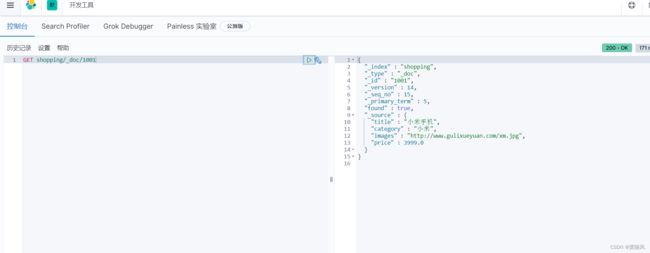
elasticsearch配置集群、读写流程、分词器
1、创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务

2.修改集群节点中的config/elasticsearch.yml 配置文件
node-1001的配置如下:
#集群名称,节点之间要保持一致
cluster.name: my-es
#节点名称,集群内要唯一
node.name: node-1
#代表可以是master节点
node.master: true
#代表可以是数据节点
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
#跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["localhost:9303", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5node-1002的配置如下:
#集群名称,节点之间要保持一致
cluster.name: my-es
#节点名称,集群内要唯一
node.name: node-2
#代表可以是master节点
node.master: true
#代表可以是数据节点
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1002
#tcp 监听端口
transport.tcp.port: 9302
#跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["localhost:9301","localhost:9303"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5node-1003节点配置如下
#集群名称,节点之间要保持一致
cluster.name: my-es
#节点名称,集群内要唯一
node.name: node-3
#代表可以是master节点
node.master: true
#代表可以是数据节点
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1003
#tcp 监听端口
transport.tcp.port: 9303
#跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 53.创建一个user索引分配三个主分片和一个副本(每个主分片拥有一个副本分片),即3个主分片和3个副本分片一共6个分片。
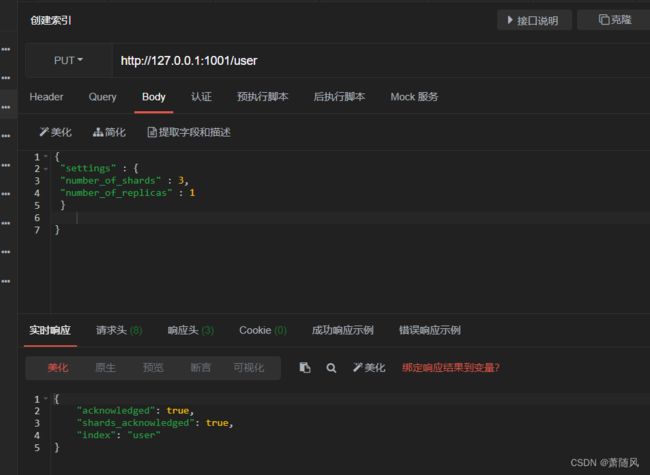
4.使用浏览器插件elasticsearch-head,访问查看界面
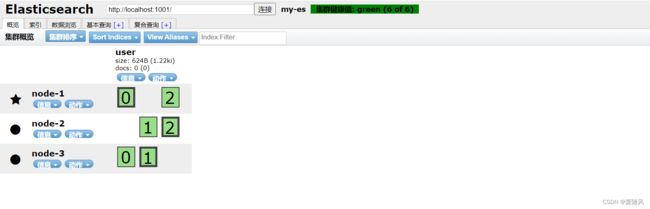
5.故障转移
所有索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们既可以从主分片又可以从副本分片上获得文档。
6.水平扩容
启动多个节点时为了分散负载对分片进行重新分配,如果想要动态调整副本分片数量,可以增加副本数比如副本数从1调整到2,从6个节点变成了9个节点,更多的副本分片数也会提高数据冗余量,最好选择合适的分配,保证不会丢失数据即可。
7.路由计算与分片控制
文档存储在分片中是根据公式 hash(routing)%主分片的数量,routing默认是文档的id,也可以设置成一个固定的值,routing 通过 hash 函数生成一个数字,对主分片数量求余,来决定存储在第几主分片上。
分片控制:用户可以访问任何一个节点获取数据,这个节点称为协调节点,访问的方式一般是轮询。
8.数据写流程
数据访问协调节点,根据公式计算出应存储在哪个节点,请求转发到指定节点,主分片将数据存储,主分片将数据发送到副本分片进行存储,存储完成后向客户端反馈。
Elasticsearch会设置consistency参数来表示必须要多少数量的分片副本处于活跃状态才会执行读写操作,公式计算int( (primary + number_of_replicas) / 2 ) + 1 ,number_of_replicas 指的是在索引设置中的设定 副本分片数。consistency参数的值可以设置成one表示只要主分片状态没问题就执行读写操作,设置成all表示必须主分片和所有分片副本都没问题才执行读写操作,默认是quorum表示大部分分片副本状态没问题就执行读写操作。
Elasticsearch设置timeout参数表示如果没有足够的分片副本,Elasticsearch会等待多少时间,默认是一分钟。
9.数据读流程
数据访问协调节点,协调节点计算数据所在的分片和全部副本位置,为了负载均衡,轮询访问节点,将请求转发具体的节点,节点返回查询结果,将结果反馈给客户端。
10.分析器和分词器
分析器包含字符过滤器,分词器,符号过滤器
分析器(analyzer)有标准分析器(standard):根据绝大部分标点分析,并转为小写,中文以字分
简单分析器(simple):根据所有标点分析,并转为小写
空格分析器(whitespace):根据空格分析
语言分析器(language):各种语言分析器
标准分析器是elasticsearch默认使用的分析器,无法将中文识别词汇,只能将中文分成一个个字,可以使用ik中文分词器。
下载地址: https://github.com/medcl/elasticsearch-analysis-ik,注意要下载和elasticsearch版本一致的,解压进es目录下的plugins目录下,重启es即可启用。
ik_max_word:会将文本做最细粒度的拆分
ik_smart:会将文本做最粗粒度的拆分
elasticsearch也可以自定义分析器
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type":"mapping",
//使用一个自定义的映射字符过滤器把 & 替换为 " and "
"mappings": [ "&=> and "]
}},
"filter": {
//使用自定义停止词过滤器移除自定义的停止词列表中包含的词
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}},
"analyzer": {
//分析器名称
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}}
}}}11.Kibana可视化界面
下载地址:Download Kibana Free | Get Started Now | Elastic
修改config目录下的kibana.yml文件
# 默认端口
server.port: 5601
# ES 服务器的地址
elasticsearch.hosts: ["http://localhost:9200"]
# 索引名
kibana.index: ".kibana"
# 支持中文
i18n.locale: "zh-CN"执行bin目录下的kibana.bat文件,访问localhost:5601点击控制台