chatGPT API调用指南,GPT3.5 turbo API,上下文携带技巧,python函数封装
概要
chatGPT是openAI的一款语言类人工智能聊天产品,除了在官网直接使用外,我们还可以通过发起http请求调用官方的gpt3.5turbo API来构建自己的应用产品。
内容概述:
1本篇博客使用python语言演示了如何简单调用chatGPT接口
2简单描述了chatGPT接口可选的一共12个参数
3从实践案例角度对于API进行函数式封装
gpt-3.5-turbo官方文档
https://platform.openai.com/docs/introduction/overview
官方文档链接点击跳转
英文好、有时间可以直接研究官方文档。
简单例子
首先需要安装python包openai
pip install openai
pip list查看版本号:openai 0.27.2
下面的例子向openai的chatgpt API发送消息“你好”,然后输出应答。
图一:获取api_key
import os
import openai
openai_api_key = os.getenv("openai_api_key")
openai.api_key=openai_api_key
def example1():
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "你好"}
]
)
print(response.get("choices")[0]["message"]["content"])
if __name__ == '__main__':
example1()
openai.ChatCompletion.create中填写了两个必要参数,模型名、消息。
openai_api_key需要在API官网获取,链接在上面已经贴过了。 然后设置为环境变量,或者直接粘贴字符串在这里也可以。
详细参数示例
def example2():
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "你好"}
],
temperature=1.5, # 0-2之间,越大越随机,越小越确定
top_p=1, #随机取前多少概率的token,0.1意味着取前10%,越小越确定。top_p temperature两个参数推荐只使用一个
n=2,#生成几个回答,默认是1个,我这里让它生成2个
stream=False,#是否流式获得结果,流式就是chatgpt官网那种,结果是一点一点蹦出来的,用于长句子先得到部分结果
stop="我",#停止词,生成出来“我”就停止生成
max_tokens=100,#最多生成的token数量
presence_penalty=0,#(-2.0,2.0) 越大模型就趋向于生成更新的话题,惩罚已经出现过的文本
frequency_penalty=0,#(-2.0,2.0) 惩罚出现频率高的文本
#logit_bias=None,#设置token的先验偏置
user="会写代码的孙悟空"#一个表示您的终端用户的唯一标识符,可帮助OpenAI监控和检测滥用行为
)
print(response)
print(response.get("choices")[0]["message"]["content"])
print(response.get("choices")[1]["message"]["content"])
output:
你好!
你好!有什么
temperature参数示意图
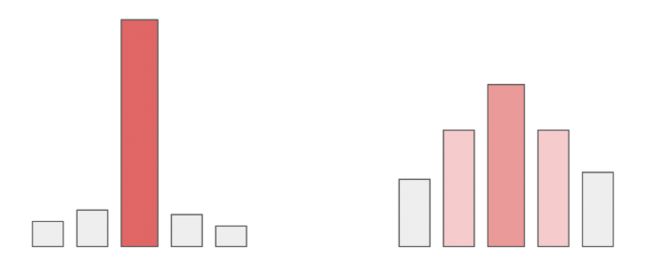
图:temperature参数改变概率分布,左较小temperature,右较大temperature
top_p=1 就是以图中的概率分布取样本,注意低柱子只是取到的概率小
top_p=0.2 取前20%的样本,就只有高柱子这一种情况了
top_p=0.4 取前40%的样本,从第一高与第二高中取。
API封装
说明:从实践案例角度对于API进行函数式封装,方便开发。
response是python字典格式:
{
'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-3.5-turbo',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'},
'finish_reason': 'stop',
'index': 0
}
]
}
字段很多,只使用最关键的content,也就是回复文本内容。
一次对话API封装
一问一答,无上下文
def chat_once(prompt):
try:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
return response.get("choices")[0]["message"]["content"]
except:
return ""
def test_chat_once():
res=chat_once("你好")
print(res)
if __name__ == '__main__':
test_chat_once()
一次对话+角色扮演
def chat_once_with_sb(prompt,sb): #sb:some body 不是骂人
try:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": sb},
{"role": "user", "content": prompt}
]
)
return response.get("choices")[0]["message"]["content"]
except:
return ""
def test_chat_once_with_sb():
prompt="请问你擅长什么?"
sb="医生"
res=chat_once_with_sb(prompt,sb)
print(res)
if __name__ == '__main__':
test_chat_once_with_sb()
output:
作为一个 AI 医生,我可以提供广泛的医疗领域的知识和帮助。我可以帮你获取医疗信息、提供急救指导并回答健康问题。 但是,我不能进行具体治疗和诊断,如果您有任何身体不适或医务问题,建议立即咨询专业医生或上医院检查。
连续对话保存所有上下文
class ChatGPT:
def __init__(self,sb="You are a helpful assistant."):
self.sb=sb
self.messages=[
{"role":"system","content":sb}
]
def send(self,prompt):
try:
self.messages.append({"role":"user","content":prompt})
response=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=self.messages
)
response_txt=response.get("choices")[0]["message"]["content"]
self.messages.append({"role": "assistant", "content": response_txt})
return response_txt
except:
return ""
def test_ChatGPT():
chatgpt=ChatGPT()
while True:
text=input()
if(text==""):break
res=chatgpt.send(text)
print(res)
if __name__ == '__main__':
test_ChatGPT()
output:
