第四章 数据中台架构PaaS层(平台服务层)之实时存储资源规划与架构设计
1、Kafka高可用设计
1.1、Kafka服务端高可用设计
- 高可用:leader挂了会通过Zookeeper重新选举,不存在单点故障问题
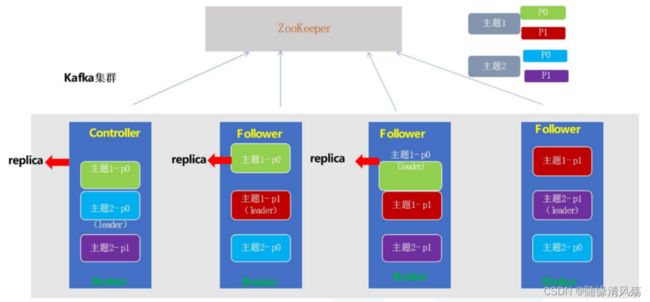
- Controller:负责各partition的Leader选举一级Replica的重新分配
kafka让所有的Broker都在Zookeeper的Controller节点注册一个Watcher,当Controller发生故障时对应的Controller临时节点会自动删除,此时注册在其上的Watcher会被触发,让所有活着的Broker都会区竞争成为新的Controller,竞选成功者即为Controller。
1.2、kafka服务端高并发设计
(1)同步顺序处理:每个请求必须等待前一个请求处理完了以后才会得到处理,吞吐量太差!
while(true){
Request request=accept(connection);
handle(request);
}
缺点:
-
①并发低:所有的处理放在一个线程里,这个线程压力很大,网络IO的处理总是要比CPU慢的多;
-
②网络延迟很大:如果这里有一个客户端的请求,处理比较复杂则会影响后面其他客户端的请求响应能力;
(2)半异步半同步编程:
- T1线程
while(1)
{
epoll_wait(...);
for(){
if(fd == listenner_socket)
{
cfd=accpt(listenner_socket);
}
else{
read(fd,buf,size);
enqueue(buf);
}
}
}
- T2线程
while(1){
wait_queue(buf);
process(buf);
}
- 缺点
- ①线程间需要同步;
- ②线程间有数据的拷贝(memcpy),这个拷贝也是很耗CPU
(3)异步处理:每个请求都创建一个线程去处理,请求不会阻塞,但是每个请求都创建一个线程开销太大
while(true){
Request request=accept(connection);
Thread thread = new Thread(handle(request));
thread.start();
}
(4)Reactor设计模式:引入NIO多路复用,高并发保证
- 架构概要设计:

- 架构详细设计:

-
注意事项:
-
第一层:对应Read HandlePool,线程数默认num.network.threads=3,如果想提高性能则可调大参数增加线程个数
-
第二层:对应MessageQueue
-
第三层:对应Handler ThreadPool,线程数默认num.io.threads=8,如果想提供性能则可调大参数增加线程个数,最好不高于CPU个数。
每个线程:2000QPS 8个线程:2000QPS=1.6wQPS -
①客户端发送请求到服务端;
②服务端由acceptor线程监听客户端请求,如果请求到来会将其封装为SocketChannel;
③SocketChannel被发送到线程池,按照轮询的方式将其线程池的一个连接队列里面;
④SocketChannel注册OP_READ事件,真正接收到客户端发送过来的请求**,此时请求以为跨网络传输为二进制格式**;
⑤Processor线程解析请求将其封装为一个Request对象发送到RequestQueue,主要起到缓冲作用;
⑥RequestHandlerPool从RequestChannel中不断获取请求,通过工具类将数据写到磁盘;
⑦工具类封装响应结果,将Response存到ResponseQueue队列里面。
⑧Processor线程拉取Response,将其注册为OP_WRITE事件,并发送回客户端。
2、Kafka的高性能设计
2.1、Kafka的服务端高性能设计
2.1.1、数据写入高性能 - 顺序写磁盘
-
P:kafka将详细记录持久化到本地磁盘中,一般人会认为是磁盘的读写性能比较差,对kafka性能如何提出质疑。
-
A:不管是内存还是磁盘,快或慢关键在于寻址的方式。磁盘和内存都有顺序读写和随机读写,基于磁盘的顺序读写高出磁盘的随机读写三个量级,甚至高于内存随机读写。

- 注意事项:kafka不断将数据写入到os cache中达到一定阈值批量顺序写磁盘。
2.1.2、数据读取高性能 - 索引文件
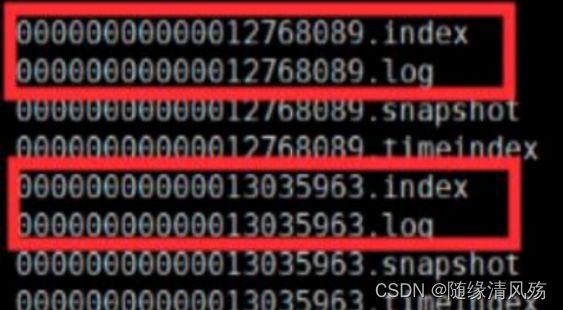
- kafka的文件存储:
- ①log文件:里面存储的是消息数据,文件名以log文件中的第一条消息的offset命名的。
- ②index文件:里面存储的是索引信息
Ⅰ、跳表设计:快速定位消息所在文件位置
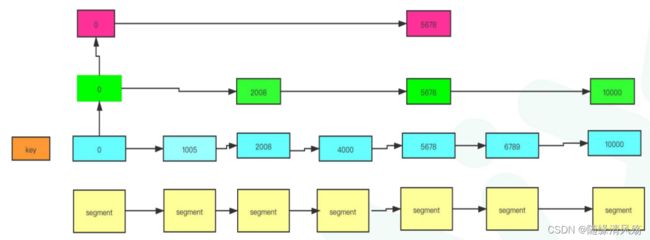
- P:快速找到offset=5000的消息
- A:跳表设计,构建多级索引,快速定位文件位置,以空间换时间。
Ⅱ、稀松索引:快速定位文件中的消息位置
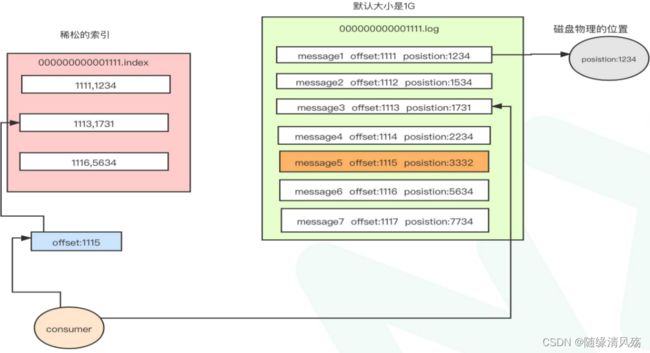
- P:如何在已定位的文件中快速找到消息位置
- A:稀疏索引(index文件),消息位置对应磁盘位置,,每隔4kb数据在index文件中记录下偏移量+物理磁盘位置。
业务场景:查找offset=1115的消息,首先在index文件中定位offset=1113的物理磁盘位置,之后顺序扫描1731之后的物理磁盘找到offset=1115的消息。
Ⅲ、零拷贝:

- 传统读取数据并发场景:
- ①操作系统将数据从磁盘文件中读取到内核空间的页面进行缓存;
- ②第一次拷贝:应用程序将数据从内核空间读入用户空间缓冲区;
- ③第二次拷贝:应用程序将读到的数据写回到内核空间并放入socket缓冲区;
- ④操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络进行发送。

零拷贝技术只用将磁盘文件的数据复制到系统缓冲区一次,然后将数据从页面的缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面进行缓存),避免了重复复制操作。
- 零拷贝场景:如果有10个消费者,传统方式下数据复制次数为4 * 10 = 40 次,而是用零拷贝技术只需要复制1 + 10 = 11 次,其中一次为从磁盘复制到页面缓存,10 次表示10个消费者各自读取一次页面缓存,由此可以看出kafka的效率是非常高的。
2.2、kafka客户端高性能设计
2.2.1、批处理方案设计

①生产者发送消息请求,生产者将其封装为ProducerRecord对象
②将其序列化后请求broker获取集群元数据;
③根据partitionor分区算法确定将消息存储到topic的某个分区,确定好将消息发送到某台服务器上;
- 0.8以前就截至到这里:来一条消息发送一条请求,这种设计性能上会比较差,请求建立连接次数太多。
④将**消息先存入RecordAccumulator(缓存)**中
⑤Sender线程将多条消息封装成一个batch发送到服务器上
2.2.2、RecordAccumulator内存池方案设计

RecordAccumulator 会由业务线程写入,经过哈希/轮询等分区策略计算出分区号,最后写入到对应TopicPartition,在Batchs队列中写入到RecordBatch中,等到RecordBatch达到批处理阈值后,最后Sender 线程批量读取到Broker的partition中。
3、服务配置文件参数
(1)num.io.threads=8
- broker处理磁盘IO的线程数 :主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍.
(2)num.network.threads=3
- broker处理消息的最大线程数:主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1.
(3)log.dirs=/data/kafka-logs
- 生产环境下会有多个目录,一个目录对应一个磁盘
4、实时存储平台资源评估与架构设计
- 评估目标:平台每天hold住10亿请求
4.1、QPS设计
(1)二八法则定QPS
每天集群需要承载10亿数据请求,一天24小时,对于网站晚上12点到陵城8点这8个小时几乎没有多少数据。使用二八法则估计,也就是80%的数据(8亿)会在其余16个小时涌入,而且8亿的80%的数据(6.4亿)会在16个小时的20%时间(3个小时)涌入。
QPS计算公式=6.4亿÷(3*60*60)=6万,故高峰期集群需要抗住每秒6万的并发
(2)副本数量估算存储
每天10亿条数据,每天请求10kb,也就是9T的数据,如果保存3副本,9✖3=27T,保留最近5天的数据,故需保留27*5=135T数据。
存储资源=10kb*10亿*3副本*5天
(3)QPS评估
如果资源充足,让高峰期QPS控制在集群能承载的总QPS的30%左右,故集群能承载的总QPS为20w才是安全的,根据经验一台物理机能支持4万QPS是没问题的,所以从QPS的角度上讲,需要5台物理机,再考虑上消费者请求,增加1.5倍,需要7~8台服务器。
4.2、磁盘评估
(1)磁盘数据评估
7台物理机,需要存储135T的数据,每台存储11T的数据,一般也就是11块盘,一个盘2T,要做磁盘预留。
log.dirs=/data1,/data2,/data3,......
#多磁盘目录
(2)磁盘类型选择
SSD是固态硬盘,比机械硬盘要快,主要快在磁盘随机读写性能上。
kafka是顺序写磁盘,机械硬盘顺序写性能跟内存读取性能差不多,所以kafka集群使用机械硬盘就可以了。
4.3、内存评估
经过相关业务处理,此集群有100各topic,这100个topic的partition的数据在os cache里效果是最好的。100个topic,一个topic有9个partition,则总共会有900个partition,每个partition的Log文件大小是1G,我们有3个副本,也就是说要900个topic的artition数据都驻留在内存需要2700G的内存。
我们现在有7台服务器,所以平均下来每台服务器需要400G内存,但是其实partition的数据我们没必要所有的都要驻留在内存中,10~20%的数据在内存里就非常好了,400G*0.2=80G就可以了,kafka进程需要6G内存(并没有创建很多对象),所以需要86G内存,故我们可以挑选128G内存的服务器就非常够用了。
- 注意事项:kafka与实时结合读取最新数据,大概占比10~20%比例。
4.4、CPU评估
CPU规划主要看Kafka进程里面有多少线程,线程主要是依托多核CPU来执行的,如果线程特别多,但是CPU核很少就会导致CPU负载很高,会导致整体工作线程执行的效率不高。

- kafka进程中的线程个数:
- Acceptor线程:1个
- Processor线程:默认3个,一般设置为9个
- RequestHandle线程:默认8个,一般设置为32个
- 日志清理线程
- 感知Controller状态的线程
- 副本同步的线程
估算下来Kafka内部有接近100个线程
4个CPU core,一般来说几十个线程,在高峰期CPU几乎都快打满了,8个CPU core,也就能够比较宽裕的支撑几十个线程繁忙工作,所以Kakfa的服务器一般建议是16核,基本上可以hold住一两百线程的工作,当然如果给到32cpu core那就更好。
5、实时存储平台规划
- 总体规划:10亿写请求,6w/s的吞吐量,9T的数据,7台物理机
- 硬盘:11(SAS) 1T,7200转*
- 内存:128GB,JVM分配6G,剩余给os cache
- CPU:16核/32核
- 网络:万兆网卡更佳
6、实时存储平台架构设计

(1)Zookeeper服务器:3台
(2)Kafka服务器:台
- kafka集群和HDFS集群的zookeeper可共用,一般建议分开(除非资源遇到瓶颈)
- 风险点:zookeeper集群挂掉则两个服务都不可用
7、实时存储平台核心配置
7.1、日志保留策略配置优化
建议减少日志保留时间,建议三天或者更短时间。通过log.retention.hours来实现,例如设置:
log.retention.hours=72
7.2、段文件大小优化
段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快,相反,如果文件过小,则文件数量比较多,kafka启动 时是单线程扫描目录(log.dir)下所有数据文件,文件较多时性能会稍微降低。可通过如下选项配置段文件大小:
log.segment.bytes=1073741824
7.3、log数据文件刷盘策略优化
为了大幅度提高producer写入吞吐量,需要定期批量写文件 优化建议为:每当producer写入10000条消息时,刷数据到磁盘。可通过如下选项配置:
log.flush.interval.messages=10000
每间隔1秒钟时间,刷数据到磁盘。可通过如下选项配置:
log.flush.interval.ms=1000
7.4、提升并发处理能力
num.io.threads =8,num.network.threads =4