【论文笔记】Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learn
文章目录
- 【论文笔记】 Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning
-
- Abstract
- I. INTRODUCTION
- II. RELATED WORK
-
- Non-prehensile manipulation
- Grasping
- Pushing with grasping
- III. PROBLEM FORMULATION
- IV. METHOD
-
- A. State Representations
- B. Primitive Actions
- C. Learning Fully Convolutional Action-Value Functions
- D. Rewards
- E. Training details
- F. Testing details
- V. EXPERIMENTS
-
- 实验目标
- A. Baseline Methods
- B. Evaluation Metrics
- C. Simulation Experiments
-
- Comparisons to Baselines
- Challenging Arrangements
- No Pushing Rewards?
- Shortsighted Policies?
- D. Real-World Experiments
-
- Random Arrangements
- Challenging Arrangements
- Novel Objects
- VI. DISCUSSION AND FUTURE WORK
【论文笔记】 Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning
Abstract
【研究背景】熟练的机器人操作得益于**非可抓动作(如“推”动作)和可抓动作(如“抓取”动作)**之间复杂的协同作用:推可以重新排列杂乱的物体,为手臂和手指(夹持器)腾出空间;同样,抓握可以帮助移动物体,使推动动作更加精确,不受碰撞。
【研究内容】证明了通过无模型的深度强化学习,可以从零开始发现和学习这些推抓协同效应。
【具体技术路线】方法包括如下点。
- 训练两个完全卷积的网络,从视觉观察映射到动作:一个推断了推动对末端执行器方向和位置的密集像素级采样的效用(the utility of pushes for a dense pixel-wise sampling of end-effector orientations and locations),而另一个推断了抓取的同样的效用。
- 这两个网络都是在 Q Q Q-学习框架中共同训练的,并且完全由试错进行自监督学习。其中奖励函数设计,是由成功的抓取中提供的。
- 我们的策略学习能够进行抓取的推动动作,同时可以利用过去的推动学习抓取。
【实验设置】模拟和真实场景中的 picking 实验
【实验指标】grasping success rates (抓取成功率) picking efficiencies (拾取效率)
【实验效果】系统可以快速学习复杂的行为,即使是在混乱的情况下;并在训练后,获得比基线更好的性能。能够泛化到新物体上。
【链接】http://vpg.cs.princeton.edu
I. INTRODUCTION
-
研究推抓协同的意义?
虽然已经有相当多的研究致力于推动和抓取规划,但它们主要是孤立地研究的。
将推动和抓取策略结合起来进行顺序操作是一个相对未被探索的问题。
-
前人关于推抓协同都做了哪些工作?
-
对于推这个动作:传统上研究的是精确控制物体的姿态。
在推握和抓握之间的许多协同作用中,推起着松散定义的作用。(任务不明确,push for what?)
例如分离两个物体,在一个特定区域创造空间,或打破一组物体。
对于基于模型的或数据驱动的方法,这些目标很难定义或设计奖励函数。
model based 方法论文名字:(此处 model based 概念与 RL 方向的 model based 不同)
- Mechanics and planning of manipulator pushing operations. (1986)
- Planar sliding with dry friction part 1. limit surface and moment function. (1991)
- Feedback control of the pusher-slider system: A story of hybrid and under actuated contact dynamics. (2016)
data-driven 方法论文名字:
- A probabilistic data-driven model for planar pushing. (2017)
- Deep visual foresight for planning robot motion. (2017)
- Policy transfer via modularity. (2017)
-
许多成功的学习抓取策略的方法,最大限度地提高了从已学习的经验或由诱导抓取稳定性指标。
没有认识到如何计划将抓握和推结合在一起的动作序列,每一个动作都是孤立学习的。
从已学习的经验习得技能 的方法论文:
- Supersizing self-supervision: Learning to grasp from 50 k k k tries and 700 robot hours
https://blog.csdn.net/m0_48948682/article/details/125422884
- Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching.
由诱导抓取稳定性指标习得技能 的方法论文:
- High precision grasp pose detection in dense clutter
- Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics.
-
通过利用特定领域的知识,成功地开发了基于监督学习的推送抓取策略的硬编码启发式学习
它们限制了推动和抓握之间的协同行为类型。
- A planning framework for non-prehensile manipulation under clutter and uncertainty
-
-
针对前人的不足,本文做了哪些工作?
-
通过自监督的试错来学习联合推动和把握策略。
推动动作只有在实现抓取的条件下才有用。
这与之前定义启发式或硬编码目标的方法相反。
-
通过一个深度网络端到端训练我们的策略。
该网络接受视觉观察并输出潜在的预期回报(以 Q Q Q 值的形式)。
关节策略选择 Q Q Q 值最高的动作,即,使当前/未来抓取的预期成功最大化的一个。
这与明确地感知单个物体并基于手工设计的特征规划行动形成对比。
-
为了使在真实机器人上的训练易于处理,将动作空间简化为一组末端执行器驱动的运动原语
-
将该任务表述为一个像素级的标记问题。
其中每个图像像素和图像方向对应于在场景中该像素的三维位置上执行的一个特定的机器人运动原语(推动或抓取)。推时,这个位置表示推运动的起始位置;抓握时,平行夹持器抓握过程中两个手指之间的中间位置。
我们训练一个完全卷积网络(FCN)来将场景的图像作为输入,并推断出所有像素的未来预期奖励值——从而对场景中所有可见表面执行机器人运动原语。这种机器人原始动作的像素级参数化,我们称之为全卷积动作值函数,使我们能够在不到几个小时的机器人时间内,在单个机器人手臂上训练有效的推动和抓取策略。
-
-
这样的工作具有哪些效果?
- 我们证明了训练端到端深度网络是可能的,以获取通过经验相互受益的互补的推动和抓取策略。
- 推动策略扩大了抓取成功的场景布置,并且这两种策略同时产生了与对象的复杂交互。
II. RELATED WORK
Non-prehensile manipulation
许多模拟物理运动学方法依赖于在实践中不太可能成立的建模假设。物体表面的非均匀摩擦分布,是导致现实世界中,摩擦建模推动解决方案预测不足的首要因素。
最近的方法已经探索了 data driven 的算法来学习推动的动力学特性,但许多这些工作主要集中于一次执行一个对象的稳定推动。在特定对象、收敛到最优策略等方面存在困难。
Grasping
在实际系统中,部署这些方法的一种常见方法是,从已知的三维对象模型的数据库中预计算抓取,并在运行时使用点云对它们进行标记索引,以进行对象姿态估计。
位姿估计方法通常假设有物体形状、姿态、动力学和接触点的知识——这些信息是非结构化环境中的新物体很少知道的信息。
数据驱动方法探索了训练**模型无关(model-agnostic)**的深度抓取策略的前景,这些策略通过利用学习到的视觉特征来检测抓取,而不明确使用特定对象的知识(即形状、姿态、 动力学特性)。
Pushing with grasping
Dogar 等人的开创性工作,提出了一个用于推动抓取的鲁棒规划框架,以减少抓取的不确定性,以及一个额外的运动基元:扫动,以在混乱中绕过障碍物。框架中的策略在很大程度上是基于启发式搜索的。相比之下,本文提出的方法是由数据驱动的,并通过自我监督进行在线学习。
Dogar 论文:
A planning framework for non-prehensile manipulation under clutter and uncertainty
其他方法探索无模型(model-free)规划,通过推到将运动物体移动到目标位置,这更有利于预先设计的抓取算法——其行为通常是手工制作的、固定的和众所周知的。然而,试图为数据驱动的模型无关的抓取策略**(最优行为来自经验)**定义类似的目标变得不那么清楚,因为这些策略随着时间的更多数据不断学习、变化和适应行为。
相关方法论文:
Policy transfer via modularity
Automated construction of robotic manipulation programs
Boularias 提供了一个管道,将图像分割成物体,提出推动和抓取动作,为每个动作提取手动调整的特征,然后执行具有最高预期奖励的动作。他们的方法分别对感知和控制策略进行建模(而不是端到端),并依赖于基于模型的模拟来预测被推物体的运动,并推断其对未来抓取的好处。相比之下,我们用端到端深度网络训练感知和控制策略;我们对对象的形状或动力学特性(无模型)不做任何假设,我们证明了我们的范式适用于许多对象的各种测试用例(高达30+),并且能够快速推广到新的对象和场景。
Learning to manipulate unknown objects in clutter by reinforcement.
III. PROBLEM FORMULATION
利用异策略的 Q Q Q 学习来训练一个贪婪的确定性策略,通过最大化 Q Q Q 函数来执行策略
δ t = ∣ Q ( s t , a t ) − y t ∣ = ∣ Q ( s t , a t ) − ( R a t ( s t , s t + 1 ) + γ Q ( s t + 1 , arg max a ′ ( Q ( s t + 1 , a ′ ) ) ) ) ∣ \begin{split} \delta_{t}&=|Q(s_t,a_t)-y_t|\\ &=|Q(s_t,a_t)-(R_{a_t}(s_t,s_{t+1})+\gamma Q(s_{t+1},\arg\max\limits_{a^{\prime}}(Q(s_{t+1},a^{\prime}))))| \end{split} δt=∣Q(st,at)−yt∣=∣Q(st,at)−(Rat(st,st+1)+γQ(st+1,arga′max(Q(st+1,a′))))∣
IV. METHOD
概述我们的系统和 Q Q Q 学习范式。我们的机械臂在一个由静态安装的RGB-D相机观察到的工作空间上工作。可视化3D数据被重新投影到正交RGB-D高度图上,作为当前状态 s t s_t st 的表示。然后,这些高度图被输入两个全连接卷积神经网络——一个 Φ p \Phi_{p} Φp 推断像素级 Q Q Q 值(用热图 heat map 可视化),用于右侧的推动高度图;另一个 Φ g \Phi_g Φg 用于水平抓取高度图。每个像素表示执行原语的不同位置。这是重复的16个不同的旋转的高度图,以解释不同的推动和抓取角度。这些全连接卷积神经网络共同定义了我们的深度Q函数,并同时进行了训练。

A. State Representations
为了计算这个高度图,我们从固定安装的相机(眼在手外)捕获RGB-D图像,将数据投影到3D点云上,并在重力方向上向上反向投影,以构建具有**颜色(RGB)和底部高度(D)**通道的高度图图像表示。
高度图的边缘是根据智能体的工作空间的边界来预定义的。在我们的实验中,这个区域覆盖了一个 0.44 8 2 0.448^{2} 0.4482 米的桌面表面。由于我们的高度图的像素分辨率为 224 × 224 224\times 224 224×224,因此每个像素在空间上代表智能体工作空间中的一个 2 × 2 m m 2\times 2mm 2×2mm 的三维空间垂直列。
B. Primitive Actions
运动基元做了定义:
a = ( ϕ , q ) ∣ ϕ ∈ { push , grasp } , q → p ∈ s t a=(\phi,q)|\phi\in\{\text{push},\text{grasp}\},q\rightarrow p\in s_{t} a=(ϕ,q)∣ϕ∈{push,grasp},q→p∈st
将每个动作参数化为一个运动原始行为 ϕ \phi ϕ(例如,推动或抓取),在三维位置 q q q 处执行;
q q q 是从表征状态 s t s_t st 的高度图图像像素 p p p 的投影。
-
Pushing: Q Q Q 表示在 k = 16 k = 16 k=16 方向上 10 c m 10cm 10cm 推动动作的起始位置。
推动的轨迹是直的。在我们的实验中,它是用一个闭合的两个手指的夹持的尖端来物理执行的。
-
Grasping: Q Q Q 表示自上而下平行夹持器抓握的中间位置。在一次抓握尝试中,两个手指试图移动 3 3 3 厘米(在重力方向)。
在这两个原语中,机器人手臂的运动规划都是通过稳定的、无碰撞的逆解运动学求解器自动执行的。
C. Learning Fully Convolutional Action-Value Functions
全连接卷积神经网络 Φ p \Phi_p Φp 和 Φ g \Phi_g Φg 共享相同的网络架构:在 Image Net 上预训练的两个并行的121层Dense Net,然后是通道连接和2个额外的1×1卷积层,与非线性激活函数(ReLU)和空间批归一化交错,然后双向上采样。
一个 Dense Net 通道将高度图的颜色通道(RGB)作为输入,而另一个将高度图的通道克隆深度通道(通过减去平均值和除以标准差进行标准化)作为输入。
为了简化面向学习的推握和抓握运动原语,通过将输入高度图 s t s_t st 旋转 k = 16 k = 16 k=16 方向( 22. 5 ∘ 22.5^{\circ} 22.5∘的不同倍数)来考虑不同的方向,然后只考虑旋转高度图中的水平推(向右)和抓取。因此,每个全连接卷积神经网络的输入是 k = 16 k = 16 k=16 旋转的高度图,总输出是32个 Q Q Q 值的像素级映射(16用于不同方向的推动,16用于不同方向的抓取)。使 Q Q Q 函数最大化的动作是所有32个像素级映射中Q值最高的原语和像素。
arg max a t ′ Q ( s t , a t ′ ) = arg max ( ϕ , p ) ( ϕ p ( s t ) , ϕ g ( s t ) ) \arg\max\limits_{a_{t}^{\prime}}Q(s_t,a^{\prime}_t)=\arg\max\limits_{(\phi,p)}(\phi_{p}(s_t),\phi_g(s_t)) argat′maxQ(st,at′)=arg(ϕ,p)max(ϕp(st),ϕg(st))
使用全连接卷积神经网络的好处:
- 每个动作的 Q Q Q 值预测现在都有了一个明确的空间局部性的概念
- 全连接卷积神经网络对于像素级计算是有效的
- 全连接卷积神经网络模型可以用较少的训练数据收敛,因为末端效应器位置(像素级采样)和方向(通过旋转 s t s_t st)的参数化使卷积特征能够在不同位置和方向上共享
D. Rewards
奖励函数设置:
| 数值 | 情形 |
|---|---|
| 1 | 成功抓握(通过尝试抓握后对抓握手指之间的阈值计算) |
| 0*.*5 | 那些对环境产生可检测的变化的推动(超过阈值) |
E. Training details
使用 Huber 损失函数进行训练。
θ i \theta_{i} θi:迭代时神经网络的参数θ i − \theta_{i}^{-} θi−:目标网络参数 θ i − \theta_{i}^{-} θi− 在各个更新之间保持不变

只通过单像素 p p p 和网络 Φ ψ \Phi_ψ Φψ 传递梯度,从中计算出执行的动作 a i a_i ai 的值预测。
所有其他像素在迭代i反向传播与0损失。
F. Testing details
由于策略在测试期间是贪婪确定性的,因此当状态表示(以及值估计)保持不变时,它可能会被卡住,重复执行相同的操作。由于对动作空间的像素级参数化,基于访问计数的朴素加权操作可能低效。
为了缓解这个问题,在测试过程中,我们为网络规定了一个 1 0 − 5 10^{−5} 10−5 的小学习速率,并在每次执行操作后继续通过网络反向传播梯度。为了进行评估,网络权值在每次新的实验测试运行之前被重置到其原始状态(在训练之后和测试之前)。当环境没有变化的连续执行的动作数量超过10时,工作空间中的所有对象都被成功掌握(即完成)。
V. EXPERIMENTS
实验参数:
| 参数名称 | 数值 |
|---|---|
| 训练器 | 随机梯度下降 |
| 固定学习率 | 0.0001 |
| 动量 | 0.9 |
| 权重延迟 weight decay | 2 − 5 2^{-5} 2−5 |
| 服务器 | an NVIDIA Titan X on an Intel X eon CPU E 5-2699 v3 clocked at 2.30 GHz |
| 经验回放技术 | 后视经验回放 |
| 探索策略 | 随机性概率下降的 ϵ \epsilon ϵ-greedy |
| 折扣率 | 0.5 |
| 在场景中放置的物体数量 | 10 for simulation,30 for real scene |
实验目标
- 研究将推动作为运动原语的添加是否扩大了可以成功抓住物体的场景设置
- 以同时训练把抓取策略的未来预期成功为监督训练推动策略是否可行、
- 证明我们的公式能够直接从对真实系统的视觉观察中训练有效的、非抓取的的推动抓取策略
A. Baseline Methods
-
Reactive Grasping-only Policy (Grasping-only)
抓取策略使用与我们在第四节中提出的方法相同的像素状态和动作空间公式
但使用单一全卷积神经网络监督学习式二进制分类(从试验和错误)来推断是否可抓取的0到1像素提供值
这个基线类似于一个最先进的自上而下的平行夹持器抓取算法的自监督版本
-
Reactive Pushing and Grasping Policy (P+G Reactive)
这两个网络都是通过自监督试验和错误的二值分类训练的,其中推动是由变化检测的二值明确监督
变化检测是推动的最简单的直接监督形式,但需要更高的 ϵ \epsilon ϵ 值的探索策略来保持稳定的训练。
这一策略追随的是最大化即时负担价值的行动(可以来自于推动或抓取全卷积神经网络)。
B. Evaluation Metrics
我们执行 n n n 次运行( n n n 次 ∈ ∼ 10 , 30 \in\sim 10,30 ∈∼10,30),并使用3个指标来评估性能
- n n n 次测试运行的平均完成率,通过获取所有对象而不连续失败超过10次尝试来衡量策略完成任务的能力
- 每次完成的平均抓取成功率
- 操作效率(定义为 物体数量 执行的运动次数 \frac{物体数量}{执行的运动次数} 执行的运动次数物体数量),它描述了策略如何能够简洁地完成任务
模拟环境。策略在10个对象随机排列的场景中进行训练(左),然后在不同程度杂乱(10个对象、30个对象或具有挑战性的对象排列)的场景中进行评估。在最具挑战性的场景中,对抗性的杂乱由手动设计,以反映具有挑战性的现实世界的挑选场景(例如,紧密包装的盒子,如右侧所示)。
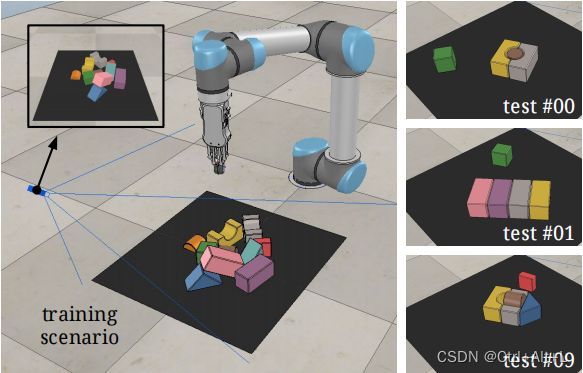
C. Simulation Experiments
除了摩擦系数外,大多数动态参数都保持默认值,摩擦系数已经被修改,以实现与真实世界尽可能相似的合成物体交互行为。
在我们的实验中,我们没有对模拟物理进行任何随机种子的调整。
Comparisons to Baselines
我们可以看到,VPG 在所有度量标准上都优于这两种基线方法。值得注意的是,P+G反应性在完成率和行动效率方面表现较差。这可能是由于它倾向于(面对杂乱)不断地推着物体,直到它们被迫离开工作空间,因为抓取效果仍然很低。

Challenging Arrangements
每个测试用例由放置在机器人前面的工作区中的3 - 6个对象的配置组成
在许多这样的测试用例中,物体被紧密地放置在位置和方向上,即使是最优的抓取策略也很难在不先整理的情况下成功地捡起任何物体。作为完整性检查,单个隔离的对象将被额外放置在与配置分离的工作区中。这只是为了确保所有策略在进行基准测试之前都经过了充分的训练。
P+G反应策略比仅获得更高的完成和抓握成功率,但平均动作效率较低。这表明,该策略执行了大量的推动,其中许多推动并不简洁,可能实际上没有帮助抓取。这是意料之中的,因为P+G反应使用来自变化检测的二进制监督来进行推-推运动,并不是直接通过它们帮助抓取的程度来监督。通过与VPG联合规划推动和抓握,我们观察到明显更高的完成率和抓取成功率(11个测试用例中有5个的完成率为100%)。更高的行动效率也表明,推动现在更简洁地帮助抓取。

No Pushing Rewards?
比较有和没有奖励的VPG策略的表现。实线表示抓取成功率(性能的主要指标),虚线表示训练步骤中推后抓取成功率。
(衡量推取质量的次要指标)
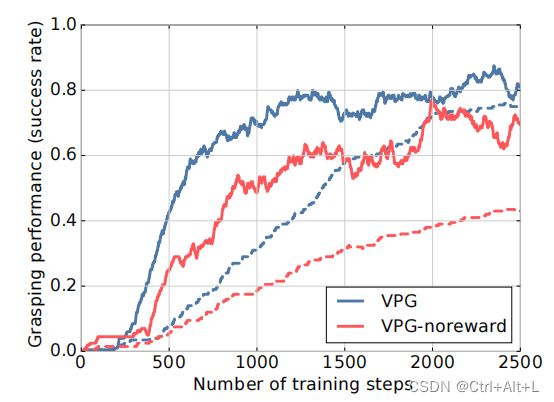
学习协同推动和抓取动作,即使没有任何内在的推动奖励( R p ( s t , s t + 1 ) = 0 R_p(s_t,s_{t+1})= 0 Rp(st,st+1)=0)。
我们还报告了推后抓成功率(即立即按后抓,如果抓成功,则认为是成功的),用虚线表示。
由于没有事实上的方法来衡量推动运动的质量,以衡量它们如何有利于无模型的抓取策略,这个次要度量可以作为一个很好的近似。
Shortsighted Policies?
为了测试这些策略的价值,我们训练了一个目光短视的VPG版本(“VPG-myopic”),其中 γ = 0.2 \gamma=0.2 γ=0.2 ,在仿真环境中用10个随机物体做训练。
有趣的是,我们发现 VPG-myopic 在训练早期以更快的速度提高其抓取表现(可能是优化短期抓取奖励),但在大多数硬测试案例中最终达到较低的平均表现(即抓取成功、行动效率)。这表明,为顺序操作计划长期策略的能力可以有利于选择和地点的整体稳定性和效率。

D. Real-World Experiments
摄像机通过自动校准程序将摄像机相对于机器人底座进行定位,在此期间,摄像机跟踪粘在夹具上的棋盘图案的位置。当机器人在摄像机视野内的三维位置(相对于机器人坐标预定义)的网格上移动抓手时,校准会优化外部图像。
Random Arrangements
有趣的是,VPG和仅抓取者在训练早期的表现改善是相似的。因为人们期望VPG需要更多的训练样本(因此需要更多的训练时间)来达到相当的性能,因为每个训练步骤只能执行一个动作(抓握或推)。这种性能增长的相似性可能归因于我们的方法优化了推动策略,使掌握甚至在训练的早期阶段更容易。当只抓取策略忙于微调本身以检测更难的抓取时,VPG花时间学习推动,使抓取变得更容易。
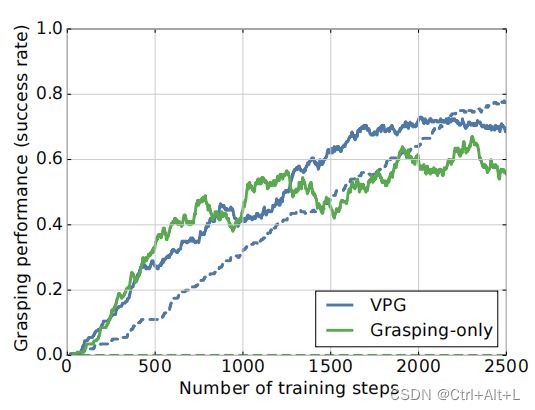
这个实验还表明,VPG是相当有效的样本效率——我们能够在不到2000状态转移的过渡中训练有效的推动和掌握策略。在一个真正的机器人上,每个动作执行 10 10 10 秒,这相当于大约 5.5 5.5 5.5 小时的挂钟训练时间。
Challenging Arrangements
VPG策略执行了有趣的协同行为,并且比只抓取策略更有能力在混乱的场景下有效地完成挑选任务。
Novel Objects
总的来说,该系统能够推广到与训练对象的形状分布相似的对象集,但当引入全新的形状时,就会遇到困难。
该机器人能够规划复杂的推动运动,以消除这些新物体的杂乱场景。
在现实世界中使用玩具块(顶部行)和新对象(下行)进行具有挑战性的安排的例子。

VI. DISCUSSION AND FUTURE WORK
-
运动原语和参数指定常规网格(高度图)提供了学习效率,但会限制表达。
探索其他参数,允许更多的表达运动(同时没有过度诱导样本复杂性)将会更加有利;
-
只用块来训练我们的系统,并用有限范围的其他形状(水果、瓶子等)进行测试。
-
只研究推动和抓住之间的协同作用,还有其他操作。