Evaluate the Malignancy of Pulmonary Nodules Using the 3D Deep Leaky Noisy-or Network 论文阅读
paper:https://arxiv.org/abs/1711.08324
源码:https://github.com/lfz/DSB2017
简介
简介——从CT扫描图像进行自动诊断肺癌需要两个步骤:检测所有可疑的病变(肺结节)以及评估整个肺部恶性程度。
目前大多数的研究主要集中于第一步,但是很少研究在第二部分。由于结节存在不能明确的指明得了癌症以及结节的形态跟肺癌有着复杂的联系,肺癌的诊断需要在每一个可疑的结节进行细致分析以及整合所有结节的信息。针对上述问题,我们提出了一个三维深度神经网络(3D deep neural network)用于解决这些问题。该模型由两个模块组成:
- 用于结节检测的3D region proposal network;
- 基于置信检测(the detection confidence)选出top-5结节并评估其癌症可能性,最后将此概率与Leaky noisy-or模型相结合评估患者患癌的可能性。
这两个模块共享相同的骨干网络(backbone network),一个修改的U-net网络。交替(alternately)训练两个模块缓解了(alleviated)由于训练集过少导致的过拟合问题。提出的模型在Data Science Bowl 2017 compettion 取得了第一名,已经开源了。
介绍
肺癌是最为普遍和最为致命的恶性肿瘤之一,像其他癌症一样,最好的方法就是早诊断早治疗。因此定期检查是有必要的。对于癌症的诊断,容量胸腔CT是一个普遍的成像工具。它显示了所有的组织,根据组织对X光的吸收情况。肺的损害被称为肺结节。结节通常具有与正常组织相同的吸收水平。但是拥有独特的形状。支气管(bronchus)和血管(vessels)是连续的管道系统,粗的在根上和细的在分支上(指的是支气管和血管),结节通常是球形的(spherical)和独立的。经验丰富的医生大约花费10分钟去彻底检查一位病人,因为部分结节是小的和难以发现的。此外,有很多结节亚型(subtypes)和不同亚型的癌症概率不同。医生根据结节的形状可以评估结节的恶性程度。但是准确率的高低取决于医生的经验,以及不同医生或许给出不同的预测。
计算机辅助诊断适用于此任务,因为电脑视觉模型可以以等质量的方式快速扫描任何地方,不受疲劳和情绪的影响。最近深度学习的进展已经开启。深度学习的最新进展使计算机视觉模型能够帮助医生诊断各种问题,在某些情况下,这些模型在医生面前表现出竞争性。
与一般的计算机视觉问题相比,肺癌自动诊断有几个困难。首先,结节检测是一种比二维目标检测更难的三维目标检测问题。由于GPU内存有限,二维目标检测方法直接推广到三维场景面临技术难题。因此,一些方法使用二维RPN网络在单个二维图像中提取,然后将它们结合生成三维proposals。更重要的是,标注3D数据通常要比标注2D数据困难得多,这可能会导致深度学习模型由于过度拟合而失败。其次,结节形状多样(图1),结节与正常组织的差异不明显。因此,在某些情况下,即使是经验丰富的医生也无法达成共识。第三,结节与癌症的关系比较复杂。结节的存在并不一定表明得了肺癌。对于多发结节的患者,应考虑所有结节,以推断癌症的可能性。换句话说,不像经典的检测任务和经典的分类任务,在这个任务中,一个标签对应几个对象。这是一个多实例学习(MIL)[11]问题,是计算机视觉中的一个难题。
为了解决这些困难,我们采取了以下策略。我们构建了一个3D RPN[12]来直接预测结节的边界框。3D卷积神经网络(CNN)结构使网络能够捕获复杂的特征。为了解决GPU内存问题,采用了patch-based的训练和测试策略。对模型进行端到端训练,以实现高效的优化。数据增强被用来对抗过度拟合。检测器的阈值设置得很低,这样所有可疑的结节都包括在内。然后选择前5个可疑结节作为分类器的输入。在分类器中引入了一个leaky noisy-or model[13],将前5个结节的分数结合起来。

图1:DSB数据集中的mudles示例。上图:整个切片。底部:放大图像
在概率图模型中,noisy-or model 是一种局部的因果概率模型[13]。它假设一个事件可以由不同的因素引起,而这些因素中的任何一个的发生都可以导致事件以独立的概率发生。这个模型的一个修改版本叫做leaky noisy-or module[13],假设事件有leaky probability即使没有任何因素发生。noisy-or model 适合这个任务。首先,当一个病例出现多个结节时,所有的结节都有助于最终的预测。其次,一个高度可疑的结节可以解释癌症病例,这是可取的。第三,当没有肿瘤可以解释癌症病例时,癌症可以归因于泄漏概率(leakage probability)。
分类网络也是一种三维神经网络。为了防止过度拟合,我们让分类网络共享检测网络的主干(绑定两个网络的骨架参数),并交替训练两个网络。广泛的数据增强也被使用。
我们在这项工作中的贡献总结如下:
1)据我们所知,我们为3D 目标检测提出了第一个容量的(volumetric)单级端到端CNN。
2 )我们建议将噪声门(nosiy-or gate)集成到神经网络中网络中解决多实例学习任务CAD。
我们在Data Science Bowl 2017年验证了该方法,并在1972个团队中获得了第一名。
论文的其余部分如下所示。第二节介绍了一些密切相关的工作。提出的方法在后面的章节中详细介绍。它由三个步骤组成:(1)预处理(第三节):将肺从其他组织中分离出来;(2)检测(第四节):发现肺内所有可疑结节;(3)分类(SectionV):对所有结节打分,结合其癌症概率,得到患者整体的癌症概率。第一步是经典的图像预处理技术和其他两部分(指的是检测和分类)通过神经网络。本研究的结果在第六节中提出。第七节以讨论的形式总结全文。
相关工作
A.一般目标检测
提出了多种目标检测方法,并对其进行了深入的研究。这些方法大多是为二维目标检测而设计的。一些最先进的方法有两个阶段(例如,Faster-RCNN[12]),其中在第一阶段提出了一些边界框(称为proposal)(是否包含对象),而在第二阶段进行类决策(proposal属于哪一类)。最近的方法有一个单独的阶段,在这个阶段中,边界框和类概率同时被预测(YOLO[14]),或者类概率被预测从default box,而不是proposal(SSD[15])。一般来说,单级方法比较快,两级方法比较准确。对于单类对象检测,不再需要两阶段方法中的第二阶段,方法退化为单阶段方法。
将前沿的2D物体检测方法扩展到3D物体检测任务(如视频中的动作检测和体积检测)是有局限性的。由于主流gpu的内存限制,一些研究使用2D RPN提取单个2D图像中的建议,然后使用一个额外的模块将2D提案结合到3D提案中[8,9]。类似的策略也被用于三维图像分割[16]。据我们所知,3D RPN尚未用于处理视频或容量数据。
B.结节检测
结节检测是典型的体积检测任务。由于其临床(clinical)意义重大,近年来受到越来越多的关注。该任务通常分为两个子任务[17]:提出proposal和减少假阳性,每个子任务都吸引了大量的研究。第一个子任务的模型通常从简单快速的3D描述符开始,然后用分类器给出许多proposals。第二个子任务的模型通常是复杂的分类器。2010年,Van Ginneken等人对六种传统算法进行了全面的回顾,并在包含55次扫描的ANODE09数据集上对它们进行了评估。在2011-2015年期间,开发了一个更大的数据集LIDC[18,19,20]。研究人员开始采用CNN来减少假阳性的数量。Setio等[21]采用了多视图CNN,而Dou等[22]采用了3D CNN来解决这一问题,并取得了比传统方法更好的结果。Ding et al.[9]采用2D RPN制作每一片的结节提案,采用3D CNN减少假阳性样本数量。2016年肺结核分析比赛(LUNA16)[23]举行。基于选定的LIDC子集。在本次比赛的检测轨迹中,大部分参赛者采用了[23]两阶段法。
C.多实例学习
在MIL任务中,输入是一个实例包。如果任何一个实例被标记为正数,则袋子被标记为正数。如果所有的实例都被标记为负数,那么这个包就被标记为负数。
许多医学图像分析任务是MIL任务,所以。在深度学习兴起之前,一些早期的作品已经有了已经在CAD中提出了MIL框架。Dundar等[24]。引入凸包表示多实例特性。应用于肺栓塞和结肠癌的检测。Xu等人从组织检测中提取了很多贴片对它们进行映像处理,并将它们作为多实例来解决冒号问题癌症分类问题。
为了将MIL合并到深度神经网络框架工作中,关键组件是将不同实例的in-formation组合在一起的层,称为MIL池[26]。一些MPL示例有:最大池层[27]、平均池层[26]、log-sum-exppooling层[28]、广义平均层[25]和noisy-or layer[29]。如果每个示例的实例数都是固定的,那么也可以使用特性连接作为MPL[30]。MPL可以用于组合特性级别[27,28]或输出级别[29]中的不同实例。
D.Noisy-or layer
噪声或贝叶斯模型(Noisy-or layer Bayesian)被广泛用于推断肝病[31]和哮喘病例[32]等疾病的概率。Heckerman[33]基于噪声门构建了一个多特征、多疾病诊断系统。Halpern和Sontag[34]提出了一种基于噪声模型的无监督学习方法,并在快速医学参考模型上进行了验证。
上述所有研究都将noisy-or model纳入贝叶斯模型。然而,noisy-or model和神经网络的整合是罕见的。Sun等人在深度神经网络框架中将其作为MPL,提高图像分类精度。Zhang等[35]将其作为提高目标检测精度的一种促进方法。

图二:结节直径的分布。(一)分布在DSB和LUNA数据集中。(b)的分布肿瘤患者和健康患者 的最大结节直径在DSB数据集中的人。
数据集和预处理
A.数据集
使用两个肺扫描数据集对模型进行训练,肺结节分析2016数据集(缩写为LUNA)和Date Science Bowl 2017训练集(缩写为DSB)。LUNA数据集包括888个由放射科医生标注的患者的1186个结节标签,而DSB数据集只包括每个受试者的二进制标签,表明该受试者在扫描后的一年内是否被诊断为肺癌。DSB数据集包括1397、198、506人(case)在训练、验证和测试集。我们在训练集中手工标注了754个结节,在验证集中标注了78个结节。
LUNA结节与DSB结节有明显差异。LUNA数据集有许多非常小的带注释的结节,这可能与癌症无关。根据医生的经验[36],结节小于6毫米通常不危险。然而,DSB数据集有许多非常大的结节(大于40mm)(图1中的第五个样本),DSB数据集中平均结节直径为13.68mm, LUNA数据集中平均为8.31 mm(图1)。2)。此外,DSB数据集在主支气管上有许多结节(图1中的第三个样本),这在LUNA数据集中很少发现。如果网络是经过训练的仅在LUNA数据集上,很难检测到在DSB数据集中的结节。缺了大结节就会导致癌症以错误的癌症预测为大结节的存在是癌症患者的标志(图2b)。应对这些问题是,我们从小于6毫米的地方移除小结节。LUNA标注并手工标注DSB中的结节。作者没有肺癌的专业知识诊断时,可以选择结节和手工标注增加相当大的噪音。下一阶段的模型(癌症)分类)被设计成对错误的检测是健壮的,这减少了对高度可靠的结节标签的需求。
B.预处理
整个预处理过程如图3所示。所有的原始数据首先转换成Hounsfield Unit(HU),这是描述放射性密度的标准定量标度。每个组织都有其特定的HU值范围,而这个范围对于不同的人来说是相同的(图3a)。
1 )掩模提取:CT图像不仅包含肺,还包含其他组织,有些可能呈球状,看上去像结节,为了排除这些干扰因素,最方便的方法是提取肺掩模,忽略检测阶段的所有其他组织。对于每个切片,用高斯滤波器(标准差= 1像素)过滤二维图像,然后以-600作为阈值进行二值化(图3b)。所有小于![]() 或偏心率大于0.99(对应某些高亮度径向成像噪声)的二维连通分量均为移除。然后计算得到的二元三维矩阵中的所有三维连通分量,只保留不接触矩阵角、体积在0.68 L到7.5 L之间的部分。
或偏心率大于0.99(对应某些高亮度径向成像噪声)的二维连通分量均为移除。然后计算得到的二元三维矩阵中的所有三维连通分量,只保留不接触矩阵角、体积在0.68 L到7.5 L之间的部分。
在这一步之后,通常只剩下一个与肺对应的二元成分(指的是肺部和其他组织区分开来了),但有时也会有一些分散注意力的成分。与这些分散注意力的成分相比,肺成分总是在图像的中心位置。对于每一个切片,我们计算它到图像中心(MinDist)和它的面积的最小距离。然后我们选择所有的切片> 6000![]() 的分量,计算平均值MinDist这些片。如果平均的MinDist高于62mm时,该组件被移除。剩下的然后将组成部分统一起来,表示lung mask(图3.c)。
的分量,计算平均值MinDist这些片。如果平均的MinDist高于62mm时,该组件被移除。剩下的然后将组成部分统一起来,表示lung mask(图3.c)。
在某些情况下,肺的顶部切片外部世界相连,这使得上面描述的过程无法将肺与外部世界空间分开。因此,需要先将这些切片删除,才能完成上面的工作处理工作。

图3:预处理过程。注意到结节贴在肺的外壁。(a)将图像转换为HU。(b)阈值化图像,(c)选择与肺对应的连通域,(d)分割左 右肺,(e)计算每个肺的凸包。(f)放大和合并两个掩模,(g)用掩模将图像相乘,用组织亮度填充掩模区域,将图像转换 为UINT8,(h)裁剪图像,修剪骨头的亮度。
2)凸包和扩张:在肺的外壁有一些结节。它们不包含在前面步骤中获得的mask中,这是不被允许的。为了使它们保持在mask内,一种方便的方法是计算mask的凸包。然而,直接计算面具的凸壳会包含太多不相关的组织(如心脏和脊柱)。所以肺面罩首先被分成两部分(大约与左右相对应)肺)前凸壳计算采用以下方法。
mask将被反复地腐蚀,直到它被分解成两个部分(它们的体积会相似),这两个部分是左右肺的中心部分。然后将这两个部件放大到原来的尺寸。它们与原始面罩的交汇处现在是两个肺的mask(图3 d)。对于每个掩模,大多数2D切片都用它们的凸包替换,以包含上面提到的那些结节(图)。3 e)。合成的掩模进一步膨胀了10个voxels包括一些周围的空间。得到一个完整的掩模通过统一两个肺的口罩(图3f)。
然而,一些肺下部的二维切片却有新月形(图4)。它们的凸包也可能包含在内许多不必要的组织。所以如果a的凸壳的面积。2D掩模比掩模本身的1.5倍大保留原掩模(图4e)。
3)灰度归一化:为了准备深度网络的数据,我们将图像从HU变换到UINT8。原始数据矩阵首先在[-1200,600]内剪切,然后线性变换为[0,255]。然后乘以上面得到的完整的掩模,掩模外面的所有东西都充满了170,这是普通组织的亮度。此外,对于前一步中膨胀生成的空间,所有大于210的值也用170替换。因为周围区域含有一些骨骼(高亮度组织),所以很容易被错误地归类为钙化结节(也是高亮度组织)。我们选择将170把骨头替换,使它们看起来像正常的组织(图3g)。该图像在所有三个维度中都被裁剪,因此每边的边缘都是10个像素(图3h)。(我:尽可能的将肺部进行前景提取,为下一步肺结节检测做铺垫)
3D CNN FOR Nodule Detection
3D CNN被设计用来检测可疑的结节。它是RPN的一个3D版本,使用一个修改过的U-net[37]作为骨干模型。由于该任务只需要分为两类(结节和非结节),所以预测的proposals直接作为检测结果使用,不需要额外的分类器。这类似于一级检测系统YOLO[14]和ssd[15]。这种结节检测模型简称为N- net,其中N代表结节。
A.patch-based input for training
对象检测模型通常采用基于图像的训练方法:在训练过程中,整个图像被用作模型的输入。然而,由于GPU内存限制,这对于我们的3D CNN来说是不可行的。当肺扫描的分辨率保持在一个很好的水平,即使是一个示例也会消耗超过主流的最大内存gpu。
为了解决这个问题,我们从肺扫描中提取小的3D patchs,分别输入到网络中。patch的大小为128×128×128×1(高×长×宽×通道,使用相同的符号在下面)。随机选择两种patch。首先,选择70%的输入,使它们包含至少一个结节。第二,30%的输入是从肺扫描中随机抽取的,可能不包含任何结节。后者的输入保证了足够的负样本的覆盖。
如果一个patch超出了肺扫描范围,它将被填充为170,与预处理步骤相同。结节目标不一定位于斑块的中心但是距离补丁边界的距离大于12像素(除了一些太大的结节)。
数据增强是用来缓解过度拟合问题的。这些补丁随机从左到右翻转,大小在0.8到1.15之间。其他的扩充,如轴交换和旋转也被尝试,但这是没有重要意义改进了
B.Network structure
检测器网络由U-Net[37]骨干和RPN输出层及其结构如图5所示。U-Net骨干网络使网络能够捕获多尺度信息,这是必要的,因为结节的大小变化很大。RPN的输出格式使网络能够直接生成proposals。
网络主干具有前馈路径和反馈路径(图5a)。前馈路径始于两个3×3×3卷积层与24通道。然后紧接着是四个3 d残差块[38]交叉四3 d max pooling(池大小是2×2×2和,步长等于2)。每个三维残差块(图5b)由三个残差单元[38]组成。残差单元的结构如图5b所示。前馈路径中的所有卷积内核有一个内核大小为3×3×3和1的填充。
反馈路径由两个反卷积层和两个组合单元组成。每个反卷积层的步长为2,核大小为2。每个组合单元连接一个前馈blob和一个反馈blob,并将输出发送到一个残差块(图5c)。在左边的组合单元中,我们将位置信息作为额外的输入引入(详细信息请参见第IV-C节)。特征映射相结合的单元大小32×32×32×131。紧随其后的是两个1×1×1的卷积与通道64和15分别导致的输出大小32×32×32×15。
四维张量的大小输出32×32×32×3×5。最后两个维度分别对应anchors和回归值。在RPN的启发下,网络在每个位置都有三个不同尺度的anchors,对应三个长度为10,30,60的边框分别为毫米。所以有32×32×32×3 anchor boxes。五个回归值(![]() )。第一个用sigmoid激活函数:,其他的不用激活函数。
)。第一个用sigmoid激活函数:,其他的不用激活函数。
C.位置信息
proposal的位置也会影响是否为结节,是否为恶性的判断,所以我们也会在网络中引入位置信息。对于每一个图像patch,我们计算它对应的位置裁剪,与输出特征图(32 32 32 3)一样大。位置裁剪有3个特征映射,对应于X、Y、Z轴的归一化坐标。在每个轴上,每个轴上的最大值和最小值分别归一化为1和-1,对应于分割后肺的两端。
D.损失函数
用(Gx、Gy、Gz、Gr)表示目标结节的真实的边界框(bounding box),用(Ax、Ay、Az、Ar)表示anchor的边界框,前三个元素表示盒子中心点的坐标,最后一个元素表示边的长度。通过联合(IoU)来确定每个anchor box的标签。对于IoU大于0.5和小于0.02的目标结节分别作为阳性和阴性样本处理。其他的则在训练的过程中被忽略。预测的概率和标签anchor box分别用 和p表示。注意,p∈{ 0,1 }(0为负样本,1为正样本。对于box的分类loss被定义为:
和p表示。注意,p∈{ 0,1 }(0为负样本,1为正样本。对于box的分类loss被定义为:
![]()
Bbox回归的标签生成:
dx=Gx−AxAr
dy=Gy−AyAr
dz=Gz−AzAr
dr=log(GrAr)
总的回归损失为:
![]()
![]()
其中S是smoothes L1-norm function。
最后网络的训练loss是:
L=Lcls+pLreg
这个方程表明,回归损失只适用于正样本,因为只有在这些情况下,p = 1。整体损失函数是一些选定anchor boxes的损失函数的平均值。我们使用正样本平衡和硬负挖掘进行选择(参见下一小节)
E.平衡正样本
对于一个大结节,有许多对应的正锚盒。为了降低训练样本之间的相关性,在训练阶段只随机选取其中一个样本。
虽然我们已经从LUNA上切除了一些非常小的结节,但结节大小的分布仍然高度不规则。小结节的数目比大结节的数目大得多。如果采用均匀抽样,经过训练的网络将会偏向小结节。这是不需要的,因为大结节通常比小结节更能显示癌症。因此,大结节的采样频率在训练集中增加,大于30mm和40mm的结节的采样频率分别比其他结节高2倍和6倍。
F.Hard negative mining(强制减少负样本的数量)
负样本比正样本多得多。虽然大多数负样本可以通过网络进行分类,但也有少数样本具有与结节相似的外观,很难进行正确的分类。针对这一问题,采用硬负挖掘技术作为目标检测的一种常用技术。我们在训练中使用了一个简单的在线版本的hard negative mining。
第一,通过将patch输入到网络中,我们获得了输出映射,它代表了一组具有不同可信度的proposed边界框。第二,随机抽取N个负样本形成候选池。第三,该池中的负样本按其分类置信分数进行降序排序,选取最上面的n个样本为hard negative。其他负样品被丢弃,不包括在损失的计算中。使用随机选择的候选池可以减少负样本之间的相关性。通过调整候选池的大小和n值,可以控制hard negative mining强度。
G.Image splitting during testing
网络训练完成后,整个肺扫描可作为输入,获得所有可疑结节。因为网络是完全卷积的,所以这样做很简单。但是对于GPU的内存限制是不可行的。即使网络在测试中比在训练中需要更少的内存,但需求仍然超过GPU的最大内存。为了克服这个问题,我们把肺扫描分割成几个部分(208×208×208×1每一部分),分别处理它们,然后合并结果。我们将这些分割保持在一个较大的范围内(32像素),以消除卷积计算中不需要的边界效应。
这一步将输出许多结节proposed {xi、yi、zi、ri、pi}其中xi、yi、zi代表提案的中心,ri代表半径,pi代表信心。然后执行非最大抑制(NMS)[39]操作,以排除重叠建议。基于这些建议,另一个模型用于预测癌症概率。
V. CANCER CLASSIFICATION
然后根据所检测到的结节,对发生癌症的概率进行评估。在N-Net中,每一个subject(案例)都会根据他们的信心分数选出五个proposals。作为一种简单的数据增强方法,在训练过程中,随机抽取建议。被选为结节的概率与它的置信分数成正比。但在测试过程中,前五个proposals被直接挑选出来。如果检测到的proposal的数量小于5个,则使用几个空白图像作为输入,因此仍然是5个。
由于训练样本的数量有限,建立一个独立的神经网络来实现这一点是不明智的,否则会发生过度拟合。另一种选择是重用在检测阶段训练的N-Net。
对于每一个选择的候选框(proposal),我们都要剪切一个96*96*96*1个patch,它的中心是结节(注意这个patch比检测阶段的输入要小),把它喂给N-Net,然后得到N-Net的最后一个卷积层,它的大小是。24*24*24*28。每个proposals的中央2*2*2个voxels被提取并进行了max-pooled,结果是一个128-D的特性(图6a)。为了从单个病例的多个结节中获得单分,我们探索了四种集成方法(见图6b)。(接下来的A,B,C,D,方法)
A. feature combining method(特征组合方法)
首先,前5个结节的特征都被输入到一个完全连接的层中,从而产生5个64-D特征。然后结合这些特性,通过max-pooling提供单个的64-D特性。然后将特征向量输入第二个全连通层,激活函数为sigmoid函数,得到病例的癌症概率(图6b左面板)。
这种方法可能会有用,如果存在一些非线性相互作用的结节。缺点是在集成步骤中缺乏可解释性,因为每个结节与癌症概率之间没有直接的关系。
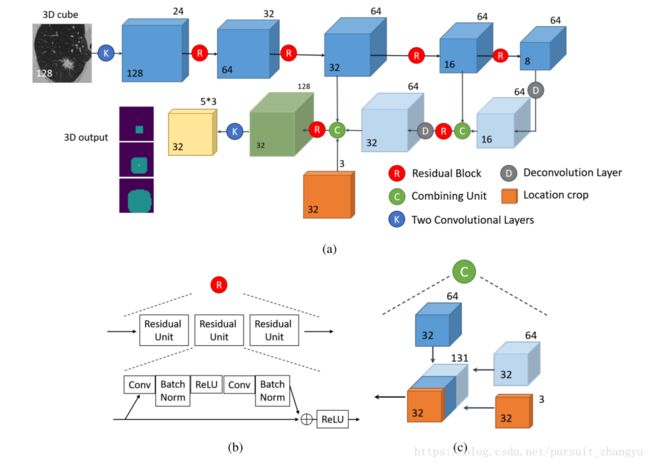
图5:结节检测网络。(a)整体网络结构。图中的每个立方体代表一个4D张量。图中只显示了两个维度。立方体内的数字表示空间大小(Height=Width=Length)。立方体外的数字表示通道的数量。(b)残差块的结构。(c)在(a)中左合并单元的结构。右合并单元的结构相似,但没有定位剪切。
B.MaxP method
所有前5个节点的特征都分别输入到同一两层感知器中,包含64个隐藏单元和一个输出单元。最后一层的激活函数也是sigmoid函数,它输出是每个结节的癌症概率。然后将这些概率的最大值作为这种情况的概率。
与特征组合方法相比,该方法为每个结节提供了可解释性。然而这种方法忽略了结节之间的相互作用。例如,如果一个病人有两个同时具有50%癌症概率的结节,医生会推断总体癌症概率远远大于50%,但模型仍会给出50%的预测。
C.Noisy-or method
为了克服上述问题,我们假设结节是独立的癌症病因,任何一个人的恶性肿瘤都会导致癌症。与最大概率模型一样,每个结节的特征首先被输入到一个双层感知器中,得到概率。最终的癌症概率为[13]:
![]()
Pi表示第i个结节的癌症概率
D.Leaky Noisy-or method
在噪声方法和MaxP方法中存在一个问题。如果受试者患有癌症,但检测网络漏掉了一些恶性结节,这些方法会将癌症的原因归为被检测到但为良性的结节,这将增加数据集中其他类似良性结节的概率。显然,这没有道理。我们引入一个假想的假瘤,并将Pd定义为其癌症概率[13]。最终的癌症概率为:
![]()
Pd是在训练过程中自动学习的,而不是手动调整。这个模型被用作我们的默认模型,叫做C- net (C代表case)。
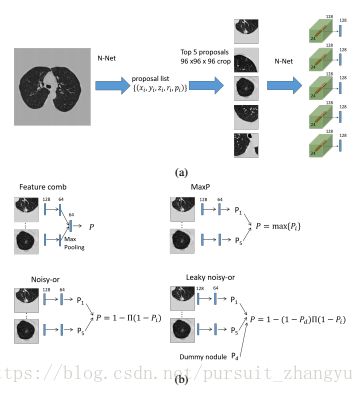
图6:案例分类器的说明。(a)得到proposals和proposals特征的流程。(b)不同的多节点信息集成方法。
E.训练步骤
用标准的交叉熵损失函数进行分类。由于内存的限制,预先生成每个病例的结节的边界框。分类器,包括共享特征提取层(N-Net部分)和集成层,然后在这些预先生成的边界框中进行训练。由于N-Net较深,三维卷积核的参数比二维卷积核多,但分类样本数量有限,模型往往会对训练数据的拟合过度。
为了解决这个问题,采用了两种方法:数据增强和交替训练。3D数据增强比2D数据增强更强大。例如,如果我们只考虑翻转和轴交换,在2D情况下有8个变量,而在3D情况下有48个变量。具体地说,采用了以下的数据增强方法:(1)随机翻转3个方向(2)在0.75和1.25之间随机调整大小,(3)以任何角度在三维中旋转,(4)向3方向移动,随机距离小于半径的15%。另一种常用的缓解过度的方法是使用一些适当的regulizer。在这个任务中,因为卷积层是由检测器和分类器共享的,所以这两个任务可以很自然地互相转换。所以我们在检测器和分类器上交替训练模型。
训练过程是相当不稳定的,因为批量大小只有2 / GPU,还有很多训练集的离群值。因此梯度剪裁是用于后期的训练,即如果梯度向量的l2范数大于1,这将是标准化为1。(有点问题)
网络中使用了批标准化(BN)[40]。但是在交替训练中直接应用它是有问题的。在训练阶段,在批处理中计算BN统计量(激活的平均值和方差),在测试阶段,使用存储的统计量(运行的平均统计量)。替代训练方案将使运行平均不适合分类器和检测器。首先,它们的输入样本不同:分类器的patch尺寸为96,检测器的patch尺寸为128。其次,贴片的中心一直是分类器的建议,但是图像是随机裁剪的。因此,对于这两个任务来说,平均统计数据是不同的,运行的平均统计数据可能位于中间点,并会在验证阶段影响它们的性能。为了解决这一问题,我们首先对分类器进行训练,使BN参数适合于分类。然后在交替训练阶段,这些参数被冻结,即在训练和验证阶段,我们使用存储的BN参数。
总之,培训过程有三个阶段:(1)把权重从训练有素的探测器和训练分类器在标准模式下,(2)训练分类器与梯度剪裁,然后冻结BN参数,(3)训练网络的分类和检测交替梯度剪裁和BN存储参数。这个训练计划对应一个表I中的A→B→E。
VI.结果
A.结节定位
由于我们的检测模块在训练过程中忽略了非常小的结节,所以LUNA16评价系统不适合对其性能进行评价。我们对DSB的验证集进行了性能评估。它包含198个病例的数据,并且有71个(7个小结节小于6毫米)的结节总数。自由响应工作特性曲线如图7a所示。1/ 8,1 / 4,1 /2、1、2、4、8次扫描的平均召回率为0.8562。
我们还调查了在选择不同的top-k数字时的召回情况(图7b)。结果表明,k = 5足以捕获大部分结节。
B.case classification
为了选择训练方案,我们重新安排了训练集和验证集,因为我们发现原始的训练和验证集有显著差异。使用原训练集的四分之一作为新的验证集,其余的与原验证集结合形成新的训练集。
VII.讨论
提出了一种基于神经网络的肺癌自动诊断方法。一个3D CNN被设计用来检测结节和leaky noisy-or model 评估每一个检测到的结节的癌症概率,并将它们结合在一起。整个系统在一个基准竞赛中在癌症分类任务上取得了很好的成绩。
该方法在医学图像分析中具有广泛的应用前景。许多疾病的诊断都是从图像扫描开始的。图中显示的病变可能与疾病有关,但关系不确定,与本文所研究的癌症预测问题的情况相同。leaky noisy-or model 可以用来整合来自不同病灶的信息来预测结果。它还减少了对高精度精细标签的需求。
将三维CNN应用于三维目标检测和分类面临两个难题。首先,当模型大小增长时,模型占用了更多的内存,所以运行速度、批处理大小和模型深度都是有限的。我们设计了一个较浅的网络,用图像块代替整张图像作为输入。其次,三维CNN的参数个数明显大于二维CNN,结构相似,因此模型容易对训练数据进行过度拟合。采用数据增强和交替训练的方法来解决这一问题。
有一些潜在的方法来提高所提模型的性能。最直接的方法是增加训练样本的数量:1700个病例太少,不足以涵盖所有结节的变异,而一个经验丰富的医生在他的职业生涯中会看到更多的病例。其次,合并结节的分割标签可能有用,因为研究表明,分割和检测任务的协同训练可以提高两项任务的性能。
虽然很多团队在这次癌症预测比赛中取得了不错的成绩,这项任务本身对临床有一个明显的限制:不考虑结节的增长速度。
事实上,生长迅速的结节通常是危险的。要检测生长速度,需要在一段时间内多次扫描患者,并检测所有结节(不仅是大结节,也包括小结节),并将其按时间排列。虽然本文提出的方法对小结节的检测精度不高,可以为此目的修改它。例如,可以添加另一个取消池层来合并更精细的信息并减少anchor的大小。