4-1MongoDB 复制集 & 分片
目录
4-1MongoDB 复制集 & 分片
第一关:MongoDB 架构
复制集
分片
复制集与分片的区别:
第二关:MongoDB 复制集搭建
配置文件设置
1、数据存放位置;
2、日志文件;
3、配置文件
4、配置文件启动命令(在命令行中输入):
配置主从节点
1、进入端口号为27018的进行配置,连接数据库:
2、选择数据库 admin;
3、输入配置要求如下:
4、使用 rs.initiate(config)进行初始化:
5、使用 rs.status() 查看状态。
验证复制集同步
1、连接主数据库:
2、连接从数据库:
切换 Primary 节点到指定的节点
1、先进入主节点中进行操作:
2、查看目前的节点状态:
编程测试代码:
第三关:
配置文件设置
config 节点
1、配置启动节点服务:
2、连接 route 节点:
route 节点
1、配置启动节点服务:
2、连接上 route 节点:
3、添加分片:
4、查看集群的状态:分片摘要信息、数据库摘要信息、集合摘要信息等;
分片验证
1、连接 route 节点:
2、对集合使用的数据库启用分片:
3、添加索引:
4、分片:
5、插入10万条数据:
6、再次运行 sh.status()
7、去各个节点查看数据分布情况:
4-1MongoDB 复制集 & 分片
第一关:MongoDB 架构
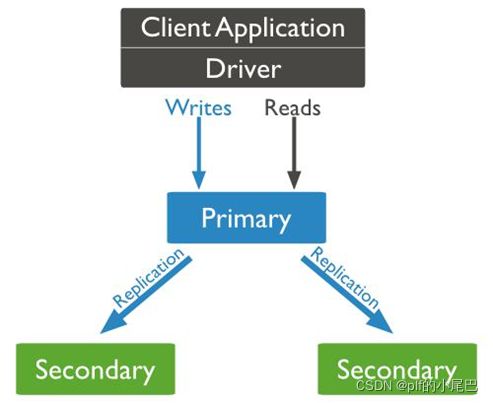
复制集
复制集由一个主服务器和多个副本服务器构成,通过复制讲数据的更新由主服务器推送到其他副本服务器上,在一定的延迟后,达到每个mongoDB实例维护相同的数据集副本
复制集优点:
- 备份数据 (数据冗余)
数据库的数据只有一份的话是极不安全的,一旦数据所在的电脑坏掉,我们的数据就彻底丢失了,所以要有一个备份数据的机制。
- 故障自动转移
部署了复制集,当主节点挂了后,集群会自动投票再从节点中选举出一个新的主节点,继续提供服务。而且这一切都是自动完成的,对运维人员和开发人员是透明的。当然,发生故障了还是得人工及时处理,不要过度依赖复制集,万一都挂了,那就连喘息的时间都没有了。
- 在某些特定的场景下提高读性能 (读写分离)
副本集可以将读取请求分流到所有副本上,以减轻主节点的读写压力
默认情况下,读和写都只能在主节点上进行。 下面是 MongoDB 的客户端支持5种复制集读选项:
-
- primary :默认模式,所有的读操作都在复制集的主节点进行的;
- primaryPreferred :在大多数情况时,读操作在主节点上进行,但是如果主节点不可用了,读操作就会转移到从节点上执行;
- secondary :所有的读操作都在复制集的从节点上执行;
- secondaryPreferred :在大多数情况下,读操作都是在从节点上进行的,但是当从节点不可用了,读操作会转移到主节点上进行;
- nearest :读操作会在复制集中网络延时最小的节点上进行,与节点类型无关。
分片
分片(sharding)是指将数据库拆分,使其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。通过一个名为 mongos 的路由进程进行操作,mongos 知道数据和片的对应关系(通过配置服务器)。
什么时候使用分片:
- 机器的磁盘不够用了,使用分片解决磁盘空间的问题;
- 单个 mongod 已经不能满足写数据的性能要求,通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源;
- 想把大量数据放到内存里提高性能,通过分片使用分片服务器自身的资源。

- Shard :用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组个一个 replica set 承担,防止主机单点故障;
- Config Server :mongod 实例,存储了整个 ClusterMetadata,其中包括 chunk 信息;
- Query Routers :前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
复制集与分片的区别:
分片是每个节点存储数据的不同片段,副本集是每个节点存储数据的相同副本
第二关:MongoDB 复制集搭建
配置文件设置
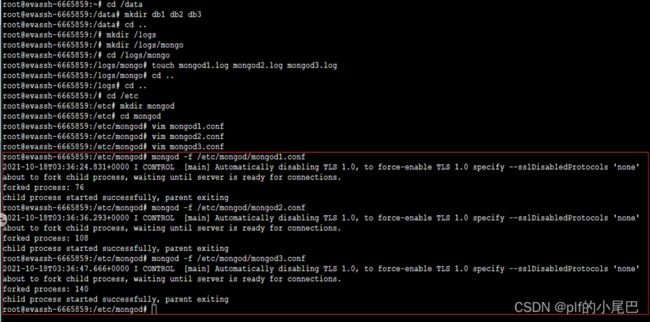
要启动三个 mongodb 服务,要准备三个数据存放位置,三个日志文件,三个配置文件
1、数据存放位置;
在 /data 路径下创建文件夹 db1、db2 和 db3 来存放三个服务的数据。
cd /data
mkdir db1 db2 db32、日志文件;
在 /logs 路径下创建文件夹 mongo 存放日志文件 mongod1.log、mongod2.log 和 mongod3.log(文件不用创建,到时候会自动生成,但路径即文件夹必须提前创建好)。
cd ..
mkdir /logs
mkdir /logs/mongo
cd /logs/mongo
touch mongod1.log mongod2.log mongod3.log3、配置文件
在 /etc/mongod 路径下新建三个配置文件,使用配置文件启动 mongod 服务(在之前的实训中我们都是用命令启动的)。
cd
cd /etc
mkdir mongod
cd mongodvim mongod1.confmongod1.conf 内容如下:
port=27018 #配置端口号
dbpath=/data/db1 #配置数据存放的位置
logpath=/logs/mongo/mongod1.log #配置日志存放的位置
logappend=true #日志使用追加的方式
fork=true #设置在后台运行
replSet=YOURMONGO #配置复制集名称,该名称要在所有的服务器一致
vim mongod2.confmongod2.conf 内容如下:
port=27019 #配置端口号
dbpath=/data/db2 #配置数据存放的位置
logpath=/logs/mongo/mongod2.log #配置日志存放的位置
logappend=true #日志使用追加的方式
fork=true #设置在后台运行
replSet=YOURMONGO #配置复制集名称,该名称要在所有的服务器一致
vim mongod3.confmongod3.conf 内容如下:
port=27020 #配置端口号
dbpath=/data/db3 #配置数据存放的位置
logpath=/logs/mongo/mongod3.log #配置日志存放的位置
logappend=true #日志使用追加的方式
fork=true #设置在后台运行
replSet=YOURMONGO #配置复制集名称,该名称要在所有的服务器一致
4、配置文件启动命令(在命令行中输入):
mongod -f /etc/mongod/mongod1.conf
mongod -f /etc/mongod/mongod2.conf
mongod -f /etc/mongod/mongod3.conf测试结果如下图所示:
配置主从节点
三个端口的服务全部启动成功后,需要进入其中一个进行配置节点。
设置27019为 arbiter 节点。
1、进入端口号为27018的进行配置,连接数据库:
mongo --port 27018;2、选择数据库 admin;
use admin3、输入配置要求如下:
config = {
_id:"YOURMONGO",
members:[
{_id:0,host:'127.0.0.1:27018'},
{_id:1,host:'127.0.0.1:27019',arbiterOnly:true},
{_id:2,host:'127.0.0.1:27020'},
]}4、使用 rs.initiate(config)进行初始化:
rs.initiate(config)
具体效果如图所示:

5、使用 rs.status() 查看状态。

验证复制集同步
在主数据库插入数据,然后去从数据库查看数据是否一致。
1、连接主数据库:
mongo --port 27018;
use test
db.person.insert({name:'王小明',age:20})
2、连接从数据库:
mongo --port 27020;从库查询数据需要设置 slaveOk 为 true;
use test
rs.slaveOk(true)
db.person.find()
至此复制集搭建完成,主数据库的数据的更新后,从数据库的数据也会同步更改,一旦主数据库挂掉,从数据库可自动变为主数据库,极大地保障了数据的安全,这也是搭建复制集的必要性。
切换 Primary 节点到指定的节点
1、先进入主节点中进行操作:
mongo --port 270182、查看目前的节点状态:
rs.conf() #查看配置
rs.status() #查看状态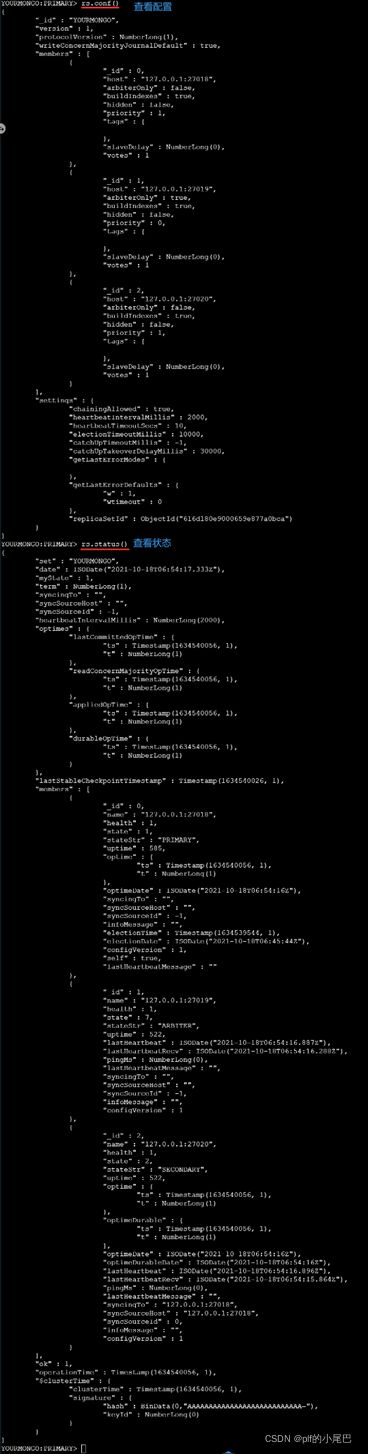
其中 priority : 是优先级,默认为 1,优先级 0 为被动节点,不能成为活跃节点。优先级不为 0 则按照由大到小选出活跃节点。
因为默认的都是1,所以只需要把给定的服务器的 priority 加到最大即可。让27020成为主节点,操作如下:
现进入目前的主节点进行操作如下:
cfg=rs.conf()
cfg.members[2].priority=2 #修改priority,members[2]即对应27020端口
rs.reconfig(cfg) #重新加载配置文件,强制了副本集进行一次选举,优先级高的成为Primary。在这之间整个集群的所有节点都是secondary
rs.status()结果如下图所示:

编程测试代码:
mkdir db1
mkdir db2
mkdir db3
cd ~
mkdir /logs
cd /logs
mkdir test
cd ~
cd /etc
mkdir test
cd test
vi ./mongod1.conf
port=20001
dbpath=/data/test/db1
logpath=/logs/test/mongod1.log
logappend=true
fork=true
replSet=YOURMONGO
vi ./mongod2.conf
port=20002
dbpath=/data/test/db2
logpath=/logs/test/mongod2.log
logappend=true
fork=true
replSet=YOURMONGO
vi ./mongod3.conf
port=20003
dbpath=/data/test/db3
logpath=/logs/test/mongod3.log
logappend=true
fork=true
replSet=YOURMONGO
mongod -f /etc/test/mongod1.conf
mongod -f /etc/test/mongod2.conf
mongod -f /etc/test/mongod3.conf
mongo --port 20001
use admin
config={_id:"YOURMONGO",members:[{_id:0,host:'127.0.0.1:20001'},{_id:1,host:'127.0.0.1:20002',arbiterOnly:true},{_id:2,host:'127.0.0.1:20003'}]}
rs.initiate(config)第三关:
同复制集一样,我们要准备目录存放我们的数据和日志:(步骤与第二关一样)
配置文件设置
config 节点
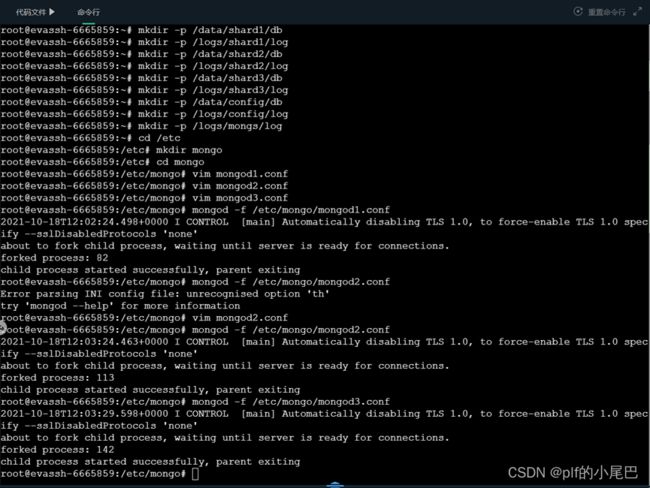
1、配置启动节点服务:
mongod --dbpath /data/config/db --logpath /logs/config/log/mongodb.log --port 10004 --configsvr --replSet cs –fork
2、连接 route 节点:
mongo localhost:10004
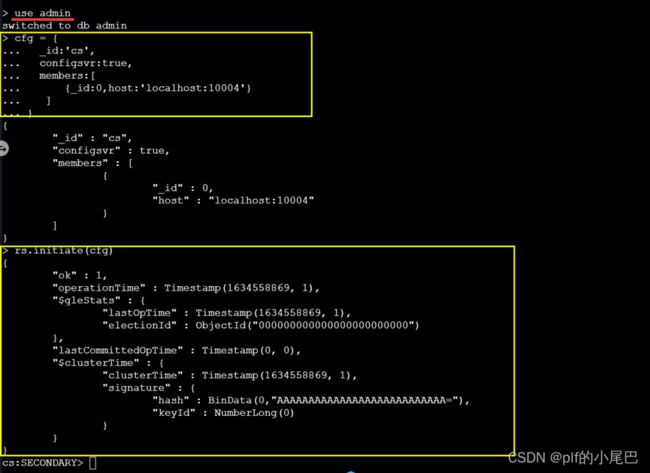
输入以下命令:
use admin
cfg = {
_id:'cs',
configsvr:true,
members:[
{_id:0,host:'localhost:10004'}
]
}
rs.initiate(cfg)运行效果如图设置成功:
route 节点
1、配置启动节点服务:
mongos --configdb cs/localhost:10004 --logpath /logs/mongs/log/mongodb.log --port 10005 --fork2、连接上 route 节点:
mongo localhost:100053、添加分片:
sh.addShard('localhost:10001')
sh.addShard('localhost:10002')
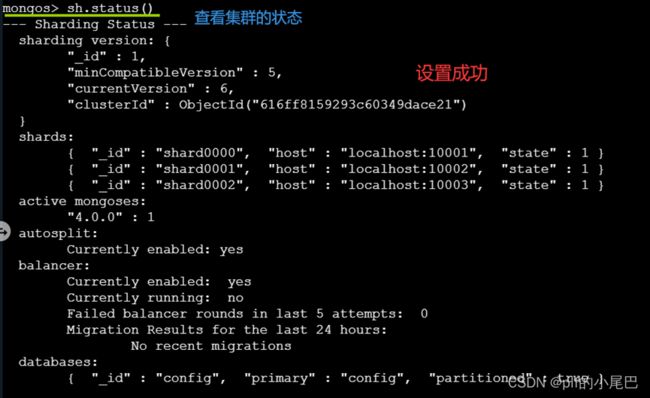
sh.addShard('localhost:10003')4、查看集群的状态:分片摘要信息、数据库摘要信息、集合摘要信息等;
sh.status()运行效果如图设置成功:
分片验证
1、连接 route 节点:
mongo localhost:10005;数据量太小可能导致分片失败,这是因为 chunksize 默认的大小是 64MB( chunkSize 来制定块的大小,单位是 MB ),使用以下代码把 chunksize 改为 1MB 后,插入数据,便可以分片成功。
use config
db.settings.save( { _id:"chunksize", value: 1 } )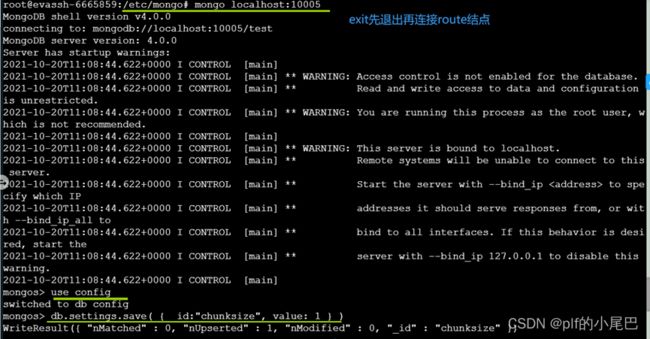
2、对集合使用的数据库启用分片:
sh.enableSharding("test")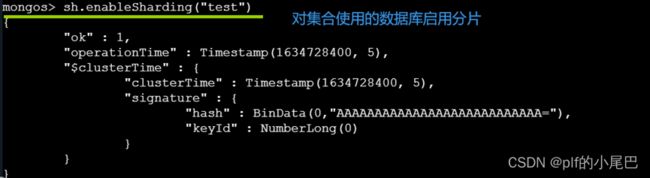
3、添加索引:
db.user.ensureIndex({ "uid" : 1})
4、分片:
sh.shardCollection("test.user",{"uid" : 1})
5、插入10万条数据:
use test
for(i=0;i<100000;i++){db.user.insert({uid:i,username:'test-'+i})}6、再次运行 sh.status()
如图显示了分片的情况。

7、去各个节点查看数据分布情况:
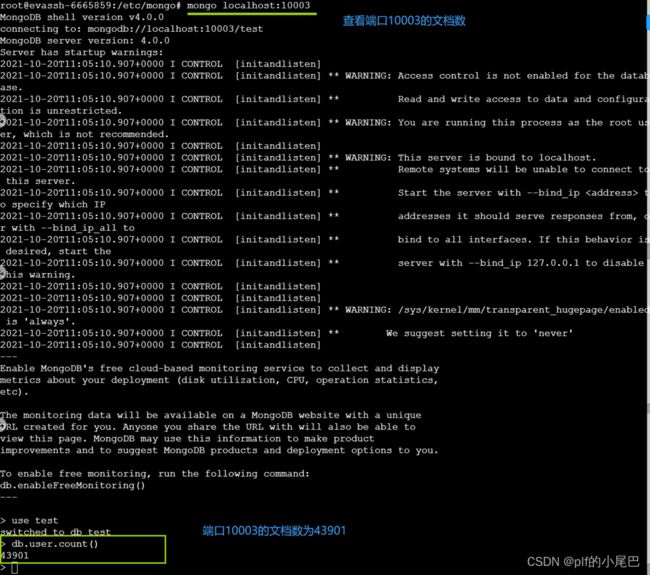
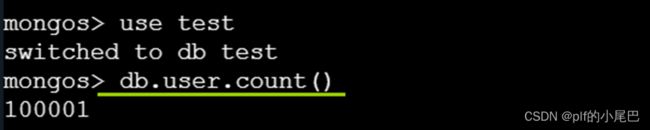
端口10005的文档总数为100001条数据
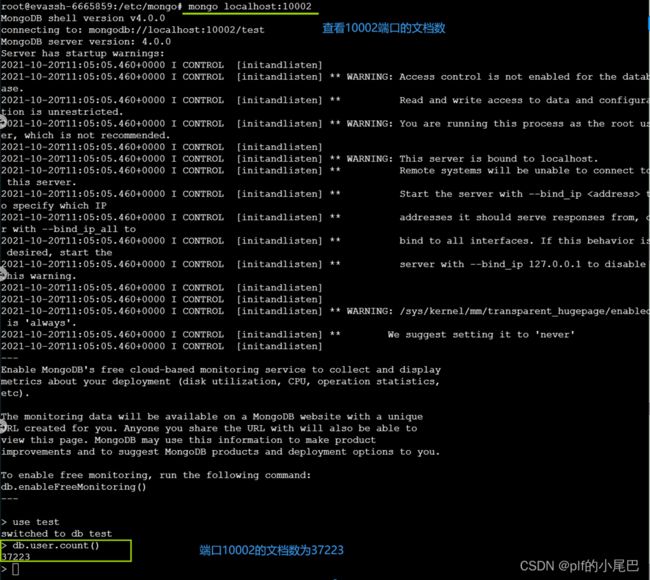
其他三个端口数据分别为:18877+37223+43901=100001
端口10001的文档总数为18877条数据

端口10002的文档总数为37223条数据
端口10003的文档总数为43901条数据