C++智能指针原理与丐版实现
文章目录
- 一、为什么需要智能指针?
- 二、简易智能指针实现
- 三、智能指针的详细原理与实现
-
- 3.1 RAII机制
- 3.2 智能指针的发展历史
- 3.3 unique_ptr(唯一指针)
- 3.4 shared_ptr(共享指针)
- 3.5 shared_ptr的循环引用问题
- 3.6 weak_ptr(弱指针)
- 3.7 为智能指针定制删除器
一、为什么需要智能指针?
C++为什么需要智能指针呢?像Python、Java等有GC机制的OOP语言,通常是没有智能指针的,但是C++经常会因为异常安全问题,突然因为异常跳到catch中,导致new申请出来的资源没有被正常delete,这样就会出现异常安全问题。
在上一节异常中,我们通过重新捕获异常来解决这个事情,但是它没有从根源上解决这个问题,比如如果我们重新捕获异常,前面如果有多个可能抛异常的位置,你还要通过判断是哪个异常发生了把我带到了异常处理这个地方,相当的麻烦,比如下面的实例代码:
void div()
{
int a, b;
cin >> a >> b;
if (b == 0) throw exception("除0错误");
cout << a / b << endl;
}
int main()
{
int* p1 = nullptr, *p2 = nullptr, *p3 = nullptr;
try
{
p1 = new int[10000000];
p2 = new int;
p3 = new int;
div();
}
catch (const exception& e)
{
// 因为new也可能抛异常 我怎么知道是p1抛的 还是p2抛的 还是p3抛的 还是div抛的
// 如果是p1抛出异常 那么不需要处理p2和p3
// 如果是p2抛出异常 那么需要delete p1
// 如果是p3抛出异常 那么需要delete p1 和 p2
// 如果是div抛出异常 那么需要delete p1 p2 和 p3
cout << e.what() << endl;
if (p1 == nullptr)
{
}
else if (p2 == nullptr)
{
delete p1;
}
else if (p3 == nullptr)
{
delete p1;
delete p2;
}
else
{
delete p1;
delete p2;
delete p3;
}
}
}
二、简易智能指针实现
有没有什么思想能帮我们解决这个问题呢?可以参考我们之前写的 lock_guard的写法,我们利用离开作用域会调用析构函数来帮助我们释放资源:
template <class T>
class SmartPtr
{
public:
SmartPtr(T* ptr) : _ptr(ptr) {}
~SmartPtr()
{
if (_ptr) delete _ptr;
cout << "智能指针已释放资源" << endl;
}
private:
T* _ptr;
};
void div()
{
int a, b;
cin >> a >> b;
if (b == 0) throw exception("除0错误");
cout << a / b << endl;
}
int main()
{
int* p1 = nullptr, *p2 = nullptr, *p3 = nullptr;
try
{
vector<int> vec;
p1 = new int;
SmartPtr<int> sp1(p1);
p2 = new int;
SmartPtr<int> sp2(p2);
throw exception("test");
p3 = new int;
SmartPtr<int> sp3(p3);
// vec.reserve(1000000000);
div();
}
catch (const exception& e)
{
// 直接离开作用域交给智能指针处理
cout << e.what() << endl;
}
}
我们通过 vector 申请空间过大去造成 bad_alloction异常错误,然后来看看我们写的智能指针能不能帮我们管理资源:
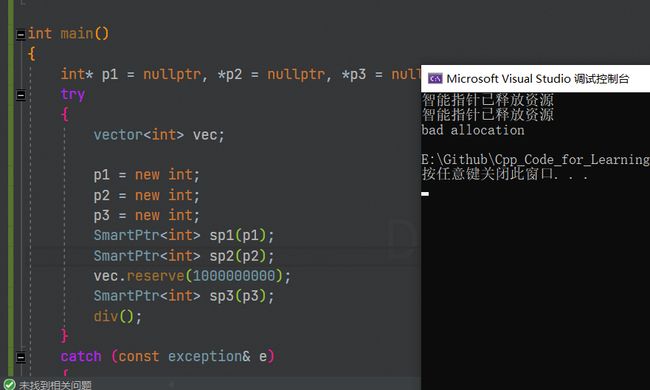
还可以不需要p1 p2 p3这些裸指针,直接用new给智能指针初始化,顺便利用运算符重载,实现一下让我们的智能指针能像原生指针一样操作:
template <class T>
class SmartPtr
{
public:
SmartPtr(T* ptr) : _ptr(ptr) {}
~SmartPtr()
{
if (_ptr) delete _ptr;
cout << "智能指针已释放资源" << endl;
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
void div()
{
int a, b;
cin >> a >> b;
if (b == 0) throw exception("除0错误");
cout << a / b << endl;
}
int main()
{
try
{
vector<int> vec;
SmartPtr<int> sp1(new int());
SmartPtr<int> sp2(new int());
// throw exception("test");
SmartPtr<int> sp3(new int());
(*sp1)++;
// vec.reserve(1000000000);
cout << *sp1 << ' ' << *sp2 << ' ' << *sp3 << endl;
div();
}
catch (const exception& e)
{
// 直接离开作用域交给智能指针处理
cout << e.what() << endl;
}
}
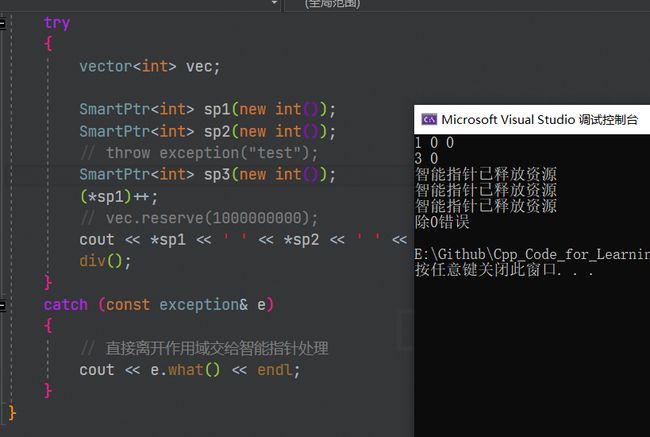
三、智能指针的详细原理与实现
3.1 RAII机制
RAII即Resource Acquisition Is Initialization,意味资源获取后就把它交给一个作为构造函数的一个参数去初始化一个对象,然后利用对象的生命周期来管理这个资源。
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的
时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。这种做法有两大好处:
- 不需要显式地释放资源。
- 采用这种方式,对象所需的资源在其生命期内始终保持有效。
所以一个基本的智能指针它有两种机制:RAII机制管理资源、通过operator*和operator->像指针一样操作。
3.2 智能指针的发展历史
假如继续完善我们的智能指针,我们如果拷贝智能指针,默认拷贝会按字节拷贝,然后析构时就会delete两次,就会导致程序崩溃。
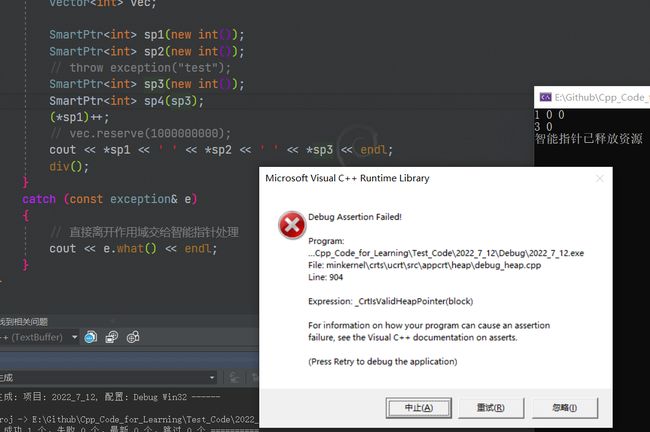
怎么解决呢?这就牵扯出了智能指针的发展历史:
C++98就已经有智能指针了,对这个拷贝问题也非常难受,C++98中提出了管理权转移的思想 auto_ptr,想法很简单,既然两个人指向同一块空间会出现析构两次的问题,那么每次要拷贝的时候我就转移管理权。
auto_ptr(auto_ptr<T>& ap)
: _ptr(ap._ptr)
{
// 被拷贝的指针置空 不管理资源了
ap._ptr = nullptr;
}
这样设计虽然不会崩溃,但是它最大的问题是我被拷贝的对象在拷贝后就悬空了,如果操作者不熟悉很容易就会发生空指针的问题。
这一个问题就否掉了 auto_ptr的使用,大部分公司都明令禁止 auto_ptr的使用,总之,auto_ptr是一个失败的设计。
我们都知道,C++98之后下一个大版本就是C++11,这中间难道C++的智能指针就一直这么烂?额,标准库的确实一直这么烂,但是C++不止有标准库噻,因为这个标准更新的太慢了,毕竟要追求一个稳定,很多标准库的人建立了一个社区,他们创立了boost库,用来探索C++的发展,在C++11之前,boost库就已经有了三个较为实用的智能指针。
它们分别是:scoped_ptr/shared_ptr/weak_ptr,大家在这漫长的空窗期用智能指针一般都是用这三个,在C++11更新后,把这三个指针“抄”了过来,名字啊实现啊稍微改了一下,有了三个智能指针:unique_ptr/shared_ptr/weak_ptr,他们都在头文件
3.3 unique_ptr(唯一指针)
它对拷贝的处理非常简单粗暴,防拷贝,不让你拷贝,也不让你赋值,C++98中通过只声明不实现,声明成私有就行;C++11中搞成delete即可。
namespace scu
{
template <class T>
class unique_ptr
{
public:
unique_ptr(T* ptr) : _ptr(ptr) {}
~unique_ptr()
{
if (_ptr) delete _ptr, cout << "智能指针已释放资源" << endl;
}
// 禁止拷贝 禁止赋值
unique_ptr(const unique_ptr& up) = delete;
unique_ptr<T>& operator=(const unique_ptr<T>& up) = delete;
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
}
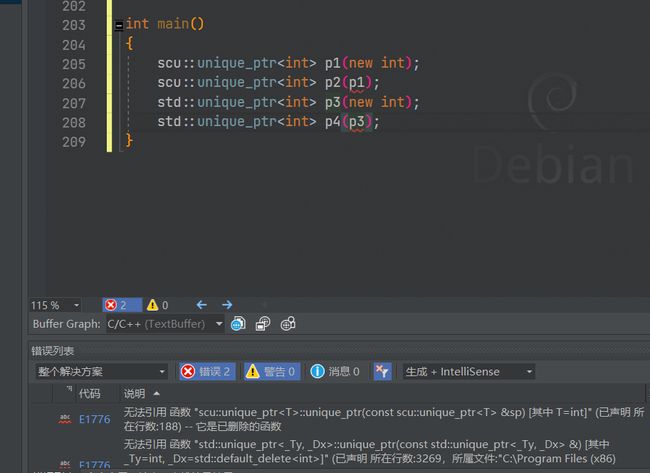
那如果我需要拷贝呢?这里我们就可以用 shared_ptr了。
3.4 shared_ptr(共享指针)
shared_ptr的设计思路是引用计数。
原理:记录有多少个对象管理着这块资源,每个对象析构时–计数,最后一个析构的对象负责释放资源。
但是如果我们用类的静态数据成员,相当于所有 shared_ptr只有一个静态成员对象,如果有很多类型的资源呢,比如P1 P2 P3都是A类型的指针,P4是B类型的指针,那难道他们共享同一个RefCount吗,显然不合理啊。
我们希望一个资源配一个引用计数。
观察我们的场景,对不同的资源的管理过程中,对某一块资源,只有第一次进入构造函数时,是申请这个资源,其他情况都是拷贝,会进拷贝构造函数,因此我们可以在构造函数内增加一个东西,进构造函数时,申请一个堆资源表示引用计数,后续再进入拷贝构造时,++这个引用计数即可。
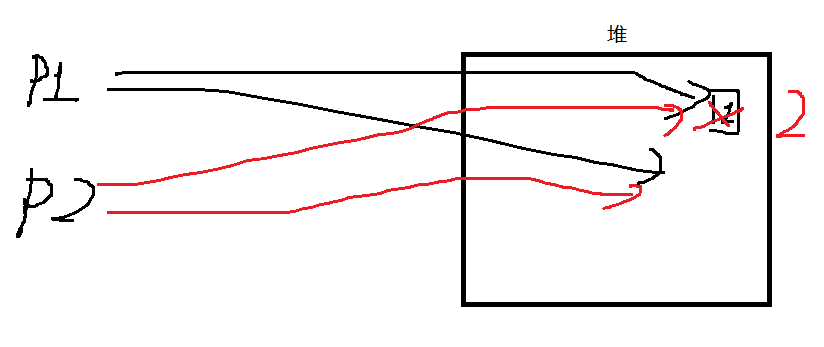
模拟这个思想,我们写出来的代码如下:
namespace scu
{
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr) : _ptr(ptr), _pRefCnt(new int(1)){}
~shared_ptr()
{
--(*_pRefCnt);
if ((*_pRefCnt) == 0 && _ptr)
{
delete _ptr;
delete _pRefCnt;
_ptr = nullptr;
_pRefCnt = nullptr;
cout << "scu::shared_ptr释放内存成功" << endl;
}
}
shared_ptr(const shared_ptr& sp) : _ptr(sp._ptr), _pRefCnt(sp._pRefCnt)
{
++(*_pRefCnt);
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
int* _pRefCnt;
};
}
int main()
{
scu::shared_ptr<int> p1(new int(3));
auto p2 = p1;
auto p3 = p1;
scu::shared_ptr<int> p4(new int(2));
auto p5(p4);
}
这里我们再控制一下赋值,如果是管理着不同地址但同一类型的资源(也就是引用计数的地址不同,则左操作数的引用计数应该减1,右操作数的引用计数应该加1,如果做操作数的引用计数减到0了,则delete它)
shared_ptr<T>& operator=(const shared_ptr& sp)
{
// 不同地址的同种类型资源
if (sp._pRefCnt != _pRefCnt)
// 或
// if (sp._ptr != _ptr)
{
release();
_pRefCnt = sp._pRefCnt;
_ptr = sp._ptr;
_pmtx = sp._pmtx;
addRef();
}
return *this;
}
这里我们把减少引用计数并且判断若引用计数到0了就释放资源放到了函数release中,把增加引用计数放到了成员函数addRef中:
void release()
{
--(*_pRefCnt);
if ((*_pRefCnt) == 0 && _ptr)
{
delete _ptr;
delete _pRefCnt;
_ptr = nullptr;
_pRefCnt = nullptr;
cout << "scu::shared_ptr释放内存成功" << endl;
}
}
void addRef()
{
++(*_pRefCnt);
}
但是多线程情况下,这里还有别的问题:多线程场景下,指向的资源不归我们智能指针管,这个由资源的使用者自己去用锁去管理,但是有一个东西我们必须要管->引用计数的线程安全问题。
看下面的代码:
struct Date
{
Date(int year = 2022, int month = 7, int day = 12)
: _year(year), _month(month), _day(day)
{}
int _year, _month, _day;
};
void shared_ptr_func(scu::shared_ptr<Date>& sp, int n)
{
for (int i = 0; i < n; ++i)
{
scu::shared_ptr<Date> copy(sp);
copy->_day++;
copy->_month++;
copy->_year++;
}
}
int main()
{
scu::shared_ptr<Date> sp = new Date(2022, 7, 11);
thread t1(shared_ptr_func, std::ref(sp), 100000);
thread t2(shared_ptr_func, std::ref(sp), 100000);
t1.join();
t2.join();
return 0;
}
这里引用计数可能出现线程安全问题:两个线程都在拷贝sp时,按理说引用计数应该变成3,然后每轮循环结束引用计数再减1,两个都减1回到1,但是有可能出现同时访问那个引用计数,然后都读取到了1,然后把2写了回去,然后析构时两个拷贝的指针析构了,减减到0,那不就崩了吗,比如我们下面这个实验:
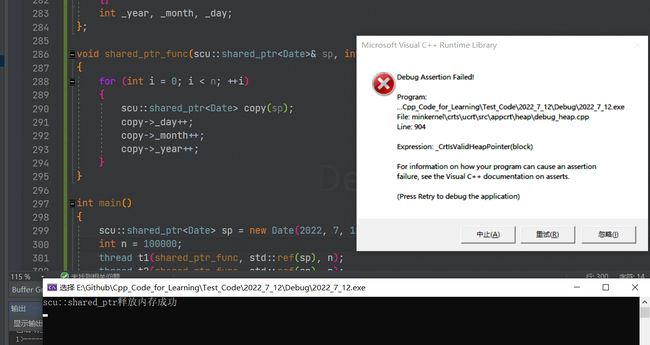
具体概括我们面对的问题就是:多线程对同一个智能指针对象进行拷贝和析构时,会同时++和–引用计数,这时引用计数就存在线程安全问题。
怎么解决呢,加锁呗,注意,这里加锁和引用计数那里一样,我们一个锁去保护一个引用计数,一个锁对应一个资源,所以我们这里需要锁的指针,在加加引用计数和减减引用计数时加锁即可:
namespace scu
{
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr) : _ptr(ptr), _pRefCnt(new int(1)), _pmtx(new mutex) {}
// 同一把--引用计数 如果引用计数的值为0了就delete的逻辑放到外面去 统一调
void release()
{
_pmtx->lock();
--(*_pRefCnt);
if ((*_pRefCnt) == 0 && _ptr)
{
delete _ptr;
delete _pRefCnt;
_ptr = nullptr;
_pRefCnt = nullptr;
cout << "scu::shared_ptr释放内存成功" << endl;
}
_pmtx->unlock();
}
// 为方便后续加锁 加一个addRef函数 表示引用计数++
void addRef()
{
_pmtx->lock();
++(*_pRefCnt);
_pmtx->unlock();
}
~shared_ptr()
{
release();
}
shared_ptr(const shared_ptr& sp) :
_ptr(sp._ptr), _pRefCnt(sp._pRefCnt), _pmtx(sp._pmtx)
{
addRef();
}
shared_ptr<T>& operator=(const shared_ptr& sp)
{
// 不同地址的同种类型资源
if (sp._pRefCnt != _pRefCnt)
// 或
// if (sp._ptr != _ptr)
{
release();
_pRefCnt = sp._pRefCnt;
_ptr = sp._ptr;
_pmtx = sp._pmtx;
addRef();
}
return *this;
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
int getcnt() const
{
return *_pRefCnt;
}
private:
T* _ptr;
int* _pRefCnt;
// 保护某个引用计数的锁 同样在构造函数里初始化
std::mutex* _pmtx;
};
}
struct Date
{
Date(int year = 2022, int month = 7, int day = 12)
: _year(year), _month(month), _day(day)
{}
int _year, _month, _day;
};
void shared_ptr_func(scu::shared_ptr<Date>& sp, int n)
{
for (int i = 0; i < n; ++i)
{
scu::shared_ptr<Date> copy(sp);
copy->_day++;
copy->_month++;
copy->_year++;
// if (copy.getcnt() == 2) cout << copy.getcnt() << endl;
}
}
int main()
{
scu::shared_ptr<Date> sp = new Date(2022, 7, 11);
int n = 100000;
thread t1(shared_ptr_func, std::ref(sp), n);
thread t2(shared_ptr_func, std::ref(sp), n);
t1.join();
t2.join();
return 0;
}
上面的代码还有一个问题:什么时候释放new来的锁比较合适呢?在引用计数为0的释放资源的那个位置释放new来的锁肯定不对,因为下面还要解锁,简易的解决方法是外头放一个 flag,既然我们释放new来的锁应该是最后一个引用计数哪里释放,那么就在那个地方flag置为true,然后每次release那个地方检查flag去决定释放锁与否:
void release()
{
_pmtx->lock();
--(*_pRefCnt);
bool flag = false;
if ((*_pRefCnt) == 0 && _ptr)
{
delete _ptr;
delete _pRefCnt;
_ptr = nullptr;
_pRefCnt = nullptr;
flag = true;
cout << "scu::shared_ptr释放内存成功" << endl;
}
_pmtx->unlock();
if (flag == true)
{
delete _pmtx;
_pmtx = nullptr;
cout << "new的锁资源也已经释放" << endl;
}
}
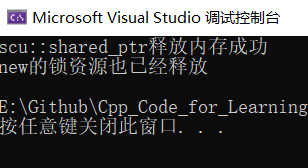
既然我们这个锁能够保护引用计数的线程安全,我们能否把我们的资源也一起通过这个锁保护了呢,可惜这是不可能的,因为访问资源的地方是智能指针使用者在使用解引用和->的地方,这些地方你想管你也管不到啊。
所以上面的函数,保护访问堆资源的线程安全,还需要我们自己再加一个锁:
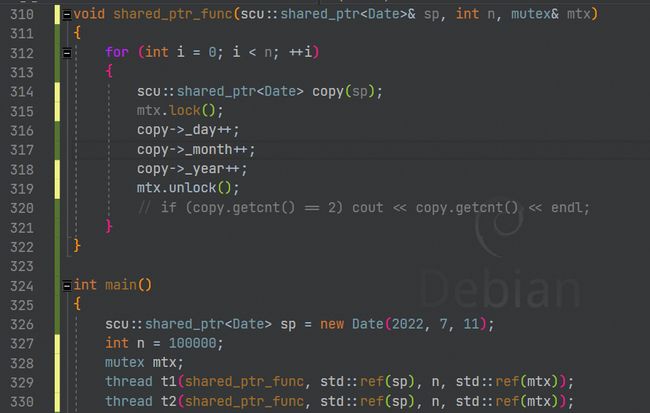
再换上锁守卫,充分利用RAII机制:
namespace scu
{
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr) : _ptr(ptr), _pRefCnt(new int(1)), _pmtx(new mutex) {}
// 同一把--引用计数 如果引用计数的值为0了就delete的逻辑放到外面去 统一调
void release()
{
_pmtx->lock();
--(*_pRefCnt);
bool flag = false;
if ((*_pRefCnt) == 0 && _ptr)
{
delete _ptr;
delete _pRefCnt;
_ptr = nullptr;
_pRefCnt = nullptr;
flag = true;
cout << "scu::shared_ptr释放内存成功" << endl;
}
_pmtx->unlock();
if (flag == true)
{
delete _pmtx;
_pmtx = nullptr;
cout << "new的锁资源也已经释放" << endl;
}
}
// 为方便后续加锁 加一个addRef函数 表示引用计数++
void addRef()
{
_pmtx->lock();
++(*_pRefCnt);
_pmtx->unlock();
}
~shared_ptr()
{
release();
}
shared_ptr(const shared_ptr& sp) :
_ptr(sp._ptr), _pRefCnt(sp._pRefCnt), _pmtx(sp._pmtx)
{
addRef();
}
shared_ptr<T>& operator=(const shared_ptr& sp)
{
// 不同地址的同种类型资源
if (sp._pRefCnt != _pRefCnt)
// 或
// if (sp._ptr != _ptr)
{
release();
_pRefCnt = sp._pRefCnt;
_ptr = sp._ptr;
_pmtx = sp._pmtx;
addRef();
}
return *this;
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
int getcnt() const
{
return *_pRefCnt;
}
private:
T* _ptr;
int* _pRefCnt;
// 保护某个引用计数的锁 同样在构造函数里初始化
std::mutex* _pmtx;
};
}
struct Date
{
Date(int year = 2022, int month = 7, int day = 12)
: _year(year), _month(month), _day(day)
{}
int _year, _month, _day;
};
void shared_ptr_func(scu::shared_ptr<Date>& sp, int n, mutex& mtx)
{
for (int i = 0; i < n; ++i)
{
scu::shared_ptr<Date> copy(sp);
std::lock_guard<mutex> lg(mtx);
copy->_day++;
copy->_month++;
copy->_year++;
// mtx.unlock();
// if (copy.getcnt() == 2) cout << copy.getcnt() << endl;
}
}
int main()
{
scu::shared_ptr<Date> sp = new Date(2022, 7, 11);
int n = 100000;
mutex mtx;
thread t1(shared_ptr_func, std::ref(sp), n, std::ref(mtx));
thread t2(shared_ptr_func, std::ref(sp), n, std::ref(mtx));
t1.join();
t2.join();
return 0;
}
如果想要控制RAII资源的粒度,可以利用一个局部域,比如下面的例子:
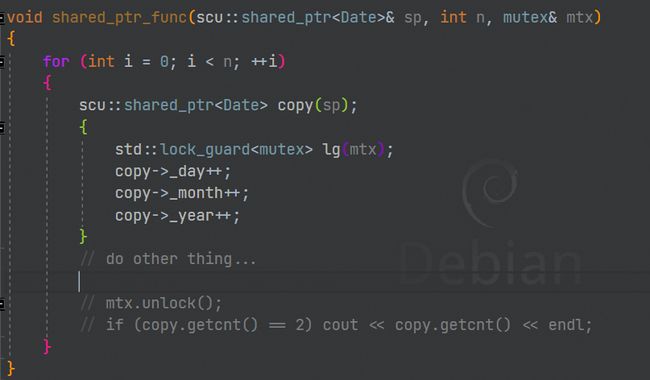
所以对于问题C++中的智能指针是线程安全的吗?回答应该是这样的:
C++中的智能指针是线程安全的,因为它的引用计数是加锁了的,保证了多线程情况下不会同时加加减减资源的引用计数而导致出现问题,但是智能指针指向的资源的线程安全要我们自己保证。
3.5 shared_ptr的循环引用问题
只有在下面的特殊场景中,shared_ptr会出现一种循环引用的问题:
假设我们有一个双链表,我们把两个结点链到一起,因为我们学习了智能指针嘛,我们把链表中的指向前一结点和后一结点的指针都换成 shared_ptr,申请结点时也使用shared_ptr,期望智能指针能帮我们析构链表中的两个结点:
struct ListNode
{
int _val;
std::shared_ptr<ListNode> _next;
std::shared_ptr<ListNode> _prev;
ListNode() = default;
~ListNode()
{
cout << "~ListNode" << endl;
}
};
int main()
{
shared_ptr<ListNode> n1(new ListNode);
shared_ptr<ListNode> n2(new ListNode);
n1->_next = n2;
n2->_prev = n1;
return 0;
}
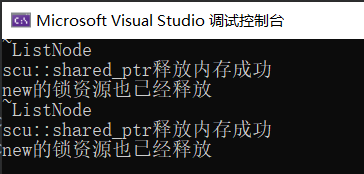
我们发现完全没有资源释放,两个ListNode节点都没去调用析构函数:
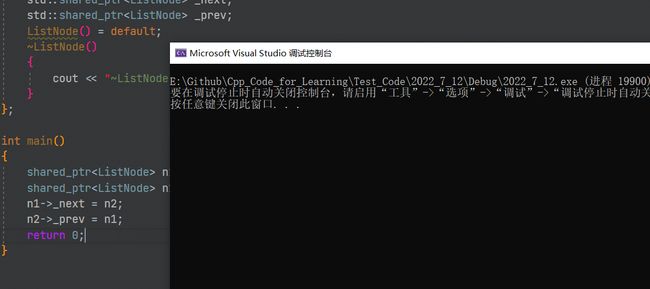
这是为啥呢?参考下面的图片解释:
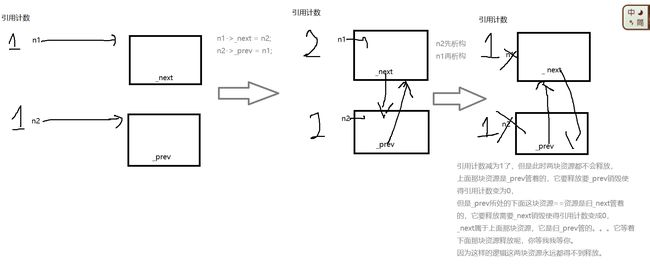
这就好像两个人打架,我抓着你的头发,你抓着我的头发,你觉得我不松手你就一定不松手,我觉得你不松手我就一定不松手,而且我们两个人都不会退一步主动松手,这就是一个死结了。
shared_ptr那么好,但是就是有这个循环引用问题。。。设计者也找不到怎么修改shared_ptr来处理这个问题,所以他的选择是让大家在学习时意识到这个问题,并且提供一个 weak_ptr来应对这种情况。
3.6 weak_ptr(弱指针)
weak_ptr并不是常规意义上的智能指针,它并不去负责管理我们的资源,这可以从他的构造函数中看出来:
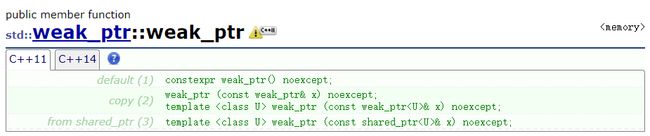
发现它没有一个接受原生指针的接口,它也不去用RAII机制管理我们的资源,它最重要的是可以从 shared_ptr得到,并且可以像一个指针一样操作。
所以我们可以把刚刚的节点的指针改成 weak_ptr,它不会去增加引用计数,这样它就不会去负责资源的释放:
weak_ptr可以去像指针一样去访问资源,修改值,但是它不会去增加或减少引用计数去负责管理这些资源。
我们考虑自己写一个weak_ptr,首先我们考虑到我们的shared_ptr没有默认构造函数,为其增加一个默认构造函数,把指针都置成空的,然后稍微修补一下细节:
namespace scu
{
template <class T>
class shared_ptr
{
public:
shared_ptr()
: _ptr(nullptr), _pRefCnt(nullptr), _pmtx(nullptr)
{}
shared_ptr(T* ptr) : _ptr(ptr), _pRefCnt(new int(1)), _pmtx(new mutex) {}
// 同一把--引用计数 如果引用计数的值为0了就delete的逻辑放到外面去 统一调
void release()
{
// 防止是空的锁指针进来上锁并且干别的
if (_pmtx != nullptr)
{
_pmtx->lock();
--(*_pRefCnt);
bool flag = false;
if ((*_pRefCnt) == 0 && _ptr)
{
delete _ptr;
delete _pRefCnt;
_ptr = nullptr;
_pRefCnt = nullptr;
flag = true;
cout << "scu::shared_ptr释放内存成功" << endl;
}
_pmtx->unlock();
if (flag == true)
{
delete _pmtx;
_pmtx = nullptr;
cout << "new的锁资源也已经释放" << endl;
}
}
}
// 为方便后续加锁 加一个addRef函数 表示引用计数++
void addRef()
{
_pmtx->lock();
++(*_pRefCnt);
_pmtx->unlock();
}
~shared_ptr()
{
release();
}
shared_ptr(const shared_ptr& sp) :
_ptr(sp._ptr), _pRefCnt(sp._pRefCnt), _pmtx(sp._pmtx)
{
addRef();
}
shared_ptr<T>& operator=(const shared_ptr& sp)
{
// 不同地址的同种类型资源
if (sp._pRefCnt != _pRefCnt)
// 或
// if (sp._ptr != _ptr)
{
release();
_pRefCnt = sp._pRefCnt;
_ptr = sp._ptr;
// 记得这里还要换锁
_pmtx = sp._pmtx;
addRef();
}
return *this;
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
int getcnt() const
{
return *_pRefCnt;
}
private:
T* _ptr;
int* _pRefCnt;
// 保护某个引用计数的锁 同样在构造函数里初始化
std::mutex* _pmtx;
};
}
再增加一个简易的weak_ptr,并不去提供它和shared_ptr相关联的东西,如shared_ptr引用了多少之类的:
namespace scu
{
template <class T>
class weak_ptr
{
public:
weak_ptr() : _ptr(nullptr) {}
weak_ptr(const weak_ptr<T>& wp)
: _ptr(wp._ptr) {}
weak_ptr(const shared_ptr<T>& sp)
: _ptr(sp.get()) {}
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.get();
return *this;
}
weak_ptr<T>& operator=(const weak_ptr<T>& wp) = default;
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
}
然后我们的循环引用问题就可以用自己的智能指针去看到并解决:
struct ListNode
{
int _val = 0;
scu::weak_ptr<ListNode> _next;
scu::weak_ptr<ListNode> _prev;
ListNode() = default;
ListNode(int val) : _val(val), _next(), _prev() {}
~ListNode()
{
cout << "~ListNode" << endl;
}
};
int main()
{
scu::shared_ptr<ListNode> n1(new ListNode(1));
scu::shared_ptr<ListNode> n2(new ListNode(2));
n1->_next = n2;
n2->_prev = n1;
return 0;
}
3.7 为智能指针定制删除器
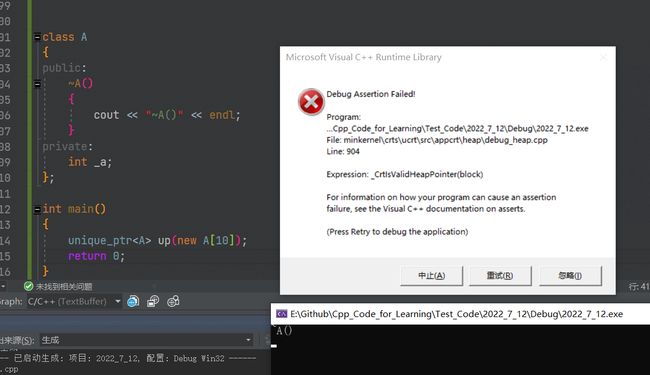
我们的资源不一定是new来的啊,也可能是new[]来的啊,还可能是malloc或者fopen(这都行)或者我自己的内存申请函数申请出来的,如果申请内存的函数与回收内存的函数不匹配使用,就有可能会报错。
标准库中,智能指针的底层默认使用delete,如果是new[]来的资源,就会出问题(还要有析构函数),如我们下面的一个场景:
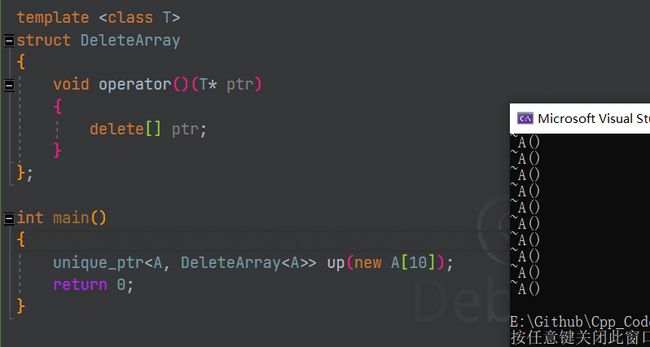
观察unique_ptr的标准文献,发现还有一种特殊的模板参数:定制删除器

定制删除器是一个可调用对象,我们用仿函数实现一个调用operator[]的默认删除器:
class A
{
public:
~A()
{
cout << "~A()" << endl;
}
private:
int _a;
};
template <class T>
struct DeleteArray
{
void operator()(const T* ptr)
{
delete[] ptr;
}
};
int main()
{
unique_ptr<A, DeleteArray<A>> up(new A[10]);
return 0;
}
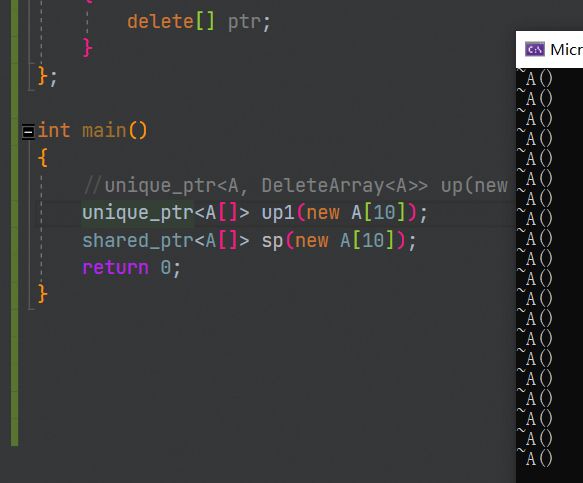
当然标准库为了我们方便使用,unique_ptr和shared_ptr都有new[]专属版本:
下面我们支持我们自己的unique_ptr增加定制删除器:
namespace scu
{
template <class T>
struct DefaultDel
{
void operator()(const T* ptr)
{
delete ptr;
}
};
template <class T, class D = DefaultDel<T>>
class unique_ptr
{
public:
unique_ptr(T* ptr) : _ptr(ptr) {}
~unique_ptr()
{
if (_ptr) D()(_ptr), cout << "unique_ptr已释放资源" << endl;
}
// 禁止拷贝 禁止赋值
unique_ptr(const unique_ptr& up) = delete;
unique_ptr<T, D>& operator=(const unique_ptr<T, D>& up) = delete;
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
}
class A
{
public:
~A()
{
cout << "~A()" << endl;
}
private:
int _a;
};
template <class T>
struct DeleteArray
{
void operator()(const T* ptr)
{
delete[] ptr;
}
};
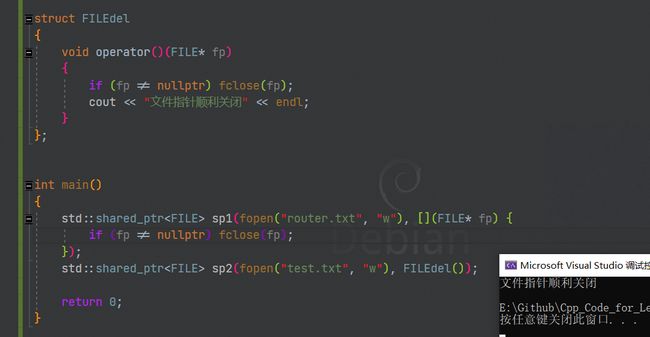
struct FILEdel
{
void operator()(FILE* fp)
{
if (fp != nullptr) fclose(fp);
cout << "文件指针顺利关闭" << endl;
}
};
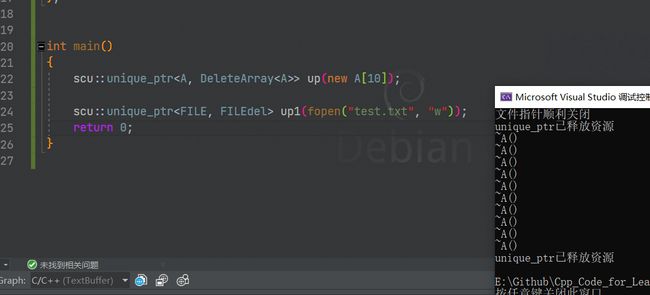
int main()
{
scu::unique_ptr<A, DeleteArray<A>> up(new A[10]);
scu::unique_ptr<FILE, FILEdel> up1(fopen("test.txt", "w"));
std::shared_ptr<FILE> sp2(fopen("router.txt", "w"), FILEdel());
return 0;
}
为什么说我们写的智能指针是阉割版本呢,标准库中,shared_ptr既可以通过模板参数指定删除器,也可以通过构造函数参数指定删除器,这样可以和lambda表达式很好的配合,而它之所以可以这样,是因为它实现了好几个版本的 shared_ptr,底层结构都是完全不同的,不然通过函数参数它怎么保存这个删除器呢?
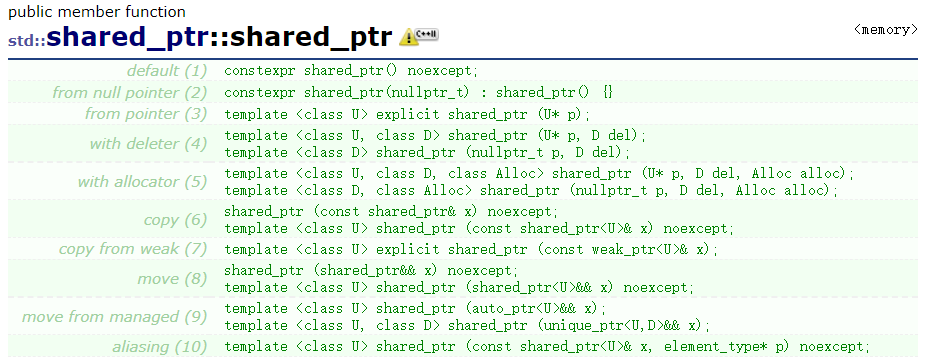
比如我们下面这个例子: