实验六-线性分组码的MATLAB实现
信息论编码实验3~9连载,更多看专栏。
线性分组码的MATLAB实现
- 一、线性分组码原理介绍
-
- 1.1 信道编码基本概念
- 1.2 分组编码
-
- 1.2.1 编码
- 1.2.2 译码
- 1.2.3 线性分组码的距离和纠错能力
- 二、(7,4)汉明码编译码实例
- 三、代码展示及运行结果
-
- 3.1 (7,4)汉明码编码
- 3.2 (7,4)汉明码译码
- 3.3 (7,4)汉明码性能探究
- 四、程序自评价
一、线性分组码原理介绍
1.1 信道编码基本概念
信道编码 也叫 差错控制编码,指在将要传输的信息序列中人为的添加一些保护成分(监督码元),从而在接收端译码时可以进行自动纠错(当然,这种纠错能力是有限的),从而增强了信号的抗干扰能力。
假设 发送序列长度 为 n,其中信息码元数为 k,监督码元数为 n-k,则:
编码效率(码率)= k / n;
冗余度= (n-k) / k;
信道编码分为 分组编码 和 卷积编码。两者都是将原始信息流按长度 k 分组,再按照各自的编码规则映射成 长度为n的码组 进行发送。不同的是,对于每个码组的监督码元(长度为n-k),分组编码仅与本码组的 k 个信息码元有关,而卷积编码则同时与前 N-1 个码组及本码组的(共N*k个)信息码元有关(其中,N 被称为 编码约束度 )。
于是,根据上述定义的变量,对于上述两类编码有命名:
(n,k)分组码;
(n,k,N)卷积码;
本实验以(7,4)分组码为例演示分组编码,卷积编码则在实验七中进行演示。
1.2 分组编码
1.2.1 编码
M=(mk-1,mk-2,…,m1,m0)为单个码组中的信息码元;
C=(cn-1,cn-2,…,c1,c0)为分组编码后的分组码;
分组编码的映射规则如下:
 若 fi(·),(i=0,1,…,n-1)均为线性函数,则称 C 为 线性分组码。若我们处理的码流都是二元信号(即元素为{0,1}),则称 C 为 二元线性分组码。这也是本实验的情况。
若 fi(·),(i=0,1,…,n-1)均为线性函数,则称 C 为 线性分组码。若我们处理的码流都是二元信号(即元素为{0,1}),则称 C 为 二元线性分组码。这也是本实验的情况。
也就是说,编码过程为 k 个信息码的线性组合:
 其中,G 是生成矩阵,由 k 个线性无关的行向量(基底)组成,注意到每一个基底都包含 n 个元素,它的系统形式(一种标准形式)为:
其中,G 是生成矩阵,由 k 个线性无关的行向量(基底)组成,注意到每一个基底都包含 n 个元素,它的系统形式(一种标准形式)为:
 则编码过程进一步写为:
则编码过程进一步写为:
![]() 之所以再写一遍是因为终于出现了最开始提到的概念:
之所以再写一遍是因为终于出现了最开始提到的概念:
M 是信息码元;
MP 是监督码元;
于是,我们就完成了将 k 维空间的信息码元映射到n维空间的编码过程。这多出来的 n-k 维元素将帮助我们在接收端进行纠错。

1.2.2 译码
在二进制序列传输的过程的,显然不可避免的会出现差错,定义为:
错误图样 E=(en-1,en-2,…,e1,e0),发生错误的地方为1,其余为0;
则接收序列为 R = C + E 。根据神奇的线性代数知识,由于生成矩阵 G 是由 k 个线性无关的行向量组成,所以必然存在一个校验矩阵 H,使得 GHT=0,其中:![]() 则解码过程为:
则解码过程为:
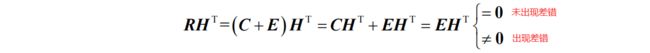 其中, EHT 被称为 伴随式。
其中, EHT 被称为 伴随式。
由于 H 是已知的,所以根据接收结果我们就可以知道错误图样是什么,这就完成了纠错!!(感谢神奇的线性代数)。
1.2.3 线性分组码的距离和纠错能力
但是当然了,这个纠错能力是有限的,下面我们来具体的量化一下。
码距 定义为两个码组间对应位置不同的位数,也叫 汉明距离,记为 d。而所有码组间距离的最小值被称为 最小码距:
![]() 于是对于线性分组码,纠错能力 为:
于是对于线性分组码,纠错能力 为:
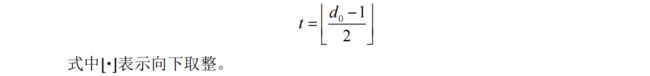 并且要注意:纠错能力 t 只是说明距离 t 以内的差错一定能纠正,并非说距离大于 t 的差错一定不能纠正。 因为纠错的本质就是计算当前的序列和哪个正确序列的码距最短,假如有一个码组错误位数超过 t,但是只有一个正确序列和它距离最短,那就可以认为纠正回来了。
并且要注意:纠错能力 t 只是说明距离 t 以内的差错一定能纠正,并非说距离大于 t 的差错一定不能纠正。 因为纠错的本质就是计算当前的序列和哪个正确序列的码距最短,假如有一个码组错误位数超过 t,但是只有一个正确序列和它距离最短,那就可以认为纠正回来了。
另外,按照定义计算最小码距很复杂。但是再次根据神奇的线性代数知识(二元线性分组码的封闭性),任意两个线性码组之和仍为许用码组,所以那两个码组间的距离就是另一个码组的 码重(码组中1的个数)。所以 码组中的最小码重=最小码距。
二、(7,4)汉明码编译码实例
终于可以看实例了。
假如我们选择(7,4)汉明码,且令生成矩阵为:

将待编码序列分成长度为 4 的信息码元,根据生成矩阵计算出监督码元:

上面就是编码的过程,下面进行解码。
首先根据 1.2.2 的内容,由生成矩阵可以得到校验矩阵:

再根据上面发送码组的所有情况,发现最小码重=3(0要排除在外),于是纠错能力t=1,于是根据只发生一位错误的错误图样得到伴随式(接收到码组的最后三位)的所有情况:

因为只有当伴随式=[000]的时候才认为没有错误,所以当伴随式为其他情况时,就默认错误是对应的错误图样,然后进行相应的纠正。当然,也有可能错了好几位也得到相同的伴随式,但那种情况我们(7,4)汉明码把握不住,所以也就按照上述那么处理了。这个时候就指望着我们的信道环境不要太差,错个一位就差不多得了。
然后再取出改正后码组的前四位,就得到我们的信息码元了。完成译码。
三、代码展示及运行结果
3.1 (7,4)汉明码编码
下面来验证上述编码实例,假设发送序列是M=[1 0 1 1 0 1 0 1 1 0],分组时不足 4 的整倍数将进行补零。
%% 实验六-汉明码编码过程
clear all
clc
%% 主函数
M = [1 0 1 1 0 1 0 1 1 0];
G = [1 0 0 0 1 1 0;...
0 1 0 0 1 0 1;...
0 0 1 0 0 1 1;...
0 0 0 1 1 1 1];
C = hamming(M,G)
function C = hamming(M,G)
[k,n] = size(G);
% 输入序列补位
N = size(M,2); % 获得输入序列元素个数
r = k-rem(N,k); % 获得需要对输入序列进行补位的个数
M_add0 = [M,zeros(1,r)];% 补位
% 将输入信息序列进行分组
groups = ceil(length(M_add0)/k); % 获得分组个数
M_dis = reshape(M_add0,[k,groups]).';
%{
M_dis = zeros(groups,k);
for i=1:groups
M_dis(i,:) = M_add0(1,(1:k)*groups);
end
%}
% 生成编码结果C
C = mod(M_dis*G,2);% 生成结果别忘了对2取余
end
得到结果为:

每一行代表一个码组。
3.2 (7,4)汉明码译码
在上述编码的基础上添加译码子函数,完成对上述结果的译码。
%% 实验六-汉明码译码过程
clear all
clc
%% 主函数
% 生成分组编码C
M = [1 0 1 1 0 1 0 1 1 0];
G = [1 0 0 0 1 1 0;...
0 1 0 0 1 0 1;...
0 0 1 0 0 1 1;...
0 0 0 1 1 1 1];
C = hamming(M,G);
% 生成错误图样
% 第一行未发生错误、第二行发生一位、第三行发生两位错误
e = [0 0 0 0 0 0 0;...
1 0 0 1 0 0 0;...
0 1 0 0 0 0 0];
R = mod(C+e,2);
C_result = decode(R,G)
% 汉明译码
function C_result = decode(R,G)
%{
输入:
接收序列R
生成矩阵G
输出:
译码结果C_result
%}
% groups代表接收序列的编码组数
[groups,~] = size(R);
% k代表每组中的信息码元大小,n代表一个组里面包含样本点数
[k,n] = size(G);
% 根据G生成校验矩阵
H = [G(:,k+1:n).',eye(groups)];
% 生成伴随式S
S = mod(R*(H.'),2);
[S_row,S_column] = size(S);
% 设置伴随式和错误图样的对应元胞矩阵
SE = {[0 0 0],[0 0 0 0 0 0 0];...
[0 0 1],[0 0 0 0 0 0 1];...
[0 1 0],[0 0 0 0 0 1 0];...
[1 0 0],[0 0 0 0 1 0 0];...
[1 1 1],[0 0 0 1 0 0 0];...
[0 1 1],[0 0 1 0 0 0 0];...
[1 0 1],[0 1 0 0 0 0 0];...
[1 1 0],[1 0 0 0 0 0 0]};
% 找出计算出的伴随式所对应的错误图样,并进行纠正
C_result = zeros(S_row,n);
[SE_row,SE_column] = size(SE);
for m=1:S_row
for n=1:SE_row
if all(S(m,:) == cell2mat(SE(n,1)))
C_result(m,:) = R(m,:)+cell2mat(SE(n,2));
C_result(m,:) = mod(C_result(m,:),2);
end
end
end
C_result = C_result(:,1:k);
end
% 生成汉明码
function C = hamming(M,G)
[k,n] = size(G);
% 输入序列补位
N = size(M,2); % 获得输入序列元素个数
r = mod(-rem(N,k),k); % 获得需要对输入序列进行补位的个数
M_add0 = [M,zeros(1,r)];% 补位
% 将输入信息序列进行分组
groups = ceil(length(M_add0)/k); % 获得分组个数
M_dis = reshape(M_add0,[k,groups]).';
%{
M_dis = zeros(groups,k);
for i=1:groups
M_dis(i,:) = M_add0(1,(1:k)*groups);
end
%}
% 生成编码结果C
C = mod(M_dis*G,2);% 生成结果别忘了对2取余
end
译码结果为:
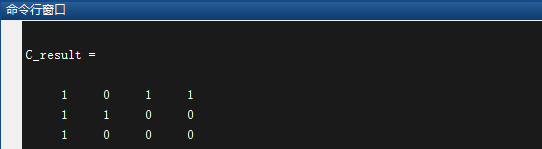
每一行对应一个码组,结合输入序列为[1 0 1 1 0 1 0 1 1 0],可以看出第三组最后两位进行了补零,而且结果很正确;但是第二组由于发生了两个错误所以没有正确的解译出来。
3.3 (7,4)汉明码性能探究
下面来点有意思的。在 AWGN 信道传输与 BPSK 调制的条件下,绘制未编码系统 与(7,4)汉明编码系统的误码率曲线。信噪比范围:0~5dB,系统流程图如下:
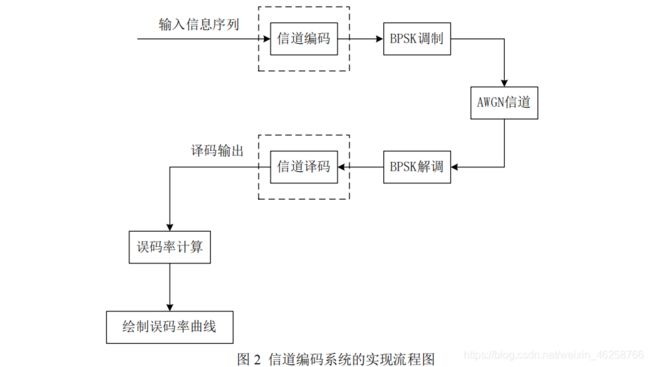 碰到这种情况当然是进行蒙特卡洛仿真了,所以程序应该可以输入总共发送的符号数。并且,也要注意在发送过程中要是将矩阵形式转换成码流。另外还增加了子函数用于仿真BPSK-AWGN信道。代码如下:
碰到这种情况当然是进行蒙特卡洛仿真了,所以程序应该可以输入总共发送的符号数。并且,也要注意在发送过程中要是将矩阵形式转换成码流。另外还增加了子函数用于仿真BPSK-AWGN信道。代码如下:
%% 实验六-(AWGN信道BPSK调制)未编码系统与(7,4)汉明码的BER-SNR对比
clear all
clc
%% 主函数
N = input('每个信噪比条件下要发送多少个样本点:');
snrdB_min = 0; snrdB_max = 5;% SNR范围是0-5dB
snrdB = snrdB_min:1:snrdB_max;
sym_initial = round(rand(1,N));% 生成原始序列
% 获得汉明码编码C_hamming
G = [1 0 0 0 1 1 0;...
0 1 0 0 1 0 1;...
0 0 1 0 0 1 1;...
0 0 0 1 1 1 1]; % 生成矩阵G
[k,n] = size(G);
C_ham = hamming(sym_initial,G);
[groups,~] = size(C_ham);
C_ham_stream = reshape(C_ham.',[1,length(C_ham(:))]);% 转换成码流
% 两种序列都通过BPSK-AWGN信道
[~,BER_dir] = BPSK(sym_initial,snrdB);% 未编码码流
[RX_ham,~] = BPSK(C_ham_stream,snrdB);% 汉明编码码流
% 汉明码解码并计算SNR
errors_ham = zeros(1,length(snrdB)); % 预分配错误内存
for i=1:length(snrdB)
RX_ham1 = reshape(RX_ham(i,:),[n,groups]).';
C_result1 = decode(RX_ham1,G);
errors_ham(i) = sum(sum(mod(C_result1+C_ham(:,1:k),2)));
end
BER_ham = errors_ham/N; % 得到BER
% 计算两种方案的BER-SNR曲线
figure
semilogy(snrdB,BER_dir,'*-',snrdB,BER_ham,'o-');grid on;
%axis([snrdB_min snrdB_max 0.0001 1]);
xlabel('信噪比 SNR / dB');ylabel('误码率 BER');
title(['发送的信息序列长度为 ',num2str(N)]);
legend('未编码系统','汉明编码系统');
% 直接显示数值
disp(['未编码系统',num2str(BER_dir)]);
disp(['汉明编码系统',num2str(BER_ham)]);
% 子函数-完成BPSK-AWGN信道的仿真
function [RX,BER] = BPSK(TX,SNR)
%{
输入:
原始码元序列Tx
信噪比范围SNR(dB)
输出:
接收判别后序列RX
信噪比对应的误码率序列BER
%}
N = length(TX); % 获得原始序列长度
snr = 10.^(SNR/10); % 转化成公制
len_snr = length(snr); % 获得SNR范围长度
RX = zeros(len_snr,N); % 预分配接收判别序列内存
errors = zeros(1,len_snr); % 预分配错误内存
for j=1:len_snr % 遍历所有SNR
sigma = sqrt(1/(2*snr(j))); % 计算SNR下AWGN的标准差
error_count = 0;
for i=1:N % 遍历每一个发送符号
x_d = 2*TX(i) - 1; % 得到+1和-1的发送序列
n_d = sigma*randn(1); % GWN
y_d = x_d + n_d; % 加性噪声
if y_d > 0
RX(j,i) = 1;
else
RX(j,i) = 0;
end
if (RX(j,i) ~= TX(i))
error_count = error_count + 1; % 对错误样本进行计数
end
end
errors(j) = error_count; % 得到该信噪比下的错误个数
end
BER = errors/N; % BER estimate
end
% 子函数-汉明码编码
function C = hamming(M,G)
[k,n] = size(G);
% 输入序列补位
N = size(M,2); % 获得输入序列元素个数
r = mod(-rem(N,k),k); % 获得需要对输入序列进行补位的个数
M_add0 = [M,zeros(1,r)];% 补位
% 将输入信息序列进行分组
groups = ceil(length(M_add0)/k); % 获得分组个数
M_dis = reshape(M_add0,[k,groups]).';
% 生成编码结果C
C = mod(M_dis*G,2);% 生成结果别忘了对2取余
end
% 子函数-汉明码解码
function C_result = decode(R,G)
%{
输入:
接收序列R
生成矩阵G
输出:
译码结果C_result
%}
[k,n] = size(G);
% 根据G生成校验矩阵
H = [G(:,k+1:n).',[1 0 0;0 1 0;0 0 1]];
% 生成伴随式S
S = mod(R*(H.'),2);
[S_row,S_column] = size(S);
% 设置伴随式和错误图样的对应元胞矩阵
SE = {[0 0 0],[0 0 0 0 0 0 0];...
[0 0 1],[0 0 0 0 0 0 1];...
[0 1 0],[0 0 0 0 0 1 0];...
[1 0 0],[0 0 0 0 1 0 0];...
[1 1 1],[0 0 0 1 0 0 0];...
[0 1 1],[0 0 1 0 0 0 0];...
[1 0 1],[0 1 0 0 0 0 0];...
[1 1 0],[1 0 0 0 0 0 0]};
% 找出计算出的伴随式所对应的错误图样,并进行纠正
C_result = zeros(S_row,n);
[SE_row,SE_column] = size(SE);
for m=1:S_row
for n=1:SE_row
if all(S(m,:) == cell2mat(SE(n,1)))
C_result(m,:) = R(m,:)+cell2mat(SE(n,2));
C_result(m,:) = mod(C_result(m,:),2);
end
end
end
C_result = C_result(:,1:k);
end
我输入就假设发送的原始码流有50w个符号,输出结果如下:

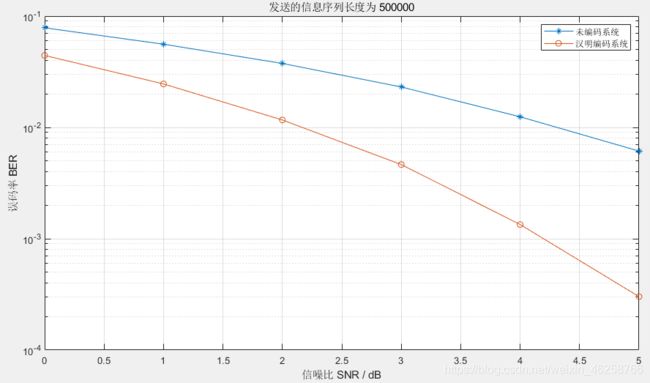
可以看出,增加分组码可以明显的提升系统性能,针不戳。
四、程序自评价
1.关于切割码流。编码函数只需要输入码流和生成矩阵,这很好。但是编码函数将各码组按行输出,想要传送还需要将其在主函数中 reshape 成码流;解码函数也需要提前将码流 reshape 成切割好的码流,这造成程序的移植性差。需要的小伙伴可以将 reshape 的过程放到子函数里,我就懒得改了。
2.自动计算(n,k)。这是优点,汉明码的编解码函数可以自动识别(n,k),用户只要输入自己的生成函数和码流即可(包括上面切割的过程也不需要调参),这增强了移植性。
代码原创,但因为原理编写参考到了实验课的指导书,假如有什么不对的地方,侵删。