【深度学习】【语义分析】LogAnomaly:基于序列异常和定量异常的无监督学习的非结构化日志异常检测
LogAnomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs
文章目录
-
- LogAnomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs
-
- 【前言】
- 【0 摘要】
- 【1 介绍】
- 【2 背景】
- 【3 LogAnomaly设计】
-
- 【3.1 整体框架】
- 【3.2 template2vec】
- 【3.3 日志异常检测】
- 【3.4 两次连续训练之间的模板近似】
- 【4 评估】
-
- 【4.1 实验设置】
- 【4.2 整体表现】
【前言】
发表会议:International Joint Conference on Artifificial Intelligence(CCF-A)
发表时间:2019年
关键词:日志异常检测、template2vec、序列/定量异常
【0 摘要】
现有的自动日志异常检测方法使用索引而不是日志模板的语义,往往会导致误警报。在这项工作中,我们提出了LogAnomaly,一个将日志流建模为一个自然语言序列的框架,同时提出了template2vec,一种新颖的、简单而有效的语义信息提取方法,可以同时检测序列和定量日志异常,这是以往工作中没有做到的。此外,LogAnomaly可以避免周期模型重训练之间新出现的日志模板所引起的误报。
【1 介绍】
今天的大型服务正变得越来越灵活和复杂,而单一服务异常可能会影响数百万用户的体验,所以准确和及时的异常检测可以帮助运营商快速减轻损失。大规模服务通常生成日志,这些日志记录它们观察到的大量事件,以记录运行时的系统状态,所以日志是异常检测最有价值的数据源之一。
一个大规模的服务及其底层机器通常是由数百个开发人员/操作员来实现/维护的。通常,开发人员/操作员倾向于从局部的角度来确定异常日志,并不能从系统的整体角度去思考异常问题,因此很容易出错。此外,关键字匹配和正则表达式,以及基于显式关键字或结构特征检测单个异常日志,可以防止大部分日志异常被检测到,但是这些异常只能根据它们的日志序列来推断,其中包含多个违反常规规则的日志。

如上图所示,图中的前四个日志显示了两个正常的链接,如果我们应用关键字匹配来检测日志异常,那么包含关键字“down”的L1和L2都会触发误报。然而,这实际上是一个正常的事件,因此,我们需要一种根据日志序列的自动异常检测方法。
日志序列异常一般有两类:序列异常和定量异常。
程序通常根据固定的流来执行,而日志是由这些执行产生的一系列事件。我们说如果一个日志序列偏离了程序流的正常模式,则会发生顺序异常。同时,程序的执行有一定的恒定线性关系,这可以通过日志的定量关系来捕获,在不同的工作负载下应该总是正确的。我们说,如果日志集合中的这些关系被破坏,就会发生定量异常。
现有的自动异常日志序列检测方法可以大致可以分为两类:基于日志消息计数器的方法捕获定量异常,和基于深度学习的方法从日志序列中学习序列模式。而目前日志异常检测主要面临以下问题:
- 如果只使用日志模板索引,则可能会丢失有价值的语义信息。例如,一些模板在语义上是相似的,但在模板索引上却不同,而忽略这种相似性可能会导致误报。
- 通过训练生成新的日志模板需要进行手动反馈。
- 现有的方法不能同时检测序列异常和定量异常。
基于以上问题,我们提出了LogAnomaly,并通过以下方式来解决这些问题:
- 受词嵌入的启发,提出template2vec,来捕获包括同义词和反义词在内的语义信息。
- 设计一种无需操作员反馈就可以合并新的日志模板的机制。
- 提出LogAnomaly,一个端到端使用LSTM网络自动同时检测序列和定量异常的框架。
【2 背景】
解析日志的一种常见方法是从历史日志中挖掘和提取模板,然后将日志与模板进行匹配,如下图所示,日志L3和L6是相似的,它们的模板都是T3,即“Interface∗,change state to up”,它勾勒出了L3和L6所代表的事件。日志L3和L6的其余部分(即分别为“ae1”和“ae3”)是运行时参数。我们简单地采用FT-Tree,这是目前最先进的日志解析方法之一,在模板提取方面具有较高的精度,当新日志出现时可增量再训练。
对现有的日志异常检测方法进行分类有两个维度:1)检测顺序异常或定量异常;2)有监督或无监督。
对于那些用于检测定量异常的方法,定义一个时间或会话窗口,然后使用窗口内每个模板索引(无论序列)的计数作为异常检测的基础。监督方法可以使用各种算法来检测异常:逻辑回归和决策树。在检测定量异常的无监督方法中,通常通过检测一些挖掘的不变量(如count(T1)=count(T3))是否在窗口内成立。
【3 LogAnomaly设计】
【3.1 整体框架】

如上图所示,在LogAnomaly中,主要分为离线学习(offline learning)和在线检测(online detection)两部分。
在离线学习组件里面,首先利用FT-Tree从历史日志中提取模板,然后将历史日志与这些模板匹配,每个模板都是一组半结构化文本中的单词。然后通过template2vec将日志序列就被转换为模板向量序列,最后利用LSTM模型从日志序列中提取出序列特征和定量特征。离线学习会定期进行,例如每周进行一次,以便新出现的日志模板可以定期合并到新学习到的离线模型中。
在在线检测组件里面,首先确定,对于一个实时日志,它是否可以与一个现有的模板相匹配。如果是,那么我们将其转换为一个模板向量。否则,我们将根据模板向量的相似性,将“临时”模板向量“近似”为现有的模板向量。因此,每个实时日志都被匹配到一个模板向量,并且实时日志被转换为模板向量序列。基于离线学习组件中训练好的LSTM模型,LogAnomaly可以确定日志序列是否异常。
【3.2 template2vec】

在许多情况下,两个日志模板中具有相似或相同上下文的单词可以是反义词,这使得这两个模板非常不同,而word2vec并不能捕获单词的语义信息,受word2vec的启发,我们提出template2vec,它可以有效地将模板中的单词转换为单词嵌入向量,并通过结合单词向量来计算模板向量,如上图所示,一共有以下几个步骤:
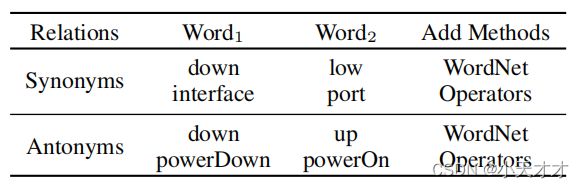
- 构造同义词和反义词集。如上图所示,通用的同义词和反义词可以在WordNet ,这是一个英语词汇数据库。但是,一些领域特定的同义词和反义词必须由基于域知识的操作符来添加。因此,我们首先在WordNet的模板中搜索单词的同义词和反义词。之后,操作符就可以更新同义词和反义词了。
- 生成词向量,利用dCLE模型。
- 计算模板向量。对于一个给定的模板,我们计算它的模板向量,即模板中单词的单词向量的加权平均值,来表示模板的分布。
【3.3 日志异常检测】
正常的日志自然会有一些顺序模式,对于一个给定的模板(向量)序列,如果没有发生异常,它的下一个模板是可以预测的。设 Ω = ( v 1 , v 2 , . . . , v n ) Ω = (v_1,v_2,...,v_n) Ω=(v1,v2,...,vn)是不同模板向量的整个集合,检测序列是 w w w个最新模板向量的滑动窗口,对于一个日志序列 S = ( s 1 , s 2 , . . . , s m ) S =(s_1,s_2,...,s_m) S=(s1,s2,...,sm),假设 S j = ( s j , s j + 1 , . . . , s j + w − 1 ) S_j=(s_j,s_{j+1},...,s_{j+w−1}) Sj=(sj,sj+1,...,sj+w−1)是它的子序列之一。
下图 (a)显示了模板的顺序模式。例如, [ v 1 , v 2 , v 3 ] [v_1,v_2,v_3] [v1,v2,v3]的下一个向量很可能是 v 1 v_1 v1。由于LSTM是一种流行的递归神经网络结构,已被证明可以对数据序列进行稳健预测,我们应用LSTM来学习日志的顺序模式。然后 S j S_j Sj的模板向量序列为 V j = ( V s j , v s j + 1 , . . . , v s j + w − 1 ) V_j =(V_{s_j},v_{s_{j+1}},...,v_{s_{j+w−1}}) Vj=(Vsj,vsj+1,...,vsj+w−1),其中 v s i v_{s_i} vsi为 s i s_i si的模板向量,和 v s i ∈ Ω v_{s_i}∈Ω vsi∈Ω。因此,在训练阶段,将 V j V_j Vj输入到 S j S_j Sj的LSTM模型中。
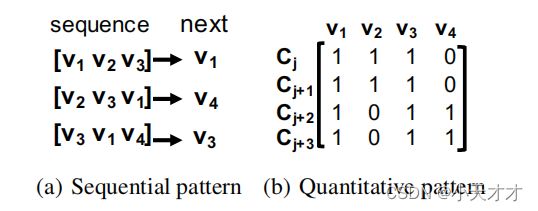
除了顺序模式外,模板(向量)序列也具有定量模式。通常,一个正常的程序执行有一些不变量,并且在不同的输入和工作负载下总是保持在日志中。例如,每个打开的文件最终都会在某个阶段被关闭。因此,指示“打开一个文件”的日志数应该等于在正常情况下显示“关闭一个文件”的日志数。日志中的这些定量关系可以捕获正常的程序执行行为。如果一个新的日志打破了某些不变量,我们可以确定在系统的异常过程中发生了异常。如上图(b)所示,其中 C i ( v k ) C_i(v_k) Ci(vk)是模板向量序列中 v k v_k vk的个数。
对于一个日志序列,我们根据其概率对下一个可能的模板向量进行排序,这是根据LSTM模型学习的,如果观察到的下一个模板向量包含在前 k k k个候选项中(或与它们足够相似),我们认为它是正常的。
【3.4 两次连续训练之间的模板近似】
在在线检测阶段,对于无法匹配任何现有模板的日志,我们首先应用FT-Tree从新日志中提取一个“临时”模板,并计算其模板向量。然后,我们根据模板向量之间的相似性,将这个“临时”模板向量与现有的模板向量进行匹配。请注意,模板近似的目的是处理两个连续的离线训练之间新出现的日志模板。
因此,在没有操作员干预的情况下,可以解决新型日志所带来的挑战。通过这种方式,不同的模板向量的数量保持不变,即使可以出现新的日志类型。
【4 评估】
【4.1 实验设置】
数据集

- BGL:BGL数据集包含4,747,963个日志。每个BGL日志被手动标记为异常或正常,348,460个日志被标记为异常。BGL数据集由Blue Gene/L超级计算机生成,该超级计算机由128K处理器组成,部署在劳伦斯利弗莫尔国家实验室(LLNL)。
- HDFS:HDFS数据集由来自超过200个Amazon EC2节点的11,175,629个日志组成。在HDFS系统中的程序执行,例如,写入一个文件,然后关闭它,通常涉及一个日志块。数据集中有575,061块日志,其中16,838个块被Hadoop域专家标记为异常。
在接下来的实验中,我们从任何一个数据集中,利用前80%(根据日志的时间戳)作为训练数据,其余的20%作为测试数据。此外,由于上述两个数据集都是手工标记的,所以我们将这些标签作为评估的基本事实。
基线
我们将LogAnomaly与四种无监督方法进行了比较,即LogCluster 、PCA、不变挖掘(IM)和Deeplog ,这些方法的参数都是最好的精度设置。
评价指标
- 精度、查全率和F1 score。
- TP是由该方法准确确定的异常日志(或HDFS数据集的块),TN是准确确定的正常日志(或HDFS数据集的块),如果方法确定一个日志(或块HDFS数据集)异常,但实际上是正常的,我们标签结果为FP,其余为FN。
其他设置
我们在LintelXeon2.40 GHz CPU和64G内存的Linux服务器上进行所有实验。FT-Tree被用于解析日志。我们用Python 3.6和Keras 2.1实现了日志异常和深度日志。至于日志聚类、PCA和不变挖掘,我们使用了在[He等人,2016]中实现的一个流行的开源工具包。
【4.2 整体表现】

|

|
其中w/o为without,作为与LogAnomaly的对比实验。