
大白159753
2021年是我的本命年,是红色的一年,也是注定不一样的一年。之前我从来没有这么正式的写过我的年中回顾。今年不知道为什么也恰好是在6月30日这一天有了这个想法,时间地点都合适,那就开始动笔吧~一直觉得自己过得平平无奇,回顾都要靠翻朋友圈翻相册去寻找过往的时光,偏偏又不是一个爱照相爱发朋友圈的人。只能靠着蛛丝马迹来回忆我这匆匆过去的半年时光。上半年让我印象最深刻的事情可能就是我换工作吧,5月24日我来
- 重回择婿那天,我诞下极品孔雀蛋(嘉禾月礼)好看小说-最新章节重回择婿那天,我诞下极品孔雀蛋(嘉禾月礼)
时光里文馆
《重回择婿那天,我诞下极品孔雀蛋》主角:嘉禾月礼简介:我是孔雀公主,成年那年,全孔雀族的男子都来求娶。我明明选择了血统高贵的绿孔雀青山。成婚后生得却是三等白孔雀。青山看到白孔雀,勃然大怒,一把将孩子摔死,将尚在原形的我割颈拔毛,扔给了野兽分食。嫁给二等蓝孔雀的姐姐,却生下罕见的紫孔雀。她的夫君因此成为新的百鸟之王。再睁眼,回到我选青山做我夫君那日。他当着所有人的面,拒绝我,求娶我的姐姐。我知道他也
- 适合学生赚钱的软件 学生在校赚零花钱
氧惠_飞智666999
生时代是人生中最美好的阶段之一,但也是经济压力较大的阶段之一。很多学生想要通过自己的努力赚取一些零花钱,既能减轻家庭负担,又能锻炼自己的能力和经验。但是,在校学习任务繁重,时间和空间都有限制,如何找到适合自己的赚钱方式呢?氧惠APP,2022全新模式,0投资,最快63天做到月入十万。我的直推也会放到你下面,我曾经1年做到百万团队,现在加入我也会帮你做到百万团队。【氧惠】百度有几百万篇报道,也期待你
- 厉司寒晚凝(我的超雄霸总老公)全本免费在线阅读_(我的超雄霸总老公)完结版免费在线阅读_厉司寒晚凝(我的超雄霸总老公)完整版免费在线阅读_《我的超雄霸总老公》全集在线阅读_厉司寒晚凝《我的超雄霸...
完整版看小说
厉司寒晚凝(我的超雄霸总老公)全本免费在线阅读_(我的超雄霸总老公)完结版免费在线阅读_厉司寒晚凝(我的超雄霸总老公)完整版免费在线阅读_《我的超雄霸总老公》全集在线阅读_厉司寒晚凝《我的超雄霸总老公》全本免费在线阅读_(厉司寒晚凝)最新章节在线阅读主角配角:厉司寒晚凝简介:5厉司寒一开口,所有人瞬间止住了动作,朝他望了过去他穿着一身高端定制西装,戴着一副金丝细框眼镜,面容俊俏,却冷厉威严见状,盛
- 2021年08月 3日
Maggie章
邀请您和我一起1000天《我的崇道堂成长历程》一一悟善道,行正道!朗读第105天《自醒文》第43天[语音][语音]每日一悟:重新理解”福祸相依”这个词的意义,今天眼前发生的祸福都是过去种下的因缘导致的,灾难的背后往往是上天给我们送福来的,抓住这个机会就是重获新生了。人就是一只空瓶子,向里面装信仰、装善良、装天地,装爱的能力,那么人世间的是是非非、争争斗斗、一切的一切都不会遮住人的慧眼,生命也就会充
- 《我的病娇女总裁老婆》沈青竹叶凡完结版阅读_沈青竹叶凡完结版在线阅读_我的病娇女总裁老婆(沈青竹叶凡)最新章节在线阅读_(我的病娇女总裁老婆)完整版免费在线阅读_沈青竹叶凡《我的病娇女总裁老婆》...
笔趣阁官方推荐小说
《我的病娇女总裁老婆》沈青竹叶凡完结版阅读_沈青竹叶凡完结版在线阅读_我的病娇女总裁老婆(沈青竹叶凡)最新章节在线阅读_(我的病娇女总裁老婆)完整版免费在线阅读_沈青竹叶凡《我的病娇女总裁老婆》完结版免费阅读_沈青竹叶凡热门小说主角配角:沈青竹叶凡简介:5沈青竹一开口,所有人都不禁朝她望了过去她穿着一身高定连衣裙,披着一头乌黑微卷的长发白皙的皮肤,玲珑有致的身材,配上她冷艳的气质,使她更加高贵动人
- 接纳自己
晴岚85
郑海燕焦点初级十期坚持分享第59天2018.8.9今天早上做完中药热敷回来的路上,我一直在心里默默的念叨着一句话:郑海燕你真是太棒了,你做事真有自己的想法,你真善于表达自己。这是我最想给自己说的话,也是我最渴望达到的目标,所以我在心里默默的念叨了快一百遍。念叨完我觉得自己内心生出了许多的力量。学习焦点有两个月了,虽然看书,分享,听课,都在坚持,但是最近半个月,我的情绪很低落,也许是生活的压力,也许
- 【由泥巴匠到教授】随笔第53篇 技校任教
泥巴匠赵仁
技校任教1980年的一天,也就是在没有去上海和北京考察之前,天气特别晴朗。奎生到机械队的技术办公室里把我叫出来。把我领到办公室南边到一个空旷的场子里。这个场子很奇怪,在信阳市遍地都是开发商的足迹的年代,这块空地已经空了40多年了,到现在还是个空旷的场地。奎生对我说,李国斌支书可能在这几天里会找你谈个事情,你一定要答应他。我说,李支书他是我的长辈,特别是在70年代初,咱们一施工队出现反革命匿名信案件
- 2023-04-03
向日葵积极向上
每日一省导师班复训结束了,这一次断断续续的听课,听的不是很好,不过,还是有收获的,今天的实操流程有很大的启发。今天老公又说,你学了这么久有用的不嘛?问题解决了没?怎么还是这个样子呢?他爱怎么怎么的,我好解脱……听到他这样说,我心里就在想,这货就那样,固执又不学习,他自己也没招,把希望寄托在我身上,希望我去解决目前的问题(一直以来都这样,只要有事就是我的事)。我说:我们养了十几年的娃,十几年的教育结
- 《欠债大佬们对我咬牙切齿》完整版小说无弹窗广告(陈阳、赵建国)全文免费阅读无弹窗_《欠债大佬们对我咬牙切齿》无弹窗全文在线阅读
霸道推书1
书名:《欠债大佬们对我咬牙切齿》主角配角:陈阳、赵建国小说简介:别人穿越是吃香的喝辣的,身边还有一群美女小弟,而我穿越,除了一屁股债还是一屁股债。就没有什么好事了吗!上天还是怜惜我的,让我绑定了欠债不还系统。从此,我开启了画大饼模式。成为了世纪最大债务人,高新科技巨头,产品营销专家,新时代成功大师。带着我的债主们投身一个个科研项目。推荐指数:✩✩✩✩✩———阅读全文小说内容请翻阅最底部———“额.
- 2022.04.18简单日记
谢谋淦
2022.04.18晴不冷不热早饭牛奶袋豆浆茶叶蛋菜包花费6.5块钱。来客户买U盘收费100块钱128gb。进货399+69.9+840+71块钱。午饭买两个馒头花费1.5块钱加鱼汤。睡午觉。醒了去买20块钱瓜子带去办公室人员吃,送了发票去等着结账。骑电动车出去爬山。股市收盘三大指数涨跌不一,个股涨一片,我的股票海默科技跌6.46%,收盘价格4.92块钱,华仁药业跌1.21%,收盘价格4.08块钱
- 2018年的回想,我在中化的日子里
文学汇作者
文/家奴又是一年岁尾,感觉日子过得飞快,嗖嗖嗖就逝去了,再想返回身去,追寻失去的光阴,已经变得遥不可及,日子就是一个过程,一旦远去,再难抓住,每一个人都有自己的日子,周而复始,有改变内容的,也有维持着原状,一成不变的,但日子不论怎么过,我们都有自己的目标,都有自己的追求,想要实现愿望,就需要不停地奋斗。我的2018年,是有意义,有收获的一年,感觉自己又有了进步,又获得了成长,一个人的学历可能几十年
- 我骄傲,我来自农村,出自寒门,我的父母是地地道道的农民
初心入口
我骄傲,我来自农村,出自寒门,我的父母是地地道道的农民。今天有个好友提出一个问题,当遇到别人耻笑你是山里娃、乡下人的时候,你应该怎么样回答他?这就是我的回答。农村别人耻笑你是山里娃、乡下人,这个“别人”是什么人,我不得而知,也没必要知道,我只是想知道他是如何与我们这些山里娃、乡下人混到一起来的?既然你高人一等,你是阳春白雪,曲高和寡,我们是下里巴人,你站在泰山之顶,怎么隔空喊话,把这消息传达到我们
- 2023-03-16
绿提子雪糕
粉色系的花花~自带温柔特效,仙气飘飘向来不喜欢粉色,觉得稚嫩康乃馨的粉钻和樱花粉,一直想入手,有优惠就果断下手多头康乃馨古朴也是粉色系静待花开,萌发我的少女心粉色系花花
- 秦方舟云然(十年恩爱一朝尽)全章节在线阅读_(十年恩爱一朝尽)完结版免费阅读_秦方舟云然《十年恩爱一朝尽》完结版免费阅读_十年恩爱一朝尽全文免费阅读_秦方舟云然《十年恩爱一朝尽》完结版免费阅读_...
全本全集小说
秦方舟云然(十年恩爱一朝尽)全章节在线阅读_(十年恩爱一朝尽)完结版免费阅读_秦方舟云然《十年恩爱一朝尽》完结版免费阅读_十年恩爱一朝尽全文免费阅读_秦方舟云然《十年恩爱一朝尽》完结版免费阅读_秦方舟云然热门小说主角配角:秦方舟云然简介:4任臻拉了一把我的手,将我护在了身后云然迅速反应过来,脸色阴沉,直勾勾的看着我「不入流?秦方舟,你就任由别人这么给齐云科技泼脏水吗?你该不会真的要为了一个村姑,跟
- 两月速通大模型开发,你需要做什么?32岁程序员转行大模型,大龄程序员如何转行大模型?
别再犹豫转不转行,只看理论不行动了!作为一位30+北漂男程序员,2个月零基础转行大模型,成功拿下月薪2w+的offer!今天我来分享一下我的亲身经历,希望能给还在迷茫中的你一些启发!转行前的“悲惨”生活我,一个30+男单身青年,因为家里在一个小城市,大学时一心想报到大城市来,想尝试一下新的生活方式,所以选择了一个普通的二本学院在北京开启了我的大学生活。因为选择的计算机专业,每天都很忙,也比较难,听
- 道德文章
四海同心666
我的之所以有要想写下些许文字的想法,乃是源于老早的从前读过的一篇小文,今偶然间翻了翻日记本,又看到了当时记下的话,也不知道触动了哪根错位的神经,甚至是可以说也不知道是哪根神经错了位。于是,便有了想要写下些什么文字的想法。亦于是,便由着自己的思,随手写些着边际甚乃不着边际的文字了。也可以是说,也算是了却了一种思的感慨吧。然,真的是要去写了,却又被现在的诸多的诸种的——尤其是现实生活中的——奇葩的怪象
- 2019-08-04
b10bc01d9838
尊敬的李老师,智慧的班主任,亲爱的跃友们:大家好!我是来自山东莱州鑫和金店的王秀娟,李总的人今天是2019年8月4日,是我的日精进行动第74天,每天进步一点点,时间长了,实现质的飞跃!1、比学习:生活中有很多细节的地方都需要学习。2、比改变:销售技巧还需要改变,还需要提升。3、比付出:这几天家人们为了换款活动加班加点。4、比谦卑:学会放下,学会感恩。5、比感恩:感恩公司感恩所有的伙伴们。6、比坚持
- 2019-04-07只要方向对,就不怕路远
阿牛时间管理笔记
昨天和公司的小伙伴一起聊天,谈到了价值观,相对我们这个小团队来说:自律、利他、走正道、以用户为中心,是我们一致的价值观。大家只有先在思维方面达成一致,才会拧成一股更有力量的绳,一起做有价值能沉淀的事业。实际上,查理·芒格在他的书中以及演讲中多次提到「价值观」。谈及自己的家庭,他说:「虽然我的家庭没有留下大笔财产,但为我提供了良好的教育,为我的行为规范树立了一个了不起的榜样。归根到底,这些比实际的钱
- 记录我的元宵节
文字世界的漫游
早晨我的早点是糯糯甜甜的黑芝麻馅的汤圆。吃了这碗汤圆祝我今年甜甜蜜蜜的。上午在朋友圈看看家乡的雪景雪把大地照得晶莹剔透。好可爱的雪,想摸摸它。发个朋友圈,祝大家元宵节快乐。夜晚听一首诗朗诵月夜作者:李元胜为你读诗:张韬|主持人今夜,月亮高悬我到过的地方都转向它那些我倾听过的人,在各自的朝代各自的书籍中,都在转向它真的,黑暗中不仅有蜉蝣的翅不仅有灌木。树叶的细语大地录下了所有温存的转动心跳。轻微的哭
- 数字人系统:AI界的超级巨星,你准备好了吗?
优秘智能UMI
数字人人工智能深度学习计算机视觉机器学习自然语言处理语言模型图像处理
在这个日新月异的科技时代,每一个创新的火花都可能点燃一场变革的燎原之火。今天,我们要聊的,正是那颗在AI领域熠熠生辉的璀璨新星——优秘数字人系统。它不仅仅是技术的飞跃,更是对未来生活方式的深刻重塑,一场关于人机交互、智能共生的美好预演。技术原理:深度解析与智能构建的奥秘1.深度学习:智能的基石数字人系统的核心技术之一在于深度学习。深度学习是一种模仿人脑神经网络结构和功能的机器学习技术,通过构建多层
- 普通人想利用AI变现,这5个赛道不能错过!
浮沉导师
随着人工智能技术的迅猛发展,越来越多的普通人开始关注如何利用AI实现变现。AI不仅改变了我们的工作方式,也创造了众多赚钱的机会。本文将介绍五个值得关注的AI赛道,帮助你抓住这些机会,实现收入增长。【高省】APP网购优惠券免费领,分享还能赚钱。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台。佣金更高,模式更好,终端用户不流失。0投资,稳定可靠,百度有几百万篇报道,期待你的加入。应用市场下载【高省
- 静而不争
遗憾美
Hi!你现在好吗?今天快乐吗?有觉得很开心吗?如果有另你不开心的事情发生,你会怎样对待呢?如果是我的话,会选择性的用“无所谓”的态度面对,在心底告诉自己“不值得”!人生就像羽毛一样随风飘荡,人的命运也是如此。漂浮于世,如羽毛漂浮于天地之间,追求本性,不刻意要求问心无愧才是真谛。往后余生,静而不争!静而不争
- 室友得病,嫁祸给我陈然苏倩倩最新完本小说_小说全文免费阅读室友得病,嫁祸给我陈然苏倩倩
绾绾呐
《室友得病,嫁祸给我》主角:陈然苏倩倩简介:室友得病了,还想传染给我..校花舍友得了脏病,全身起红疹。我告诉她,这是得了脏病,她不相信,还觉得我是妒忌她,找了个那么好的男朋友。她不仅偷偷用我的毛巾,还偷穿我的内裤,致使我得了脏病。我去和她理论,却被她一把从天台推了下。她联合舍友造谣我得了脏病自杀而死,还感染了她和同宿舍的其他舍友。我死后,还被全校骂上热搜。再睁眼,我回到了舍友起红疹的那天。我先是去
- 当身边的人离我们而去时,我们可以选择做什么?
朱亚萍
昨天把爷爷送走,今天整理了一下朋友圈,发现一个对我很好的长辈,也在昨天走了。如何才能更好的去陪伴身边的亲人?陪伴?电话?或是什么?猫叔说时间就是生命。现在的我真的不能去浪费时间我要去把握当下,把每一件事做好努力的去践行最大的感恩就是拿钱说话因为钱,引发了多少问题在我的家人身上,这两天也看的很清楚把2019年的计划,认真践行,有能力给到我最爱的人。我不管别人怎么去说去对待我知道小时候我在你们身上得到
- 被假千金凌虐致死后,我爸杀疯了(沈薇薇沈千金)免费小说全集_阅读免费小说被假千金凌虐致死后,我爸杀疯了沈薇薇沈千金
d036fb3b3d05
《被假千金凌虐致死后,我爸杀疯了》主角:沈薇薇沈千金简介:我有个用命疼我的首富爸爸。每天上课,教室后面都站着我家三十个保镖。同学不小心碰到我,当场就被暴揍一顿。老师说一句我的不是,直接就被开除。我提出抗议,我爸却说:“你妈临死前让我好好照顾你,我绝不能让你受半点伤害。”我无法忍受这窒息的爱,偷偷离家出走。我爸动用关系全城搜捕,仅用半小时就将我抓回,并把我禁锢在山顶别墅,不允许任何人接近。为了让我听
- 2018-07-18
雨后彩虹816
随笔随着年龄的变化,小时候那些童真消失了。八岁时,我向别人借了一个悠悠球,我总觉得,要是它能多转几秒该多好,于是,我“胡想”一真去,我竟想出一个“粘玻璃球”的办法,我把“珍藏”多年的玻璃球粘上去,用手掂了掂,还挺沉,我用手轻轻一甩,空转时间提高两倍!在一班时,我经常带一些小玩易儿到班上玩,引得好多人看,有的人说我的思维太怪了,有人说我太好玩了,还有人要借回去玩两天。多么奇妙的思维,它几乎每天都缠着
- 随感
自由风016
图片发自App林清玄先生写到:“我曾经在一个开满凤凰花的城市住了三年,今天看到一棵凤凰花开,好像唱着歌一样,使我的眼耳口鼻舌身意都洋溢着少年时代的欢喜。”同样,对于我这样一个善感的人来说,每年看到合欢花瓣落下时,常常想起,少年时,我在学校河边那棵高密如伞的合欢树下,远远地凝望的那个暗恋的男生。时过境迁,如今的自己的孩子都已是高高的少年了,往事却仿佛就在昨天,想想,还是有些怅然……图片发自App
- 免费小说全集被疯批皇叔强取豪夺后薛阮阮萧肃渊_被疯批皇叔强取豪夺后(薛阮阮萧肃渊)免费完本小说
六小升
《被疯批皇叔强取豪夺后》主角:薛阮阮萧肃渊简介:先皇垂涎我阿娘美貌,不顾她身怀有孕,强抢她进宫,我也被迫认贼作父。别人都在背后骂我是小野种,只有当时的三皇叔将我视作珍宝。他总爱将我揽入怀中,抹去我的泪珠,疼惜地哄我:“我们阮阮可是皇叔的宝贝。”我也渐渐对他生出了情意。登基那夜,他借着酒意将我压在身下,欺负了一遍又一遍。可他口中分明唤着我阿娘的名字。原来,萧肃渊只是在我身上寻找阿娘的影子。我不愿为人
- AI人工智能 Agent:金融投资中智能体的应用
AI天才研究院
AI大模型企业级应用开发实战AI大模型应用入门实战与进阶AI人工智能与大数据计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
AI人工智能Agent:金融投资中智能体的应用1.背景介绍在金融投资领域,人工智能(AI)技术的应用已经成为一种趋势。随着数据量的爆炸性增长和计算能力的提升,AI技术在金融市场中的应用变得越来越广泛和深入。智能体(Agent)作为AI技术的重要组成部分,能够在金融投资中发挥重要作用。智能体可以通过学习和适应市场环境,自动执行交易策略,优化投资组合,甚至预测市场趋势。2.核心概念与联系2.1智能体(
- apache 安装linux windows
墙头上一根草
apacheinuxwindows
linux安装Apache 有两种方式一种是手动安装通过二进制的文件进行安装,另外一种就是通过yum 安装,此中安装方式,需要物理机联网。以下分别介绍两种的安装方式
通过二进制文件安装Apache需要的软件有apr,apr-util,pcre
1,安装 apr 下载地址:htt
- fill_parent、wrap_content和match_parent的区别
Cb123456
match_parentfill_parent
fill_parent、wrap_content和match_parent的区别:
1)fill_parent
设置一个构件的布局为fill_parent将强制性地使构件扩展,以填充布局单元内尽可能多的空间。这跟Windows控件的dockstyle属性大体一致。设置一个顶部布局或控件为fill_parent将强制性让它布满整个屏幕。
2) wrap_conte
- 网页自适应设计
天子之骄
htmlcss响应式设计页面自适应
网页自适应设计
网页对浏览器窗口的自适应支持变得越来越重要了。自适应响应设计更是异常火爆。再加上移动端的崛起,更是如日中天。以前为了适应不同屏幕分布率和浏览器窗口的扩大和缩小,需要设计几套css样式,用js脚本判断窗口大小,选择加载。结构臃肿,加载负担较大。现笔者经过一定时间的学习,有所心得,故分享于此,加强交流,共同进步。同时希望对大家有所
- [sql server] 分组取最大最小常用sql
一炮送你回车库
SQL Server
--分组取最大最小常用sql--测试环境if OBJECT_ID('tb') is not null drop table tb;gocreate table tb( col1 int, col2 int, Fcount int)insert into tbselect 11,20,1 union allselect 11,22,1 union allselect 1
- ImageIO写图片输出到硬盘
3213213333332132
javaimage
package awt;
import java.awt.Color;
import java.awt.Font;
import java.awt.Graphics;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imagei
- 自己的String动态数组
宝剑锋梅花香
java动态数组数组
数组还是好说,学过一两门编程语言的就知道,需要注意的是数组声明时需要把大小给它定下来,比如声明一个字符串类型的数组:String str[]=new String[10]; 但是问题就来了,每次都是大小确定的数组,我需要数组大小不固定随时变化怎么办呢? 动态数组就这样应运而生,龙哥给我们讲的是自己用代码写动态数组,并非用的ArrayList 看看字符
- pinyin4j工具类
darkranger
.net
pinyin4j工具类Java工具类 2010-04-24 00:47:00 阅读69 评论0 字号:大中小
引入pinyin4j-2.5.0.jar包:
pinyin4j是一个功能强悍的汉语拼音工具包,主要是从汉语获取各种格式和需求的拼音,功能强悍,下面看看如何使用pinyin4j。
本人以前用AscII编码提取工具,效果不理想,现在用pinyin4j简单实现了一个。功能还不是很完美,
- StarUML学习笔记----基本概念
aijuans
UML建模
介绍StarUML的基本概念,这些都是有效运用StarUML?所需要的。包括对模型、视图、图、项目、单元、方法、框架、模型块及其差异以及UML轮廓。
模型、视与图(Model, View and Diagram)
&
- Activiti最终总结
avords
Activiti id 工作流
1、流程定义ID:ProcessDefinitionId,当定义一个流程就会产生。
2、流程实例ID:ProcessInstanceId,当开始一个具体的流程时就会产生,也就是不同的流程实例ID可能有相同的流程定义ID。
3、TaskId,每一个userTask都会有一个Id这个是存在于流程实例上的。
4、TaskDefinitionKey和(ActivityImpl activityId
- 从省市区多重级联想到的,react和jquery的差别
bee1314
jqueryUIreact
在我们的前端项目里经常会用到级联的select,比如省市区这样。通常这种级联大多是动态的。比如先加载了省,点击省加载市,点击市加载区。然后数据通常ajax返回。如果没有数据则说明到了叶子节点。 针对这种场景,如果我们使用jquery来实现,要考虑很多的问题,数据部分,以及大量的dom操作。比如这个页面上显示了某个区,这时候我切换省,要把市重新初始化数据,然后区域的部分要从页面
- Eclipse快捷键大全
bijian1013
javaeclipse快捷键
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)Ctrl+D: 删除当前行 Ctrl+Alt+↓ 复制当前行到下一行(复制增加)Ctrl+Alt+↑ 复制当前行到上一行(复制增加)Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)Alt+↑ 当前行和上面一行交互位置(同上)Alt+← 前一个编辑的页面Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)Alt+En
- js 笔记 函数
征客丶
JavaScript
一、函数的使用
1.1、定义函数变量
var vName = funcation(params){
}
1.2、函数的调用
函数变量的调用: vName(params);
函数定义时自发调用:(function(params){})(params);
1.3、函数中变量赋值
var a = 'a';
var ff
- 【Scala四】分析Spark源代码总结的Scala语法二
bit1129
scala
1. Some操作
在下面的代码中,使用了Some操作:if (self.partitioner == Some(partitioner)),那么Some(partitioner)表示什么含义?首先partitioner是方法combineByKey传入的变量,
Some的文档说明:
/** Class `Some[A]` represents existin
- java 匿名内部类
BlueSkator
java匿名内部类
组合优先于继承
Java的匿名类,就是提供了一个快捷方便的手段,令继承关系可以方便地变成组合关系
继承只有一个时候才能用,当你要求子类的实例可以替代父类实例的位置时才可以用继承。
在Java中内部类主要分为成员内部类、局部内部类、匿名内部类、静态内部类。
内部类不是很好理解,但说白了其实也就是一个类中还包含着另外一个类如同一个人是由大脑、肢体、器官等身体结果组成,而内部类相
- 盗版win装在MAC有害发热,苹果的东西不值得买,win应该不用
ljy325
游戏applewindowsXPOS
Mac mini 型号: MC270CH-A RMB:5,688
Apple 对windows的产品支持不好,有以下问题:
1.装完了xp,发现机身很热虽然没有运行任何程序!貌似显卡跑游戏发热一样,按照那样的发热量,那部机子损耗很大,使用寿命受到严重的影响!
2.反观安装了Mac os的展示机,发热量很小,运行了1天温度也没有那么高
&nbs
- 读《研磨设计模式》-代码笔记-生成器模式-Builder
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 生成器模式的意图在于将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示(GoF)
* 个人理解:
* 构建一个复杂的对象,对于创建者(Builder)来说,一是要有数据来源(rawData),二是要返回构
- JIRA与SVN插件安装
chenyu19891124
SVNjira
JIRA安装好后提交代码并要显示在JIRA上,这得需要用SVN的插件才能看见开发人员提交的代码。
1.下载svn与jira插件安装包,解压后在安装包(atlassian-jira-subversion-plugin-0.10.1)
2.解压出来的包里下的lib文件夹下的jar拷贝到(C:\Program Files\Atlassian\JIRA 4.3.4\atlassian-jira\WEB
- 常用数学思想方法
comsci
工作
对于搞工程和技术的朋友来讲,在工作中常常遇到一些实际问题,而采用常规的思维方式无法很好的解决这些问题,那么这个时候我们就需要用数学语言和数学工具,而使用数学工具的前提却是用数学思想的方法来描述问题。。下面转帖几种常用的数学思想方法,仅供学习和参考
函数思想
把某一数学问题用函数表示出来,并且利用函数探究这个问题的一般规律。这是最基本、最常用的数学方法
- pl/sql集合类型
daizj
oracle集合typepl/sql
--集合类型
/*
单行单列的数据,使用标量变量
单行多列数据,使用记录
单列多行数据,使用集合(。。。)
*集合:类似于数组也就是。pl/sql集合类型包括索引表(pl/sql table)、嵌套表(Nested Table)、变长数组(VARRAY)等
*/
/*
--集合方法
&n
- [Ofbiz]ofbiz初用
dinguangx
电商ofbiz
从github下载最新的ofbiz(截止2015-7-13),从源码进行ofbiz的试用
1. 加载测试库
ofbiz内置derby,通过下面的命令初始化测试库
./ant load-demo (与load-seed有一些区别)
2. 启动内置tomcat
./ant start
或
./startofbiz.sh
或
java -jar ofbiz.jar
&
- 结构体中最后一个元素是长度为0的数组
dcj3sjt126com
cgcc
在Linux源代码中,有很多的结构体最后都定义了一个元素个数为0个的数组,如/usr/include/linux/if_pppox.h中有这样一个结构体: struct pppoe_tag { __u16 tag_type; __u16 tag_len; &n
- Linux cp 实现强行覆盖
dcj3sjt126com
linux
发现在Fedora 10 /ubutun 里面用cp -fr src dest,即使加了-f也是不能强行覆盖的,这时怎么回事的呢?一两个文件还好说,就输几个yes吧,但是要是n多文件怎么办,那还不输死人呢?下面提供三种解决办法。 方法一
我们输入alias命令,看看系统给cp起了一个什么别名。
[root@localhost ~]# aliasalias cp=’cp -i’a
- Memcached(一)、HelloWorld
frank1234
memcached
一、简介
高性能的架构离不开缓存,分布式缓存中的佼佼者当属memcached,它通过客户端将不同的key hash到不同的memcached服务器中,而获取的时候也到相同的服务器中获取,由于不需要做集群同步,也就省去了集群间同步的开销和延迟,所以它相对于ehcache等缓存来说能更好的支持分布式应用,具有更强的横向伸缩能力。
二、客户端
选择一个memcached客户端,我这里用的是memc
- Search in Rotated Sorted Array II
hcx2013
search
Follow up for "Search in Rotated Sorted Array":What if duplicates are allowed?
Would this affect the run-time complexity? How and why?
Write a function to determine if a given ta
- Spring4新特性——更好的Java泛型操作API
jinnianshilongnian
spring4generic type
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- CentOS安装JDK
liuxingguome
centos
1、行卸载原来的:
[root@localhost opt]# rpm -qa | grep java
tzdata-java-2014g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
[root@localhost
- 二分搜索专题2-在有序二维数组中搜索一个元素
OpenMind
二维数组算法二分搜索
1,设二维数组p的每行每列都按照下标递增的顺序递增。
用数学语言描述如下:p满足
(1),对任意的x1,x2,y,如果x1<x2,则p(x1,y)<p(x2,y);
(2),对任意的x,y1,y2, 如果y1<y2,则p(x,y1)<p(x,y2);
2,问题:
给定满足1的数组p和一个整数k,求是否存在x0,y0使得p(x0,y0)=k?
3,算法分析:
(
- java 随机数 Math与Random
SaraWon
javaMathRandom
今天需要在程序中产生随机数,知道有两种方法可以使用,但是使用Math和Random的区别还不是特别清楚,看到一篇文章是关于的,觉得写的还挺不错的,原文地址是
http://www.oschina.net/question/157182_45274?sort=default&p=1#answers
产生1到10之间的随机数的两种实现方式:
//Math
Math.roun
- oracle创建表空间
tugn
oracle
create temporary tablespace TXSJ_TEMP
tempfile 'E:\Oracle\oradata\TXSJ_TEMP.dbf'
size 32m
autoextend on
next 32m maxsize 2048m
extent m
- 使用Java8实现自己的个性化搜索引擎
yangshangchuan
javasuperword搜索引擎java8全文检索
需要对249本软件著作实现句子级别全文检索,这些著作均为PDF文件,不使用现有的框架如lucene,自己实现的方法如下:
1、从PDF文件中提取文本,这里的重点是如何最大可能地还原文本。提取之后的文本,一个句子一行保存为文本文件。
2、将所有文本文件合并为一个单一的文本文件,这样,每一个句子就有一个唯一行号。
3、对每一行文本进行分词,建立倒排表,倒排表的格式为:词=包含该词的总行数N=行号
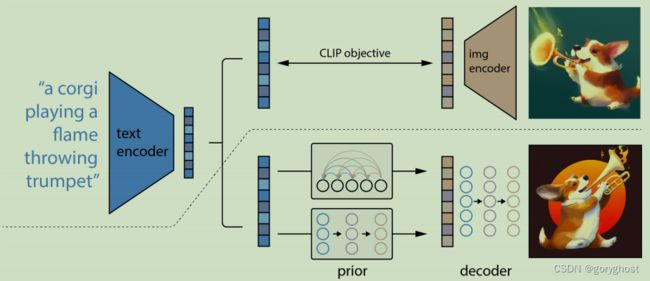 虚线上面是 CLIP 的训练流程
虚线上面是 CLIP 的训练流程