blog增量追加ing~(1/10阶段)ctf oj
18.2.15-CTF之隐写术LSB(最低有效位):
知识查询准备:
- 隐写是将Flag隐藏到图片、音频、视频等各类数据载体中
- PNG文件中的图像像数一般是由RGB三原色(红绿蓝)组成,每一种颜色占用8位,取值范围为0x00~0xFF,即有256种颜色,一共包含了256的3次方的颜色,即16777216种颜色,但是人类的眼睛具有一定的容错度,LSB隐写就是修改了像素中的最低的1bit。在人眼中不会注意到这前后的变化。这样就把信息隐藏起来的。
- PNG 文件头:89504E47 文件尾:AE426082
GIF 文件头:47494638 文件尾: 003B
JPEG 文件头:FFD8FF 文件尾:FFD9
ZIP 文件头:504B0304 文件尾:504B
实验步骤:
- 首先下载附件secret.png,以及破解色道隐写,需要JAVA环境的Stegsolve工具(常见的CTF工具都可从点击打开链接下载)
- 使用Stegsolve工具open加密图片,然后①选择Analyse-DataExtract
2. Bit Planes 选中Reg、Green、Blue的第0位
3. Bit Order选中LSBFirst
4. Bit Plane Order选中RGB
可以看到加密形式的payload - 在操作页面中,点击“〈“或”〉”,发现在红0通道内有二维码,扫二维码得
flag{least_significant_bitttt}

所遇疑惑:
1.问:此实验所用的图片名称为“secret.png”,但我因用手机下载再发送到电脑操作名称变为了"微信图片_20180214222809”,对后者进行如上操作,发现无二维码,并且所提取的数据也是不同的。同样的一幅图片,难道备注名会影响图片的数据组成吗?
答:一开始我是认为把备注名换了之后会直接影响图片的组成,至少我的实验结果是说明了这一点。我接着直接在电脑上改文件名称,发现改完后用Stegsolve分析的两个不同png文件名的同一副图提取出的数据是相同的,但是我再次尝试将手机下载传给电脑,所分析出来的数据又是不同的。最后我发现,我在发送的时候忘记点击发送原图。所以,中介在传播文件的时候,会压缩损失信息综上得:改变PNG文件的备注名称不影响图片的数据组成。
2.问:老师直接说出了此题的做法就是LSB,对我这种小白来说,怎么看出来是用LSB?如何从提取的数据信息来说分析是LSB?答:
体会:
完全的小白,从昨晚接到任务,需要,以前听过这一词,但从来没有尝试过,昨天捣鼓了好几个小时,也是仅仅局限于能用手机,这样才能从墙外看到oj的题,但是随之而来的问题,下载下来的文件我只能通过手机端下载下来再微信到电脑端,所以文件的名字就有差别,影响的实验的进行,直到现在。我用虚拟机,根据某同学的建议,在虚拟机里跑免费的梯子,虽然是直接用的脚本,没有任何动脑的地方,但是也算是在自己的电脑上了,至少不用担心下载下来的文件不是所需的实验材料了。尽管这样能获取一些知识,但对于无基础的我来说,这样未免效率不高,应该先在实验吧这种,或者b站看一些相关的视频,大体明白原理后,再去尝试动手。
加油!
Exif图片隐写题
知识查询准备:
- Exif就是在JPEG格式头部插入了数码照片的信息,包括拍摄时的光圈、快门、白平衡、ISO、焦距、日期时间等各种和拍摄条件以及相机品牌、型号、色彩编码、拍摄时录制的声音以及GPS全球定位系统数据、缩略图等。
18.2.16-CTF隐写题docx
知识查询准备:
对于docx文件的本质是什么?docx是Office2007使用的,是Microsoft Office Word 2007文档的扩展名,它用新的基于XML的压缩文件格式取代了其目前专有的默认文件格式,在传统的文件名扩展名后面添加了字母x(即.docx取代.doc、.xlsx取代.xls,等等)。.docx 格式的文件本质上是一个ZIP文件。将一个.docx文件的后缀改为ZIP后是可以用解压工具打开或是解压的。事实上,他可以算作是.docx文件的容器。.docx 格式文件的主要内容是保存为XML格式的,但文件并非直接保存于磁盘。它是保存在一个ZIP文件中,然后取扩展名为.docx。将.docx 格式的文件后缀改为ZIP后解压。可以看到解压出来的文件夹中有word这样一个文件夹,它包含了Word文档的大部分内容。而其中的document.xml文件则包含了文档的主要文本内容。
步骤:直接将docx后缀改为zip解压缩即可发现flag.xml文档,再用记事本打开得到Flag{k42bP8khgqMZpCON}(这应该是最简单的一道了。。。。)
所遇疑惑:
问1:解压出来的文件夹有_rels、theme,还包括很多.xml文件,这都有什么含义,为什么要这样存储?
答:其实里面的内容都是对word文档的表述,只不过分别写在不同的.xml文件中了,比如说我们可以看到在其中的document.xml文件则包含了文件文本内容和段落的设置。本docx文档中没有图片等其他信息,如果有的话会有一个media文件夹,里面会包含此类的信息
问2:docx和doc的区别,是不是都可以用这样的方式改为zip类型?
答:我进行了简单的测试分别将.docx和.doc两种文件的扩展名都修改成.zip的格式,并使用winrar打开,会发现.docx修改的可以打开,而.doc修改的提示错误"压缩文件格式未知或者数据已经被损害"
18.2.17-HTTP流量分析Forensics1
知识查询准备:
抓出来的数据报各个段表示什么?

Frame:物理层的数据帧概况
Ethernet II:数据链路层以太网帧头部信息。(帧↓)
Internet Protocol Version 4:互联网层IP包头部信息。(包↓)
Transmission Control Protocol:传输层的数据段头部信息。(段↓)
Hypertext Transfer Protocol:应用层的信息,此处是HTTP协议
步骤:
①直接用wireshark工具打开network.pcapng文件,根据要求关注http部分,直接用审查元素抓出来。得到如下

(思考:此时我本能就去找flag{}字符串,发现并没有,看到只有flags(在计网中学过的标记字段),我单个打开每一个包,然后我发现这段报文是在请求![]() 这个网址,我本能尝试打开,却未成功(关键不在于这个网址能不能打开,通信双方重要的是传输的内容),然后我开始研究报文,通过wireshark的实战详解pdf版先去了解这些英文字段到底表示什么含义,通过了解,无非是计网中的各个层次数据头+数据信息。而由应用层交付下来的数据肯定是一层一层的封装到下面。所以我们要得到flag必定是从最上面的http层次开始看,我门关注
这个网址,我本能尝试打开,却未成功(关键不在于这个网址能不能打开,通信双方重要的是传输的内容),然后我开始研究报文,通过wireshark的实战详解pdf版先去了解这些英文字段到底表示什么含义,通过了解,无非是计网中的各个层次数据头+数据信息。而由应用层交付下来的数据肯定是一层一层的封装到下面。所以我们要得到flag必定是从最上面的http层次开始看,我门关注![]() 字段,这是6次请求的过程,我一眼就看到了secret.png,想必flag一定是存在这里面。那么我们如何得到这个.png文件呢,接下来就是如何display png in wireshark pcap,我在点击打开链接此中查到所需。)
字段,这是6次请求的过程,我一眼就看到了secret.png,想必flag一定是存在这里面。那么我们如何得到这个.png文件呢,接下来就是如何display png in wireshark pcap,我在点击打开链接此中查到所需。)
②我们使用wireshark可以自动提取通过http传输的文件内容,方法:文件→导出对象→http,在打开的对象列表中找到有价值的文件,点击saveas,查看即可。


体会:通过这几次做题,我一个最大的误区是以为flag会直接获得,比如exif那道题,将jpg图片拖到exiftool中,我会本能的看有没有直接显示flag{}字样(这道还没做出来),这个题也是更让我确定,所谓的flag只是嵌入在别的媒介中的,比如二维码,png对象等,而我们所需要做的是如何一步步的将这些媒介找出来,然后提取出我们想要的flag{}.
18.2.18-HTTP流量分析 Forensics2(结合18.19期(在此期完成))
知识查询准备:
ICMP:网络控制协议,用于在IP主机、路由器之间传递控制消息,控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。我们经常使用的检查网络通不通的Ping命令,这个Ping过程实际上就是ICMP协议工作的过程,在此报文中,可明显有ping测试
![]()
ARP:地址解析协议,根据IP地址获取物理地址的一个,主机发送信息时将包含目标IP地址的ARP请求广播到网络上的所有主句,并接受返回消息,以此确定目标的物理地址。在此抓取的报文中,10.0.0.2询问10.0.0.22的物理地址。
![]()
TCP:这是一种面向连接的、可靠的、基于字节流的传输层通信协议,TCP层是位于IP层之上,应用层之下的中间层。不同的应用层之间经常需要可靠的,像管道一样的连接,但是IP层不提供这样的流机制,而是提供不可靠的包交换。
SSH:为建立在应用层基础上的安全协议。转为登录会话和其他网络服务提供安全性的协议,利用SSH协议可以有效防止远程管理过程中的信息泄露问题。例如ftp、telnet在本质上都是不安全的,因为它们在网络上用明文传送口令和数据,其他人非常容易就可以截获这些口令和数据,而且这种服务程序的安全验证方式也是有其弱点的,很容易受到中间人攻击,通过使用ssh,可以把所传输的数据进行加密,也能够防止DNS欺骗和IP欺骗。为数据传输提供一个安全通道
NFS:网络文件系统,它允许网络中的计算机之间通过TCP/IP网络共享资源,在NFS的应用中,本地NFS的客户端应用可以透明的读写位于远端NFS服务器上的文件,就像访问本地文件一样
Portmap:portmap进程的主要功能是把RPC(远程过程调用)程序号转化为Internet的端口号,当一个RPC服务器启动时,会选择一个空闲的端口号并在上面监听,同时它作为一个可用的服务会在portmap进程注册。但portmap只在第一次建立连接的时候起作用,帮助用裸应用程序找到正确的通讯端口,一旦双方正确连接,端口和应用就绑定,portmap也就不起作用了,在抓取的报文中确实只看到了一次交流
![]()
步骤:
①(思考:根据上个题,something about file,首先我想到的是肯定跟文件有关,所以我直接过滤了nfs协议,从info中可以直接看到关于flag的文档
![]()
![]()
我猜想,只要想办法把这个压缩包导出来就可以,我像上题那样直接文件导出,发现并没有NFS对象,索性都导出一遍,发现没有任何东西,我想到了从FTP中提取传输的文件:我们知道,客户端和服务器之间互相发送的数据,比如说客户端登录服务器user、切换目录cwd、监听目录list,我们关心的应该是监听目录和文件传输,而不是命令,所以应该需要显示非FTP命令的显示过滤器,并且将FTP的TCP stream关闭掉,捕获的文件中才不会出现有FTP命令的数据包,在删去这些非FTP命令的数据包后,右击任何数据帧,follow tcp stream会直接显示文件内容,此时直接save as相应的文件,打开即可。我尝试用此中方式进行操作,发现对任何的使用nfs的数据进行follow tcp都是得到的类似控制的协议,而传输文件的本身其实用的是TCP协议,而SSH对其加密,我就根据tcp握手规则,把可能的传输数据的流都找出来,再拿去编码,也没收获。。)
18.2.19-续Forensics2+生成字典,zip暴力破解
续18.2.18期
知识查询准备:
·ftp、tftp、nfs三种文件传输协议的区别:
ftp的基本应用就是将文件从一台计算机复制到另一台计算机中。它要存取一个文件,就必须先获得一个本地文件的副本,如果修改文件,也只能对文件的副本进行修改,然后再将修改后的文件副本传回到原节点。关键词:交互式、存取权限和副本。
tftp是小而易于实现的文件传送协议,tftp是基于UDP数据报,需要有自己的差错改正措施,TFTP只支持文件传输,不支持交互,TFTP和FTP的一个主要的区别就是它没有交互式,且不进行身份验证。
nfs允许应用进程打开一个远地文件,并能够在该文件中某一个特定位置上开始读写数据。(不需要或取文件,直接远程读写)
步骤:(思考:之前的思路中心就是如何解决在wireshark中提取传输的文件,其实这个思路是错的,我又明确了一下NFS协议的含义(实质是远程读写文件,而不需要获取文件),所以更正后的思路应该是从报文中找到对文件的读写操作,所以我查阅了TCP-IP详解的关于nfs协议的有关内容,发现

只有这两个命令是直接对文件操作,我们只要过滤出这两个字符串的位置,找到读写的Data,解码即可)
①过滤READ和WRITE字符串,发现只有WRITE,里面包含请求call和回复repley

②在call中看到Data数据,直接右击显示分组字节,解码为压缩即得flag



问题:
之前理解为ssh加密不应该把传输的内容加密,读写文件操作不应该在ssh协议中得到吗?
答:其实ssh是ssh,nfs是文件传输协议,好比一个事3389一个是ftp,也就是说ssh只是在使用ssh的端口对数据进行加密,而nfs是属于另一个端口,所以没有联系。
生成字典,zip暴力破解
知识查询准备:
字典生成: 我使用的是superdic字典生成工具,简单来说,就是根据用户的需要,比如说对密码位数的要求,特殊位的要求,字符等,利用程序高度优化算法,创建出适合自己需要的字典,从而为暴力破解来提供数据来源。
我使用的是superdic字典生成工具,简单来说,就是根据用户的需要,比如说对密码位数的要求,特殊位的要求,字符等,利用程序高度优化算法,创建出适合自己需要的字典,从而为暴力破解来提供数据来源。
暴力破解:此一般指穷举法,穷举法的基本思想是根据题目的部分条件确定答案的大致范围(也就是我们生成的字典),并在此范围内对所有可能的情况逐一验证,直到全部情况验证完毕。若某个情况验证符合其母的全部条件,则为本问题的一个解,若全部情况验证后都不符合题目的全部条件,则无解
步骤:
①首先生成字典。根据90后、生日密码、8位数字确定以下约束,以此生成superdic.dic文件
![]()



②使用ziperello软甲,使用字典破解,从而得出密码,进而打开文档获得flag


18.2.20-基于shell的流量分析题
知识查询准备:
· python语言的一些入门语法,以及swapcase()的意思是转换大小写。
· bash:是许多Linux发行版的默认shell
· base64:用于传输8bit字节码的编码方式之一,Base64是一种基于64个可打印字符来表示二进制数据的方法,Base64编码具有不可读性,需要解码后才能阅读,转码实质为每3个8bite用4个6bit来表示。
· URL编码:url编码是一种浏览器用来打包表单输入的格式。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。
步骤:
(思路:首先我们看到http协议,
![]()
打开分组后我们可以看到URL请求,进行URL解码
![]()

通过解码,我们了解到该报文的实质就是他在向webshell发命令,解码后发现他是将bash监听12345端口,然后我们只需要看12345端口干了什么事情就可以了。
)
①如思路,先找到HTTP协议,对URL解码,查询含有12345端口的数据流
②我们可以看到大面积的12345端口与53474端口的数据交互(下图),我们随便点一个,右击追踪TCP流。

③追踪TCP流后(下图),(思路:我们看到其实是用户一直在bash里发送命令,倒数第二条命令为cat flag.txt | base64 -w 0 | python -c "print raw_input().swapcase()"(实质为进行如下操作1.显示flag.txt内容 2.将内容进行base64编码 3.对用户输入的数据进行大小写转化,转化后的结果为zMXHz3TYzxzLCNnLx3nOzwWXBdfSBgWXBh0k),所以我们只需要将过程逆回去,大小写转化→base64解码即可得出flag的内容)

④将zMXHz3TYzxzLCNnLx3nOzwWXBdfSBgWXBh0k通过python转化大小写,并对结果进行base64解码得到flag


问题:既然bash也是shell,那shell、bash、console、zsh、terminal到底有什么关系?区别呢?
答:bash、ash、等都是shell,是脚本语言和命令执行环境,比如你在命令行里输入数据,接受你的输入并执行的就是shell,而console 等是控制台,说白了就是屏幕加键盘,屏幕当然既可以执行shell程序,又可以显示用户输入的信息,如果想用文本方式用键盘交互输入命令,就需要一个终端,同时在终端里运行一个shell,其实这个shell不是在终端内部运行,是在计算机上运行,我的理解来说console相当于GUI下的terminal,而shell是壳程序,shell其实就是一个解释器,它负责接受你的输入,通过与操作系统的交互,你在terminal下输入的指令就是被shell介绍的,shell是包裹在操作系统外的一道程序,是操作系统的壳。
18.2.21-Python学习
最近在学习的过程中,感觉到了自己linux知识不足,以及一些基础知识的不牢固,和python在开发web时的重要性,由此,结合黑马的python视频,学习和实践python语言,python学习主要以笔记和实践为主。
1.了解操作系统及作用:特殊的管理硬件的软件,操作系统将硬件的操作封装成系统调用,由应用程序、终端命令、图形窗口进行调用。
例如1.将歌曲文件从硬盘加载到内存,2,使用声卡对音频数据进行解码,3.将解码后的数据发送给音响
2.服务器操作系统:无键盘和鼠标,怎样维护?在远程通过终端,远程登服务器进行管理维护。
·Linux 安全、稳定、免费、占有率高
·windows Server 付费、占有率低
02.Linux内核(只有一个)及发行版(例如红帽等)
2.1Linux内核版本
·内核是系统的心脏,是运行程序和管理磁盘等硬件设备的核心成熟,提供了一个在裸设备与应用程序间的抽象层。
·Linux发行版,是在linux内核的基础上又包含各个公司所制作的包括桌面环境、办公套件、媒体播放器等应用软件的linux版本
常见发行版:Ubuntu、Redhat、(Linux只是一个操作系统内核而已,而GNU提供了大量的自由软件来丰富在其之上各种应用程序)
02.windows和Linux文件系统区别
·windows,一个个的驱动器盘符,每个驱动器都有自己的根目录结构.xp的前版本是单用户操作系统
·Linux下,我们是看不到盘符,而是文件夹(目录),只有一个根目录/,所有的文件都在它下面。多用户(在/Home下)
02 常用Linux命令的基本使用
02.常见Linux命令的基本使用
ls list 查看文件夹下的内容
pwd print wrok directory 查看当前文件下的内容
cd 【目录名 】 change directory 切换文件夹
touch【文件名】touch 如果文件不存在,新建文件
mkdir【目录名】 make directory 创建目录
rm【文件名】 remove 删除指定的文件名
clear clear 清屏
小技巧
·ctrl+shift+=放大终端窗口的字体显示
·ctrl+- 缩小终端窗口的字体显示
Linux 终端命令格式
command [-options] parameter
说明:[ ]代表可选 ①命令名 ②选项(可有可无) ③传输命令的参数
eg:mkdir 1 2 创建目录名为1和2的目录
rm -r 1 2可以删除目录名1和2目录
02.查阅终端命令的帮助信息
2.1 command --help 显示command命令的帮助信息
2.2 man command 查阅command命令的使用手册
·使用man的操作键:
空格键 显示手册的下一屏
Enter键 一次滚动手册页的一行
b 回滚一屏
f 前滚一屏
q 退出
/word 搜索字符串
文件和目录常用命令
· 查看目录内容 ls
· 切换目录 cd
· 创建和删除操作 touch rm mkdir
· 拷贝和移动文件 cp mv
· 查看文件内容 cat more grep
· 其他 echo 重定向>和>> 管道|
1.1终端小技巧
1)自动补全 tab键 (按两下 list 开头为你输入的全部)
2)曾经使用过的命令 ↑ ↓键 hint:想要退出选择按ctrl+c
1.2Linux下文件和目录的特点
· 以.开头的文件为隐藏文件,需要用 -a 参数才能显示
· .代表当前目录
· ..代表上一层目录
1.3 ls常用选项 (选项可以叠加,不分顺序 eg:ls-hla)
-a 显示指定目录下所有子目录及
-l 以列表方式显示文件的详细信息
-h 配合 -l 以人性化的方式显示文件大小
1.4 ls通配符的使用
* 代表任意个数个字符
? 代表任意一个字符,只能代表1个
[] 表示可以匹配字符组中的任一个
[abc] 匹配a、b、c中的任意一个
[a-f] 匹配a到f范围内的任意一个字符
02.切换目录
cd ~ 切换到当前用户的主目录(/home/hsu)
cd - 可以在最近两次工作目录之间来回切换
相对路径和绝对路径
· 相对路径在输入路径时,最前面不是/或者~,表示相对当前目录所在的目录位置
· 绝对路径在输入路径时,最前面是/或者~,表示从根目录/家目录开始的具体目录的位置
03.创建和删出操作
3.1 touch 创建文件或修改文件时间
3.2mkdir -p 可以地柜创建目录,新建目录额名称不能与当前目录中已有的目录或文件同名
18.2.22
学习内容及时间: Kali Linux安装及环境配置 1小时30分+
Python学习之linux基础 2小时30分+
kali Linux安装及配置
更换软件源指令:
Leafpad /etc/apt/sources.list
vim /etc/apt/sources.list
网上大流的就是中科大的软件源和阿里的软件源。我都试了试,我的kali用中科大的不会出错。这里我就用的中科大的源。
Open-vm-tools的安装
apt-get install open-vm-tools-desktop fuse
reboot
多任务终端terminator的安装
apt-get install terminator 安装
terminator 启动终端
右击该窗口,选择水平分割,分为上下两个子窗口
#中科大
deb http://mirrors.ustc.edu.cn/kali kali-rolling main non-free contrib deb-src http://mirrors.ustc.edu.cn/kali kali-rolling main non-free contrib
什么事软件源,为啥要更换?
不同版本的linux其更新补丁或安装软件都需要用到一个源(可以理解为服务器),就相当于要连接到某一个服务器,再进行更新或安装等相关操作。可以理解为软件仓库和源码仓库,相当于手机上的应用商店。
Python学习之Linux基础
04.拷贝和移动文件
tree[目录名] tree 以树状图列出文件目录结构
cp 源文件 目标文件 copy 复制文件或目录
mv 源文件 目标文件 move 移动文件或目录/文件或者目录重命名
4.1 tree 命令可以以树状图列出文件目录结构
-d 只显示目录
4.2 cp 命令的功能是将给出的文件或目录复制到另一个文件或目录中,相当于DOS下的copy命令
-f 已经存在的目标文件直接覆盖,不会提示
-i 覆盖文件前提示
-r 若给出的源文件是目录文件,则cp将递归复制该目录下的所有子目录和文件,目标文件必须为一个目录名
4.3 mv 命令可以用来移动文件或目录,也可以给文件或目录重命名
-i 覆盖文件前提示
05.查看文件内容
cat 文件名 concatenate 查看文件内容、创建文件内容、文件合并、追加文件内容等功能(文件内容少)
more 文件名 more 分屏显示文件内容(文件内容多。)
grep 搜索文本 文件名 grep 搜索文本文件内容
5.1 cat命令一次显示所有内容,适合内容较少的文本文件
-b 对非空输出行编号
-n 对输出的所有行编号
5.2 more命令适合查看内容较多的文本文件(空格键、Enter键、b、f、q 、/word)
5.3 grep 文本搜索工具
-n 显示匹配行及行数
-v 显示不包含匹配文本的所有行(反)
-i 忽略大小写
常见两种模式查找:
^a 行首,搜索以a开头的行
ke$ 行尾,搜索以ke结束的行
06.其他
6.1 echo 文字内容 echo 会在终端显示参数指定的文字,通常和重定向联合使用
6.2 重定向>和>>
Linux允许将命令执行结果重定向到一个文件
其中: >表示输出,会覆盖原有的内容
>>表示追加,内容追加到已有文件的末尾
6.3 管道 |
Linux允许将一个命令的输出可以通过管道作为另一个命令的输入
常用的管道命令: more 分屏显示内容
grep 在命令执行结果的基础上查询指定的文本
6.4 ifconfig 可以查看/配置计算机当前的网卡配置信息
ifconfig | grep inet 查看网卡对应的IP地址
03.远程登录和复制文件
3.1 SSH基础(重点)
SSH是非常常用的工具,通过SSH客户端我们可以连接到运行了SSH服务的远程机器上,SSH客户端是一种使用SSH协议连接到远程计算机的软件程序,为远程登录会话和其他网络服务提供安全性的协议。通过SSH,数据加密,并且压缩,可以防止信息泄露和提高传输速度。
SSH服务器默认端口号为22
2)SSH客户端的简单使用
ssh [-p port] user@remote 其中user是远程机器上的用户名,remote是远程机器的地址(IP/域名),port
是SSH Server监听的端口,不指定就默认22
提示:ssh这个终端命令只能在Linux或者unix系统下使用(已内嵌里面了)
如果在win系统,可以安装PuTTY或者XShell客户端软件,exit退出当前用户的登录
准备工作:
确认Ubuntu中安装并启动了ssh,方法如下:
sudo apt-get install openssh-server
如果没安装过ssh,那么就会安装,如果提示已经安装过了,那就接着执行:
ps -e |grep ssh
如果只有ssh-agent那ssh-server还没有启动,需要/etc/init.d/ssh start,如果看到sshd那说明ssh-server已经启动了。
具体操作可参照点击打开链接
3.2 scp (secure copy,在linux下用来进行远程拷贝文件的命令)
·他的地址格式与ssh基本相同,但是在指定端口时用的是大写的 -P 而不是小写的
eg:把本地当前目录下的 01.py 文件 复制到 远程 家目录下的 Desktop/01.py(‘:’后面的路径为以用户家目录作为参照路径)
scp -P 22 port 01.py user@remote:Desktop/01.py
eg : 把当前目录下的 demo 文件夹 复制到 远程 家目录下的Desktop(加上 -r 选项可以传送文件夹)
scp -r demo user@remote:Desktop
提示:scp这个终端命令只能在linux或者unix系统下使用
如果在win系统中,可以安装putty,使用pscp命令行工具或者安装FileZilla使用FTP进行文件传输(注意:FileZilla传输文件时,使用的是FTP服务,不是SSH服务,因此端口号应该设置为21)
3.3 SSH高级
提示:有关SSH配置信息都保存在用户家目录下的.ssh目录下
1)免密码登录
步骤:
①配置公钥:执行 ssh-keygen 即可生成SSH钥匙,一路回车即可
②上传公钥到服务器:执行 ssh-copy-id -p port user@remote,可以让远程服务器记住我们的公钥
(原理:通过执行ssh-keygen,在ssh客户端生成id_rsa.pub公钥和id_rsa私钥。本地使用私钥对数据进行加密/解密 服务器使用公钥对数据进行加密/解密)
2)配置别名
每次都输入 ssh -p port user@remote,时间长了会麻烦,如果用ssh hsu 来代替上面一长串,那么就在~/.ssh/config 里面追加一下内容
Host mac
HostName ip地址
User 名
Port 22保存之后,即可用 ssh hsu实现远程登录,scp同样可以使用
18.2.22
学习内容及时间: 乌班图安装及所需部分软件安装 1小时30分+
Python学习 2小时30分+
03.打包压缩
在不同操作系统中,常用的打包压缩方式是不同的,windows常用rar,Mac常用zip,linux常用tar.gz
3.1打包/解包
· tar 是Linux中最常用的备份工具,此命令可以把一系列文件打包到一个大文件中、也可以把一个打包的大文件恢复成一系列的文件(tar只负责打包不负责压缩)
· tar的命令格式如下:
#打包文件
tar -cvf 打包文件.tar 被打包的文件/路径..
#解包文件
tar -xvf 打包文件.tar· tar选项说明
c 生成档案文件,创建打包文件
x 解开档案文件
v 列出归档解档的详细过程,显示进度
f 指定档案文件名称,f后面一定是 .tar 文件,所以必须放选项后面
3.2压缩/解压缩
1)gzip
tar 与 gzip 命令结合可以使用实现文件 打包和压缩
tar只负责打包文件,但不压缩
用 gzip 压缩 tar 打包后的文件,其扩展名一般用 xxx.tar.gz(Linux中常用)
在 tar 命令中有一个选项 -z 可以调用 gzip,从而可以方便的实现压缩和解压缩的功能
命令格式如下:
#压缩文件
tar -zcvf 打包文件.tar.gz 被压缩文件/路径..
#解压缩文件
tar -zxvf 打包文件.tar.gz
#解压缩文件到指定路径
tar -zxvf 打包文件.tar.gz -C 目标路径选项 -C 解压缩到指定目录(要解压缩的目录必须存在)
2)bzip2
tar 与 bzip2 命令结合可以实现文件 打包和压缩 (用法和gzip一样)
tar 只负责打包文件,但不压缩
用 bzip2 压缩 tar 打包后的文件,其扩展名一般用 xxx.tar.bz2
在 tar 命令中有一个选项 -j 可以调用 bzip2,从而更方便的实现压缩和解压缩的功能
命令格式如下:
#压缩文件
tar -jcvf 打包文件.tar.bz2 被压缩的文件/路径
#解压缩文件
tar -jxvf 打包文件.tar.bz204.软件安装
4.1通过apt安装/卸载软件
· apt 是 Advanced Packaging Tool,是Linux下的一款安装包管理工具,可以在终端中安装/卸载/更新软件包
# 1. 安装软件
$ sudo apt install 软件包
# 2. 卸载软件
$ sudo apt remove 软件名
# 3. 更新已安装的包
$ sudo apt upgradesudo是以root权限来执行系统管理工作
4.2配置软件源
在unbuntu中安装软件更加快速,可以通过设置镜像源,选择一个网速访问更快的服务器,来提供软件下载/安装服务
· 所谓镜像源就是所有服务器的内容是相同的(镜像),但根据所在位置的不同,国内的服务器通常速度回更快一些。
1.1 解释器
计算机不能直接理解任何除机器语言以外的语言,所以必须要把程序员所写的程序语言翻译成机器语言,计算机才能执行程序。将其他语言翻译成机器语言的工具,被称为编译器。
编译器翻译的方式有两种:一种是编译,一种是解释。两种方式之间的区别在于翻译时间点的不同。当编译器以解释方式运行的时候,也成为解释器。(编译型语言就是程序员在工作环境下编写源代码,交给编译器编译生成可执行文件,当用户需要的时候,在win下双击打开即可,像c++这种。而解释型语言翻译一行,执行一行。(速度慢,跨平台性强))
(在此我特意做了一个实验验证python是解释型语言,翻译一行,执行一行
正常情况下:


我们将第一个改成错的:会发现后面的也无法打印


我们将第三个改成错的:会看到前两次打印成功

 )
)
第一个Python程序
Python特点
Python是完全面相对象的语言。函数、模块、数字、字符串都是对象,在Python中一切皆对象
Python拥有一个强大的标注库,Python语言的核心只包含数字、字符串、列表、字典、文件等常见类型和函数
Python社区提供了大量的第三方模块,使用方式与标准库类似。它们的功能覆盖科学计算、人工智能、机器学习、web开发、数据库接口、图形系统多个领域
1.1Python源程序就是一个特殊格式的文本文件(因此可以使用任意文本编辑软件做Python开发),文件扩展名以-py结尾。
03.执行Python 程序的三种方式
3.1 解释器 python / python3
# 使用 python 2.x 解释器
$ python xxx.py
# 使用python 3.x 解释器
$ python3 xxx.pypython 的解释器如今又多个语言的实现,包括:
· CPython --官方版本的C语言实现
· Jython --可以运行在Java平台
· IronPython --可以运行在 .NET和Mono平台
· PyPy --Python实现的,支持JJT即时编译
3.2 交互式运行Python程序
·直接在终端运行解释器,而不输入要执行的文件名
·在Python的shell中直接输入Python的代码,会立即看到程序执行结果
1)交互式运行Python的优缺点:适合学习/验证 Python语法或局部代码,但代码不能保存,不适合运行太大的程序
2)退出官方的解释器:直接输入exit(),或者使用热键ctrl+d可以退出解释器
3)IPython(其中i代表interactive)
· IPython支持自动补全、自动缩进、支持bash shell命令、内置了许多很有用的功能和函数,是基于BSD开源的,退出方式和官方的解释器退出方式一样(只不过IPython中,按ctrl+d,IPython会询问y/n)
3.3 Python 的 IDE —Pycharm
IDE即为集成开发环境,一般包括以下工具:图形用户界面、代码编辑器、编译器/解释器、调试器等
05.PyCharm的升级及其他
5.1安装和启动步骤(网上搜即可)
· 注意:要把解压缩后的目录移动到/opt目录下,方便其他用户使用
(/opt目录用户存放给主机额外安装的软件)
(在安装过程中,启动 pycharm还要进到目录里点击 ./pycharm.sh(.sh是linux系统中的脚本文件),那么如何设置启动图标?
) 5.3卸载之前版本的PyCharm
1)程序安装
· 1. 程序文件目录
将安装包解压缩,并且移动到/opt 目录下
所有的相关文件都保存在解压缩的目录中
· 2 配置文件目录
启动pycharm后,会在用户家目录下建立一个 .PyCharmxx的隐藏目录
保存pycharm相关的配置信息
·3 快捷方式文件
在ubuntu中,应用程序启动的快捷方式通常保存在 /user/share/applications目录下
2)程序卸载
对比安装。我们需要删除解压缩目录 $sudo rm -r /opt/pycharm-2017.3/
和删除家目录下用于保存配置信息的隐藏目录 $rm -r ~/.Pycharm2017.3/
(如果需要删除图标的话,将/user/share/applications 下的jetbrains-pycharm.desktop删掉)
(对比windows下的软件安装和卸载应该说是非常简单,双击,或者安装安全软件,强力卸载,但是删不删的干净我们不知道,但在Linux中,我们程序的安装包是从官方下载的,我们程序安装包和安装到哪个目录及配置文件都会操作者都会一清二楚,哪个目录什么作用操作者都知道,所以linux很少有病毒)
18.2.24
学习内容及时间: SQL注入:2小时+
Python:1小时+
注入攻击:注入攻击的本质,是吧用户输入的数据当做代码执行,有两个关键条件,第一个是用户能够控制输入,第二个是原本程序要执行的代码,拼接了用户输入的数据
Payload是什么? 英文直译是有效载荷的意思。payload就是在一个数据包或者其它传输单元中运载的基本必要数据。有效载荷不包括使得数据包到达目的地所要求的“管理的”数据 。记录那些构成有效载荷的东西依赖的观点。通信层需要一些管理数据进行这个工作,有时有效载荷认为包括了这个层处理中的管理数据部分。然而,在多数的应用中,有效载荷是那些传送到目的地终端用户手上的“位”。
SQL注入:例如:
var sql = "select * from OrdersTable where temp='"+temp+"'"
用户如果输入正常的量,比如 aaaa。那么就会执行
select * from OrdersTable where temp='aaaa'但是如果用户输入一段有意义的sql语句,比如说
aaaa'; drop table OrderTable--那么就会执行
select * from OrdersTable where temp='aaaa';drop table OrderTable--'可以看到在查询完之后还会执行一个drop表的操作,这里注入攻击有两个条件:用户能够控制数据的输入,即变量temp,而原本要执行的代码,拼接了用户的输入,正式这个拼接过程导致了代码的注入。
盲注:
有时候我们在SQL注入的过程中,如果网站的Web服务器开启了错误回显,错误回显披露了敏感信息,则会为攻击者提供极大的便利,构造sql注入就可以更加得心应手,但很多时候,Web服务器关闭了错误回显,“盲注”就是为了应对这种情况,所谓盲注就是在服务器没有错误回显时完成的注入攻击。服务器没有错误回显,对攻击者来说缺少了非常重要的“调试信息”,所以攻击者必须找到一个方法来验证注入的SQL语句是否得到执行,最常见的盲注验证方法是,构造简单的条件语句,根据返回页面是否发生变化 ,来判断SQL语句是否得到执行。
例如,一个应用的URL是
http://newspaper.com/items.php?id=2执行的sql语句为:
SELECT title,description,body FROM items WHERE ID=2如果攻击者构造如下的条件语句:
http://newspaper.com/items.php?id=2 and 1=2
我们可以知道 and 1=2 永远是一个假命题,对web应用来说也不会将结果返回给用户,但是攻击者在此验证这个过程,构造条件 and 1=1时,如果页面正常返回,则说明sql语句成功执行,所以id参数存在sql注入的漏洞
Python 学习
注释规范:
如何注释是单独一行,#后面要加一个空格,如果注释跟注释同一行,且跟在代码后面,代码和#中间要有两个空格。
块注释:(一对连续的三个引号 “ ””)
"""
多行注释的内容
内容
"""算数运算符:
/ 除 10/20=0.5
// 取整除 9//2结果4
** 幂 2**3为8 ( * 运算符还可以用于字符串,计算结果就是字符串的指定次数的结果)
"-" * 10
"----------"Python 程序的执行原理
1.操作系统会首先让CPU把Python解释器的程序复制到内存中
2.Python解释器根据语法规则,从上到下让CPU翻译Python程序中的代码
3.CPU负责执行翻译完成的代码
Python 的解释器有多大?
# 确认解释器的所在的位置
$ which python
# 查看 python 文件大小(只是一个软连接)
$ ls -lh /usr/bin/python
# 查看具体文件大小
$ ls -lh /usr/bin/python2.7
18.2.25
学习时间及内容:
Python 2小时+
在 iPython中的变量演练:
变量定义
在Python中,每个变量在使用时必须赋值,变量赋值治好后该变量才会被创建,用 = 给变量赋值
变量名 = 值
输出的时候,应为Python是交互式,所以直接 命令输入变量名,回车即可,不需要使用print
在PyCharm中的变量演练
qq="123"
pring(qq)使用解释器执行,如果要输出变量的内容,必须要使用print函数。
程序执行完后,开始为变量分配的空间就全被释放掉了。
变量的类型
在Python中,定义变量时是不需要指定变量的类型的,在运行的时候,Python解释器,会根据赋值语句等号右边的数据自行推倒出变量中保存数据的准确类型。
s = 'Hello World'
print s # 输出完整字符串
print s[2:5] #第三个到第五个
print s[:5] #从开始到第五个
print s[2:] #从第三个到最后分析可得[a:b]类型中,a为角标,而b给整个字符串的第几个
列表:
类似于C++或Java语言中的数组,一个有序可变集合的容器。支持内置的基础结构甚至是列表,列表是可以嵌套的。不同的数据结构也可以放在同一个列表中,没有统一类型的限制
实验:
 输出:
输出:
(自己忽略了列表中嵌套的列表是作为一个整体的,而不是分开的)
元组:(元组的两端改为小括号而不是中括号)
可以视为不可变的列表,在赋值之后就不能二次更改了。
字典:类似于C++语言中的map,key—value键值对的结构,无序的容器。字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割(最后的键值对后不用加,),整个字典包括在花括号({})中 。
注:键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
实验:我们运行后发现SyntaxError: Non-ASCII character '\xe5' in file错误。原因是Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文,此时即使你把自己编写的Python源文件以UTF-8格式保存了;但实际上,这依然是不行的。
解决方法:在源码的第一行添加以下语句:(注:此语句一定要添加在源代码的第一行)
# -*- coding: UTF-8 -*-
或者
#coding=utf-8
 ,结果
,结果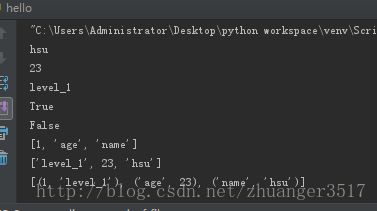
修改字典:向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
 ,输出结果
,输出结果
删除字典元素:
能删单一的元素也能清空字典,清空只需一项操作。删除一个字典用del命令,如下实例:
字典键的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住

2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,
 ,结果
,结果![]()
18.2.26
学习内容及时间:
pwn入门视频 1.5小时+
Python学习 1.5小时+
pwn入门
1.简单介绍:
1.1pwn是什么
1.2怎样分析一个程序
2.环境:
1.1unbuntu 64bit
1.2pwntools
1.3pwndbg
1.4ida
1.5gcc-multilib
1.C函数对应的汇编:
2.IDA的常用功能
1 f5 defs.h
2 shift f12 字符串
3 r重命名
4 x引用
3. pwntools常用功能
1.process remote:
2.p64,u64
3.context.binary 一般用于asm功能
Python条件语句:
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件:
执行语句……
else:
执行语句……实验:
 ,结果输出
,结果输出![]()
(与c++区别:Python中的 False和True首字母必须要大写,并且在if 语句和else语句后面要有冒号,由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。)
Python循环语句:
Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。其基本形式为:
while 判断条件:
执行语句.....实验:
 ,结果输出
,结果输出
(一开始我直接把循环语句的 print 'The count is:',count中的逗号写成了“+”,这样是不可以的,“+”连接字符串,也就是同种类型的数据)
while 语句时还有另外两个重要的命令 continue,break 来跳过循环,continue 用于跳过该次循环,break 则是用于退出循环,此外"判断条件"还可以是个常值,表示循环必定成立,
Python for 循环语句:
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。语法格式如下:
for iterating_var in sequence:
statements(s)实验:
 ,结果输出
,结果输出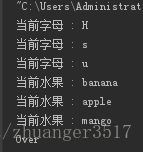
此实验还可以通过序列索引迭代:
 ,结果输出
,结果输出
(在上面中 内置函数len()是返回列表的长度,即元素的个数,range()是返回一个序列的数)
Python 循环嵌套
Python for 循环嵌套语法:
for iterating_var in sequence:
for iterating_var in sequence:
statements(s)
statements(s)Python while 循环嵌套语法:
while expression:
while expression:
statement(s)
statement(s)实验:使用嵌套循环输出2~10之间的素数:
 ,结果输出
,结果输出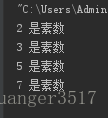
(素数是什么?一个大于1的自然数,出了1和它自身外,不能被其他的自然数整除的数叫做质数,又称素数)
循环控制语句:
break 语句: 在语句块执行过程中终止循环,并且跳出整个循环
continue 语句: 在语句块执行过程中终止当前循环,跳出该次循环,执行下一次循环。
pass 语句: pass是空语句,是为了保持程序结构的完整性。
18.2.27
学习内容及时间:
Python学习 2小时+
函数基础:
· 所谓函数,就是把具有独立功能的代码块组成为一个小模块,在需要的时候调用。
· 函数的使用包含两个步骤:
1.定义函数--封装独立的功能
2.调用函数--享受封装的成果
· 函数的作用,开发程序时,使用函数可以提高编写的效率以及代码的重用。
· 函数的定义用 def。import后使用 工具包 . 工具 来调用工具包里的工具
导入并调用过程如下:
import 01_a
01_a.multiple()2.1函数的定义:
def 函数名():
函数封装的代码
......1.函数名称要能够表达函数封装代码的功能
2.函数名称的命名应该符合标识符的命名规则
· 可以由字母、下划线和数字组成
· 不能以数字开头
· 不能与关键字重名
3.函数封装的代码要以def为参照缩进4个空格。
4.定义好函数之后,只表示这个函数封装了一段代码而已,如果不主动调用函数,函数是不会主动执行的(验证:在函数的中间设置断点后,执行下一步,会发现程序不会再断点处停)
2.2函数调用
调用函数通过 函数名() 即可完成对函数的调用
思考:能否在定义函数前调用函数? -----不能
2.4PyCharm的调试工具
· Step Over可以单步执行代码,会把函数调用看作是一行代码执行
· Step Into可以单步执行代码,如果是函数,会进入函数内部
2.5函数的文档注释
在定义函数的下方,使用连续的三对引号,在之间编写对函数的文字说明,在函数调用位置,使用快捷键 CTRL+Q 可以查看函数的说明信息
注意:因为函数体相对独立,函数定义的上方,应该和其他代码(包括注释)保留两个空行

03.函数的参数
小括号内部填写参数,多个参数之间使用 , 分割
04.函数的返回值
· 在函数中使用 return 关键字可以返回结果
· 调用函数一方,可以使用变量来接受函数的返回结果
def sum_2_num(num1,num2):
return num1+num2
#调用函数,并使用 result 变量接收计算结果
result = sum_2_num(10,20)
print(result)注意:return表示返回,后续的代码都不会被执行。(写完return后,按回车,光标会顶头。)
05.函数的嵌套调用
实验:打印多条分割线:
def print_line(char,times):
print(char *times)
def print_lines(char,times):
row=0
while row<5:
print_line(char,times)
row +=1
print_lines("-",20);06.使用模块中的函数
模块是Python程序架构的一个核心概念
模块就好比是工具包,要想使用,就必须要import这个模块,每一个以扩展名py结尾的Python源代码文件都是一个模块,在模块中定义的全局变量、函数都是模块能够提供给外界直接使用的工具。
18.2.28
学习内容及时间:
Python学习:2小时+
06.使用模块中的函数
模块是Python程序架构的一个核心概念
模块就好比是工具包,要想使用,就必须要import这个模块,每一个以扩展名py结尾的Python源代码文件都是一个模块,在模块中定义的全局变量、函数都是模块能够提供给外界直接使用的工具。
可以在Python文件中定义变量或者函数,然后再另外一个文件中使用import导入这个模块,导入之后,就可以使用 模块名.变量/模块名.函数的方式,使用这个模块中定义的变量或者函数
6.2模块名也是一个标识符
· 标识符可以由字母、下划线和数字组成
· 不能以数字开头
· 不能与关键词重名
注意:如果在给Python文件起名时,以数字开头是无法在Pycharm中导入到这个模块的
高级变量类型:
准备:Python中数据类型可以分为 数字型 和 非数字型
数字型:
·整形(int)
·浮点型(float)
·布尔型(bool)
·复数型(complex):主要用于科学计算
非数字型:
·字符串
·列表
·元组
·字典
在Python中,所有 非数字型变量 都支持以下特点:
1. 都是一个序列 sequence,也可以理解为容器
2. 取值[]
3. 遍历 for in
4. 计算长度、最大/最小值、比较、删除
5. 链接 + 和 重复 *
6. 切片
01.列表
在其他语言中叫数组,用来存储一串信息,数据之间用逗号分隔。索引从 0 开始,从列表中取值是,如果超出索引范围,程序会报错。
1.2 列表常用操作
· 在 ipython3 中定义一个 列表,例如name_list = []
· 输入 name_list. 按下Tab键, IPython会提示列表能够使用的方法:

实验:
#!/usr/bin/python
# -*- coding: utf-8 -*-
name_list = ["zhangsan","lisi","wangwu"]
# 取值取索,不能超范围
print(name_list[2])
#知道数据的内容,取出索引
#使用index,如果传递的数据不再列表中,程序会报错
print(name_list.index("lisi"))
#修改,列表指定的索引超出范围会出错
name_list[1]="lal"
#增加数据
name_list.append("xiaoer")#append 向列表末尾追加数据
name_list.insert(1,"wj")#在列表指定索引插入数据
temp_list = ["1","2","3"]
#extend把另一个列表的完整内容追加到当前列表末尾
name_list.extend(temp_list)
#删除指定数据
name_list.remove("2") #如果有重复,只会删除第一个,点击ctrl+q即可看到方法说明
name_list.pop()#pop方法默认把列表最后一个元素删除
name_list.pop(1) #pop方法可以指定删除元素的索引
print(name_list)备注:使用 del 关键字也可以删除列表元素
name_list = ["zhangsan","lisi","wangwu"]
del name_list[1]
#del 关键字本质上是将一个变量从内存中删除
print(name_list) 统计:
count 方法可以统计列表中某一个数据出现的次数
排序:
列表.sort() 升序排序
列表.sort(reverse=True) 降序排序
列表.reverse (逆序、反转)
关键字、函数和方法
· 关键字是Python内置的、具有特殊意义的标识符,关键字后面不需要使用括号
查看python中的关键字可以使用如下方法,总共有33个
import keyword
print(keyword.kwlist) · 函数封装了独立功能,可以直接调用 函数名(参数)
· 函数需要死记硬背,方法和函数类似,同样是封装了独立的功能,方法需要通过对象来调用,表示针对这个对象要做的操作。
1.3 循环遍历
· 在 Python 中为了提高列表的遍历效率,专门提供了 迭代 iteration遍历
· 使用 for 就能够实现迭代遍历
name_list = ["zhangsan","lisi","wangwu"]
#使用迭代遍历列表
"""
顺序的从列表中依次获取数据,每一次循环过程总,数据都会保存在my_name
这个变量中,在循环体内部可以访问到当前这一次获取到的数据
for my_name in 列表变量:
print("我的名字叫 %s" % my_name)
"""
for my_name in name_list:
print("我的名字叫 %s" % my_name)18.3.1
学习内容及时间:
Python学习 : 2小时+
02.元组
2.1元组的定义
Tuple(元组)与列表类似,不同之处在于元组的元组不能修改
· 元组表示多个元素组成的序列
· 元组用()定义
· 元组中通常保存不同类型的数据
· 元组中只包含一个元素时,需要在元素后面添加逗号,使用type()函数可以查看类型,不加逗号不是元组
info_tuple = ("zhangsan",18,1.75)
2.2元组常用操作
定义空元祖,
info = ()然后输入 info. 可以看到python语言提供 info.count和info.index操作
实验:
info_tuple = ("zhangsan",18,175)
#取值和取索引
print(info_tuple[0])
#已知数据内容,希望知道该数据在元组中的索引
print(info_tuple.index("zhangsan"))
#统计计数
print(info_tuple.count("zhangsan"))
#统计元祖中包含元素的个数
print(len(info_tuple)) 输出:
2.3 循环遍历
· 在Python中,可以使用 for 循环遍历所有非数字型类型的变量:列表、元组、字典以及字符串
实验: ,输出:
,输出:
2.4 应用场景
· 函数的参数和返回值,一个函数可以接受任意多个参数,或者一次返回多个数据
· 格式化字符串,格式化字符串后面的()本质上就是一个元组
· 让列表不可以被修改,以保护数据的安全
实验:
 ,输出
,输出
元组和列表之间的转换
· 使用 list 函数可以把元组转化成列表
list(元组) · 使用tuple函数可以把列表转化成元组
tuple(列表)03.字典
· 通常用于存储描述一个物体的相关信息(类似于c++中结构体)
和列表的区别
· 列表是有序的对象集合
· 字典是无序的对象集合
· 字典用 { } 定义
· 字典使用 键值对 存储数据,键值对之间使用 , 分割
· 键 key 是索引
· 键 value 是数据
· 键和值之间用 : 分隔
· 键必须是惟一的
· 值 可以取任何数据类型,但 键 只能使用字符串、数字或元组
xiaoming = {
"name":"xiaoming",
"age":18,
"gender":True,
"height":1.75
}备注:字典无序,使用print函数输出一个字典时,通常输出的顺序和定义的顺序是不一致的。
实验:
xiaoming = {
"name":"xiaoming",
}
# 1.取值
print(xiaoming["name"])
#在取值的时候,如果指定的key不存在,程序会报错
print(xiaoming["name"])
# 2. 增加/修改
#如果key不存在,会增加新增键值对
xiaoming["age"] = 18
#如果key存在,会修改已经存在的键值对
xiaoming["name"] = "xiao"
print(xiaoming)
# 3. del,删除指定key不存在,报错
xiaoming.pop("name")
print(xiaoming)
3.2字典的常用操作
在ipython下,输入自己定义的字典. 按下tab键,会提示字典能够使用的函数
实验:
xiaoming = {
"name":"xiaoming",
"age":18
}
#统计键值对数量
print(len(xiaoming))
#合并字典,如果被合并的字典中包含已经存在的键值对,则会覆盖原有的键值对
temp_dict={"height":1.75,
"age":20}
xiaoming.update(temp_dict)
print(xiaoming)
#清空字典
xiaoming.clear()
print(xiaoming)3.3 循环遍历
· 遍历 就是 依次 从 字典 中获取所有键值对
xiaoming = {
"name":"xiaoming",
"qq":"123",
"phont":"10086"
}
#迭代遍历字典
#变量K是每一次循环中,获取到的键值对的key
for k in xiaoming:
print("%s - %s" %(k,xiaoming[k]))3.4 应用
· 使用多个键值对,存储描述一个物体的相关信息
· 将多个字典放在一个列表中,再进行遍历,在循环体内部针对每一个字典进行相同的处理
实验:
card_list = [
{
"name":"zhangsan",
"qq":"123",
"phone":"110"
},
{
"name":"lisi",
"qq":"456",
"phone":"220"
}
]
for card_info in card_list:
print(card_info)输出:

18.3.2
学习内容及时间:
Python学习 2小时+
4.1字符串的定义
在Python中,可以使用 一对双引号“”,或者一对单引号 ‘’定义一个字符串,但大多数编程语言都是用双引号“”定义字符串。
· 如果字符串内部需要使用 双引号“”,可以使用 ‘’定义字符串
· 如果字符串内部需要使用 单引号 ‘’,可以使用 “”定义字符串
· 可以使用 for 循环遍历字符串中的每一个字符
实验:
str1 = "hello python"
for char in str2:
print(char)4.2字符串的常用操作
使用IPython,定义一个空字符串,输入字符串. 后会发现 python中支持的字符串操作。
len(字符串) 获取字符串的长度
字符串.count(字符串) 小字符串在大字符串中出现的次数
字符串.index(字符串) 获得小字符串第一次出现的索引
实验:
hello_str = "hello hello"
# 1.统计字符串长度
print(len(hello_str))
# 2.统计某一个子字符串出现的次数
print(hello_str.count("llo"))
print(hello_str.count("abc"))
# 3.某一个子字符串出现的位置
print(hello_str.index("llo"))
#如果使用index方法传递的子字符串不存在,程序会报错
print(hello_str.index("abc"))实验:string.isspace()如果string中只包含空格,则返回 True
(其实这里的空格不仅仅是空格,指的是空白字符,见下例,输出的仍旧是 true,可以验证这一结论)
space_str = " \t\n\r"
print(space_str.isspace())判断数字的三个方法:
string.isdecimal() 如果string只包含数字则返回True,全角数字
string.isdigit() 如果string只包含数字则返回True,全角数字、(1)(unicode 字符串)、/u00b2(平方)
string.isnumeric() 如果string只包含数字则返回True,全角数字、汉字数字
· 注意:但三个方法都不能判断小数
字符串的查找和替换方法:
string.startwith(str) 字符串若以str开头,则返回True
string.endswith(str) 字符串若以str结束,则返回True
string.find(str,start=0,end=len(string)) 检查str是否包含在string中,如果start和end指定范围,则检查是否包含在指定范围内,如果是则返回开始的索引值,否则返回-1
string.replace(old_str,new_str,num=string.count(old)) 把string中的old_str替换成new_str,如果num指定,则替换不超过num次
实验:
# 1.判断是否以指定字符串开始
print(hello_str.startswith("hello"))
# 2.判断是否以指定字符串结尾
print(hello_str.endswith("world"))
# 3.查找指定字符串
# index同样可以查找指定字符串在大字符串中的索引
print(hello_str.find("llo"))
# index如果指定的字符串不存在,会报错
# find如果指定的字符串不存在,返回-1
print(hello_str.find("abc"))
# 4. 替换字符串
# replace方法执行完成之后,会返回一个新的字符串
# 注意: 不会修改原有字符串的数据
print(hello_str.replace("world","python"))
print(hello_str)结果输出:True True 2 -1 hello python hello world
文本对齐:
string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度width的新字符串
string.rjust(width) .....右对齐.....
string.center(width) ......居中......
去除空白字符:
string.lstrip() 截掉string左边(开始)的空白字符
string.rstrip() 截掉string右边(末尾)的空白字符
string.strip() 截掉string左右两边的空白字符
拆分和连接
string.split(str="",num) 以str为分隔符拆分string,如果num有指定值,则仅分割 num +1个子字符串,str默认包含‘\r’,'\n','\t'和空格
string.join(seq) 以string作为分割符,将seq中所有的元素(的字符串表示)合并为一个新的字符串
字符串的切片:
切片 方法适用于 字符串、列表、元组
· 切片使用索引值来限定范围,从一个大的字符串中切出小的字符串。
· 列表 和 元组都是有序的几何,都能够通过索引值获取到对应的数据
· 字典是一个无需的几何,是使用键值对来保存数据
字符串[开始索引:结束索引:步长]备注:截取到的字符串是不包括结束索引的内容的。
实验:
num_str = "0123456789"
#截取从 2-5 位置的字符串
num_str[2:6]
#截取从 2-末尾的字符串
num_str[2:]
#截取从开始-5 位置的字符串
num_str[0:6]
num_str[:6]
#截取完整的字符串
num_str[:]
#从开始位置,每隔一个字符截取字符串
num_str[::2]
#从索引 1 开始,每隔一个取一个
num_str[1::2]
#截取从 2-末尾 -1 的字符串
num_str[2:-1]
#截取字符串末尾的两个字符
num_str[-2:]
#字符串的逆序
num_str[-1::-1]18.3.3
学习内容及时间 : Python学习 2小时+
05.公共方法(列表、元组、字符串都能使用)
5.1 Python 内置函数
len(item) 计算容器中元素个数
del(item) 删除变量 del有两种方式(加不加括号都可以)
max(item) 返回容器中元素最大值 如果是字典,只针对key比较
min(item) 返回容器中元素最小值 如果是字典,只针对key比较
cmp(item1,item2) 比较两个值,-1 小于0/0 相等/1 大于 字典不能比较大小
5.2 切片
· 切片使用 索引值 来限定范围,从一个大的字符串中切出小的字符串。
· 列表和元组都是有序的集合,都能够通过索引值获取到对应的数据。
· 字典 是无序的集合,是使用键值对保存数据,不能切片
5.3 运算符
+ 合并 字符串、列表、元组
* 重复 字符串、列表、元组
in 元素是否存在 字符串、列表、元组、字典
not in 元素是否不存在 字符串、列表、元组、字典
> >= == <= < 元素比较 字符串、列表、元组
注意:
· 与extend()的区别,+操作会生成新的列表,而用函数会修改原列表
· in在对 字典 操作时,判断的是 字典的键
· in和not in被称为成员运算符(用来测试序列中是否包含指定的成员)
· 在字典进行成员运算符操作是针对 Key,而不是值
5.4 完整的for循环语法
如下:
for 变量 in 集合:
循环体代码
else:
没有通过 break 退出循环,循环结束后,会执行的代码注意:else也是顶格写的,所以是独立于for之外的。
应用场景:
编辑:
students =[
{"name" : "zhangsan"},
{"name" : "lisi"}
]
find_name = "zhangsan"
for stu_dict in students:
print(stu_dict)
if stu_dict["name"] == find_name:
print("find %s" % find_name)
print("over")会输出:
{'name': 'zhangsan'}
find zhangsan
{'name': 'lisi'}
over分析:应该找到了学员信息,就应该直接退出循环,而不再遍历后续的元素。我们直接在找到后的代码后面添加break即可,但如果我们找“wangwu”(定义的列表中没有此字典),这个时候我们就需要 else 即可。代码如下
students =[
{"name" : "zhangsan"},
{"name" : "lisi"}
]
find_name = "wangwu"
for stu_dict in students:
print(stu_dict)
if stu_dict["name"] == find_name:
print("find %s" % find_name)
#如果已经找到,应该直接退出循环,而不再遍历后续的元素
break
else:
# 如果希望在搜索列表时,所有的字典检查之后,都没有发现需要搜索的目标
#还希望得到一个统一的提示
print("can not find %s" % find_name)
print("over")输出结果:
{'name': 'zhangsan'}
{'name': 'lisi'}
can not find wangwu
over01.变量的引用
· 变量和数据都是保存在内存中的
· 在Python中函数的参数传递及其返回值都是靠引用传递的。
1.1 引用
· 在python中,变量和数据是分开存储的(数据保存在内存中的一个位置,变量中保存着数据在内存中的地址,变量中记录数据的地址,使用id()函数可以查看变量中保存数据所在的内存地址)
· 如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用,变量不再对之前的数据引用,而改为对新赋值数据的引用。
实验1(证明函数本质上传递的是实参保存数据的引用,而不是实参保存的数据):
def test(num):
print("在函数内部 %d 对应的内存地址是 %d"% (num,id(num)))
# 1. 定义一个数字的变量
a=10
# 数据的地址本质上就是一个数字
print("a 变量保存数据的内存地址是 %d" % id(a))
# 2. 调用test函数,本质上传递的是实参保存数据的引用,而不是实参保存的数据
test(a)输出结果:
a 变量保存数据的内存地址是 34441104
在函数内部 10 对应的内存地址是 34441104
实验2(在实验1基础上证明:函数的返回值也是通过参数的引用来完成的)
def test(num):
print("在函数内部 %d 对应的内存地址是 %d"% (num,id(num)))
# 1) 定义一个字符串变量
result = "hello"
print("函数要返回的数据的内存地址是 %d" % id(result))
# 2) 将字符串变量返回
return result
# 1. 定义一个数字的变量
a=10
# 数据的地址本质上就是一个数字
print("a 变量保存数据的内存地址是 %d" % id(a))
# 2. 调用test函数,本质上传递的是实参保存数据的引用,而不是实参保存的数据
# 注意;如果函数有返回值,但是没有定义变量接收,程序不会报错,但是无法获得返回结果
r = test(a)
print("%s 的内存地址是 %d" %(r,id(r)))
结果输出:
a 变量保存数据的内存地址是 34310032
在函数内部 10 对应的内存地址是 34310032
函数要返回的数据的内存地址是 38859360
hello 的内存地址是 38859360