豆瓣影评爬虫
内容复制自公众号,排版可能不耐看,不要介意哈。
PythonGuy近期尝试爬取豆瓣电影评论,用作数据分析,在此记录爬取过程,以下代码仅供交流学习,你在使用过程中如有困惑可直接发私信给公众号,留言。
思路:
-
先登录豆瓣网站,获取cookie,然后携带cookie发起请求
-
发起评论请求,获得评论页面源代码
-
使用解析库爬取IOI(Information Of Interesting),写入csv文件
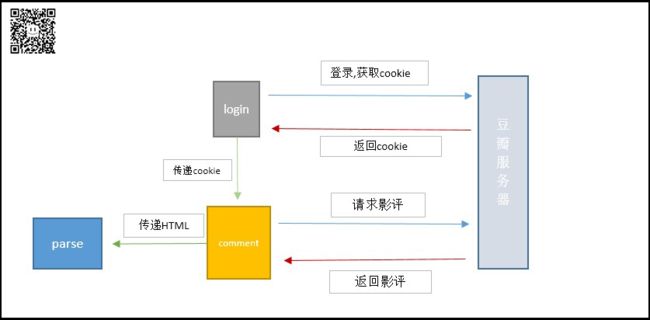
爬取原理图
依赖库:requests、os、csv、lxml
1.准备工作
分析豆瓣网站登录过程 浏览器输入https://movie.douban.com/链接,点击登录界面-->按下F12键,进入开发者模式-->点击Network。
紧接着输入用户名和密码,故意输错,查看详情,得到登录请求url

找到Ruequest Hearders,下拉找到FormData
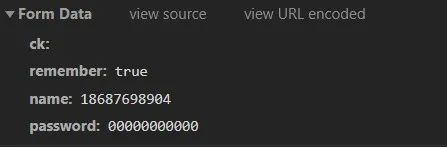
以下为登录请求携带参数,居然一点都不加密,离谱。
-
name:用户名
-
password:密码
-
remember:是否记住密码
2.登录
请求首选requests库,简洁又好用,它提供cookie获取/设置、会话维持等功能。
设置cookie
-
浏览器手动登录后,在开发者模式中复制cookie,添加到请求头headers
-
够着RequestsCookieJar对象,通过参数cookies设置
会话维持
会话功能相当于你在浏览器第一次提交登录信息后,后续一段时间就不用再重复提交信息了,因为浏览器每次请求都会自动携带cookie。如果每回都需要自己设置cookie会很繁琐,对此requests库提供了Session对象解决,它用于模拟登录后进行下一步操作。
import requestssession = requests.Session()session.get('https://*********')# 自动获取cookie
代理设置
对于某些网站,若干次请求可以正常获取内容,但一旦大规模爬取,对于频繁的请求,网站可能会弹出验证码,或者转到等登录认证界面,甚至封禁客户端ip,短时间内无法访问。为了防止以上情况发生,需要引入proxies参数
import requestsproxies = {"http":"http://10.20.000.000","https":"https://10.000.000.00"}requests.get(url,proxies = proxies)
登录函数douban_login
# 登录豆瓣def douban_login(login_url):login_url = "https://accounts.douban.com/j/mobile/login/basic" # 登录请求url# 构造请求头headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36','referer':'https://accounts.douban.com/passport/login?source=movie'}# 传递数据data = {'name':'17869888888','password':'123456789','remember':'false'}try:res = session.post(login_url , headers= headers , data=data) # 使用Session对象发起post请求res.raise_for_status()print(res.text)except Exception as e:print("Login failed")
第一次登陆可能会出现需要验证码的情况,在浏览器手动登录后即可解决。
3.请求评论
登录成功之后,随即请求评论url,获得网页源代码,并创建xpath对象,返回给parseInfo函数,将IOI提取出来。
现在分析评论url规则,挑选一步电影,假设为《送你一朵小红花》,查看全部影评,记录前几页url。
第一页https://movie.douban.com/subject/35096844/comments?status=P第二页https://movie.douban.com/subject/35096844/comments?start=20&limit=20&status=P&sort=new_score第三页https://movie.douban.com/subject/35096844/comments?start=40&limit=20&status=P&sort=new_score第四页https://movie.douban.com/subject/35096844/comments?start=60&limit=20&status=P&sort=new_score
显然start参数控制页面,既可以使用推导式构造评论url列表,也可以动态拼接。
comments_url=["https://movie.douban.com/subject/35096844/comments?status=" + str(i*20) for i in range(25)]
为了提高成功率,对请求头user-agent参数进行伪装,方法是创建一个用户代理池,可以直接保存在数据库里,方便每次请求url从中随机抽选一个。
# 用户代理池user_agents = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1""Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
请求评论函数comment_crawl
# 获取评论页面def comment_crawl(comment_url, agent, pageStart = 0):comment_url = 'https://movie.douban.com/subject/35096844/comments?start=' + str(pageStart * 20) # 构造评论url# 够早啊请求头headers = {'user-agent':agent}try:res = session.get(url = comment_url , headers = headers) # 使用Session对象发起get请求res.raise_for_status() # 查看状态html = etree.HTML(res.text) # 造xpath解析对象return htmlexcept Exception as e:print("Crawl comment html failed",e)
4.解析IOI
浏览器打开评论页面,进入开发者模式,检查内容,查看网页源代码,所有的评论都在id="comment"的div标签下,每一条评论在class="comment-item"的div标签内,构建爬取规则,将评论者昵称、评论内容、是否有用数量提取出来,保持至csv文件,本地持久化。
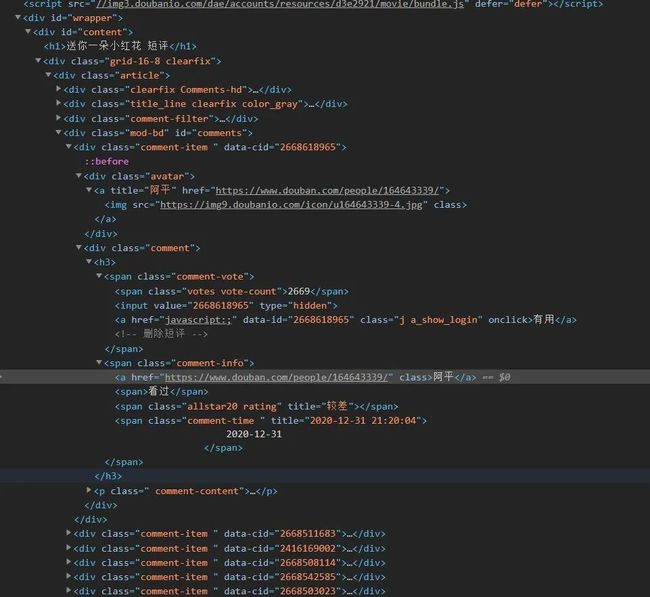
解析函数parseInfo
# 解析函数def parseInfo(html):try:# 构造爬取规则names = html.xpath('//div[@class="mod-bd"]//div[@class="comment-item "]//span[@class="comment-info"]/a/text()')comments = html.xpath('//div[@class="mod-bd"]//div[@class="comment-item "]//p[@class=" comment-content"]/span[@class="short"]/text()')uses = html.xpath('//div[@class="mod-bd"]//div[@class="comment-item "]//span[@class="votes vote-count"]/text()')save_dir = "E:/Desktop/豆瓣评论" # 保存路径# 判断路径是否存在,否则创建路径if os.path.exists(save_dir) == False:os.mkdir(save_dir)# 将爬取的信息写入csv文件for i in range(len(names)):with open(save_dir + "/comment.csv", 'a', encoding='utf-8-sig', newline="") as f:writer = csv.writer(f)writer.writerow([names[i], comments[i], uses[i]])# 打印输出消息print("Successfully save!")except Exception as e:print("解析网页错误",e)
5.结果
本人亲测,登录和评论请求不要过于频繁,否则会出现如下情况。
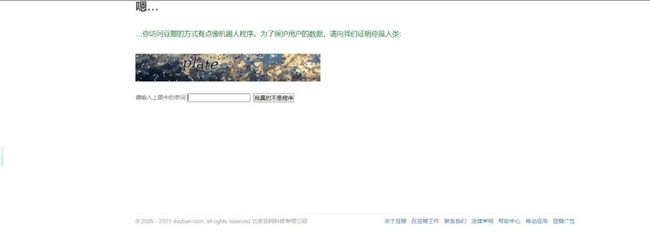
最好的方法是分页爬取或者设置程序定时sleep一下,降低触发反爬几率,这样子既可以减少豆瓣服务器压力,又成功爬取到数据,实现双赢。

程序运行
爬取结果

