Flink容错机制介绍
Flink容错机制介绍
1.状态一致性
一致性实际上是"正确性级别"的另一种说法,是在成功处理故障并恢复之后得到的结果。
1-1.一致性级别
在流处理中,一致性可以分为3个级别
- 最多一次 - at-most-once
- 故障发生之后,计数结果可能丢失
- 至少一次 - at-least-once
- 计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算
- 严格一次 - exactly-once
- 系统保证在发生故障后得到的计数结果与正确值一致;既不多算也不少算
Flink可以做到既保证严格一次exactly-once,又具有低延迟和高吞吐的处理能力。
1-2.端到端状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源和输出到持久化系统。
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件
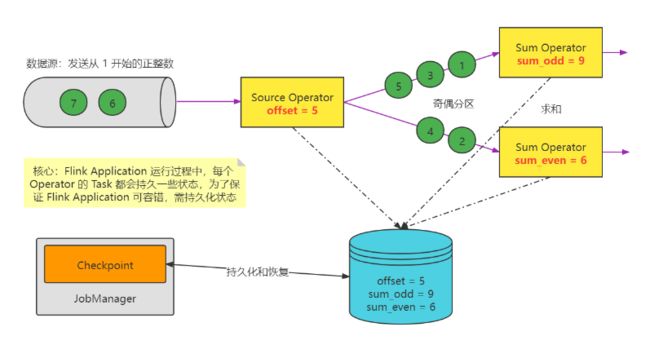
-
source 端
- 需要外部源可重设数据的读取位置。例如Kafka Source具有这种特性: 读取数据的时候可以指定offset
-
Flink 内部
- 使用checkpoint机制实现
-
sink 端
-
需要保证从故障恢复时,数据不会重复写入外部系统
-
幂等(Idempotent)写入
幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用
-
事务性( Transactional )写入
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
-
-

2.Checkpoint-检查点
2-1.Flink的检查点算法
在流处理中,我们可以借鉴电脑游戏中的游戏存档,下一次玩游戏读档接着玩的思路;把之前的计算结果做个保存,这样重启之后就可以继续处理新数据、而不需要重新计算。进一步地,我们知道在有状态的流处理中, 任务继续处理新数据,并不需要“之前的计算结果”,而是需要任务“之前的状态”。所以我们最终的选择,就是将之前某个时间点所有的状态保存下来,这份“存档”就是所谓的“检查点”。
checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。
快照实现算法:
- 简单算法——暂停应用, 然后开始做检查点, 再重新恢复应用
- Flink的改进Checkpoint算法,Flink的checkpoint机制原理来自"Chandy-Lamport algorithm"算法( 分布式快照算法 )的一种变体: 异步 barrier 快照( asynchronous barrier snapshotting )
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个检查点协调器CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作
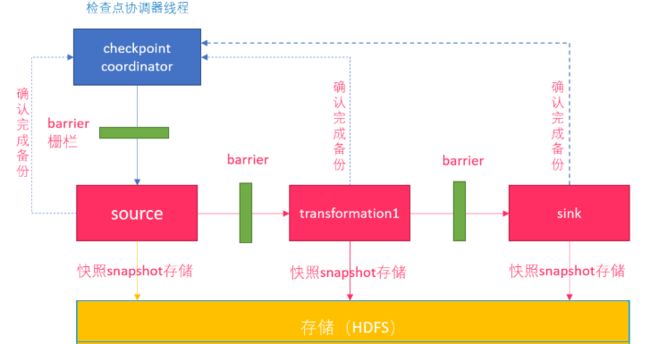
2-2.Barrier介绍
流的barrier是Flink的Checkpoint中的一个核心概念。可以理解成流数据中加入一个个分界线,多个barrier被插入到数据流中,然后作为数据流的一部分随着数据流动( 有点类似于Watermark )。这些barrier不会跨越流中的数据。
每个barrier会把数据流分成两部分: 一部分数据进入当前的快照 , 另一部分数据进入下一个快照。每个barrier携带着快照的id。barrier 不会暂停数据的流动,所以非常轻量级。在流中,同一时间可以有来源于多个不同快照的多个barrier,这个意味着可以并发的出现不同的快照。

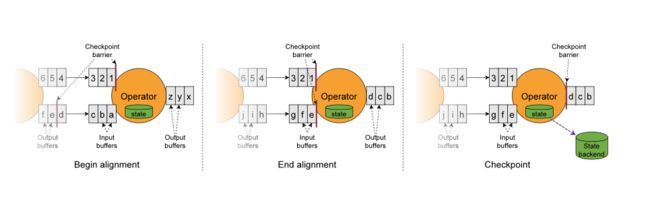
2-3.Flink检查点制作过程
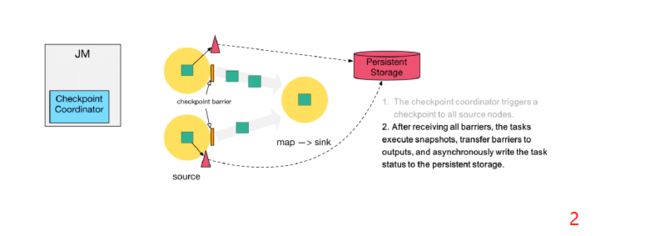
第一步:Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint。然后Source Task会在数据流中安插CheckPoint barrier
( 检查点协调器向所有source接入流节点,触发检查点。然后source任务会再数据流中安插检查点分界线 )

第二步:source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有进来的 barrier 才会执行相应的 Checkpoint
第三步:当 task 完成 state checkpoint后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator
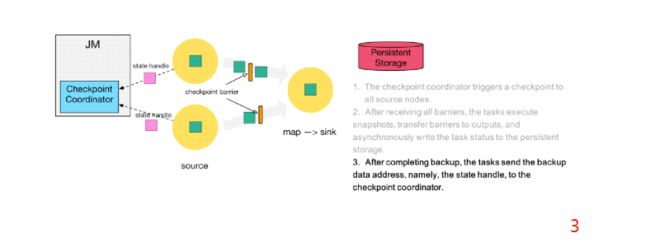
第四步:下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)
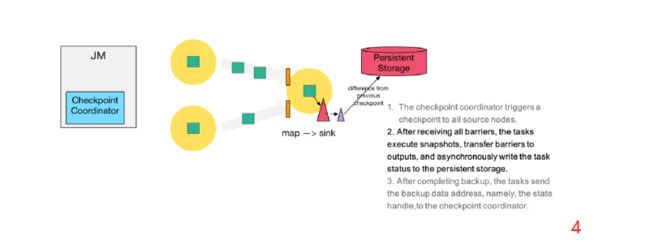
第五步:sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator
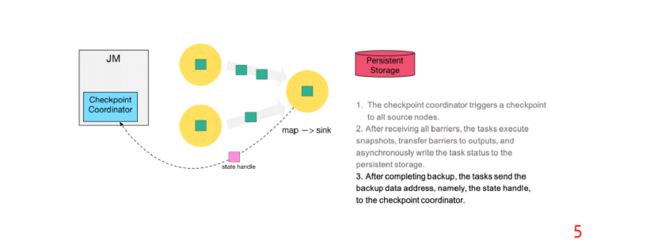
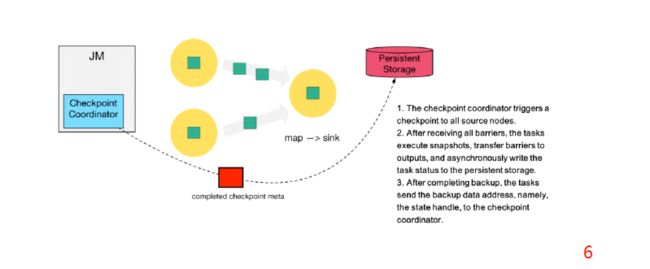
第六步:当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
2-4.严格一次语义——barrier对齐
在多并行度下,如果要实现严格一次,则要执行barrier对齐。
当 job graph 中的每个 operator 接收到 barriers 时,就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
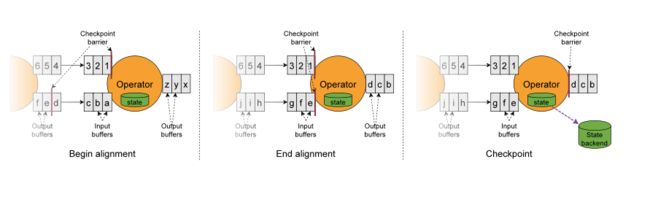
- 当operator收到数字流的barrier n时,它就不能处理(但是可以接收)来自该流的任何数据记录,直到它从字母流所有输入接收到 barrier n 为止。否则,它会混合属于快照 n 的记录和属于快照 n + 1 的记录。
- 接收到 barrier n 的流(数字流)暂时被搁置,从这些流接收的记录输入缓冲区,不会被处理。
- 图Begin alignment中的 Checkpoint barrier n之后的数据 123已结到达了算子,存入到输入缓冲区没有被处理,只有等到字母流的Checkpoint barrier n到达之后才会开始处理。
- 一旦最后所有输入流都接收到 barrier n,Operator 就会把缓冲区中 pending 的输出数据发出去,然后把 CheckPoint barrier n 接着往下游发送。这里还会对自身进行快照。
2-5.至少一次语义——barrier不对齐
严格一次语义—barrier介绍了barrier的对齐,如果barrier不对齐会怎么样则会重复消费,就是至少一次语义barrier不对齐。
如出现不对齐,在字母流的Checkpoint barrier n到达前,已经处理了1 2 3。等字母流Checkpoint barrier n到达之后,会做Checkpoint n。假设这个时候程序异常错误则重新启动的时候会Checkpoint n之后的数据重新计算。1 2 3 会被再次被计算,所以123出现了重复计算。
3.Savepoint原理
- Flink 还提供了可以自定义的镜像保存功能,就是保存点(
savepoints) - 原则上创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
- Flink不会自动创建保存点,因此用户(或外部调度程序)必须明确地触发创建操作
- 保存点是一个强大的功能。除了故障恢复外,保存点可以用于有计划的手动备份、更新应用程序、版本迁移、暂停和重启应用,等等
4.wcheckpoint和savepoint的区别
| Savepoint | Checkpoint |
|---|---|
| Savepoint是由命令触发,由用户创建和删除 | Checkpoint被保存在用户指定的外部路径中,flink自动触发 |
| 保存点存储在标准格式存储中,并且可以升级作业版本并可以更改其配置 | 当作业失败或被取消时,将保留外部存储的检查点 |
| 用户必须提供用于还原作业状态的保存点的路径。 | 用户必须提供用于还原作业状态的检查点的路径。 如果是flink的自动重启, 则flink会自动找到最后一个完整的状态 |
5.Kafka+Flink+Kafka 实现端到端严格一次
端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka读入、写入Kafka),各组件保证exactly-once语义方式
-
内部
- 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证部的状态一致性
-
source
- kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
-
sink
- kafka producer作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
source和sink运行流程:

- 某个checkpoint的第一条数据来了之后,开启一个 kafka 的事务( transaction ),正常写入 kafka 分区日志但标记为未提交,这就是“预提交” ( 第一阶段提交 )
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子状态后端会进行相应进行checkpoint,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据( 第二阶段提交 )
- 外部kafka关闭事务,提交的数据可以正常消费
6.Checkpoint代码示例
代码示例:
package com.zenitera.bigdata.state;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
import static org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.Semantic.EXACTLY_ONCE;
/**
* Kafka+Flink+Kafka 实现端到端严格一次
*/
public class Flink03_State_End2End {
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME", "wangting");
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
// 设置并行度
env.setParallelism(1);
// 开启checkpoint
env.enableCheckpointing(2000);
// 状态后端
env.setStateBackend(new HashMapStateBackend());
// checkpoint目录地址
env.getCheckpointConfig().setCheckpointStorage("hdfs://hdt-dmcp-ops01:8020/ck100");
// 设置语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// checkpoint并行数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// checkpoint最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(800);
// kafka source 配置
Properties sourceProps = new Properties();
sourceProps.put("bootstrap.servers", "hdt-dmcp-ops01:9092,hhdt-dmcp-ops02:9092,hdt-dmcp-ops03:9092");
sourceProps.put("group.id", "Flink03_State_End2End");
// 防止重复读取
sourceProps.put("isolation.level", "read_committed");
// kafka sink 配置
Properties sinkProps = new Properties();
sinkProps.put("bootstrap.servers", "hdt-dmcp-ops01:9092,hhdt-dmcp-ops02:9092,hdt-dmcp-ops03:9092");
sinkProps.put("transaction.timeout.ms", 15 * 60 * 1000);
SingleOutputStreamOperator<Tuple2<String, Long>> stream = env
.addSource(
new FlinkKafkaConsumer<String>("s1", new SimpleStringSchema(), sourceProps)
.setStartFromLatest()
)
.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
for (String word : value.split(" ")) {
out.collect(Tuple2.of(word, 1L));
}
}
})
.keyBy(t -> t.f0)
.sum(1);
stream
.addSink(new FlinkKafkaProducer<Tuple2<String, Long>>(
"default",
new KafkaSerializationSchema<Tuple2<String, Long>>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<String, Long> element,
@Nullable Long timestamp) {
return new ProducerRecord<>("s2", (element.f0 + "_" + element.f1).getBytes(StandardCharsets.UTF_8));
}
},
sinkProps,
EXACTLY_ONCE
));
stream.addSink(new SinkFunction<Tuple2<String, Long>>() {
@Override
public void invoke(Tuple2<String, Long> value,
Context context) throws Exception {
if (value.f0.contains("x")) {
throw new RuntimeException("异常");
}
}
});
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}