海量数据的实时指标计算
最近看了一本书叫《风控要略—互联网业务反欺诈之路》,这本书主要是讲互联网产品安全防范的,我之前做过一年情报数据分析的工作,当时觉得这方面工作很机密,网络上几乎没什么相关的资料,这本书让我与之前的工作产生了共鸣,因此还是推荐一下这本书。
对于海量数据库以及实时指标计算,我以前了解过一些大数据技术相关的知识,由于现在工作中涉及较少,因此写了一篇笔记了解实时指标计算方面的知识。
目录
- 一、实时指标计算概述
- 二、实时指标计算方案
- 2.1 基于数据库SQL的计算方案
- 2.2 基于事件驱动的计算方案
- 2.3.基于实时计算框架的计算方案
- 2.3.1 Storm介绍
- 2.3.2 Spark Straming介绍
- 2.3.3 Flink介绍
- 三、实时指标计算实践
- 数据拆分
- 分片计算
- 引入Flink
- Lambda架构
- 四、参考文章
一、实时指标计算概述
在风控反欺诈业务中,为了实时进行业务事件的风险判断,要求指标计算延迟非常低,一般在毫秒或几十毫秒级别。常见的指标类型有下:
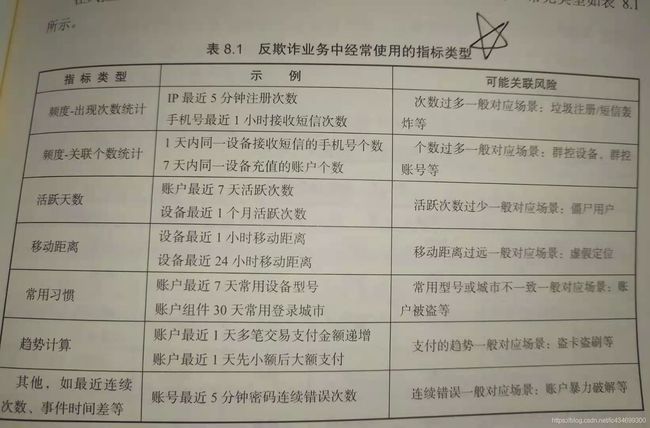
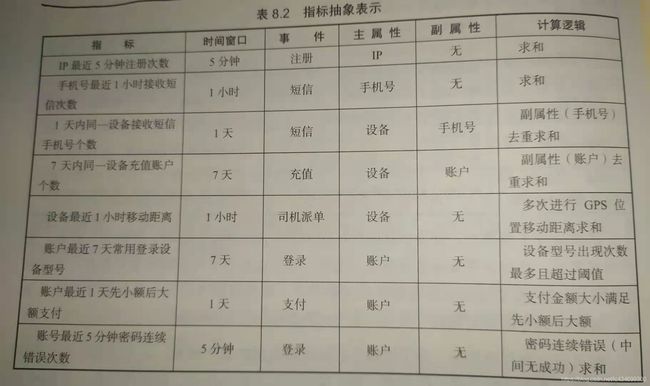
在反欺诈业务中,为了能及时发现新的黑产行为,以上业务指标计算需要随时上线,而且时间窗口和计算维度组合均不确定。因此为了满足反欺诈系统快速响应的需求,就要构建实时的反欺诈指标计算系统,用于支持策略运营人员灵活配置和使用。
二、实时指标计算方案
实时指标计算方案常见的实现方法有基于数据库SQL的计算方案、基于事件驱动的计算方案和基于实时计算框架的计算方案三种。
2.1 基于数据库SQL的计算方案
关系数据库支持基于SQL语句进行统计计算,这种方式实现简单,但不够灵活,响应时间得不到保障。比如计算最近1小时内某ip注册账号个数的代码可以如下:
select count(1) from xxx where ip=‘x.x.x.x’ and gmt_create>now()-1 hour
2.2 基于事件驱动的计算方案
注册、登录、交易等都是独立的事件,事件可以转化成消息进入kafka等消息系统中。比如以最近1小时内某IP注册账号个数为例,当注册事件到达时,可以在数据库或缓存中构造KV,代码如下:
112.3.10.6 :[{
“deviceId”:“acefhahefbibv”,
“account”:“jack”
“timestamp”:,1560745934747,
“eventType”:“register”
},{
“deviceId”:“acefhahefbibv”,
“account”:“jim”
“timestamp”:,1560745934747,
“eventType”:“login” },
{
“deviceId”:“acefhahefbibv”,
“account”:“lily”
“timestamp”:,1560745934747,
“eventType”:“register”}]
当指标查询请求来到时,只需要进行一次KV查询,即可以获得全部相关数据,然后在内存中进行数据筛选,得出结算结果。
当时间跨度较大,数据量较大的情况下,可以采用差分计算的方法。比如,计算最近一小时内注册的手机号数量,可以预先10分钟做一次聚合,最后的查询优化统计为(最近几分钟明细+5个10分钟聚合数据+10分钟明细数据)。
这种计算方式的优点在于可以进行预计算,查询性能较好。缺点是每一个指标的计算都需要处理消息系统、中间结果存储系统、业务逻辑,需要针对不同的事件场景进行逻辑开发,且需要每次进行发布,而且需要进行大量的预计算。
2.3.基于实时计算框架的计算方案
实时计算框架解决了方法二的痛点,将数据流、中间结果存储、性能和可靠性交给框架本身解决,它提供易用的不同层次抽象的API,甚至可以通过SQL完成一个计算指标的上线。业界流行的三大实时计算框架:Storm、Spark Streaming和Flink。
先了解两组基础概念:
1.实时计算和离线计算
实时计算对延迟要求较高,要求在秒级甚至毫秒级就给出结果。离线计算一般指天级别(T+1)或小时级别(T+H)给出计算结果。
2.批计算和流计算
批计算是按照数据块进行计算,一般需要累积一定时间或一定的数据量再进行计算,有一定延迟。流计算是针对数据流进行计算,1条数据处理完成后立刻发给后续计算节点,延迟较低。批计算如果时间间隔很短,处理速度很快,也可以称为某种意义上的准实时计算。
2.3.1 Storm介绍
Storm是比较早出现的实时计算框架。主要概念有Spout(产生数据源)、Bolt(消息处理者)、Topology(网络拓扑)、Tuple(元祖)。
Storm提交运行的程序称为Topology,Topology处理的最小消息单位是一个Tuple,也就是一个任意对象的数组。在Storm中,数据像流水一样,源源不断地从一个处理模型完成处理后,快读流向下一处理模块。
2.3.2 Spark Straming介绍
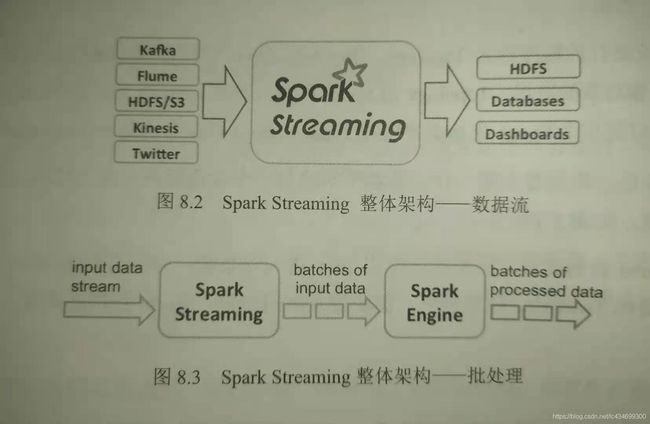
Spark Streaming是Spark核心API的一个扩展,可以实现高吞吐量、具备容错机制的实施流数据的处理。它支持从Kafka、Flume、ZeroMQ等多种数据源获取数据,然后使用map、reduce和join函数进行复杂算法的处理,最后将处理结果存储到文件系统、数据库等。
Spark Streaming本质上是基于核心Spark Core的,它接受实时流的数据,并根据一定的时间间隔拆分成一批批的数据,通过Spark Engine处理这批数据,整体框架如下:
2.3.3 Flink介绍
Flink在数据处理方式上和Storm类似,并没有采用小批量处理的方式,把所有的任务当成流来处理,是真正的流式系统。此外它也是一个流批一体的计算框架。
从本质上说,Storm和Flink是真正意义的流式计算,延迟在毫秒级。Spark Streaming采用微小批的方式进行计算,延迟在秒级,对延迟要求不高的业务场景适用。
三、实时指标计算实践
在某个风控反欺诈业务场景中,需要计算基于设备号主属性的多个指标如下“
设备在最近5分钟登录次数。
设备在最近1小时登录过的账户个数。
设备在最近1天登录过的账户个数。
设备在最近1天使用过的IP个数。
设备在最近1天的GPS位置移动距离。
实时指标计算引擎的数据结构如下:


当新的业务事件到来时,实时指标计算引擎不断更新Value数据。然后根据事件驱动的计算方案进行KV查询,在内存中对筛选过后的数据进行计算。实际操作中,还可以结合数据压缩、应用缓存、数据截断等方式提升效率。比如用户设备最近1天登录1000次和10000次的风险是没有区别的,因此可以只存储最近1000次的数据。
数据拆分
为了对实时指标计算引擎进行优化,可以对数据进行拆分计算。比如将设备ID的数据拆分gps、ip、账户等维度,实际计算时只需查询设备ID账户维度的数据,不需要返回无用多余的数据。但是这种方式使得数据的复用性较差,导致NoSQL数据库占用较大的内存和存储,是一种空间换时间的优化方式。
分片计算
对于"频度-关联个数统计"类指标,由于需要去重,因此需要业务事件的明细数据。但是对于频度-出现次数统计类指标,本质上只是个数的计算,因此不需要去重,可以进一步优化,这种方法上面也提及到。

当业务事件触发风控规则时,只需要查询多个时间分片的数据,进行聚合累加即可。
引入Flink
通过代码配置指定计算任务,将各种复杂业务逻辑都交给Flink框架处理,计算过程完全交给框架实现。以"IP最近1小时登录次数"为例,对应的Flink示例代码如下:

Lambda架构
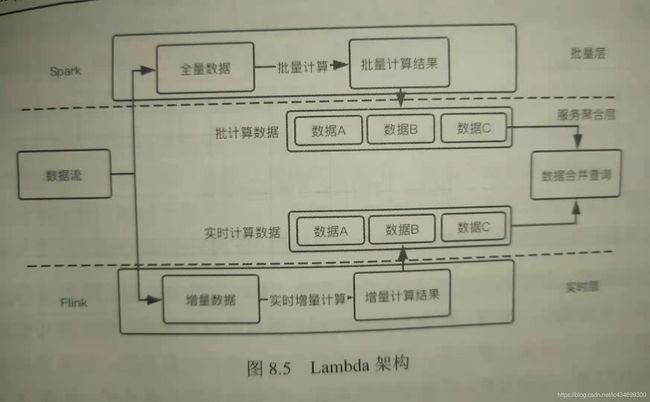
在实践场景中,有些指标需要回溯的时间较长,因此如果全部使用实时指标计算引擎的话,时间窗口很长,对系统的压力很大。Lmabda架构可以将一个时间跨度较长的实时指标计算转化为一个"较短时间窗口的实时指标"+"历史数据的离线指标"的聚合结果。实时指标用Flink做实时流处理,历史数据用Spark做批处理,Lambda架构分为实时层、批量层以及服务聚合层3层。
四、参考文章
《风控要略 互联网业务反欺诈之路》
【作者】:Labryant
【原创公众号】:风控猎人
【简介】:某创业公司策略分析师,积极上进,努力提升。乾坤未定,你我都是黑马。
【转载说明】:转载请说明出处,谢谢合作!~