【神经网络】tensorflow实验4--Matplotlib数据可视化
1. 实验目的
①掌握Matplotlib绘图基础
②运用Matplotlib,实现数据集的可视化
③运用Pandas访问数据集
2. 实验内容
①绘制散点图、直方图和折线图,对数据进行可视化
②下载波士顿数房价据集,并绘制数据集中各个属性与房价之间的散点图,实现数据集可视化
③使用Pandas访问csv数据集,对数据进行设置列标题、读取数据、显示统计信息、转化为Numpy数组等操作;并使用Matpoltlib对数据集进行可视化
3. 实验过程
题目一:
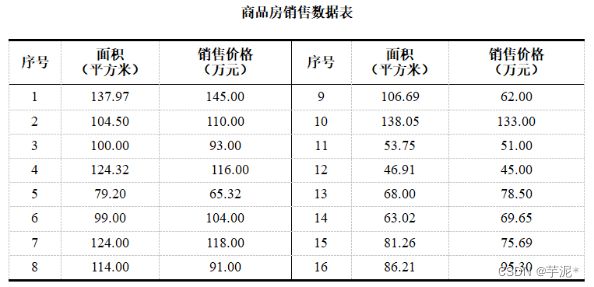
这是一个商品房销售记录表,请根据表中的数据,按下列要求绘制散点图。其中横坐标为商品房面积,纵坐标为商品房价格
要求:
1. 绘制散点图,数据点为红色圆点;
2. 标题为:“商品房销售记录”,字体颜色为蓝色,大小为16;
3. 横坐标标签为:“面积(平方米)”,纵坐标标签为“价格(万元)”,字体大小为14。
① 代码
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = 'SimHei' #黑体
x = [137.97,104.5,100,124.32,79.2,99,124,114,106.69,138.05,53.75,46.91,68,63.02,81.26,86.21]
y = [145,110,93,116,65.32,104,118,91,62,133,51,45,78.5,69.65,75.69,95.3]
plt.xlabel("面积(平方米)",fontsize = 14) #横坐标标签为:“面积(平方米)”,纵坐标标签为“价格(万元)”,字体大小为14。
plt.ylabel("价格(万元)",fontsize = 14)
plt.scatter(x,y,36,color= "r",marker='o') #绘制散点图,数据点为红色圆点;
plt.title('商品房销售记录',color = "b",fontsize = 16) #标题为:“商品房销售记录”,字体颜色为蓝色,大小为16;
plt.show()② 实验结果

题目二:
按下列要求完成程序。
(1)下载波士顿数据集,读取全部506条数据,放在NumPy数组x、y中(x:属性,y:标记)。
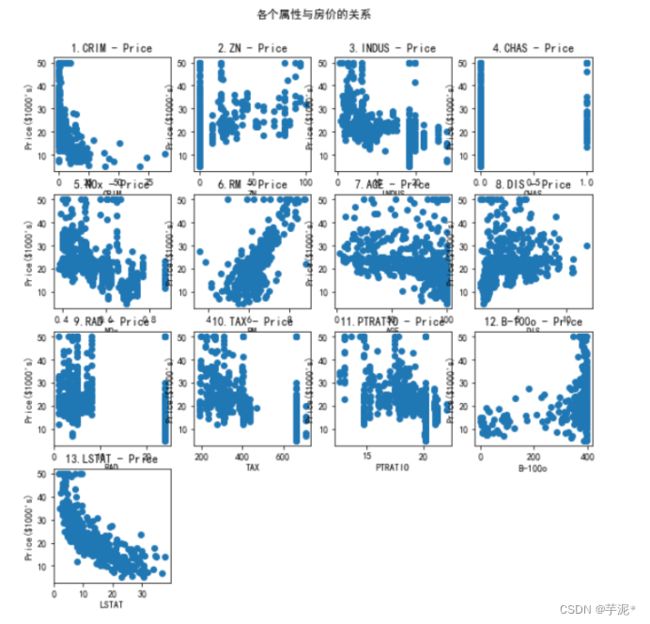
(2) 使用全部506条数据,实现波士顿房价数据集可视化,如图1所示。
(3) 要求用户选择属性,如图2所示,根据用户的选择,输出对应属性的散点图,如图3所示。
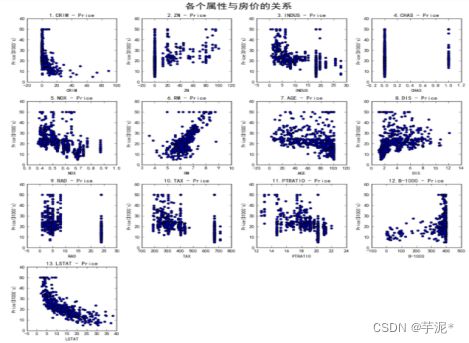
图1 波士顿房价数据集可视化图
请用户输入属性:

图2 属性选择图
运行结果:
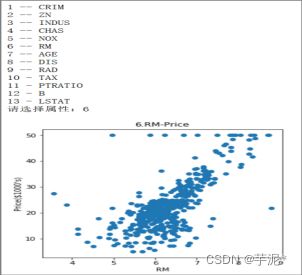
图3 运行结果图
① 代码
import matplotlib.pyplot as plt
import tensorflow as tf
def Print_Choose(): #打印选项
print('1--CRIM\n2--ZN\n3--INDUS\n4--CHA\n5--NOx6--RM\n7--AGE\n8--DIS\n9--RAD\n10--TAX\n11--PTRATIO\n12--B-100o\n13--LSTAT')
def Choose(num): #画相应散点图
plt.scatter(train_x[:, num], train_y) #绘制散点图 train_x[:, num]:平均房间数 train_y:房价
plt.xlabel(titles[num]) #横坐标标签名
plt.ylabel("Price($1000's)") #纵坐标标签名
plt.title(str(num + 1) + "." + titles[num] + "- Price") #总标签
plt.show()
def Show():
for i in range(13): # 绘制子图
plt.subplot(4, 4, (i + 1))
plt.scatter(train_x[:, i], train_y)
plt.xlabel(titles[i])
plt.ylabel("Price($1000's)")
plt.title(str(i + 1) + '.' + titles[i] + " - Price")
plt.show()
if __name__ == '__main__':
boston_housing = tf.keras.datasets.boston_housing
(train_x, train_y), (_, _) = boston_housing.load_data(test_split=0) #获取相应数据 给train_x。train_y
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 坐标轴的负号正常显示
titles = ["CRIM", "ZN", "INDUS", "CHAS", "NOx", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B-100o", "LSTAT"]
plt.figure(figsize=(10, 10)) #设置绘图尺寸
plt.suptitle("各个属性与房价的关系", x=0.5, y=0.95, fontsize=12) # 最上面的大标签 调整后不用显示 画布上看不见
Show()
Print_Choose()
num =int( input('请选择属性:'))
Choose(num-1)② 实验结果

拓展题(选做):
使用鸢尾花数据集,绘制如下图形,其中对角线为属性的直方图。
提示:绘制直方图函数 plt.hist(x, align= 'mid', color, edgecolor)
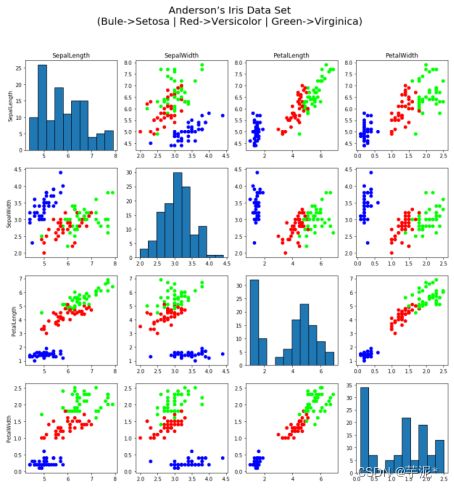
① 代码
import tensorflow as tf
import numpy as np
import pandas as pd #数据统计集
import matplotlib.pyplot as plt
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv" #训练数据集的地址
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL) #下载数据集
COLUMN_NAMES = [ 'SepalLength', 'Sepalwidth','PetalLength', 'Petalwidth', 'Species']#定义列标题列表名字
df_iris = pd.read_csv(train_path,names = COLUMN_NAMES,header = 0) #train_path 读取文件名 表头名字 names = COLUMN_NAMES,header= 0以names为列标题
iris=np.array(df_iris) #转换成数组
fig = plt.figure( 'Iris Data', figsize=(15,15))
fig. suptitle("Anderson's Iris Data Set\n(Bule->Setosa| Red-Versicolor / Green->Virginica)",fontsize=20)
plt.hist(COLUMN_NAMES[0])
for i in range(4):
for j in range(4):
plt.subplot(4,4,4*i+(j +1))
if (i == j):
plt.hist(iris[:, i], align='mid', color="royalblue", edgecolor="black") # 绘制直方图
else:
plt.scatter(iris[:,j], iris[:,i],c=iris[:,4], cmap='brg') #取所有行,第J列 c为所绘制的颜色为数据集的最后一列标签决定 颜色变换012 蓝红绿
if(i == 0):
plt.title(COLUMN_NAMES[j]) #每个图对应的标题
if(j == 0 ):
plt.ylabel(COLUMN_NAMES[i]) #纵坐标标签名字
plt.show()② 实验结果
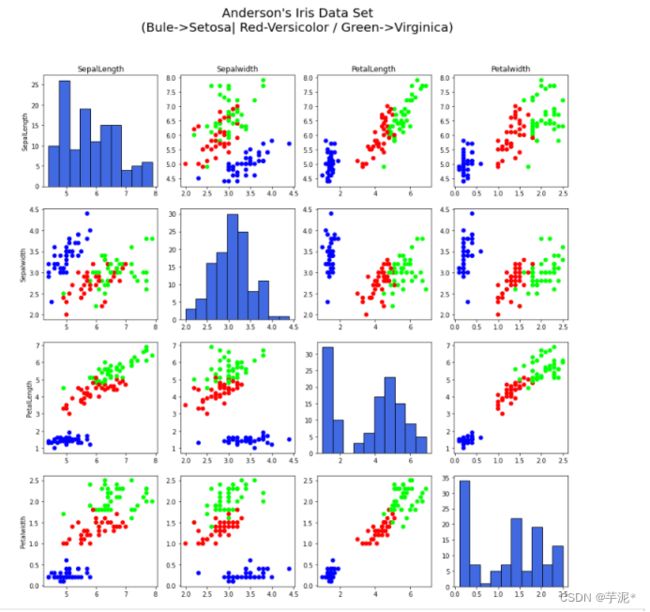
5. 实验小结
① 实验过程中遇到了哪些问题,你是如何解决的?
无问题
② 根据题目二的数据进行可视化结果,分析波士顿数据集中各个属性对房价的影响。
占地面积与房价大致呈线性相关关系。
ZN超过25000平方英尺的住宅用地所占比例对价格影响不大
eINDUS 城镇非零售业务地区的比例越高,价格越低
CHAS 查尔斯河虚拟变量对价格影响不大
NOX一氧化氨浓度(每1000万份)越高,价格越低
RM平均每居民房数越多,价格越高
AGE 在1940年之前建成的所有者占用单位的比例越高,价格越低
eDIS与五个波士顿就业中心的加权距离影响不大
RAD辐射状公路的可达性指数影响不大心
TAX 每10.000美元的全额物业税率越高,价格越低
eRTRATIO城镇师生比例越高,价格越低
B1000(Bk-0.632其中Bk是城镇黑人的比例影响不大
LSTAT 人口中地位较低人群的百分数越高,价格越低
③ Numpy和Pandas各有什么特点和优势?
NumPy已经做了相当程度的优化,可以对大数组的数据进行高效处理,NumPy除了在相当程度上优化了Python计算过程,其自身还有较多的高级特性由于NumPy几乎仅专注于数组处理,另一方面则是数据分析牵涉到的数据特性众多,需要处理各种表格和混杂数据。pandas 含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具。经常是和其他工具一起使用,如数值计算工具NumPy和SciPy,分析库statsmodels与scikit-learn,以及数据可视化库matplotlib。
④ 在题目基本要求的基础上,你对每个题目做了那些扩展和提升?或者你觉得在编程实现过程中,还有哪些地方可以进行优化?
在第二题中显示用户选择的图片,显然这中间有些冲突,应该将两者分开实现,减少了代码的冲突。