MergerTree 引擎 ReplacingMergeTree 引擎 VersionedCollapsingMergeTree 引擎
**该 MergeTree系列的引擎和其他引擎是最强大的ClickHouse引擎 。
主要是将大量的数据插入到表中,数据快速的逐个部分写入到表中,
然后应用规则在后台合并这些部分。这种方法比插入期间连续重写存储中的 数据效率更高 **
主要特点:
1) 存储按逐渐排序的数据
这时可以创建一个小的稀疏索引,以便更快的查找数据
2) 如果指定了分区键,则可以使用分区
ClickHouse 支持某些分区操作,这些操作比对相同数据,相同结果的常规操作更有效。ClickHouse 还会自动切断在查询中指定了分区数据,这也提高了查询性能。
MergerTree 引擎底层存储数据以Tree基本存储结构
1) 维护节点关系 : 方便分区
2) 方便 CRUD
3)排序 方便索引
4)合并(归并)
MergerTree 引擎
一 建表 设置引擎
create table tb_tree1(
id String ,
name String ,
city String
)
engine = MergeTree 设置引擎
order by id;
----- 导入数据
insert into tb_tree1 values('id001','wb','HB'),('id002','DHT','HN'),('id003','ZXX','HLJ');
insert into tb_tree1 values('id004','wb','HB'),('id005','DHT','HN'),('id006','ZXX','HLJ');
insert into tb_tree1 values('id007','wb2','HB'),('id008','DHT2','HN'),('id009','ZXX2','HLJ');
---- 合并数据
optimize table tb_tree1 ;
合并多次插入数据的分区 ,合并后多余的会自动删除
ReplacingMergeTree 引擎
**它是需要写数据版本的**
**
这个引擎是在 MergeTree的基础上,添加了“处理重复数据”的功能,
该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行, 所以你无法预先作出计划。有一些数据可能仍未被处理。
因此,ReplacingMergeTree
适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
看下效果 演示
一 建表
create table tb_replacing_tree(
id String ,
name String ,
v UInt8 ----> 数据版本
)
engine = ReplacingMergeTree(v) ----> 要把数据版本放进来
order by id; ----> 主键
插入数据
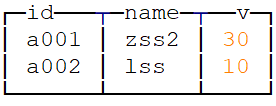
insert into tb_replacing_tree values ('a001','zss',10),('a002','lss',10) ;
insert into tb_replacing_tree values ('a001','zss2',30),('a002','lss2',5) ;

合并数据
optimize table tb_replacing_tree ;
去重主键相同的数据 保留v版本大的数据 删除操作发生在合并时
**
CollapsingMergeTree(开发中不怎么用)
不可控的
**
> ClickHouse实现了CollapsingMergeTree来消除ReplacingMergeTree的限制 (只删除小版本字段,只保留最大版本数据)。
该引擎要求在建表语句中指定一个标记列Sign,后台Compaction时会将主键相同、Sign相反的行进行折叠,也即删除。
一 建表
create table tb_collapsing_mergeTree(
id String ,
name String ,
accTime DateTime ,
flag Int8 打一个标记 (sign) 指定的删除的位置
)
engine = CollapsingMergeTree(flag) order by id ;
插入数据
insert into tb_collapsing_mergeTree values('a001','zss1',now() , 1) ;
insert into tb_collapsing_mergeTree values('a001','zss3',now() , -1) ;
insert into tb_collapsing_mergeTree values('a001','zss2',now() , 1) ;
-1 删除上一行数据
注意:
CollapsingMergeTree虽然解决了主键相同的数据即时删除的问题,但是状态持续变化且多线程并行写入情况下,状态行与取消行位置可能乱序,导致无法正常折叠。只有保证老的状态行在在取消行的上面,
新的状态行在取消行的下面! 但是多线程无法保证写的顺序!
VersionedCollapsingMergeTree
取消字段和数据版本同事使用,避免取消行数据无法删除的问题
指定删除数据的版本
一 建表
create table tb_versioned_collapsing_mergetree(
id UInt8 ,
name String ,
version UInt8 ,
sign Int8
)
engine = VersionedCollapsingMergeTree(sign, version)
order by id ;
二 导入数据
insert into tb_versioned_collapsing_mergetree values(1,'a',1,1),(1,'b',2,1) ;
insert into tb_versioned_collapsing_mergetree values(1,'a2',3,1) ;
insert into tb_versioned_collapsing_mergetree values(1,'a',2,-1) ;
-1 标记 删谁写谁