A Survey of Transformers论文解读
Transformer [137]是一个已经广泛应用于各种领域的重要的深度学习模型, 例如自然语言处理(NLP),计算机视觉(CV)以及语音处理。 Transformer was originally proposed as a sequence-to-sequence model [130] for machine translation. Later works show that Transformer-based pre-trained models (PTMs) [100] can achieve state-ofthe-art performances on various tasks. As a consequence, Transformer has become the go-to architecture in NLP, especially for PTMs. In addition to language related applications, Transformer
has also been adopted in CV [13, 33, 94], audio processing [15, 31, 41] and even other disciplines, such as chemistry [114] and life sciences [109].
Due to the success, Transformer的许多变体 (称为 X-formers) 近些年被提出。这些X-formers从许多不同的角度提升了最初的Transformer。
- Model Efficiency:应用Transformer的一个主要的挑战是its inefficiency at processing long sequences mainly due to the computation and memory complexity of the self-attention module. 这些提升方法包括lightweight attention (e.g. sparse attention variants) 以及 Divide-and-conquer methods (e.g., recurrent and hierarchical mechanism).
- Model Generalization:由于transformer是一个flexible architecture and makes few assumptions on the structural bias of input data, it is hard to train on small-scale data. 提升方法包括introducing structural bias or regularization, pre-training on large-scale unlabeled data, etc.
- Model Adaptation. This line of work aims to adapt the Transformer to specific downstream tasks and applications.
在这篇综述中,我们旨在提供关于Transformer以及它的变体的一个详细的调查。尽管我们可以organize X-formers on the basis of the perspectives mentioned above, many existing X-formers may address one or several issues. For example, sparse attention variants not
only reduce the computational complexity but also introduce structural prior on input data to alleviate the overfitting problem on small datasets. Therefore, it is more methodical to categorize the various existing X-formers and propose a new taxonomy mainly according to their ways to improve the vanilla Transformer: architecture modification, pre-training, and applications. Considering the audience of this survey may be from different domains, we mainly focus on the general architecture variants and just briefly discuss the specific variants on pre-training and applications.
2 背景
2.1 Vanilla Transformer
The vanilla Transformer [137] is a sequence-to-sequence model and consists of an encoder and a decoder, each of which is a stack of L L L identical blocks. Each encoder block is mainly composed of a multi-head self-attention module and a position-wise feed-forward network (FFN). For building a deeper model, a residual connection [49] is employed around each module, followed by Layer Normalization [4] module. Compared to the encoder blocks, decoder blocks additionally insert cross-attention modules between the multi-head self-attention modules and the position-wise FFNs. Furthermore, the self-attention modules in the decoder are adapted to prevent each position from
attending to subsequent positions. The overall architecture of the vanilla Transformer is shown in Fig. 1.
在后续的子节中,我们介绍vanilla Transformer的各个核心模块。
2.1.1 Attention Modules
Transformer adopts attention mechanism with Query-Key-Value (QKV) model. Given the packed matrix representations of queries Q ∈ R N × D k Q\in\mathbb{R}^{N\times D_k} Q∈RN×Dk,keys K ∈ R M × D k K\in\mathbb{R}^{M\times D_k} K∈RM×Dk,and values V ∈ R M × D v V\in\mathbb{R}^{M\times D_v} V∈RM×Dv,the scaled dot-product attention used by Transformer is given by
Attention(Q,K,V) = softmax ( Q K T D k ) V = A V ( 1 ) \text{Attention(Q,K,V)}=\text{softmax}(\frac{QK^T}{\sqrt{D_k}})V=AV\quad\quad\quad\quad\quad\quad(1) Attention(Q,K,V)=softmax(DkQKT)V=AV(1)
这里 N N N和 M M M表示 the lengths of queries and keys (or values); D k D_k Dk以及 D v D_v Dvdenote the dimensions of keys (or queries) and values; A = softmax ( Q K T D k ) A=\text{softmax}(\frac{QK^T}{\sqrt{D_k}}) A=softmax(DkQKT)通常被称为attention matrix; softmax is applied in a row-wise manner. The dot-products of queries and keys are divided by D k \sqrt{D_k} Dkto alleviate
gradient vanishing problem of the softmax function.
Instead of simply applying a single attention function, Transformer uses multi-head attention, where the D m D_m Dm-dimensional original queries, keys and values are projected into D k , D k D_k,D_k Dk,Dk以及 D v D_v Dv
dimensions, respectively, with H H H different sets of learned projections. For each of the projected queries, keys and values, and output is computed with attention according to Eq. (1). The model
then concatenates all the outputs and projects them back to a D m D_m Dm-dimensional representation.
待补充
3 transformer的分类
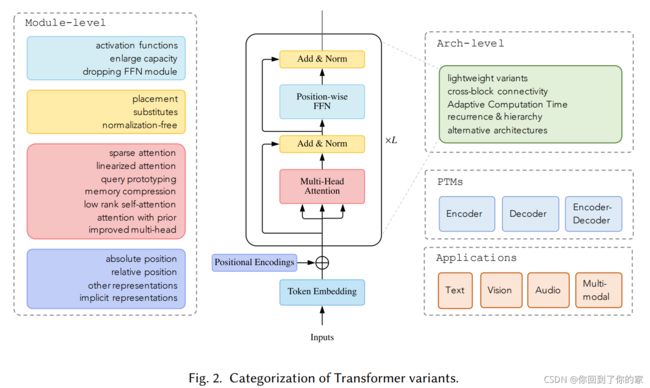
A wide variety of models have been proposed so far based on the vanilla Transformer from three perspectives: types of architecture modification, pre-training methods, and applications. Fig. 2 gives
an illustrations of our categorization of Transformer variants.