解码器LengthFieldBasedFrameDecoder
解码器LengthFieldBasedFrameDecoder, 从名字上可以猜测出来, 它是基于长度的解码器.
Netty从TCP缓冲区中读取字节, 把这些字节交给LengthFieldBasedFrameDecoder进行解码, 解码的操作是根据设定的规则, 根据规则, 从字节中解码出来有意义的数据, 然后把数据再交给后续的Handler处理.
接下来看下, 它是如何根据规则解码的.
 如上图, 从网络中读取到的数据是基于流的, 而且是有方向的. 然而数据是没有边界的, 不知道从哪儿到哪儿是一个完整的数据, 下一个数据又是从哪个到哪个. 因此应用层需要设定规则, 根据规则就可以知道数据的边界在哪儿.
如上图, 从网络中读取到的数据是基于流的, 而且是有方向的. 然而数据是没有边界的, 不知道从哪儿到哪儿是一个完整的数据, 下一个数据又是从哪个到哪个. 因此应用层需要设定规则, 根据规则就可以知道数据的边界在哪儿.

如上图, 便是根据设定的规则, 就可以’筛选’出来真正有意义的数据(data)在哪个. 而且允许每个data的长度是不一样大小.
那么就要说下这个规则是什么了. 规则是由4个主要的属性构成, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip. 通过一个数据块为例介绍这4个属性.
 如上图, 从红色箭头指向的位置开始读取数据.lengthFieldOffset表示长度字段的偏移量, 经过lengthFieldOffset之后, 箭头指向了下一个位置. 如果lengthFieldOffset=3, 那么箭头需要向右边走3个字节.
如上图, 从红色箭头指向的位置开始读取数据.lengthFieldOffset表示长度字段的偏移量, 经过lengthFieldOffset之后, 箭头指向了下一个位置. 如果lengthFieldOffset=3, 那么箭头需要向右边走3个字节.
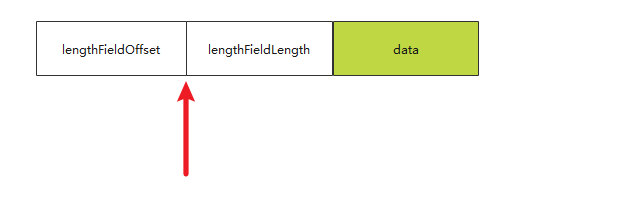 接下来, lengthFieldLength表示长度字段的长度(好绕口). 如果lengthFieldLength=4, 那么就会从上图红色位置向后读取4个字节, 把4个字节里面的内容作为真正data的长度. 而且lengthFieldLength的取值不是任意的, 它只能取值1,2,3,4,8. 具体原因后面的源码会说明.
接下来, lengthFieldLength表示长度字段的长度(好绕口). 如果lengthFieldLength=4, 那么就会从上图红色位置向后读取4个字节, 把4个字节里面的内容作为真正data的长度. 而且lengthFieldLength的取值不是任意的, 它只能取值1,2,3,4,8. 具体原因后面的源码会说明.
 如上图, 假如lengthFieldLength=4, 读取4个字节的内容是0x00000010(十六进制表示), 十进制就是16, 也就是说, 数据data的长度是16个字节. 但是这里稍等下, 需要介绍下一个关键属性.
如上图, 假如lengthFieldLength=4, 读取4个字节的内容是0x00000010(十六进制表示), 十进制就是16, 也就是说, 数据data的长度是16个字节. 但是这里稍等下, 需要介绍下一个关键属性.
lengthAdjustment表示长度调整. 调整什么呢? 还是要说下lengthFieldLength. lengthFieldLength里面的内容是16, 虽然这个16表示长度, 但是它是表示真正数据data的长度,还是表示整个的长度呢, 或者其他呢. 因此要想真正表示真正数据data的长度, 必须用lengthFieldLength的内容值+lengthAdjustment的值. 如果lengthAdjustment=-5, 也就是用16+(-5)=11, 即从上图红色位置继续向后读取11个字节才能真正的把数据读取完整, 读取少了或多了都不行.
到这里, 已经把一个完整的数据块读取完成了. 但是呢, 真正表示业务数据的内容是data部分.我们不想要前面的lengthFieldOffset和lengthFieldLength部分,这里就需要使用initialBytesToStrip. 它表示跳过多少字节. 如果initialBytesToStrip=7, 那么就是说要跳过7个字节, 把剩余部分传给下游的Handler继续处理.
 以上就是4个主要属性的解释, 从源码中拿一个具体的’案例’再温习下.
以上就是4个主要属性的解释, 从源码中拿一个具体的’案例’再温习下.

从最左边开始读取数据, lengthFieldOffset=1, 那么向后读取1个字节, lengthFieldLength=2, 向后读取2个字节, 读取到的内容是0x0010(十六进制), 十进制就是16, 由于lengthAdjustment=-3, 因此16+(-3)=13, 于是继续向后读取13个字节. 就会把0xFE和"HELLO, WORLD"这13个字节读取到. 到目前为止, 读取到的内容是0xCA0010FE和"HELLO, WORLD"共16个字节. 又initialBytesToStrip=3, 因此从16个字节的开头跳过3个字节, 跳过了0xCA0010这3个字节, 最后剩下0xFE和"HELLO, WORLD"传给了下游的Handler.
源码解读如下
Netty的源码位置 io.netty.handler.codec.LengthFieldBasedFrameDecoder
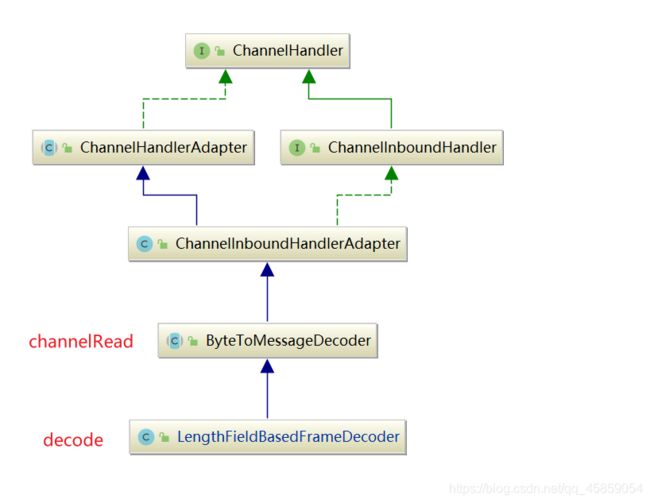 LengthFieldBasedFrameDecoder继承了ChannelInboundHandlerAdapter, 因此当Netty读取到网络数据之后,再向下传播数据的过程中, 会调用到ByteToMessageDecoder的channelRead方法, channelRead方法内部会调用decode方法.
LengthFieldBasedFrameDecoder继承了ChannelInboundHandlerAdapter, 因此当Netty读取到网络数据之后,再向下传播数据的过程中, 会调用到ByteToMessageDecoder的channelRead方法, channelRead方法内部会调用decode方法.
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 由于整个帧的长度 frameLength 大于 设定的maxFrameLength, 是需要跳过这个无效帧的.
// 之前已经跳过了一部分数据, 由于之前不够跳过, 现在又读取到了数据, 那么需要继续跳过剩下'欠'的数据
if (discardingTooLongFrame) {
discardingTooLongFrame(in);
}
// 在构造函数中定义了 lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength
// 它的意思是目前可以从网络中读取的实际字节数(in.readableBytes()) 小于 lengthFieldEndOffset , 无法处理 直接返回, 需要等待更多的数据.
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
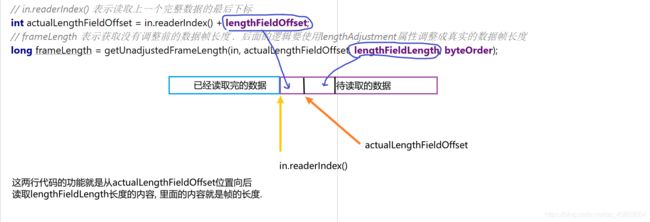
// in.readerIndex() 表示读取上一个完整数据的最后下标
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
// frameLength 表示获取没有调整前的数据帧长度 . 后面的逻辑要使用lengthAdjustment属性调整成真实的数据帧长度
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
// 如果读取到的frameLength 小于 0, 说明此数据有问题, 抛出异常
if (frameLength < 0) {
failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset);
}
// 调整frameLength长度 frameLength = frameLength + lengthAdjustment + lengthFieldEndOffset
// frameLength + lengthAdjustment 表示真实数据的长度
// 即这里的frameLength 就是整个数据的长度(包括真实数据).
frameLength += lengthAdjustment + lengthFieldEndOffset;
// 如果frameLength < lengthFieldEndOffset 那只能说明在上面的计算过程中, frameLength + lengthAdjustment < 0 了.
// frameLength + lengthAdjustment 表示真实数据的长度, 数据的长度怎么会小于0呢 因此抛异常.
if (frameLength < lengthFieldEndOffset) {
failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset);
}
// 如果整个数据的长度大于设定的最大值. 那么认为这是无效数据, 需要跳过这个无效数据
if (frameLength > maxFrameLength) {
// 跳过一个frameLength长度的数据
exceededFrameLength(in, frameLength);
return null;
}
// never overflows because it's less than maxFrameLength
int frameLengthInt = (int) frameLength;
// 表示目前可读的数据还不够一个帧, 那么直接返回
if (in.readableBytes() < frameLengthInt) {
return null;
}
// 比如一个即将要读取的帧长度=10, 可是initialBytesToStrip = 12, 跳过的字节比要读取的字节还大, 读取的字节还不够跳过的, 有问题 直接抛异常
if (initialBytesToStrip > frameLengthInt) {
failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip);
}
in.skipBytes(initialBytesToStrip);
// extract frame
// 读取实际有意义的业务数据
int readerIndex = in.readerIndex();
int actualFrameLength = frameLengthInt - initialBytesToStrip;
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}


已经添加注释的源码位置
https://github.com/infuq/netty-v4.1.42/blob/master/codec/src/main/java/io/netty/handler/codec/LengthFieldBasedFrameDecoder.java
个人站点
语雀
公众号