SparkStreaming -- 02 【SparkStreaming和kafka的整合的offset的维护,常用算子】
文章目录
- 1、SparkStreaming与kafka的整合
-
- 1.1、 比较
- 1.2、 maven依赖
- 1.3、 案例1
- 1.4、 使用0-10的Direct方法的优点
- 1.5 、 两种自动维护offset的说明
-
- 1.5.1、 0-8的receiver如何自动维护offset的图解
- 1.5.2 、 0-10如何自动维护offset的图解
- 1.6、 使用zookeeper手动维护offset
- 1.7、 使用redis手动维护offset
- 2、SparkStreaming的常用转换算子
-
- 2.1 、常用算子简介
-
- 2.1.1、 常用的转换算子(transformation)
- 2.1.2、 常用的输出算子
- 2.2、 算子的案例演示:
1、SparkStreaming与kafka的整合
1.1、 比较
kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。
二者的整合,在整合的API上有主要的两大版本,分别是0-8和0-10,两者的区别如下:
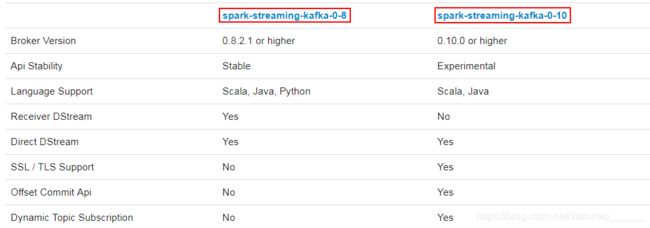
1.2、 maven依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>2.2.3version>
dependency>
1.3、 案例1
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming与Kafka的整合,用于消费Kafka里的信息
* 使用的整合包是0-10. 使用里面的Direct直连方式。 而0-8里除了direct还有一个reciver方法
*/
object _05SparkStreamingKafkaDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("test1").setMaster("local[2]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//获取上下文对象
val ssc = new StreamingContext(conf, Seconds(10))
//设置消费者的属性信息
val params: Map[String, String] = Map[String, String](
"bootstrap.servers" -> "datanode01:9092,datanode01:9092,datanode01:9092",
"group.id" -> "test1",
"auto.offset.reset" -> "latest",
"key.deserializer" -> "org.apache.kafka.common.serialization.IntegerDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
//使用整合包里的工具类,调用直连方法,读取Kafka中的消息
val dStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent, //指定消费策略:PreferConsistent, SparkStreaming会为kafka主题中的每一个分区,对应RDD中的一个分区,分配一个计算,
ConsumerStrategies.Subscribe[String,String](Array("pet").toSet, params)
)
//打印数据
dStream.map(_.value()).print()
//启动
ssc.start()
ssc.awaitTermination()
}
}
1.4、 使用0-10的Direct方法的优点
- 简化的并行性:
不需要开发人员创建多个输入Kafka流,并将其合并。
会主动创建数量和Kafka主题分区的数量一致的RDD分区,也就是分区数量一一对应,SparkSteaming会并行读取
Kafka分区中的数据 - 效率上(为了保证数据的零丢失):
0-8的receiver方法涉及到保存到zookeeper以及两次复制,一次是kafka上,一次还进行了WAL(效率低)
0-10的direct方法没有WAL,只是将数据保存了Kafka中。 - 正好一次的语义(Exactly-once)
0-8的receiver为了做到这个语义,是将消费者的消费的offset存储在ZK的/consumers/[groupId]/offsets/[topic]/[partition]路径下。但是开发人员想要重复读取,是不能手动指定offset的。
0-10的direct方法为了做到这个语义,将数据保存到了Kafka中的一个主题上。
并且还能手动维护offset,比如保存到hbase、hdfs、redis、zookeeper.
建议:如果手动维护offset,使用redis、zookeeper效率会高一些。
1.5 、 两种自动维护offset的说明
1.5.1、 0-8的receiver如何自动维护offset的图解

1.5.2 、 0-10如何自动维护offset的图解

为了应对可能出现的引起Streaming程序崩溃的异常情况,我们一般都需要手动管理好Kafka的offset,而不是让它自动提交,即需要将enable.auto.commit设为false。只有管理好offset,才能使整个流式系统最大限度地接近exactly once语义。
1.6、 使用zookeeper手动维护offset
import java.util
import java.util.Properties
import org.apache.curator.framework.CuratorFrameworkFactory
import org.apache.curator.retry.ExponentialBackoffRetry
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用zookeeper来手动维护SparkStreaming消费kafka消息的offset
* 1. 从zookeeper中获取偏移量 7
* 2. 处理数据 :从8读到12
* 3. 将最新的offset维护到zookeeper
*
*/
_02ZookeeperOffsetDemo {
def main(args: Array[String]): Unit = {
//过滤掉不需要的日志信息,留下警告级别以上的:
Logger.getLogger("org").setLevel(Level.WARN)
//获取配置对象
val conf: SparkConf = new SparkConf().setAppName("zookeeper").setMaster("local[2]")
//获取SparkStreaming的上下文对象
val ssc = new StreamingContext(conf, Seconds(5))
//定义一个主题集合
val topics: Array[String] = Array("pet")
//解析kafka的配置文件
val prop = new Properties()
prop.load(_02ZookeeperOffsetDemo.getClass.getClassLoader.getResourceAsStream("consumer.properties"))
val params: Map[String, String] = Map[String, String](
"bootstrap.servers" -> prop.getProperty("bootstrap.servers"),
"group.id" -> prop.getProperty("group.id"),
"key.deserializer" -> prop.getProperty("key.deserializer"),
"value.deserializer" -> prop.getProperty("value.deserializer"),
"enable.auto.commit" -> prop.getProperty("enable.auto.commit") //让SparkStreaming自动维护offset
)
//需要连接zookeeper集群,获取消费者消费的offsets
val zkUtils = new ZookeeperUtils(prop.getProperty("zookeeper.servers"))
val offsets:Map[TopicPartition,Long] = zkUtils.getOffsets(prop.getProperty("group.id"),topics)
var dStream: InputDStream[ConsumerRecord[String, String]] = null
//如果获取的offsetsd的长度大于0,说明不是第一次消费
if(offsets.size>0){
//调用工具类读取kafka中的数据
dStream =KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent, //让kafka的分区与rdd的分区一对一
ConsumerStrategies.Subscribe[String,String](topics, params,offsets)
)
println("这个主题不是第一次消费")
}else{
dStream = KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent, //让kafka的分区与rdd的分区一对一
ConsumerStrategies.Subscribe[String,String](topics, params))
println("这个主题是第一次消费")
}
//foreacheRDD算子就是遍历DStream里RDD序列中的每一个RDD
dStream.foreachRDD(rdd=>{
rdd.foreach(x=>{
x.offset()
x.partition()
println(x.partition()+"\t"+x.offset()+"\t"+x.value())
})
//获取消费信息的最后一个偏移量
val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//更新到zookeeper
zkUtils.updateOffset(prop.getProperty("group.id"),ranges)
})
ssc.start()
ssc.awaitTermination()
}
}
/**
* 自定义一个zookeeper的工具类,用来连接zookeer和获取zookeeper里的offset,以及更新offset的方法
* 设计一下路径:
* /kafka-2020/offsets/groupName/topicName/partitonNumber/
* @param zkServersInfo
*/
class ZookeeperUtils(zkServersInfo: String){
//连接zookeeer
val zkClient = {
val zkClient = CuratorFrameworkFactory.builder().connectString(zkServersInfo).retryPolicy(
new ExponentialBackoffRetry(1000,3)).build()
zkClient.start() //启动客户端,保持与zookeeper的连接
zkClient
}
//定义一个基础路径
val base_zookeeper_path = "/kafka-2020/offsets"
//检查zookeeper上的路径是否存在,如果不存在就创建
def checkPathExsist(path: String) = {
if(zkClient.checkExists().forPath(path)==null){
zkClient.create().creatingParentsIfNeeded().forPath(path)
}
}
//定义一个方法,来获取zookeeper上的偏移量
def getOffsets(groupName: String, topics: Array[String]): Map[TopicPartition, Long] = {
//先定义一个空的Map集合,用于存储获取到的offset
var offsets:Map[TopicPartition, Long] = Map()
//遍历主题的集合
for(topic<-topics){
//检查路径是否存在
val path = s"${base_zookeeper_path}/${groupName}/${topic}"
checkPathExsist(path)
//获取当前路径下的子节点, 子节点是当前主题下的所有分区的znode
val partitions: util.List[String] = zkClient.getChildren.forPath(path)
//从每一个分区中获取offset
import scala.collection.JavaConversions._
for(partition<-partitions){
//从znode中获取存储的数据,也就是offset
val bytes: Array[Byte] = zkClient.getData.forPath(partition)
//将字节数组转成Long类型的offset
val offset: Long = new String(bytes).toLong
//将对应的分区和offset添加到map中
offsets += (new TopicPartition(topic,partition.toInt)->offset)
}
}
offsets
}
/**
* 更新offset
* @param groupName
* @param ranges
*/
def updateOffset(groupName: String, ranges: Array[OffsetRange]): Unit = {
for(o<-ranges){
val path = s"${base_zookeeper_path}/${groupName}/${o.topic}/${o.partition}"
checkPathExsist(path)
zkClient.setData().forPath(path,o.untilOffset.toString.getBytes)
}
}
}
1.7、 使用redis手动维护offset
package com.xxx.SparkStreaming.Day02
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.{HostAndPort, Jedis, JedisCluster, JedisPool, JedisPoolConfig}
import java.util
/**
* 使用redis kv非关系型数据库俩维护kafka的主题分区的offset
*
* 1、使用redis中获取要读取的消息的开始offset
* 2、通过offset获取数据,进行处理
* 3、将读取到的最新的消息的offset更新到redis中
*
* redis存储offset数据的设计思路,使用hash数据类型
*
* key fields value
*
* groupName topic#partitonNumber offset
*
* test1 pet#0 22
*
*/
object _01RedisOffsetDemo {
def main(args: Array[String]): Unit = {
//过滤掉不需要的日志信息,留下警告级别以上的
Logger.getLogger("org").setLevel(Level.WARN)
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("redisOffset")
val context = new StreamingContext(conf, Seconds(10))
//创建一个主题集合
val topics: Array[String] = Array("pet")
//将消费者组单独提出来,后面方便使用
val groupid: String = "test2"
//创建一个kafka的配置map集合
val params: Map[String, String] = Map[String, String](
"bootstrap.servers" -> "qianfeng01:9092,qianfeng02:9092,qianfeng03:9092",
"group.id" -> "test2",
// "auto.offset.reset" -> "earliest", //因为要从维护的offset处开始读取,因此没有必要设置这个属性
"key.deserializer" -> "org.apache.kafka.common.serialization.IntegerDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"enable.auto.commit" -> "false"
)
//先要获取jedis对象,连接redis,获取偏移量
val jedis: Jedis = GetRedis.getRedis
//从redis中查询之前的数据
val offsets: Map[TopicPartition, Long] = Offset(jedis, groupid)
//如果offsets为空的话,则说明SparkStreaming是第一次消费kafka上的数据,不用获取offset
//如果不为空的话,就从redis中获取offset,然后从kafka上根据offset拉取所对应的数据
//将if表达式的结果接收,得到从kafka读到的数据的DStream
val DStream:InputDStream[ConsumerRecord[String,String]] = if (offsets.isEmpty) {
KafkaUtils.createDirectStream(context,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topics, params))
}else{
KafkaUtils.createDirectStream(context,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topics, params,offsets))
}
//处理kafka上的消息
DStream.foreachRDD(rdd=>{
rdd.foreach(println)
//获取最新的offset,发送给redis
val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (off <- ranges){
jedis.hset(groupid,off.topic+"#"+off.partition,off.untilOffset.toString)
}
})
context.start()
context.awaitTermination()
}
}
object GetRedis{
//配置连接池的配置
private val config = new GenericObjectPoolConfig
config.setMaxTotal(10)
config.setMaxIdle(5)
//连接redis集群
val pool = new JedisPool(config,"qianfeng01",6379,10000,"123123")
private val jedis: Jedis = pool.getResource
def getRedis = jedis
}
object Offset{
def apply(jedis:Jedis,groupid:String):Map[TopicPartition,Long] = {
//实例化一个新的map,用来存储从redis上获取的offset等数据
var offsets: Map[TopicPartition, Long] = Map[TopicPartition, Long]()
//从redis中查询数据
val offsetMetadata: util.Map[String, String] = jedis.hgetAll(groupid)
//遍历集合,拿到想要的数据
import scala.collection.JavaConversions._
for (offsetData <- offsetMetadata){
//根据分隔符#进行切分
val topicAndPartition: Array[String] = offsetData._1.split("#")
val topic: String = topicAndPartition(0)
val partiton: Int = topicAndPartition(1).toInt
//将数据封装到offset集合中
offsets += (new TopicPartition(topic,partiton)->offsetData._2.toLong)
}
offsets
}
}
2、SparkStreaming的常用转换算子
2.1 、常用算子简介
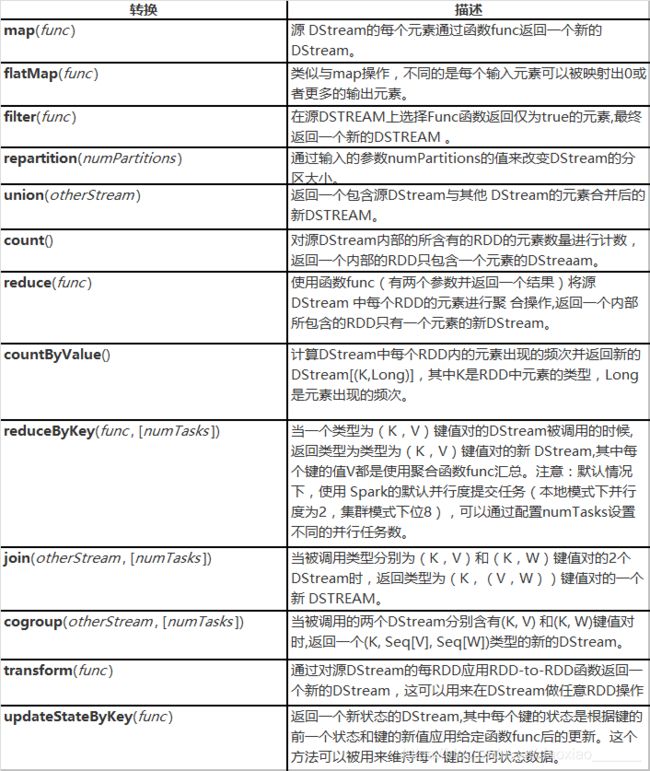
2.1.1、 常用的转换算子(transformation)
参考官网:http://spark.apache.org/docs/2.2.3/streaming-programming-guide.html#transformations-on-dstreams
2.1.2、 常用的输出算子
参考官网:http://spark.apache.org/docs/2.2.3/streaming-programming-guide.html#output-operations-on-dstreams
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QnK8Hklh-1607337253857)(ClassNotes.assets/image-20201207172749402.png)]
2.2、 算子的案例演示:
1)常用算子
package com.qf.sparkstreaming.day02
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming的常用转换算子练习 使用nc
*/
object _04TransformationDemo {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
//获取配置对象
val conf: SparkConf = new SparkConf().setAppName("zookeeper").setMaster("local[2]")
//获取SparkStreaming的上下文对象
val ssc = new StreamingContext(conf, Seconds(5))
val dStream: ReceiverInputDStream[String] = ssc.socketTextStream("qianfeng01", 10087)
//map算子的练习
// dStream.map(x=>(x,1)).print()
//reduceByKey算子, 对同意micro-batch里的数据进行按照key分组运算
// dStream.map((_,1)).reduceByKey((x,y)=>x+y).print()
//flatMap和filter算子的练习:统计单词长度大于5的单词频率
// dStream.flatMap(_.split(" ")).filter(_.length>5).map((_,1)).reduceByKey(_+_).print()
//union算子的练习:将两个DStream里的数据进行求并集
// val d1: DStream[(String, Int)] = dStream.map((_, 1))
// val d2: DStream[(String, Int)] = dStream.map((_, 1)).reduceByKey(_ + _)
// val d3: DStream[(String, Int)] = d1.union(d2)
// d3.print()
//count算子:统计每一批数据的记录数
// val value: DStream[Long] = dStream.count()
// value.print()
// val value: DStream[((String, Int), Long)] = dStream.map((_, (Math.random()*10).toInt)).countByValue()
// value.print()
//join的练习
dStream.flatMap(_.split(" ")).filter(_.length>5).map((_,1)).reduceByKey(_+_).print()
val d1: DStream[(String, Int)] = dStream.map((_, 1))
val d2: DStream[(String, Int)] = dStream.map((_, 1)).reduceByKey(_ + _)
val value1: DStream[(String, (Int, Int))] = d1.join(d2)
value1.print()
ssc.start()
ssc.awaitTermination()
}
}
2)foreachRDD
package com.qf.sparkstreaming.day02
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.ReceiverInputDStream
object _05ForeachRDDdemo {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
//获取配置对象
val conf: SparkConf = new SparkConf().setAppName("zookeeper").setMaster("local[2]")
//获取SparkStreaming的上下文对象
val ssc = new StreamingContext(conf, Seconds(5))
val dStream: ReceiverInputDStream[String] = ssc.socketTextStream("qianfeng01", 10087)
/**
* foreachRDD
* 1. 首先是一个输出算子
* 2. 在driver端执行
* 3. 将DStream处理的micro-batch数据转成RDD,就可以调用RDD的相关算子进行运算
*/
dStream.foreachRDD(rdd=>{
rdd.map((_,1)).foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
}
- transform
package com.qf.sparkstreaming.day02
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 模拟场景:
* 有几个男孩子被列为澡堂子的黑名单
* 比如:小蒋,小黄,小唐
*/
object _07TransformDemo {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("OnlineBlacklistFilter")
.setMaster("local[*]")
val duration = Seconds(20)
val ssc = new StreamingContext(conf, duration)
//模拟一个RDD,存储黑名单
val list = List(("小蒋",true),("小唐",true),("小黄",true))
val blackList: RDD[(String, Boolean)] = ssc.sparkContext.makeRDD(list)
//读取数据流中的名单
val dStream: ReceiverInputDStream[String] = ssc.socketTextStream("qianfeng01", 10087)
val dStream1: DStream[(String, (Int, Option[Boolean]))] = dStream.map((_, 1)).transform((rdd, time) => {
//micro-batch里的数据与黑名单进行关联
/*
xiaohei (1,)
小唐 (1,true)
.......
*/
val rdd1: RDD[(String, (Int, Option[Boolean]))] = rdd.leftOuterJoin(blackList)
val rdd2: RDD[(String, (Int, Option[Boolean]))] = rdd1.filter(x => {
if (x._2._2.getOrElse(false)) {
false
} else {
true
}
})
rdd2
})
dStream1.print()
ssc.start()
ssc.awaitTermination()
}
}
4)updateStateByKey
package com.qf.sparkstreaming.day02
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming的普通算子不能进行批次之间的聚合。
* 而提供的UpdateStateByKey这个算子就是用于批次之间的聚合。
*/
object _08UpdateStateByKey {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("OnlineBlacklistFilter")
.setMaster("local[*]")
val duration = Seconds(20)
val ssc = new StreamingContext(conf, duration)
ssc.checkpoint("data")
val dStream: ReceiverInputDStream[String] = ssc.socketTextStream("qianfeng01", 10087)
//定义一个函数
/**
* 第一个参数K 表示
* 第二个参数 Seq[V] 表示这一批次的同一个key的v的集合
* 第三个参数 Option[S]) 表示上一批次的这个key的v的值
* 返回值是一个迭代器,返回的是这个key与这一批次的值与上一批次值的累加之和
*/
val func = (iter:Iterator[(String, Seq[Int], Option[Int])]) => {
iter.map(x=>{
(x._1,x._2.sum+x._3.getOrElse(0))
})
}
val result: DStream[(String, Int)] = dStream.map((_, 1)).updateStateByKey(
func,
new HashPartitioner(ssc.sparkContext.defaultMinPartitions),
true)
result.print()
ssc.start()
ssc.awaitTermination()
}
}