atm系统的用例模型_战斗系统执行式测试经验汇总
(注:文章内图片均为项目内部资源,请勿随意转载)
模块简介
L18,倩女幽魂隐世录这款游戏,在我加入项目后,以19.5.30测试为分界线,经历过一次几乎是整体规模的迭代。由传统武侠式MMO转变为赛博风的ARPG的过程,游戏的核心战斗部分经历了一次翻天覆地的变化。

游戏的核心战斗方式由“法术卡牌 + 随从卡牌 + 职业机制”偏策略的玩法转变为“主角战斗动作(拟态式) + 随从战斗控制(执行式)”这样更具动作性的体验。项目组在尽可能的在不触动战斗底层逻辑的基础上,进行了以上的调整。目前的效果也是非常可观的。

而这篇文章,目的是为了阐述,作为执行式负责人,我针对具体到单个执行式测试各个细节的测试心得,以及结合项目开发过程,关于模块整体把控的个人理解。
执行式,以更通俗的话来介绍,就是玩家的随从。在游戏核心战斗定位于“拟态式 + 执行式”的战斗机制的前提下,执行式,也就是随从,对于战斗的重要性可谓是占据了半壁江山。
执行式作为玩家的随从,其主要的战斗方式是通过玩家的召唤行为,在场景中根据配置的AI进行战斗。玩家可以通过一定的方式控制执行式的战斗行为和战斗逻辑,配合拟态式(主角自身的战斗方式),进行一系列的副本战斗。
目前已经确定制作完成的执行式已经超过了60个,远远大于目前规划的拟态式数量(5个),单个执行式的测试条目本身就数量庞大,测试的工作量是巨大的。
Checklist追加
执行式测试量大,实际的测试内容分配给了多个测试小伙伴。作为测试负责人,总结测试方法,指导相关测试人员,以及帮助对执行式有兴趣的人员了解相关模块, 制作一个完备的Checklist,是很有必要的。
 从checklist条目也可得知,执行式的测试内容巨大
从checklist条目也可得知,执行式的测试内容巨大
用例框架
以执行式为中心,纵观整个战斗系统,以下是关于执行式的用例设计框架的思维导图:
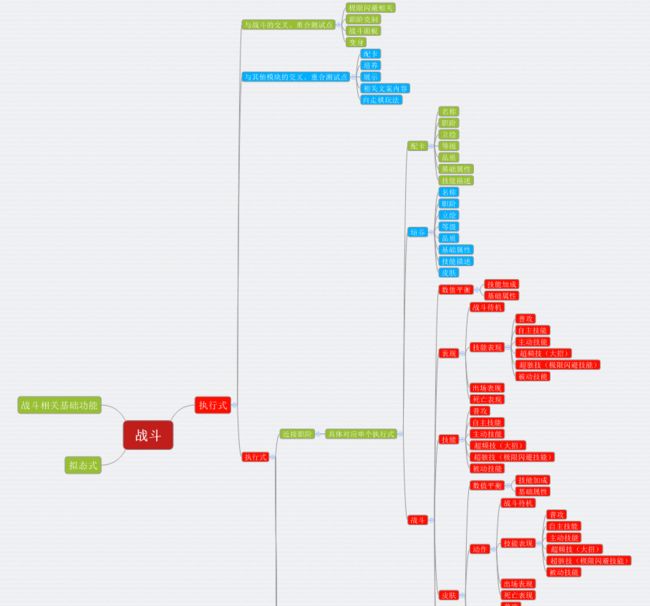
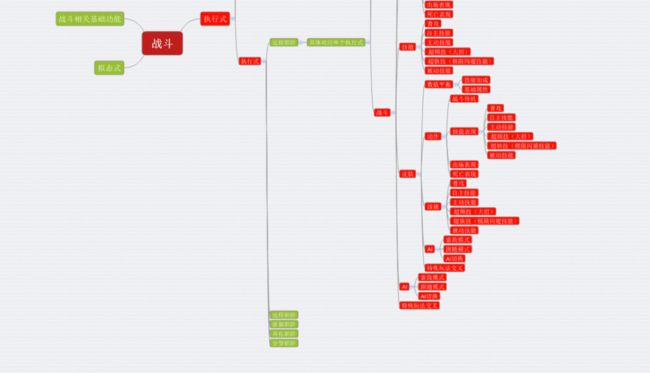 用例思维导图
用例思维导图
用例设计可以基本分为:与执行式有关的战斗基本功能、与其他玩法模块交叉、技能实现和技能表现、数值平衡类测试四块大测试点。
所以在实际编写用例时,每个执行式会基于一个由负责人提前编写完成的用例模板的基础上去编写各自的用例。再由于快速迭代的背景,保持用例模板的及时更新也是非常重要的。易协作和用例平台对此帮助很大,在验新需求时,可以通过需求单的特殊字段去自动生成一条用例,协助我们验单后及时的维护更新用例。
测试人员可以再根据每个执行式具体的游戏设计需求以及实现的细节,在模板的基础上展开,设计具体的测试用例。一切的出发点都是为了更加优良的游戏表现和游戏质量。
(用例就不给看了)
通用·交叉测试点也是执行式负责人(我)进行维护,主要是所有执行式通用的功能, 基本包含了所有与执行式有关的战斗基本功能、与其他玩法模块交叉的测试用例。无需针对单个执行式去分别执行用例,造成不必要的效率低下。
交叉测试点
抽卡、配卡、培养界面
抽卡、配卡、培养界面等模块,实际上有其他QA负责功能测试,但执行式作为模块的重要组成,执行式测试时也需要注意交叉测试内容。对应模块的QA对执行式的具体设计很可能是不清晰的,会遗漏与执行式相关的测试点,这就需要执行式与其交叉模块的负责人员妥善的沟通,同步信息,确保质量。
抽卡、配卡、培养这块,针对执行式本身,更多的是显示check。立绘、模型、执行式基本属性、技能描述、各种交互玩法的表现等等。逻辑简单,重在细节。
值得注意的是我们需要了解在各个场景下,模型的显示规格。不同的场景,策划和美术通过需求确定使用不同规格的模型prefab。在培养界面,展示用的执行式模型使用的是gm_ui规格(高模+UI展示)的prefab。我们完全可以在unity环境下去检查,不仅仅是通过肉眼,主观的判断这个模型的精度是否符合需求。
针对抽卡的表现,也做了对应的GM指令,自动化辅助测试。输入不同的指令和参数,可以选择检查所有执行式的抽卡表现,并且提供多种跑查方式,方便回归。
![]()
配卡、培养相关的展示界面牵涉到多个界面,需要保证界面以及界面细节的覆盖度。在整体上协助对应模块的负责人保证模块质量。

部分界面的交互和展示内容较多,此时就要细心了。
此前出现过一个漏测的问题:
某个执行式点击对应的交互按钮,弹出了一个错误的界面。原因是因为这个交互按钮功能是新加的,对应功能负责人没有沟通告知,即使肉眼清晰可见,执行式测试人员也想当然的没有针对新增的按钮进行任何的测试。导致部分策划配置错误的执行式,在点击交互按钮后弹出了错误的界面。

不能放过任何一个测试细节

在模块交叉测试中,本身的测试难度并不大, 更重要的就是细心和沟通,尽善尽美。
与执行式有关的战斗基本功能
战斗面板·执行式相关(不给看)战斗基本功能,主要是战斗面板功能的测试。例如自动战斗功能、执行式召唤、使用技能等等相对于战斗面板的表现。具体到单个执行式的一些战斗表现,并不会放在交叉测试的用例中,而是针对对应执行式增加用例。
测试前要对战斗系统有充分的了解,也要对与执行式有关的战斗功能和设定有明确的认识。测试的难度其实不大,重点是对项目的理解,以及积极的沟通。
针对单个执行式的整体测试
具体到单个执行式内容,测试的重点在于整体的战斗表现。按照整个战斗流程,可以分为:出场表现、战斗中表现、死亡表现以及死亡后残留的表现。战斗中的表现是测试的重中之重,也是执行式测试工作量最大的内容,更是测试的难点。
执行式的投放内容,随着不断地迭代,版本稳定后,已经基本上做到了完全通过策划配置去控制。
在测试执行式前,完整地了解策划的设计各个执行式的需求,以及配置的方式、规则,并且保持和策划的沟通。对提升测试执行式的效率会有明显的帮助,也能通过思考需求本身,结合配置表和策划代码的情况发现一些游戏内测试时难以发现或复现的问题。
出场、死亡相关表现
出场、死亡表现包括出场动画、出场语音、死亡动画、死亡语音。目前完全通过策划配置控制,迭代稳定后问题很少,问题出现也多是迭代导致动画烂了的易检查问题。
值得注意的是,测试时可以结合实际玩法测试一系列特殊操作后的表现。
比方说召唤执行式后,快速释放技能,动作衔接以及语音表现是否正常。
之前就出现过一个比较整体性的问题:
因为没有限制召唤后释放技能的时间,召唤执行式后玩家可以立即使用主动技能,出场动画和技能动作的衔接表现非常差。之后策划就做了需求,保证出场动画播放完成后玩家才能使用主动技能,优化了执行式的整体表现。

基于执行式切换的基本规则,游戏的出场语音和死亡语音出现了冲突情况。及时和策划沟通确认现象是否符合实际需求,保证游戏表现逻辑。这个案例,虽然没有开bug单处理,是一个后期可优化点。

AI相关
执行式被召唤后,玩家可以通过主动技或绝技释放按钮,控制执行式的战斗行为。在其他时间,执行式的行为由策划配置好的AI进行托管。
执行式AI一共有两种模式,可以分为主动进攻模式和跟随模式。战斗面板处提供了切换模式的按钮。
每一个执行式AI的细节会根据执行式自身的特性各有不同,但其基本上是基于同一个AI模板进行编辑的。所以在发现AI问题时,需要注意AI问题造成的影响范围。AI的bug通常不仅仅是单个执行式特有的问题。
执行式AI的问题在程序底层不进行迭代的前提下,更多的是出现在策划配置层面。因为执行式配置关联的配置表很多,结合了AI流程图、策划代码、策划配置表等等一系列的操作。容易出现许多细节上的误差。
下例是一个很典型的AI整体逻辑表现型问题:
跟随模式在初期制作完成后,策划未考虑跟随模式下执行式与敌方单位的战斗表现。导致跟随模式下的执行式进入了一种完全的跟随状态,就战斗表现来说有些过于笨重了。
在BUG修复后,执行式能够在跟随模式下,对进入射程范围内的敌人做出锁定并发动进攻的行为,但在主角保持移动时,还是会优先跟随着主人。这样的战斗表现就会自然得多。

还有一个配置普遍容易出现问题的例子:

出现问题的原因是,AI判断的可释放距离和伤害结算的距离,是分开配置数值的。所以在数值配置不准确的情况下,会出现执行式原地释放技能或使用普攻,但是无法造成伤害的情况。
这种错误配置在执行式制作初期时有发生,测试的难度虽然不大,但是经常会被忽略,因为要采取一些比较特殊的测试手段才能够复现这样的问题。
目前基本上是通过游戏内的操作去测试AI的合理性,但这样的问题在理论上是能够通过静态检查去保证AI配置和技能配置的配合是正确的,可以在后面尝试去补充这块的检查方式。
AI对执行式的整体战斗表现起着至关重要的作用,作为负责人要做到整体的质量把控,并把AI的机制和迭代情况同步给所有测试人员。让测试人员了解模块整体情况,也了解到BUG原因,提升测试的效率。说到底就是要对游戏实际需求有充分的理解。在某种层面上,你甚至要比策划更了解更理解你的项目。
技能测试
执行式的技能类型较多,包括:普攻、AI技能、被动技能、主动技能、大招等等类型。每个执行式的每种技能类型至少都有1个技能,数量较多。
首先需要保证的是每个技能类型的触发方式:普攻、AI技能是镶嵌在策划配置的AI当中的;主动技能、大招、闪避技能有各自特殊的触发以及使用的方式。不过整体的技能使用逻辑,各个执行式是一致的,可以由负责人做整体性的测试保证基本功能。
技能的细节,实际各有各的配置,但之前有提到执行式绝大部分内容目前都可以用配置去控制。所以我们能从中找到一定的规则,与策划确认规则后,针对稳定的模块,固定的规则,进行一系列的静态检查内容。例如技能类型的检查、技能CD符合需求、技能的描述文本内容在限制内不会超框等等最基本的表现,目前已经用整体的静态检查进行兜底,使用的一年多时间里,相当的稳定,帮助QA快速解决了许多基础配置上出现的问题。
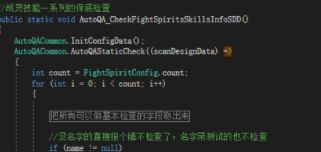
至于配置更加复杂的技能动作和特效、技能伤害、技能特殊效果等等。我们首先还是在游戏内去确认整体表现的效果(技能动作和特效) ,此时要注意技能在低配画质和高配画质,以及开发环境与真机环境下是否会有差异。
游戏设置和游戏环境可能会影响到技能的实际表现,曾经也出现过低配环境下执行式技能集体特效报错的尴尬情况,也出现了许多在其他玩家视角中表现异常的BUG。这样的问题,实际上都是因为没有完整的覆盖测试到游戏内所有不同画面质量的模型或动作或特效所导致的。
针对各画质游戏表现的测试,测试方法有多种:多开客户端、选择不同真机环境、修改游戏内设置等。

 这些都是同一测试阶段集中出现的低模问题,这只是一部分
这些都是同一测试阶段集中出现的低模问题,这只是一部分
技能的表现逻辑,需要关注技能本身的施放条件、技能释放时间节点前后的、以及执行式状态(生、死、还有各种特殊状态)等等情况下,各个技能的表现情况。整体测试可以基于测试用例模板去实施,实际也需要结合执行式技能的特点以及执行式本身的特性,针对性的做专项的,更加细节性的测试。
技能伤害、特殊效果等结算相关的测试。首先是确保结算实现的效果。包括结算的目标或范围符合预期、结算时的伤害确认、技能关联的buff或debuff的挂接等等。
就功能测试而言,主要是利用战斗测试场景去一一检查技能。但我们完全能通过策划配置以及策划代码去检查更多的细节,发现一些功能测试过程中不能轻易发现的问题,提升测试的效率,且进一步保证测试质量。
下面是一个经典的例子:
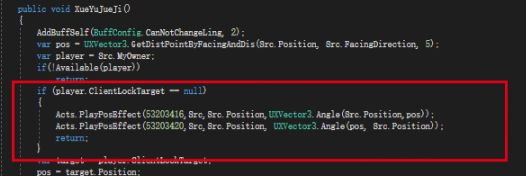
功能测试过程想要测试出这个bug是需要一些特殊步骤的。
因为游戏默认会使用锁定模式,且锁定与否对于技能使用来说,正常情况下是不会有影响的,测试过程中容易忽略这样的状况。
但在这个案例中,策划比较骚气的用了一个判断:如果主角没有锁定任何人时,使用技能后只会播放两个特效就结束了技能的流程。这个判断本身是比较多余的,且造成了一个比较严重的技能实现问题。如果不通过review策划代码的方式,在游戏中去检查技能,这个风险点是容易被遗漏的。
对配置的了解也能让我们明确出现问题的原因,例如:
大招的配置中,策划在对应配置行都会给大招添加一个buff,去规避玩家主动释放的技能造成打断大招的异常现象。策划修bug时只需要给对应skill添加上所需的bug即可修复。
这是个制作初期就能测出来的bug,但当时发现的时间比较晚了。原因便是当时测试人员对配置规则不熟悉,且没有测试覆盖完整的漏测。
作为功能测试,关注游戏内表现是最基本的测试原则。而去了解策划配置方式,并且能够理解策划的接口调用代码,乃至尝试理解程序底层代码。无论对问题原因的理解还是测试的效率上都会有很大的提升。并且可以尝试指导策划人员之后不会让问题反复,也能够进一步明确模块的风险点在哪。
数值相关

L18的技能数值配置在了技能实现的过程之中。所以在迭代稳定的前提下,仅仅只是通过战斗测试场景肉眼观察数值跳字的话,测试的效率和准确性其实都不能得到保证。
充分了解属性成长公式、伤害结算代码、技能加成公式等等,能够充分的提升数值测试的效率。也让数值测试有据可依,不仅仅是单纯的看飘字,通过主观感受和粗略的计算去确认数值是否符合预期。
在实际检查技能实现的测试过程中,通过review策划代码,完全可以做到将技能数值一并检查的操作。加上记录战斗测试场景中实际的数值,数值测试得到了双保险。在个人层面上,我认为自己还可以将大量的相关公式做一次整合,让数值测试更加系统化,进一步加强效率。
技能数值测试目前主要保证技能的加成数值与对应培养等级的预期加成值对应一致,没有针对数值平衡性做一些针对性的测试方法。待战斗系统彻底稳定后,技能数值平衡性是一个可以进行拓展的测试模块。
 伤害写在了技能实现流程中
伤害写在了技能实现流程中
特殊机制相关
变身
某些执行式的技能加入了变身的机制。变身在L18中是一个独立的模块。在模块交叉的前提下,涉及变身的技能,风险相比其他技能更高。
在测试变身技能时,我们不仅仅要思考关于技能本身,更要结合变身前后的时间节点进行分析,细化测试用例。还要通过策划代码去了解策划是通过怎样的方式进行变身的操作的,错误的逻辑会导致游戏内许多让人匪夷所思的现象。
皮肤
L18的高品质执行式拥有皮肤的拓展功能。一个执行式拥有多个形象。而每一个形象实际实现的方式其实是配置一个新的执行式。
所以在测试皮肤时,除了测试解锁皮肤的条件、流程、方式,还需要将解锁的皮肤当做一个全新的执行式进行一次完整的测试。
在430测试节点时,不乏有执行式普通形态没有异常,但是执行式皮肤的技能表现出现异常的情况。
皮肤系统本身有模块的负责人,和其他交叉模块一样。执行式测试人员也需要协助测试。
自走棋玩法
自走棋玩法是一个无主角玩法,是将各个执行式当做棋子进行战斗的一个玩法。
此时的执行式AI又配置了一套新的,且部分执行式的技能由于无主角的机制,实际上是无法正常使用的,需要做特殊的处理。
所以执行式测试人员需要针对特殊的玩法,明确玩法规则,确认技能是否需要屏蔽,或是技能是否需要允许特殊的处理或表现。
整体质量把控的心得
作为执行式测试的负责人,我比较享受的是自己能够参与到战斗系统的开发过程中,并且能通过自己的能力,对战斗系统,特别是自己负责的执行式模块进行游戏品质的保证和优化。
执行式的测试内容多,交叉系统复杂。加之快速迭代,开发周期紧凑,对每一位测试人员都是不小的考验。在目前多次大版本的上线测试中,包括大改版前的灵系统,执行式模块和战斗系统一直表现稳定。
针对测试量大的模块,首先是合理分配测试的人力资源。目前执行式测试主要通过执行式的职阶进行分配,五个职阶分别分配给了五位测试人员进行测试,相对稳定的执行式继而再交接给外包测试人员进行后期的维护;
其次是即使更新执行式整体的迭代情况,向各个负责人员告知一些整体性的迭代内容,一些经典的BUG分享,BUG原因普及。保证让每一位测试人员都能获得最新最快的信息;
交叉模块注意细节,保持良好沟通。在版本回归的过程中我们也有吃过沟通怠惰的亏,导致一些很弱智的问题没有及时的发现。交叉模块的风险无须赘述,避免问题的关键就在于测试人员的责任心以及沟通积极性;
最后就是保持学习的态度,功能测试不仅仅是发现bug,更要学会发掘bug的原因。这样不仅能提高测试的效率,提升自身对游戏开发流程各个阶段内容的理解,也可以积极的影响到策划、程序的工作,引导他们去规避已经犯过的错误和漏洞。
测试也许是一个比较被动的职能岗位,但一定要提醒自己保持着积极的心态和行动力去推动模块,乃至整个游戏的开发进程和产品质量。