动态规划-构造最优二叉树的解路径_20230403
动态规划-最优二叉搜索树的解路径(算法导论)
- 前言
本文将探索递归的先序和后续对信息表达的影响,通过考察最优二叉搜索树的解roo[i][j]的解,我们可以分析先序和后续遍历之间的互相转换关系,以及为了转换,所付出的空间代价。
本文来源于《算法导论》的习题,习题是对课本中的最优二叉搜索树的解空间的具体表达。首先回顾一下,最优二叉搜索树的求解过程。给定特定的关键字,已知每个关键字的查询概率以及关键字之间未被查询到的概率。相对于常规的最优二叉搜索树,我们考虑了无法搜到到的概率。
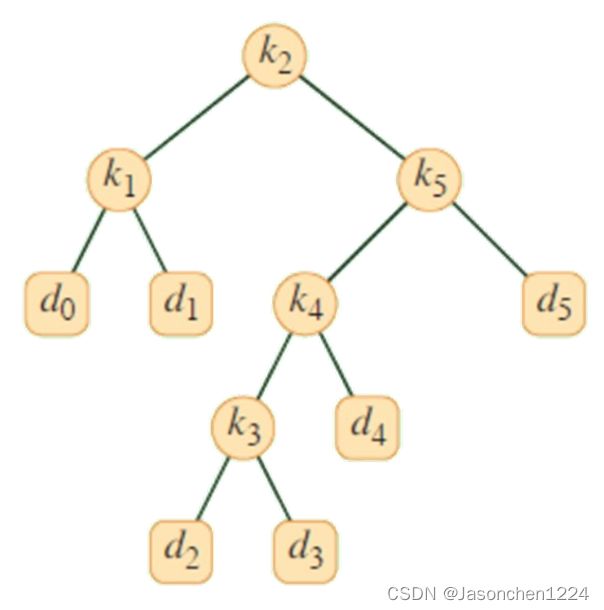
- 问题描述
通过动态规划计算,一致root[i][j]代表节点i和节点j之间的根节点,root数组形成上三角形式的查询矩阵。其中i代表起始关键字,j代表结束关键字. root[i][j]表达的数字为这两个关键字之间的根节点的位置。我们从下表中观察到,root[1][5]=2, 代表节点2为节点[1…5]之间的根节点,同理可以观察到节点[2…5]的根节点为4。
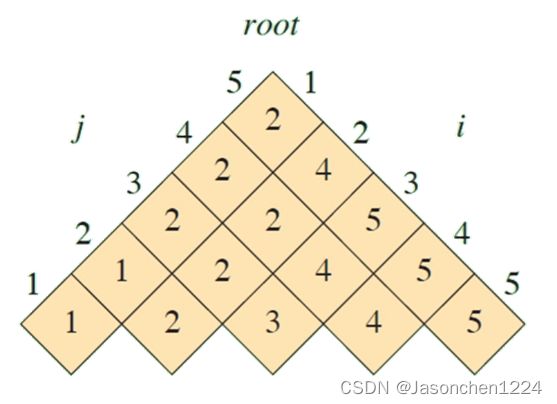
要求在roo[i][j]已知前提下,根据关键字打印出下列对应的二叉树结构:

- 问题求解
对于这个问题的求解,因为涉及到左右孩子和根节点,最原始和直接的理解就是利用前序、中序或后续遍历的形式,对客户需要的打印信息进行分类。那么就需要判断到底采用哪种顺序遍历的数据结构,其实每种形式都可以实现,最终的区别在于,如果我们提前提取和利用相关的信息,那么就可以称之为先序信息处理;如果递归发生后再对信息处理,那么称之为后续信息处理。后续和先序的本质差异在于,一个在于递归后利用现成信息,一个先对信息进行处理,然后再利用。
对于本问题,两个方法都适用,我们分别对其进行阐述。
3.1 先序处理信息
如果要先序处理信息,我们必须清楚左右根节点和目前待处理节点的相对位置,F(i,j,last)分为四种情况:
-
i
- 如果j
- 如果j>=last, 那么j就是根节点(last)的右子树
- 如果j
-
i>j,在种种情形下:
- 如果j
- 如果j>last,那么d(i-1)就是last的右子树,此时d(i-1)也代表叶子节点,表示某两个关键字之间的信息未被搜索到的概率
- 如果j
分析到这里,实际上递归方程在纸面上就呼之欲出,左右摇摆的二叉树肯定是所需要的二叉树结构。同时在前序中做好判断条件,根绝上述四种不同的情形,那么就可以打印出 题干要求的对应答案。
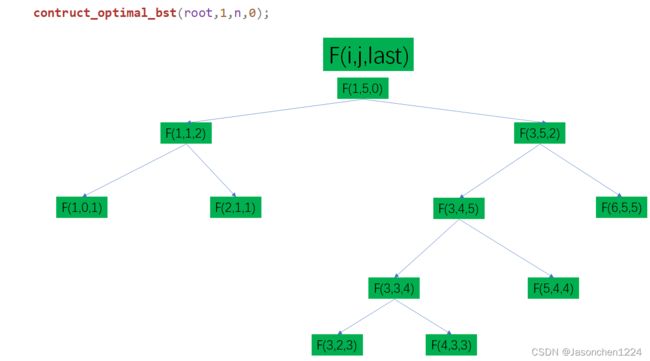
对函数作进一步分析,函数第一个关键字root保留[i]和[j]连续关键字之间的根节点信息,参数i表示起始节点序列号,参数j为结束节点序列号,值得关注的是命名为last的参数,它保留根节点的序列号,总的根节点的根节点并不存在,所以在函数入口前赋值last=-1。
整体函数采用前序遍历的形式,按照上述四类情形,分别进行不同的打印操作。
值得一提的是,对于遍历的赋值,每次都需要把last赋值为root[i][j],以便在下次的前序遍历过程中保留根节点的具体序列号。
void contruct_optimal_bst(int (*root)[N + 2], int i, int j, int last)
{
if(i>j)
{
if (j < last)
{
printf("d%d is the left child of k%d\n", i - 1, last);
}
else
{
printf("d%d is the right child of k%d\n", i-1, last);
}
return; //if i>j, it indicates there is no action to take(no print)
}
if(last==-1)
{
printf("k%d is the root of tree\n",root[i][j]);
}
else if(j<last)
{
//a[i...j] is located in the left side of the last node
//j will act the new 'root' node
// last is the previous the root node
printf("k%d is the left child of k%d\n",root[i][j],last);
}
else
{
printf("k%d is the right child of k%d\n", root[i][j], last);
}
contruct_optimal_bst(root,i,root[i][j]-1,root[i][j]);
contruct_optimal_bst(root,root[i][j]+1,j,root[i][j]);
return;
}
上述遍历最终会形成一颗递归二叉树,对递归二叉树中的i,j及last信息的比较,就可以给出有效的二叉树的信息。假定有5个关键字,我们可以勾勒出递归二叉树的具体形式。
3.2 混合order 处理信息
前文提过,如果采用多种次序对信息进行处理,也不失为一种有效方式。这种条件下,往往需要提前对信息进行挖掘,以便能提前进行对应信息的打印。
为了方便问题的阐述,我们先上代码,后作具体的分析。
递归函数与上一个函数类似,最大区别在于没有保存根节点的信息,参数root保留连续两个节点之间的根节点,参数i为起始编号,参数j为结束编号,其中n为常数,为总的节点数量。
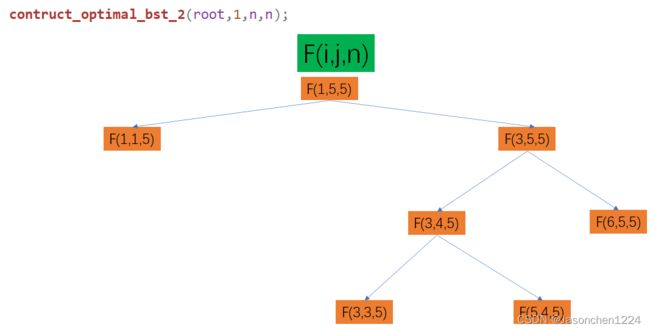
本操作结合先序、中序和后序三类方式进行遍历,由于未保存根节点信息,所以需要预先判定i与root[i][j]-1的关系,以及root[i][j]+1与j之间的关系。
void contruct_optimal_bst_2(int (*root)[N + 2], int i, int j,int n)
{
if(i==1 && j==n)
{
printf("k%d is the root\n",root[i][j]);
}
if(i<j) //start the recursive action with pre-order and post-order traversal method
{
if (i <= (root[i][j] - 1))
{
printf("k%d is the the left child of k%d\n", root[i][root[i][j] - 1], root[i][j]);
}
contruct_optimal_bst_2(root,i,root[i][j]-1,n);
if((root[i][j] + 1)<=j)
{
printf("k%d is the the right child of k%d\n", root[root[i][j] + 1][j], root[i][j]);
}
contruct_optimal_bst_2(root, root[i][j] +1,j,n);
}
if(i==j) // it has nothing to do with the recursive, just check the situation of dn
{
printf("d%d is the the left child of k%d\n", i-1, i);
printf("d%d is the the right child of k%d\n", i, i);
}
if(i>j)
{
printf("d%d is the the right child of k%d\n", j, j);
}
return;
}
遍历形成的二叉树与第一个先序遍历类似,由于剪枝原因,叶子节点更少。
- 小结
对中间信息的处理起始不改变二叉树的遍历过程,人为定义先序、中序和后序只是对过程中信息处理的时间不同罢了,它并不影响递归树的整体过程和流程。
参考资料
- 《Introduction to algorithm, 4ed》
- 15.5 Optimal binary search trees - CLRS Solutions (walkccc.me)