Kaggle 入门 Titanic: Machine Learning from Disaster(1)数据分析和处理
数据集及分析
泰坦尼克号的故事大家都耳熟能详,具体就不说了,这个题目是Kaggle的入门题目,关注点在通过题目给定的乘客信息,推断乘客能否在海难中生存下来。
数据有三个csv文件,一个训练集,一个测试集,还有一个答案模板(按照性别作为划分依据的答案)
数据特征:
survival:label,是否存活
plclass:票务舱情况,分三档,top,middle,low(1,2,3)
sex:性别
Age:年龄
sibsp:是xx的兄弟
parch:是xx的父母/子女 这两个是身份信息,同船上有多少亲人
ticket:票号(我个人觉得这个和最后结果应该相关性不高)
fare:费用,乘客票价
cabin:舱数
embarked:上船地点(港口)
利用pandas导入数据
import numpy as np
import pandas as pd
data =pd.read_csv("train.csv")
data.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
发现数据在age\cabin\Embarked上有缺失值,可能需要后面数据处理
查看具体的数据信息

查看一下存活率与各个数据之间的相关程度
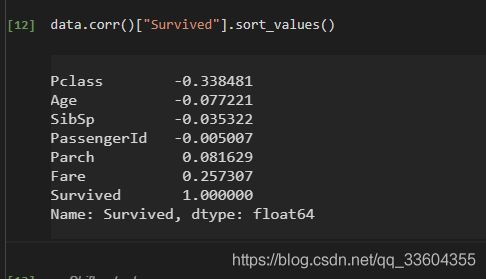
看出来,pclass\fare等参数与存活率相关程度较高,猜测海难到来时,船舱的位置与是否能够逃难有关(或者是有不公平对待,高等舱位的旅客获得了优先对待?)
对非数值的参数,进行其他处理
例如对男女比例进行分析
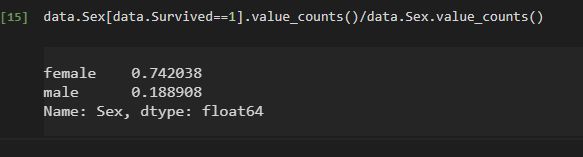
看出来女士的存活率远高于男士
对上船港口进行类型处理
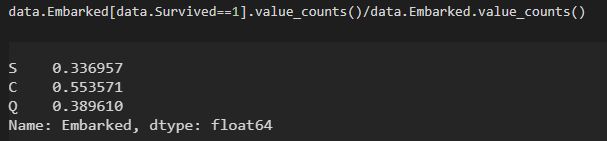
这个结果和我最初预期不太一致,后续看看如何处理吧
然后是cabin舱信息,只有200+数据,先看一下分布吧

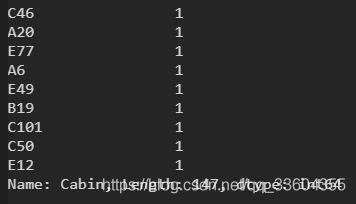
这个分布也太散了吧,200+数据分布在147个船舱,而且缺失值极多,感觉非常棘手,考虑到船舱与票价&票仓等级息息相关,我觉得后面可以放弃这个特征值,前面两者基本可以代替了…
特征工程
首先是补缺失值的问题
#fare只缺一个数据(在测试集),这里直接用中位数代替了
mid =X["Fare"].median()
mid
X.loc[X.Fare.isnull(),"Fare"]=14.4542
对于年龄,缺失的数据较少,利用模型(这里用随机森林)拟合,来填充数据
from sklearn.ensemble import RandomForestRegressor
to_fill_age=X[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
age_ =to_fill_age.loc[to_fill_age.Age.notnull()].values
un_age_=to_fill_age.loc[to_fill_age.Age.isnull()].values
X_AGE=age_[:,1:]
Y_AGE=age_[:,0]
RFR=RandomForestRegressor(random_state=42,n_estimators=500,n_jobs=-1)
RFR.fit(X_AGE,Y_AGE)
pred =RFR.predict(un_age_[:,1:])
X.loc[X.Age.isnull(),"Age"]=pred
最后是cabin这个特征值,我最初的,在训练集+测试集共1309数据,但只有295个记录了cabin的信息。缺失量实在太多,我本来想训练模型的时候舍弃这个数据,但是看到一些博主/论坛的文章,将cabin记录分成有记录(Yes)和无记录(No)两部分。如果从逻辑上来理解的话,这个数据大多数是无可查证的,但是如果能够在海难活下来,后续就可以(从幸存者中采访等)获得这部分信息。因此,有这组信息的人更有可能是活下来了。这样看也有些道理
Has_cabin =data.Survived[data.Cabin.notnull()]
No_cabin =data.Survived[data.Cabin.isnull()]
df=pd.DataFrame({'No':No_cabin.value_counts(),'Have':Has_cabin.value_counts()}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"Wether Survived")
plt.xlabel(u"Has Cabin or Not")
plt.ylabel(u"numbers")
plt.show()

我们将有Cabin数据转换成1,数据缺失转为0
X.loc[(X.Cabin.notnull()),'Cabin'] =1
X.loc[(X.Cabin.isnull()),'Cabin'] =0
特征工程的最后一步是把文本数据(非数字)转换成数字,前面对Cabin数据的处理也是相类似的
利用pandas的get_dummies函数进行独热编码
dummies_Embarked = pd.get_dummies(X['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(X['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(X['Pclass'], prefix= 'Pclass')
X = pd.concat([X, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1) #将哑编码的内容拼接到data_train后
X.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Embarked'], axis=1, inplace=True) # 把编码前的字段删除
效果如下:

归一化
经过独热编码的操作,现在的函数,只有Fare和Age两个特征是离散的,需要对其归一化处理
from sklearn.preprocessing import StandardScaler
age_scale =StandardScaler().fit(X.Age.values.reshape(-1,1))
X["Age_scaled"]=StandardScaler().fit_transform(X.Age.values.reshape(-1,1),age_scale)
fare_scale =StandardScaler().fit(X.Fare.values.reshape(-1,1))
X["Fare_scaled"]=StandardScaler().fit_transform(X.Fare.values.reshape(-1,1),fare_scale)
X.drop(["Age","Fare"],axis=1,inplace=True)
先存一下处理后的数据
#保存数据
X.to_csv("data.csv",index=0)
y.to_csv("label.csv",index=0)