- Python教程:一文了解使用Python处理XPath
旦莫
Python进阶python开发语言
目录1.环境准备1.1安装lxml1.2验证安装2.XPath基础2.1什么是XPath?2.2XPath语法2.3示例XML文档3.使用lxml解析XML3.1解析XML文档3.2查看解析结果4.XPath查询4.1基本路径查询4.2使用属性查询4.3查询多个节点5.XPath的高级用法5.1使用逻辑运算符5.2使用函数6.实战案例6.1从网页抓取数据6.1.1安装Requests库6.1.2代
- PHP环境搭建详细教程
好看资源平台
前端php
PHP是一个流行的服务器端脚本语言,广泛用于Web开发。为了使PHP能够在本地或服务器上运行,我们需要搭建一个合适的PHP环境。本教程将结合最新资料,介绍在不同操作系统上搭建PHP开发环境的多种方法,包括Windows、macOS和Linux系统的安装步骤,以及本地和Docker环境的配置。1.PHP环境搭建概述PHP环境的搭建主要分为以下几类:集成开发环境:例如XAMPP、WAMP、MAMP,这
- Git常用命令-修改远程仓库地址
猿大师
LinuxJavagitjava
查看远程仓库地址gitremote-v返回结果originhttps://git.coding.net/*****.git(fetch)originhttps://git.coding.net/*****.git(push)修改远程仓库地址gitremoteset-urloriginhttps://git.coding.net/*****.git先删除后增加远程仓库地址gitremotermori
- python八股文面试题分享及解析(1)
Shawn________
python
#1.'''a=1b=2不用中间变量交换a和b'''#1.a=1b=2a,b=b,aprint(a)print(b)结果:21#2.ll=[]foriinrange(3):ll.append({'num':i})print(11)结果:#[{'num':0},{'num':1},{'num':2}]#3.kk=[]a={'num':0}foriinrange(3):#0,12#可变类型,不仅仅改变
- 【JS】执行时长(100分) |思路参考+代码解析(C++)
l939035548
JS算法数据结构c++
题目为了充分发挥GPU算力,需要尽可能多的将任务交给GPU执行,现在有一个任务数组,数组元素表示在这1秒内新增的任务个数且每秒都有新增任务。假设GPU最多一次执行n个任务,一次执行耗时1秒,在保证GPU不空闲情况下,最少需要多长时间执行完成。题目输入第一个参数为GPU一次最多执行的任务个数,取值范围[1,10000]第二个参数为任务数组长度,取值范围[1,10000]第三个参数为任务数组,数字范围
- webpack图片等资源的处理
dmengmeng
需要的loaderfile-loader(让我们可以引入这些资源文件)url-loader(其实是file-loader的二次封装)img-loader(处理图片所需要的)在没有使用任何处理图片的loader之前,比如说css中用到了背景图片,那么最后打包会报错的,因为他没办法处理图片。其实你只想能够使用图片的话。只加一个file-loader就可以,打开网页能准确看到图片。{test:/\.(p
- 【华为OD技术面试真题 - 技术面】- python八股文真题题库(4)
算法大师
华为od面试python
华为OD面试真题精选专栏:华为OD面试真题精选目录:2024华为OD面试手撕代码真题目录以及八股文真题目录文章目录华为OD面试真题精选**1.Python中的`with`**用途和功能自动资源管理示例:文件操作上下文管理协议示例代码工作流程解析优点2.\_\_new\_\_和**\_\_init\_\_**区别__new____init__区别总结3.**切片(Slicing)操作**基本切片语法
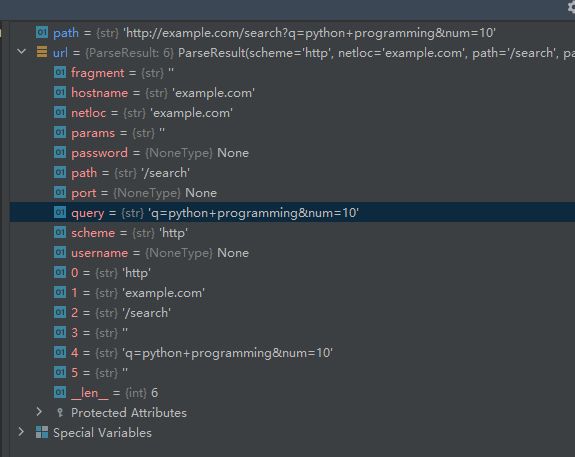
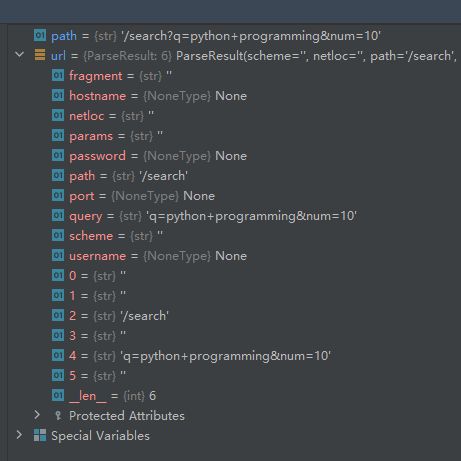
- Python爬虫解析工具之xpath使用详解
eqa11
python爬虫开发语言
文章目录Python爬虫解析工具之xpath使用详解一、引言二、环境准备1、插件安装2、依赖库安装三、xpath语法详解1、路径表达式2、通配符3、谓语4、常用函数四、xpath在Python代码中的使用1、文档树的创建2、使用xpath表达式3、获取元素内容和属性五、总结Python爬虫解析工具之xpath使用详解一、引言在Python爬虫开发中,数据提取是一个至关重要的环节。xpath作为一门
- 18、架构-可观测性之聚合度量
大树~~
架构javapython后端架构
聚合度量聚合度量是指对系统运行时产生的各种指标数据进行收集、聚合和分析,以了解系统的健康状况和性能表现。聚合度量是可观测性的关键组成部分,通过对度量数据的分析,可以及时发现系统中的异常和瓶颈。以下是对聚合度量各个方面的详细解析,并结合具体的数据案例和技术支撑。指标收集收集系统运行时产生的各种指标数据是聚合度量的基础。常见的指标包括CPU使用率、内存使用率、请求处理时间、请求数、错误率等。以下是指标
- 如何选择最适合你的项目研发管理软件?TAPD卓越版全面解析
北京云巴巴信息技术有限公司
产品经理需求分析
在当今快速发展的科技时代,项目研发管理软件已成为企业不可或缺的重要工具。面对市场上琳琅满目的产品,如何选择一款适合自己团队的项目研发管理软件呢?本文将围绕项目研发管理软件的选择标准,重点介绍TAPD卓越版的特点、优势以及使用体验,让你更好地理解和选择适合自己的项目研发管理软件。项目研发管理软件的选择标准在选择项目研发管理软件时,我们需要考虑以下几个方面的因素:功能全面性:软件是否覆盖了从需求管理、
- 剧本杀《鲸鱼马戏团》剧本杀剧透+真相答案复盘解析攻略
VX搜_奶茶剧本杀
本文为剧本杀《鲸鱼马戏团》剧本杀测评+部分真相复盘,获取完整真相复盘只需两步:①、关注微信公众号【奶茶剧本杀】→②、回复剧本杀《鲸鱼马戏团》即可获取查看剧本杀《鲸鱼马戏团》剧本杀真相答案复盘+凶手剧透:以下是玩家评测+部分关键证据,凶手,时间线,复盘解析,推理逻辑--------------------------------------------------------------------
- Some jenkins settings
SnC_
Jenkins连接到特定gitlabproject的特定branch我采用的方法是在pipeline的script中使用git命令来指定branch。如下:stage('Clonerepository'){steps{gitbranch:'develop',credentialsId:'gitlab-credential-id',url:'http://gitlab.com/repo.git'}}
- ArrayList 源码解析
程序猿进阶
Java基础ArrayListListjava面试性能优化架构设计idea
ArrayList是Java集合框架中的一个动态数组实现,提供了可变大小的数组功能。它继承自AbstractList并实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量capacity,表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添
- Kafka是如何保证数据的安全性、可靠性和分区的
喜欢猪猪
kafka分布式
Kafka作为一个高性能、可扩展的分布式流处理平台,通过多种机制来确保数据的安全性、可靠性和分区的有效管理。以下是关于Kafka如何保证数据安全性、可靠性和分区的详细解析:一、数据安全性SSL/TLS加密:Kafka支持SSL/TLS协议,通过配置SSL证书和密钥来加密数据传输,确保数据在传输过程中不会被窃取或篡改。这一机制有效防止了中间人攻击,保护了数据的安全性。SASL认证:Kafka支持多种
- Java爬虫框架(一)--架构设计
狼图腾-狼之传说
java框架java任务html解析器存储电子商务
一、架构图那里搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容数据库:存储商品信息索引:商品的全文搜索索引Task队列:需要爬取的网页列表Visited表:已经爬取过的网页列表爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。二、爬虫1.流程1)Scheduler启动爬虫器,TaskMast
- 光盘文件系统 (iso9660) 格式解析
穷人小水滴
光盘文件系统iso9660denoGNU/Linuxjavascript
越简单的系统,越可靠,越不容易出问题.光盘文件系统(iso9660)十分简单,只需不到200行代码,即可实现定位读取其中的文件.参考资料:https://wiki.osdev.org/ISO_9660相关文章:《光盘防水嘛?DVD+R刻录光盘泡水实验》https://blog.csdn.net/secext2022/article/details/140583910《光驱的内部结构及日常使用》ht
- Spring MVC 全面指南:从入门到精通的详细解析
一杯梅子酱
技术栈学习springmvcjava
引言:SpringMVC,作为Spring框架的一个重要模块,为构建Web应用提供了强大的功能和灵活性。无论是初学者还是有一定经验的开发者,掌握SpringMVC都将显著提升你的Web开发技能。本文旨在为初学者提供一个全面且易于理解的学习路径,通过详细的知识点分析和实际案例,帮助你快速上手SpringMVC,让学习过程既深刻又高效。一、SpringMVC简介1.1什么是SpringMVC?Spri
- 崩坏星穹铁道哪个角色值得培养 崩坏星穹铁道新手角色优先级教学
会飞滴鱼儿
崩坏星穹铁道新手角色培养攻略:哪些角色值得投资?在《崩坏星穹铁道》中,角色的强度和培养一直是玩家们关心的焦点。要想体验更爽快的游戏过程,选对角色至关重要。那么,哪些角色值得投资培养呢?本篇教学文章将针对新手玩家,从T0到T1强度的角色中为你做出详尽解析。游戏豹官网现在的手游平台很多,但是在游戏界有这么一个传说:“喜欢肝的玩家不如氪金玩家,氪金玩家不如内部福利玩家”,这就是游戏界可悲的生物链,很多平
- WebMagic:强大的Java爬虫框架解析与实战
Aaron_945
Javajava爬虫开发语言
文章目录引言官网链接WebMagic原理概述基础使用1.添加依赖2.编写PageProcessor高级使用1.自定义Pipeline2.分布式抓取优点结论引言在大数据时代,网络爬虫作为数据收集的重要工具,扮演着不可或缺的角色。Java作为一门广泛使用的编程语言,在爬虫开发领域也有其独特的优势。WebMagic是一个开源的Java爬虫框架,它提供了简单灵活的API,支持多线程、分布式抓取,以及丰富的
- 【2022 CCF 非专业级别软件能力认证第一轮(CSP-J1)入门级 C++语言试题及解析】
汉子萌萌哒
CCFnoi算法数据结构c++
一、单项选择题(共15题,每题2分,共计30分;每题有且仅有一个正确选项)1.以下哪种功能没有涉及C++语言的面向对象特性支持:()。A.C++中调用printf函数B.C++中调用用户定义的类成员函数C.C++中构造一个class或structD.C++中构造来源于同一基类的多个派生类题目解析【解析】正确答案:AC++基础知识,面向对象和类有关,类又涉及父类、子类、继承、派生等关系,printf
- 绝招曝光!3小时高效利用ChatGPT写出精彩论文
kkai人工智能
chatgpt人工智能ai学习媒体
在这份指南中,我将深入解析如何利用ChatGPT4.0的高级功能,指导整个学术研究和写作过程。从初步探索研究主题,到撰写结构严谨的学术论文,我将一步步展示如何在每个环节中有效运用ChatGPT。如果您还未使用PLUS版本,可以参考相关教程。**初步探索与主题的确定**起初,我处于庞大的知识领域中,寻找一个可深入研究的领域。ChatGPT如同灯塔,通过深入分析最新研究趋势和领域热点,帮助我在广阔的学
- ERP企业资源规划系统
点滴~
教育电商
ERP企业资源规划系统ERP(EnterpriseResourcePlanning)企业资源规划系统是一种综合性的管理信息系统,旨在通过信息技术手段实现对企业内部资源的全面规划、管理和控制。以下是对ERP企业资源规划系统的详细解析:一、定义与核心思想ERP系统建立在信息技术基础上,以系统化的管理思想,为企业决策层及员工提供决策运行手段的管理平台。它不仅仅是一个软件,更重要的是一个管理思想,实现了企
- 使用由 Python 编写的 lxml 实现高性能 XML 解析
hunyxv
python笔记pythonxml
转载自:文章lxml简介Python从来不出现XML库短缺的情况。从2.0版本开始,它就附带了xml.dom.minidom和相关的pulldom以及SimpleAPIforXML(SAX)模块。从2.4开始,它附带了流行的ElementTreeAPI。此外,很多第三方库可以提供更高级别的或更具有python风格的接口。尽管任何XML库都足够处理简单的DocumentObjectModel(DOM
- 每日OJ_牛客_马戏团(模拟最长上升子序列)
GR鲸鱼
c++算法开发语言牛客数据结构
目录牛客_马戏团(模拟最长上升子序列)解析代码牛客_马戏团(模拟最长上升子序列)马戏团__牛客网搜狐员工小王最近利用假期在外地旅游,在某个小镇碰到一个马戏团表演,精彩的表演结束后发现团长正和大伙在帐篷前激烈讨论,小王打听了下了解到,马戏团正打算出一个新节目“最高罗汉塔”,即马戏团员叠罗汉表演。考虑到安全因素,要求叠罗汉过程中,站在某个人肩上的人应该既比自己矮又比自己瘦,或相等。团长想要本次节目中的
- APQP,ASPICE,敏捷,功能安全,预期安全,这些汽车行业的一堆标准
二大宝贝
安全架构
前言APQP,ASPICE,敏捷,功能安全,预期安全,PMP,PRICE2汽车行业的有这样一堆标准。我是半路出家来到汽车行业做项目经理的,对几个标准的感觉是,看了文档和各种解析之后还是一头雾水,不知道到底说了个啥,别人问我还是一脸懵逼。APQP(TS16949的最重要工具),ASPICE(软件)这些是质量标准,是优化整个公司体系的,但这套体系对项目管理有要求;敏捷,PMP这些是项目管理的标准;项目
- 前端代码上传文件
余生逆风飞翔
前端javascript开发语言
点击上传文件import{ElNotification}from'element-plus'import{API_CONFIG}from'../config/index.js'import{UploadFilled}from'@element-plus/icons-vue'import{reactive}from'vue'import{BASE_URL}from'../config/index'i
- Shell脚本中sed使用
jcrhl321
linux
目录一、sed编辑器1、sed概述2、sed的工作流程3、sed命令的常见格式4、sed命令常用操作二、sed常用命令使用1、sed打印2、sed删除3、sed替换4、sed插入与增加4、sed剪切粘贴与复制粘贴一、sed编辑器sed(StreamEDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出
- “无”,有大用
我若盛开
2021/7/7日更36/100网图,侵删《道德经》节选解析“三十辐,共一毂;当其无,有车之用。埏埴以为器,当其无,有器之用。凿户牖以为室,当其无,有室之用。故有之以为利,无之以为用。”译文:三十根辐条汇集到一根毂的孔洞当中,有了车毂中空的地方,才有车的作用。揉和陶土做成器皿,有了器具中空的地方,才有器皿的作用。开凿门窗建造房屋,有了门窗四壁内的空虚部分,才有房屋的作用。所以,“有”只是提供了条件
- 打造专业投票评选平台:创建大型活动的完整指南
口碑信息传播者
在数字化时代,打造专业的投票评选平台成为举办大型活动的不可或缺的一环。本指南将深入探讨如何创建一个高效、安全、用户友好的投票平台,旨在帮助您成功举办大型投票评选活动。从平台的设计和功能规划到活动的推广和安全性保障,每个步骤都将得到详细解析。第一部分:构建投票平台的基础在创建投票平台之前,首先需要明确平台的基础构建要素:1.**投票平台的定义和关键功能:**确定您的平台将提供的服务和功能,包括投票方
- 2021-06-07 Do What You Are Meant To Do
春生阁
Don’tgiveupontryingtofindbalanceinyourlife.Sticktoyourpriorities.Rememberwhat’smostimportanttoyouanddoeverythingyoucantoputyourselfinapositionwhereyoucanfocusonthosepriorities,ratherthanbeingpulledbyt
- Enum 枚举
120153216
enum枚举
原文地址:http://www.cnblogs.com/Kavlez/p/4268601.html Enumeration
于Java 1.5增加的enum type...enum type是由一组固定的常量组成的类型,比如四个季节、扑克花色。在出现enum type之前,通常用一组int常量表示枚举类型。比如这样:
public static final int APPLE_FUJI = 0
- Java8简明教程
bijian1013
javajdk1.8
Java 8已于2014年3月18日正式发布了,新版本带来了诸多改进,包括Lambda表达式、Streams、日期时间API等等。本文就带你领略Java 8的全新特性。
一.允许在接口中有默认方法实现
Java 8 允许我们使用default关键字,为接口声明添
- Oracle表维护 快速备份删除数据
cuisuqiang
oracle索引快速备份删除
我知道oracle表分区,不过那是数据库设计阶段的事情,目前是远水解不了近渴。
当前的数据库表,要求保留一个月数据,且表存在大量录入更新,不存在程序删除。
为了解决频繁查询和更新的瓶颈,我在oracle内根据需要创建了索引。但是随着数据量的增加,一个半月数据就要超千万,此时就算有索引,对高并发的查询和更新来说,让然有所拖累。
为了解决这个问题,我一般一个月会进行一次数据库维护,主要工作就是备
- java多态内存分析
麦田的设计者
java内存分析多态原理接口和抽象类
“ 时针如果可以回头,熟悉那张脸,重温嬉戏这乐园,墙壁的松脱涂鸦已经褪色才明白存在的价值归于记忆。街角小店尚存在吗?这大时代会不会牵挂,过去现在花开怎么会等待。
但有种意外不管痛不痛都有伤害,光阴远远离开,那笑声徘徊与脑海。但这一秒可笑不再可爱,当天心
- Xshell实现Windows上传文件到Linux主机
被触发
windows
经常有这样的需求,我们在Windows下载的软件包,如何上传到远程Linux主机上?还有如何从Linux主机下载软件包到Windows下;之前我的做法现在看来好笨好繁琐,不过也达到了目的,笨人有本方法嘛;
我是怎么操作的:
1、打开一台本地Linux虚拟机,使用mount 挂载Windows的共享文件夹到Linux上,然后拷贝数据到Linux虚拟机里面;(经常第一步都不顺利,无法挂载Windo
- 类的加载ClassLoader
肆无忌惮_
ClassLoader
类加载器ClassLoader是用来将java的类加载到虚拟机中,类加载器负责读取class字节文件到内存中,并将它转为Class的对象(类对象),通过此实例的 newInstance()方法就可以创建出该类的一个对象。
其中重要的方法为findClass(String name)。
如何写一个自己的类加载器呢?
首先写一个便于测试的类Student
- html5写的玫瑰花
知了ing
html5
<html>
<head>
<title>I Love You!</title>
<meta charset="utf-8" />
</head>
<body>
<canvas id="c"></canvas>
- google的ConcurrentLinkedHashmap源代码解析
矮蛋蛋
LRU
原文地址:
http://janeky.iteye.com/blog/1534352
简述
ConcurrentLinkedHashMap 是google团队提供的一个容器。它有什么用呢?其实它本身是对
ConcurrentHashMap的封装,可以用来实现一个基于LRU策略的缓存。详细介绍可以参见
http://code.google.com/p/concurrentlinke
- webservice获取访问服务的ip地址
alleni123
webservice
1. 首先注入javax.xml.ws.WebServiceContext,
@Resource
private WebServiceContext context;
2. 在方法中获取交换请求的对象。
javax.xml.ws.handler.MessageContext mc=context.getMessageContext();
com.sun.net.http
- 菜鸟的java基础提升之道——————>是否值得拥有
百合不是茶
1,c++,java是面向对象编程的语言,将万事万物都看成是对象;java做一件事情关注的是人物,java是c++继承过来的,java没有直接更改地址的权限但是可以通过引用来传值操作地址,java也没有c++中繁琐的操作,java以其优越的可移植型,平台的安全型,高效性赢得了广泛的认同,全世界越来越多的人去学习java,我也是其中的一员
java组成:
- 通过修改Linux服务自动启动指定应用程序
bijian1013
linux
Linux中修改系统服务的命令是chkconfig (check config),命令的详细解释如下: chkconfig
功能说明:检查,设置系统的各种服务。
语 法:chkconfig [ -- add][ -- del][ -- list][系统服务] 或 chkconfig [ -- level <</SPAN>
- spring拦截器的一个简单实例
bijian1013
javaspring拦截器Interceptor
Purview接口
package aop;
public interface Purview {
void checkLogin();
}
Purview接口的实现类PurviesImpl.java
package aop;
public class PurviewImpl implements Purview {
public void check
- [Velocity二]自定义Velocity指令
bit1129
velocity
什么是Velocity指令
在Velocity中,#set,#if, #foreach, #elseif, #parse等,以#开头的称之为指令,Velocity内置的这些指令可以用来做赋值,条件判断,循环控制等脚本语言必备的逻辑控制等语句,Velocity的指令是可扩展的,即用户可以根据实际的需要自定义Velocity指令
自定义指令(Directive)的一般步骤
&nbs
- 【Hive十】Programming Hive学习笔记
bit1129
programming
第二章 Getting Started
1.Hive最大的局限性是什么?一是不支持行级别的增删改(insert, delete, update)二是查询性能非常差(基于Hadoop MapReduce),不适合延迟小的交互式任务三是不支持事务2. Hive MetaStore是干什么的?Hive persists table schemas and other system metadata.
- nginx有选择性进行限制
ronin47
nginx 动静 限制
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;...
server {...
location ~.*\.(gif|png|css|js|icon)$ {
- java-4.-在二元树中找出和为某一值的所有路径 .
bylijinnan
java
/*
* 0.use a TwoWayLinkedList to store the path.when the node can't be path,you should/can delete it.
* 1.curSum==exceptedSum:if the lastNode is TreeNode,printPath();delete the node otherwise
- Netty学习笔记
bylijinnan
javanetty
本文是阅读以下两篇文章时:
http://seeallhearall.blogspot.com/2012/05/netty-tutorial-part-1-introduction-to.html
http://seeallhearall.blogspot.com/2012/06/netty-tutorial-part-15-on-channel.html
我的一些笔记
===
- js获取项目路径
cngolon
js
//js获取项目根路径,如: http://localhost:8083/uimcardprj
function getRootPath(){
//获取当前网址,如: http://localhost:8083/uimcardprj/share/meun.jsp
var curWwwPath=window.document.locati
- oracle 的性能优化
cuishikuan
oracleSQL Server
在网上搜索了一些Oracle性能优化的文章,为了更加深层次的巩固[边写边记],也为了可以随时查看,所以发表这篇文章。
1.ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(这点本人曾经做过实例验证过,的确如此哦!
- Shell变量和数组使用详解
daizj
linuxshell变量数组
Shell 变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
your_name="w3cschool.cc"
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
首个字符必须为字母(a-z,A-Z)。
中间不能有空格,可以使用下划线(_)。
不能使用标点符号。
不能使用ba
- 编程中的一些概念,KISS、DRY、MVC、OOP、REST
dcj3sjt126com
REST
KISS、DRY、MVC、OOP、REST (1)KISS是指Keep It Simple,Stupid(摘自wikipedia),指设计时要坚持简约原则,避免不必要的复杂化。 (2)DRY是指Don't Repeat Yourself(摘自wikipedia),特指在程序设计以及计算中避免重复代码,因为这样会降低灵活性、简洁性,并且可能导致代码之间的矛盾。 (3)OOP 即Object-Orie
- [Android]设置Activity为全屏显示的两种方法
dcj3sjt126com
Activity
1. 方法1:AndroidManifest.xml 里,Activity的 android:theme 指定为" @android:style/Theme.NoTitleBar.Fullscreen" 示例: <application
- solrcloud 部署方式比较
eksliang
solrCloud
solrcloud 的部署其实有两种方式可选,那么我们在实践开发中应该怎样选择呢? 第一种:当启动solr服务器时,内嵌的启动一个Zookeeper服务器,然后将这些内嵌的Zookeeper服务器组成一个集群。 第二种:将Zookeeper服务器独立的配置一个集群,然后将solr交给Zookeeper进行管理
谈谈第一种:每启动一个solr服务器就内嵌的启动一个Zoo
- Java synchronized关键字详解
gqdy365
synchronized
转载自:http://www.cnblogs.com/mengdd/archive/2013/02/16/2913806.html
多线程的同步机制对资源进行加锁,使得在同一个时间,只有一个线程可以进行操作,同步用以解决多个线程同时访问时可能出现的问题。
同步机制可以使用synchronized关键字实现。
当synchronized关键字修饰一个方法的时候,该方法叫做同步方法。
当s
- js实现登录时记住用户名
hw1287789687
记住我记住密码cookie记住用户名记住账号
在页面中如何获取cookie值呢?
如果是JSP的话,可以通过servlet的对象request 获取cookie,可以
参考:http://hw1287789687.iteye.com/blog/2050040
如果要求登录页面是html呢?html页面中如何获取cookie呢?
直接上代码了
页面:loginInput.html
代码:
<!DOCTYPE html PUB
- 开发者必备的 Chrome 扩展
justjavac
chrome
Firebug:不用多介绍了吧https://chrome.google.com/webstore/detail/bmagokdooijbeehmkpknfglimnifench
ChromeSnifferPlus:Chrome 探测器,可以探测正在使用的开源软件或者 js 类库https://chrome.google.com/webstore/detail/chrome-sniffer-pl
- 算法机试题
李亚飞
java算法机试题
在面试机试时,遇到一个算法题,当时没能写出来,最后是同学帮忙解决的。
这道题大致意思是:输入一个数,比如4,。这时会输出:
&n
- 正确配置Linux系统ulimit值
字符串
ulimit
在Linux下面部 署应用的时候,有时候会遇上Socket/File: Can’t open so many files的问题;这个值也会影响服务器的最大并发数,其实Linux是有文件句柄限制的,而且Linux默认不是很高,一般都是1024,生产服务器用 其实很容易就达到这个数量。下面说的是,如何通过正解配置来改正这个系统默认值。因为这个问题是我配置Nginx+php5时遇到了,所以我将这篇归纳进
- hibernate调用返回游标的存储过程
Supanccy2013
javaDAOoracleHibernatejdbc
注:原创作品,转载请注明出处。
上篇博文介绍的是hibernate调用返回单值的存储过程,本片博文说的是hibernate调用返回游标的存储过程。
此此扁博文的存储过程的功能相当于是jdbc调用select 的作用。
1,创建oracle中的包,并在该包中创建的游标类型。
---创建oracle的程
- Spring 4.2新特性-更简单的Application Event
wiselyman
application
1.1 Application Event
Spring 4.1的写法请参考10点睛Spring4.1-Application Event
请对比10点睛Spring4.1-Application Event
使用一个@EventListener取代了实现ApplicationListener接口,使耦合度降低;
1.2 示例
包依赖
<p