一文走进hadoop大数据技术生态!
一文走进hadoop大数据技术生态!
- 一、概述
-
- 1.1 大数据与hadoop
- 1.2 组件介绍
- 二、部署
-
- 2.1 部署模式
- 2.2 单机部署方式
- 2.3 单机数据分析
-
- 2.3.1 热点词汇分析
- 三、核心组件架构介绍
-
- 3.1 HDFS架构及角色
-
- 3.1.1 HDFS角色--分布式文件系统
- 3.1.2 HDFS架构图
-
- 3.1.2.1 HDFS Client作用
- 3.1.2.2 NameNode作用
- 3.1.2.3 DataNode作用
- 3.1.2.4 Secondary NameNode作用
- 3.1.3 Client角色
- 3.1.4 NameNode和DataNode角色
- 3.1.5 Secondary namenode角色
- 3.2 Mapreduce架构及角色
-
- 3.2.1 Mapreduce架构图--分布式计算框架
- 3.2.2 JobTracker和Tasktracker
- 3.3.3 Map task和Reduce task
- 3.3 Yarn架构及角色
- 四、HDFS分布式集群
-
- 4.1 HDFS分布式集群(上)
-
- 4.1.1 slaves配置文件
- 4.1.2 xml语法格式
-
- 4.1.2.1 core-site.xml配置文件
- 4.1.2.2 hdfs-site.xml配置文件
- 4.2 HDFS分布式集群(下)
-
- 4.2.1 初始化hdfs
- 4.2.2 集群验证
- 4.2.3
- 4.3 hdfs文件系统使用
-
- 4.3.1 hdfs文件系统使用
- 五、使用集群分析数据
-
- 5.1 搭建yarn
-
- 5.1.1 mapreduce配置文件
- 5.1.2 yarn-site.xml配置文件
- 5.1.3 启动服务
- 5.1.4 使用集群分析数据
- 5.2 yarn节点管理
- 5.3 hdfs节点增加与恢复
-
- 5.3.1 HDFS新增节点
- 5.4 hdfs节点删除
-
- 5.4.1 删除节点
- 5.4.2 数据迁移
- 5.4.3 数据迁移状态
- 六、NFS网关设置
-
- 6.1 NFS网关配置(上)
-
- 6.1.1 用户管理
-
- 6.1.1.1 代理用户
- 6.1.1.2 添加用户(NFSGW、NameNode)
- 6.1.1.3 代理用户授权
- 6.1.2 Namenode配置
- 6.1.3 NFWGW配置
-
- 6.1.3.1 hdfs-site.xml配置文件
- 6.2 NFS网关配置(下)
-
- 6.2.1 运行NFS网关服务
-
- 6.2.1.1 配置NFSGW
- 6.2.1.2 在日志文件夹为代理用户授权
- 6.2.1.3 启动服务
- 6.2.1.4 mount挂载
- 6.2.1.5 mount挂载
- 6.2.2 挂载
一、概述
1.1 大数据与hadoop
Hadoop是什么
- Hadoop是一种分析和处理海量数据的软件平台
- Hadoop是一款开源软件,使用 JAVA 开发
- Hadoop可以提供一个分布式基础架构Hadoop特点
Hadoop特点
高可靠性、高扩展性、高效性、高容错性、低成本
hadoop官方文档: hadoop.apache.org/docs/
1.2 组件介绍
- GFS --》 HDFS(核心组件): GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用,可以运行于廉价的普通硬件上,提供容错功能
- MapReduce --》 MapReduce分布式计算框架(核心组件): 针对分布式并行计算的一套编程模型,由Map和Reduce组成,Map是映射,把指令分发到多个worker上,Reduce是规约,把worker计算出的结果合并
- Bigtable --》 Hbase: 存储结构化数据的数据库,建立在GFS、Scheduler、lock service和mapreduce之上
- Yarn 集群资源管理系统(核心组件)
- Zookeeper:分布式协作服务
- Hbase:分布式列存数据库
- Hive:基于Hadoop的数据仓库
二、部署
2.1 部署模式
- Hadoop部署模式有三种:单机
- 在一台机器上安装部署:伪分布式
- 在一台机器上安装部署,但区分角色:完全分布式
- 多机部署,不同角色服务安装在不同的机器上
2.2 单机部署方式
1、安装配置Java环境及jps工具
[root@hadoop1 ~]# yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel
2、查看java环境的版本,由java-1.8.0-openjdk提供
[root@hadoop1 ~]# java -version
3、上传hadoop源码包并解压(hadoop下载官网:http://hadoop.apache.org);
[root@hadoop1 ~]# tar -xf hadoop-2.7.7.tar.gz -C /root/ // 解压软件包
4、移动并重命名hadoop
[root@hadoop1 ~]# mv /root/hadoop-2.7.7 /usr/local/hadoop
5、修改hadoop目录下的所有文件的所有者和所属组为root,查看验证
[root@hadoop1 ~]# chown -R root:root /usr/local/hadoop/
**※、配置环境变量**
- hadoop 使用 java 执行,必须要配置 java 安装路径
- hadoop 的配置文件在 /usr/local/hadoop/etc/hadoop
- hadoop-env.sh 是启动 hadoop 的默认环境变量配置文件
JAVA_HOME="JAVA安装路径"
HADOOP_CONF_DIR="hadoop 配置文件路径"
验证: /usr/local/hadoop/bin/hadoop version
6、 rpm -ql 查看安装的软件包下的所有文件
#获取java的安装公共目录: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/
[root@hadoop1 ~]# rpm -ql java-1.8.0-openjdk
7、修改配置文件,在linux上启动hadoop命令的脚本配置文件
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre" # 修改环境变量
export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop" # 指定hadoop配置文件所在的路径
8、查看hadoop版本
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop version
2.3 单机数据分析
2.3.1 热点词汇分析
# 在hadoop目录下,创建一个目录input,用于存放要分析的数据
[root@hadoop1 ~]# mkdir /usr/local/hadoop/input
# 拷贝要分析的数据文件到input目录下
[root@hadoop1 ~]# cp /usr/local/hadoop/*.txt /usr/local/hadoop/input/
# 查看input目录下的数据
[root@hadoop1 ~]# ls /usr/local/hadoop/input/
# 配置hadoop的主机名解析
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.128 hadoop1
**分析**
# 进入到hadoop目录下
[root@hadoop1 hadoop]# cd /usr/local/hadoop/
# 查看hadoop命令的帮助信息,这里调用jar文件进行统计分析
[root@hadoop1 hadoop]# ./bin/hadoop
# jar文件为使用java开发处理的功能包
[root@hadoop1 hadoop]# ls share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
# 查看官方jar文件都有哪些统计方法;**wordcout** 统计单词的数量
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
# 查看wordcount的使用格式, 要处理的数据; 处理后数据存放的路径
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount
**执行hadoop的脚本命令,分析数据; 【INFO】 为正常处理输出信息;input 为要处理数据的目录路;ouput 处理后数据存放的目录**
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input ouput
# 在output目录下查看数据分析结果,第一列为单词;第二列为单词出现的次数
[root@hadoop1 hadoop]# cat ouput/*
三、核心组件架构介绍
3.1 HDFS架构及角色
3.1.1 HDFS角色–分布式文件系统
- HDFS 是Hadoop 体系中数据存储管理的基础,是一个高度容错的系统,用于在低成本的通用硬件上运行
- HDFS 角色和概念
- Client ——》客户端角色
- Namenode ——》管理者角色
- Secondarynode ——》 附加服务软件角色
- Datanode ——》 数据存储角色
3.1.2 HDFS架构图
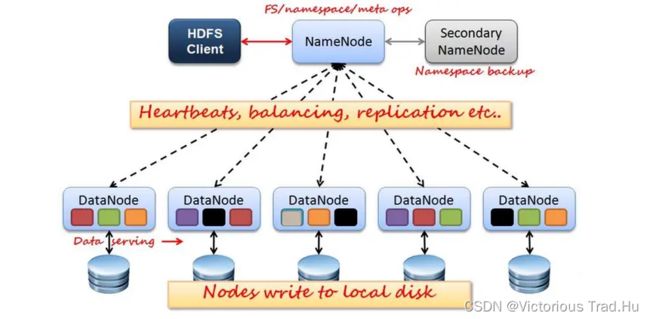
3.1.2.1 HDFS Client作用
1》 将数据切分,每份数据都存放到128M的空间中;
2》 与NameNode交互,获取每份数据存储的位置信息;
3》 与DataNode交互,写入或读取数据;
3.1.2.2 NameNode作用
1》 管理节点;
2》 当Client存储数据时,计算出数据的存储位置,告诉Client,并记录下数据的存储位置【由fsimage记录】;
3》 当Client读取数据时,NameNode告诉Client数据的存储位置;
4》 配置副本数量,当用户要把一份数据存储多份【备份】,由NameNode来向Client返回多个存储位置,Client将同一份数据存储多份在不同的数据节点上;
3.1.2.3 DataNode作用
1》 数据的存储节点,存储实际的数据;
2》 当Client存储数据时,NameNode告诉给Client数据的存储位置;
3》 当Client将数据真实存入DataNode节点以后,DataNode向NameNode发送数据存储成功的信息;
4》 NameNode接收到DataNode发送的数据存储成功的汇报后,才会由【fsimage】记录数据的存储位置;
3.1.2.4 Secondary NameNode作用
1》 fsimage记录数据存储的位置;
2》 fsedits数据变更日志;
3》 hadoop修改数据时,将数据的修改信息记录在数据变更日志中;当用户下次读取数据时,先从fsimage读取数据存储位置,再读取fsedits中的数据;如果存在数据的修改信息,则覆盖fsimage中的数据,从而完成hadoop中数据的修改;
4》 由于会频繁数据,fsedits中的数据会不断变大,占用资源,不方便管理;
5》 Secondary NameNode会定期合并fsimage和fsedits,推送给NameNode;而fseditsw文件大小就会清零,重新开始记录数据变化;
3.1.3 Client角色
- Client: 切分文件,访问HDFS; 与NameNode交互,获取文件位置信息; 与DataNode交互,读取和写入数据
- Block: 每块缺省128MB大小,每块可以多个副本
3.1.4 NameNode和DataNode角色
- NameNode: Mater节点;管理HDFS的名称空间和数据块映射信息(fsimage);配置副本策略,处理所有客户端请求
- DataNode: 数据存储节点,存储实际数据,汇报存储信息给NameNode
3.1.5 Secondary namenode角色
- Secondary namenode:定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode
- fsimage:名称空间和数据库的映射信息
- fsedits:数据变更日志
- 但Secondary NameNode并非NameNode的热备
3.2 Mapreduce架构及角色
3.2.1 Mapreduce架构图–分布式计算框架

JobTracker作用
接收客户端的任务请求,并将任务分解成多个子任务,将子任务派发给多个TaskTracker;
TaskTracker作用
运行Map Task和Reduce Task,最终执行任务的组件
3.2.2 JobTracker和Tasktracker
JobTracker
Mater节点只有一个;管理所有作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker
TaskTracker
Slave节点,一般是多台;运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态
3.3.3 Map task和Reduce task
Map Task
解析每条数据记录,传递给用户编写的map()并执行;将输出结果写入本地磁盘,如果为map-only作业,直接写入HDFS
Reducer Task
从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行
3.3 Yarn架构及角色

1》Resourcemanager处理客户端请求, 将任务分发给NodeManager;
2》NodeManager调用Container和ApplicationMaster;
Resourcemanager作用
1》处理客户端请求,资源分配与调度;
2》启动/监控 ApplicationMaster;
3》监控 NodeManager;
NodeManager作用
1》单个节点上的资源管理;
2》处理来自 ResourceManager 的命令;
3》处理来自 ApplicationMaster 的命令;
Container作用
1》对任务运行环境的抽象,封装了CPU、内存等;
2》启动命令等任务运行相关的信息资源分配与调度;
ApplicationMaster
1》数据切分;
2》为应用程序申请资源,并分配给内部任务;
3》任务监控与容错;
四、HDFS分布式集群
环境配置文件:hadoop-env.sh
核心配置文件:core-site.xml
HDFS配置文件:hdfs-site.xml
节点配置文件:slaves
4.1 HDFS分布式集群(上)
4.1.1 slaves配置文件
slaves是datanode节点的配置文件,声明的主机都会运行datanode守护进程
slaves格式:每行一个主机名(必须能ping通)
4.1.2 xml语法格式
- XML指可扩展标记语言
- XML中的每个元素名都是成对出现的。结束标签前加一个/
- hadoop xml配置格式
>
>关键字 >
>变量值 >
>描述 > >
4.1.2.1 core-site.xml配置文件
- fs.defaultsFS 文件系统配置参数
存入数据时需要和namenode进行交互,获取数据存放地址;这里声明namenode服务的地址
>fs.defaultFS >
>hdfs://hadoop1:9000 >
- hadoop.tmp.dir 数据目录配置参数(指定hadoop数据的存放路径)
>hadoop.tmp.dir >
>/var/hadoop >
配置示例:
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
<description>hdfs file system</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
</property>
</configuration>
4.1.2.2 hdfs-site.xml配置文件
- dfs.namenode.http-address: namenode 地址
>dfs.namenode.http-address >
>hadoop1:50070 >
- secondarynamenode: secondarynamenode 地址
>dfs.namenode.secondary.http-address >
>hadoop1:50090 >
- dfs.replication: 副本数量
>dfs.replication >
>2 >
配置示例:
dfs.namenode.http-address 声明在哪台机器上启动namenode
dfs.namenode.secondary.http-address 声明在哪台机器上启动secondarynamenode
dfs.replication 副本的数量,2 则代表和原数据加起来一共存储两份
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4.2 HDFS分布式集群(下)
4.2.1 初始化hdfs
- 创建数据目录,只在 namenode 上创建即可,其他 datanodde 主机可自动创建
mkdir /var/hadoop
- 格式化 hdfs,所有的提示必须都是INFO的
/usr/local/hadoop/bin/hdfs namenode -format
- 启动集群
/usr/local/hadoop/sbin/start-dfs.sh
-
查看hdfs集群启动后的日志目录,logs目录在集群启动后会生成
日志格式:
第一段: hadoop # 为服务名
第二段:root # 为启动该进程的用户名
第三段:namenode # 启动的角色名
第四段:hadoop1 # 角色所在的主机名.out 为标准输出;.log 为系统日志
[root@hadoop1 ~]# ls /usr/local/hadoop/logs/
4.2.2 集群验证
-report 显示集群的报告信息
Live datanodes (3): 显示集群datanode服务正常的数量
如果某个节点没有启动,查看对应节点的日志信息 /usr/local/hadoop/log
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
web 页面验证
http://hadoop1:50070 ——》 namenode服务
http://hadoop1:50090 ——》 secondarynamenode服务
http://node1:50075 ——》 datanode服务
4.2.3
/usr/local/hadoop/logs 文件夹在系统启动时会被自动创建
日志名称
服务名-用户名-角色名-主机名.out 标准输出
服务名-用户名-角色名-主机名.log 日志信息
4.3 hdfs文件系统使用
4.3.1 hdfs文件系统使用
web页面: 能查看,能读取,不能写入
命令行: 能查看,能读取,能写入;/usr/local/hadoop/bin/hadoop fs -命令
# 查看hadoop命令的帮助信息, fs 会运行一个操作hdfs的客户端
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop
# 查看fs客户端的使用方法
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs
# 查看hdfs文件系统的数据:/ 是hdfs文件系统的根目录
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -ls /
# 在hdfs的根目录下,创建目录input
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -mkdir /input
# 查看结果
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -ls
# 将当前目录下以.txt结尾的文件,上传到hdfs中/input目录下
[root@hadoop1 hadoop]# ./bin/hadoop fs -put *.txt /input
# 查看hdfs文件系统中/input下的数据,上传成功
[root@hadoop1 hadoop]# ./bin/hadoop fs -ls /input
五、使用集群分析数据
多个软件要同时部署在同一台机器上,要考虑软件占用的资源是否会冲突
DataNode: 存储节点,主要消耗系统的I/O(读写);
NodeManager: # 计算节点,主要消耗的系统资源为CPU和内存
5.1 搭建yarn
5.1.1 mapreduce配置文件
# 进入到hadoop的安装目录下
[root@hadoop1 ~]# cd /usr/local/hadoop/etc/hadoop/
# 拷贝模板文件
[root@hadoop1 hadoop]# cp mapred-site.xml.template mapred-site.xml
- mapreduce.framework.name 资源管理类
>mapreduce.framework.name >
>yarn >
- mapreduce.framework.name 要使用计算框架的必须选项,如果是单机版,值为local;如果是分布式集群,值则为yarn
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
>
>
>mapreduce.framework.name >
>yarn >
>
>
5.1.2 yarn-site.xml配置文件
- yarn.resourcemanager.hostname 管理主机
>yarn.resourcemanager.hostname >
>nn01 >
- yarn.nodemanager.aux-services 计算框架
>yarn.nodemanager.aux-services >
>mapreduce_shuffle >
配置示例:
-
yarn.nodemanager.aux-services 指定要使用的分布式计算框架,可以使用开发人员写的计算框架,这里采用的是官方提供的模板计算框架;
-
yarn.resourcemanager.hostname 指定resourcemanager的管理主机,为hadoop1
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
>
>
>yarn.nodemanager.aux-services >
>mapreduce_shuffle >
>
<!-- Site specific YARN configuration properties -->
>
>yarn.resourcemanager.hostname >
>hadoop1 >
>
>
5.1.3 启动服务
-
同步配置到所有主机
scp -r /usr/local/hadoop/etc node1:/usr/local/hadoop
scp -r /usr/local/hadoop/etc node2:/usr/local/hadoop
scp -r /usr/local/hadoop/etc node3:/usr/local/hadoop
-
启动服务
# 使用脚本启动resourcemanager的服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-yarn.sh
# 启动hdfs分布式文件系统的服务,没有开机自启动,需要重启
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-dfs.sh
# 查看resourcemanager下可管理的计算节点
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn node -list
5.1.4 使用集群分析数据
在上一个实验中,我们已经创建了目录,并上传了文件
/usr/local/hadoop/bin/hadoop fs -mkdir /input
/usr/local/hadoop/bin/hadoop fs -put *.txt /input/
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -ls / # 查看hdfs根目录下的数据
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -ls /input # 查看hdfs文件系统/input下的数据,用于数据分析
**分析数据**
调用jar包中的wordcount方法,统计/input目录中的数据,单词出现的次数/input和/output 均为hdfs分布式文件系统中的数据
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
**调用集群分析数据,查看结果**(在hdfs分布式文件系统中查看分析结果)
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -cat /output/*
5.2 yarn节点管理
# 启动单个节点的nodemanager服务
[root@yarnnode ~]# /usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager
# 查看角色,NodeManager角色启动
[root@yarnnode ~]# jps
# 查看ResourceManager下的节点信息
[root@hadoop1 hadoop]# /usr/local/hadoop/bin/yarn node -list
# 删除nodemanager服务节点
[root@yarnnode ~]# /usr/local/hadoop/sbin/yarn-daemon.sh stop nodemanager
删除后节点不会马上消失,需要等待一段时间后才会消失
# 查看ResourceManager下的节点信息
# yarnnode已经被删除了,这里依然显示,重启以后才会消失
[root@hadoop1 hadoop]# /usr/local/hadoop/bin/yarn node -list
# 停止resourcemanager服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager
# 启动resourcemanager服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
resourcemanager重启以后,会有个重新注册的过程,需要等待 1 ~ 2分钟;yarnnode信息消失
[root@hadoop1 hadoop]# /usr/local/hadoop/bin/yarn node --list
5.3 hdfs节点增加与恢复
5.3.1 HDFS新增节点
- 启动一个新的系统,设置SSH免密码登录
- 在所有节点修改 /etc/hosts,增加新节点的主机信息
- 安装java运行环境 (java-1.8.0-openjdk-devel)
- 拷贝NameNode 的 /usr/local/hadoop 到新节点
- 同步配置文件到所有机器
#安装 java-1.8.0-openjdk-devel; java-1.8.0-openjdk会作为依赖包被安装
[root@hadoop1 ~]# yum -y install java-1.8.0-openjdk-devel
[root@hadoop1 ~]# rsync -aXSH --delete /usr/local/hadoop newnode:/usr/local/
# 启动单个节点的DataNode服务
[root@newnode ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh start datanode
-report 显示集群的报告信息;Live datanodes
(4): 显示集群datanode服务正常的数量;如果某个节点没有启动,查看对应节点的日志信息 /usr/local/hadoop/log**
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
新节点上没有数据,需要从其他节点上拷贝数据,用于平衡数据;其他三个节点node1,node2,ndoe3,每个节点迁移一部分数据到newnode上
设置带宽,为了防止雪崩效应(即:当新节点创建后,其他机器都会想新节点拷贝数据,会导致新节点运行缓慢);设置迁移数据时的带宽,按字节进行计算,1Mb==8bytes
平时的网络带宽也是按字节计算的,千兆网,除以8,实际带宽为100多兆;一般机房的带宽为1000M,设置平衡数据的带宽为500M即可,为500000000
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -setBalancerBandwidth 500000000
# 开始平衡迁移数据,会在后台进行
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-balancer.sh
修复node节点
-
修复节点比较简单,步骤与增加节点一致
注意: 新节点的ip和主机名要与损坏节点的一致
-
如果旧节点数据丢失,新节点可以自动恢复数据
-
上线以后会自动恢复数据,如果数据量非常巨大,需要一段时间
5.4 hdfs节点删除
hdfs节点上会存储数据,直接删除节点会造成数据的丢失;
hdfs节点被删除前,要先进行数据的迁移;
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -ls -h / # 在hdfs文件系统下,查看光盘信息
查看hdfs不同节点使用空间的大小,验证hdfs上的备份存储,在hadoop1主机上操作;上传光盘之前,hdfs文件系统中存入数据的大小可以忽略不记;上传光盘之后,各节点所dfs所使用的空间大小,就是此次光盘文件在hdfs中占用的空间大小;
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
5.4.1 删除节点
- datanode 删除步骤
迁移数据;删除节点 - 配置 hdfs-site.xml 增加配置
- dfs.hosts.exclude
>dfs.hosts.exclude >
>/usr/local/hadoop/etc/hadoop/exclude >
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
>
>
>dfs.namenode.http-address >
>hadoop1:50070 >
>
>
>dfs.namenode.secondary.http-address >
>hadoop1:50090 >
>
>
>dfs.replication >
>2 >
>
**######## 此为新添加的配置信息,exclude文件中记录着要删除的节点名称 ########**
>
>dfs.hosts.exclude >
>/usr/local/hadoop/etc/hadoop/exclude >
>
>
# 在exclude文件中,写入要删除节点的主机名
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/exclude
5.4.2 数据迁移
# 在 namenode 上更改完配置文件就可以迁移数据了,这里不需要同步配置文件
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -refreshNodes
# 查看newnode数据节点的状态信息,数据正在迁移
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
5.4.3 数据迁移状态
- 三种状态:
- Normal正常状态
- Decommissioned in program:数据正在迁移
- Decommissioned 注意仅当状态当Decommissioned 才能down机下线
六、NFS网关设置
6.1 NFS网关配置(上)
NFS网关用途
- 用户可以通过操作系统,兼容本地NFSv3客户端,来浏览HDFS文件系统
- 用户可以通过挂载点直接流化数据
- 允许HDFS作为客户端文件系统的一部分被挂载
- 支持文件附加,但是不支持随机写(nolock)
- NFS网关目前只支持NFSv3 和 TCP 协议(vers=3, proto=tcp)
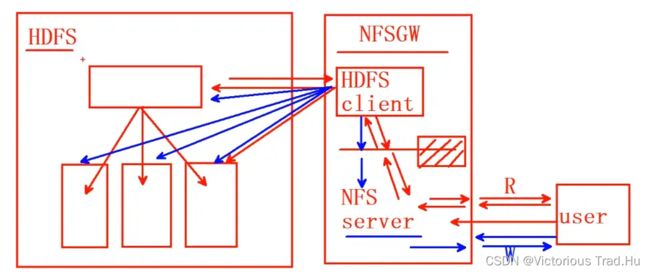
1》用户可以使用NFS版本3的客户端,浏览HDFS文件系统;
2》HDFS不支持mount, 只能通过NFS客户端的方式完成读和写数据;NFS网关,可以让HDFS文件系统被mount 挂载使用;
3》只支持文件附加,不支持随机写(没有锁的机制,即:一个程序执行写操作时,其他程序无法执行写操作,必须等待上一个程序操作完成才可以);
4》NFS网关只支持NFS版本3和TCP协议;
1》NFS网关是独立于HDFS之外的一台机器;
2》NFS网关由两部分组成:HDFS客户端(和HDFS交互)和NFS server(和用户交互);
3》user用户读写数据时,先访问【NFS server】,再由【NFS server】去访问【HDFS client】,最后由【HDFS client】从HDFS中读取或写入数据;
4》如果是用户写入数据时,【NFS server】会先将用户的写入操作存入一个NFS网关的【临时目录】中,然后【HDFS client】会从【临时目录】中读取数据,和HDFS进行交互;
6.1.1 用户管理
6.1.1.1 代理用户
- 配置代理用户
在NameNode 和 NFSGW 上添加代理用户
代理用户的UID,GID,用户名必须完全相同如果因特殊原因,用户的UID、GID、用户名不能保持一致,需要我们配置 nfs.map 的静态映射关系 - 如果因特殊原因,用户的UID、GID、用户名不能保持一致,需要我们配置nfs.map的静态映射关系
- 例如:
- uid 10 100 # Map the remote UID 10 to the local UID 100
- gid 11 101 # Map the remote GID 11 to the local GID 101
将远程的UID 10或GID 11,映射到本地UID 100或GID 101(本次实验不采用)
6.1.1.2 添加用户(NFSGW、NameNode)
groupadd -g 800 nfsuser
useradd -u 8000 -g 800 -r -d /var/hadoop nfsuser
# 创建组, -g 指定GID
[root@nfsgw ~]# groupadd -g 800 nfsuser
# 创建用户,-u 指定UID;-g 指定GID;-r 指创建系统账户;-d 自定义家目录
[root@nfsgw ~]# useradd -u 800 -g 800 -r -d /var/hadoop nfsuser
# 创建组, -g 指定GID
[root@hadoop1 ~]# groupadd -g 800 nfsuser
# 创建用户,-u 指定UID;-g 指定GID;-r 指创建系统账户;-d 自定义家目录
[root@hadoop1 ~]# useradd -u 800 -g 800 -r -d /var/hadoop nfsuser
※ 注意事项
- 在安全模式下,Kerberos keytab 中的用户是代理用户
- 在非安全模式下,运行网关进程的用户必须是代理用户
- 在 NameNode 和 NFSGW 上代理用户的 UID,GID,用户名必须完全相同
6.1.1.3 代理用户授权
- 配置core-site.xml
- hadoop.proxyuser.{代理用户}.groups # 挂载点用组授权
>hadoop.proxyuser.nfsuser.groups >
>*
- hadoop.proxyuser.{代理用户}.hosts #挂载点主机授权
>hadoop.proxyuser.nfsuser.hosts >
>*
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
>
>
>fs.defaultFS >
>hdfs://hadoop1:9000 >
>hdfs file system >
>
>
>hadoop.tmp.dir >
>/var/hadoop >
>
**############# 新添加的参数,允许所有的组进行挂载 ############**
>
>hadoop.proxyuser.nfsuser.groups >
>*
>
**############# 新添加的参数,允许所有的主机进行挂载 ############**
>
>hadoop.proxyuser.nfsuser.hosts >
>*
>
>
6.1.2 Namenode配置
配置 /etc/hosts,添加新节点信息
NameNode既要和Client进行交互,也要和DataNode进行交互,需要知道NFS网关的主机名
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.51 node1
192.168.1.52 node2
192.168.1.53 node3
192.168.1.54 newnode
192.168.1.55 yarnnode
192.168.1.56 nfsgw
授权
// 停止 hadoop 集群的所有服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/stop-all.sh
// 启动hdfs集群
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-dfs.sh
// 查看集群的状态信息,Live datanodes (3)
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
6.1.3 NFWGW配置
配置步骤: 创建一条新主机,卸载rpcbind、nfs-utils
// 卸载系统上的nfs服务,会和我们部署HDFS的nfs网关冲突
[root@nfsgw ~]# yum -y remove rpcbind nfs-utils
// 安装java-1.8.0-openjdk依赖包
[root@nfsgw ~]# yum -y install java-1.8.0-openjdk-devel
6.1.3.1 hdfs-site.xml配置文件
- nfs.exports.allowed.hosts #访问策略及读写权限
>nfs.exports.allowed.hosts>
>* rw >
- nfs.dump.dir #文件转存目录
>nfs.dump.dir >
>/var/nfstmp >
- nfs网关是一个单独的服务
**添加新nfs的参数即可,其他不需要修改**
[root@nfsgw ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
**nfs.exports.allowed.hosts 设置访问策略与读写权限**
>
* rw 所有主机,对hdfs拥有读写权限(rw 只读权限),如果有多条,以 ;分割
>
>nfs.exports.allowed.hosts >
>* rw >
>
**转储目录(写入数据时,先将数据存入此目录中,最后统一上传)**
>
>nfs.dump.dir >
>/var/nfstmp >
>
>
6.2 NFS网关配置(下)
6.2.1 运行NFS网关服务
6.2.1.1 配置NFSGW
# 创建转存目录,转储目录的磁盘要大一些,防止大量数据的写入,空间不足的问题
[root@nfsgw ~]# mkdir /var/nfstmp
# 修改转储目录的权限,使nfsuser用户或nfsuser组中用户,可以存储数据
[root@nfsgw ~]# chown nfsuser.nfsuser /var/nfstmp/
# 查看验证授权
[root@nfsgw ~]# ls -ld /var/nfstmp/
6.2.1.2 在日志文件夹为代理用户授权
# 删除logs下的所有数据
[root@nfsgw ~]# rm -rf /usr/local/hadoop/logs/*
# 为logs日志设置acl访问权限,让nfsuser用户对此目录拥有rwx权限
[root@nfsgw ~]# setfacl -m u:nfsuser:rwx /usr/local/hadoop/logs
# 查看logs日志文件的权限
[root@nfsgw ~]# getfacl /usr/local/hadoop/logs/
※ 注意事项:
- 启动 portmap 需要使用 root 用户
- 启动 nfs3 需要使用 core-site 里面设置的代理用户
- 必须为代理用户授权(/var/nfstmp,/usr/local/hadoop/logs)
- 必须先启动 portmap 之后再启动 nfs3
- 如果 portmap 重启了,在重启之后 nfs3 也必须重启
6.2.1.3 启动服务
# 进入到hadoop的安装目录下
[root@nfsgw ~]# cd /usr/local/hadoop/
# 使用root用户先启动portmap服务
[root@nfsgw hadoop]# ./sbin/hadoop-daemon.sh --script ./bin/hdfs start portmap
使用代理用户启动nfs3
[root@nfsgw hadoop]# sudo -u nfsuser ./sbin/hadoop-daemon.sh --script ./bin/hdfs start nfs3
查看日志信息;nfs3的服务日志,所有者和所属组均为代理用户:nfsuser;portmap 的服务日志,所有者和所属于组均为root用户
[root@nfsgw hadoop]# ls -l logs/
6.2.1.4 mount挂载
- 目前 NFS 只能使用v3版本
vers=3 - 仅使用 TCP 作为传输协议
proto=tcp - 不支持随机写 NLM
nolock
6.2.1.5 mount挂载
-
禁用 access time 的时间更新 noatime
access time:为访问时间,即文件每被访问一次,就会更新一下文件的访问时间,访问频繁则会占用大量的系统资源,影响nfs网关的性能,所以需要禁用【noatime】;
-
禁用 acl 扩展权限 noacl
NFS网关不支持扩展权限,需要禁用【noacl】;
-
同步写入,避免重排序写入 sync
NFS网关不支持随机写,只支持顺序读写;为了避免重排序写入,带来不可预料的突发流量【流量的增加或减少】;为了数据存储的安全性和稳定性,不采用异步写入,设置为同步写入;
6.2.2 挂载
# 安装nfs的客户端软件
[root@newnode ~]# yum -y install nfs-utils
# 查看192.168.1.56主机上的共享目录
[root@newnode ~]# showmount -e 192.168.1.56
# 挂载nfs网关到/mnt目录下;-t 指定挂载的类型,为nfs;-o 指定挂载的选项:版本为v3版;协议为tcp协议;没有锁机制;禁用更新访问时间;禁用acl扩展;采用同步复制
[root@newnode ~]# mount -t nfs -o vers=3,proto=tcp,nolock,noatime,noacl,sync 192.168.1.56:/ /mnt/
# 查看/mnt,可以看到hdfs文件系统中的数据,挂载成功
[root@newnode ~]# ls /mnt/
#-t 指定挂载的类型,为nfs
#-o 指定挂载的选项:版本为v3版;协议为tcp协议;没有锁机制;禁用更新访问时间;禁用acl扩展;采用同步写入
# 配置nfs的永久性挂载
[root@newnode ~]# vim /etc/rc.d/rc.local
[root@yarnnode ~]# mount -t nfs -o vers=3,proto=tcp,nolock,noatime,noacl,sync 192.168.1.56:/ /mnt/