Go语言学习笔记
目录
一、引入
1.1 为什么go语言?
1.2 Go语言的特点:
1.3 Golang的开发工具的介绍:
1.4 windows下配置环境变量:
1.5 linux搭建Go开发环境:
1.7 Golang执行流程的分析:
1.7.1 go build ***.go + ***.exe 与 go run ***.go的区别
1.7.2 什么是编译?
1.8 Go程序开发的注意事项:
二、Golang的基本语法
2.1 常量:
2.2 Golang的变量及使用:
2.2.1 使用变量的过程:
2.2.2 多个变量的一次性定义
2.2.3 全局变量的一次性定义
2.2.4 注意:
2.2.5 变量的作用域
2.3 数据类型:
2.3.1 基本数据类型:
2.3.2 派生/复杂数据类型:
2.3.3 基本数据类型的默认值(又称为零值)
2.4 Go语言数据类型转换:
2.4.1 基本数据类型间的相互转换
2.4.2 基本数据类型 与 string类型的转换:
2.4.3 字符串 转换成 基本数据类型:
2.5 一维、二维数组:
2.5.1 一维数组:
2.5.2 二维数组
2.6 切片slice
2.7 string字符串
2.8 map
2.8.1 map关系数组
2.8.2 map切片:
2.8.3 map排序:
2.8.4 map的使用细节:
2.9 指针
2.10 值类型和引用类型
2.11 标识符:
2.11.1 标识符的概念:
2.11.2 标识符命名的规范:
2.11.3 系统保留关键字
2.11.4 预定义标识符:
2.12 运算符:
2.12.1 算数运算符:
2.12.2 关系运算符:
2.12.3 逻辑运算符:
2.12.4 赋值运算符:
2.12.5 位运算符:
2.12.6 取址符:
2.12.7 运算符的优先级:
2.13 流程控制
2.13.1 顺序控制
2.13.2 分支控制
2.13.3 循环控制
2.14 函数:
2.14.1 写法
2.14.2 打包/引包的方法:
2.14.3 函数调用的底层机制:
2.14.4 递归调用:
2.14.5 函数的注意事项:
2.14.6 init函数的基本介绍:
2.14.7 匿名函数:
2.14.8 闭包:
2.14.9 defer的基本使用:
2.14.10 字符串常用的系统函数:
2.14.11 时间和日期相关的函数:
2.14.12 内置函数builtin:
2.15 Go语言错误处理机制:
三、面向对象编程
3.1 引入
3.2 结构体:
3.2.1 使用细节
3.2.2 创建结构体变量 和 访问结构体字段:
3.2.3 结构体的内存分配机制:
3.3 方法的声明、调用和传参机制:
3.3.1 方法和函数的区别:
3.3.2 方法的声明和定义:
3.3.3 方法的访问范围和传参机制:
3.3.4 自定义数据类型都可以有方法:
3.3.5 结构体中的String()方法
3.3.6 工厂模式:
3.4 接口
3.4.1 go语言核心interface:
3.4.2 接口的应用场景:
3.4.3 接口的注意细节:
3.4.4 interface的最佳实践:
3.4.5 接口与继承的关系:
3.4.6 接口、继承解决的问题不同:
3.4.7 类型断言:
3.4.8 类型断言的最佳实践:
3.5 封装、继承和多态
3.5.1 封装
3.5.2 继承
3.5.3 多态
四、文件
4.1 文件的基础认识
4.2 读取文件内容并显示在终端
4.2.1 带缓冲区的方式:
4.2.2 一次性读取的方式:
4.3 给文件写内容
4.3.1 打开文件
4.3.2 使用带缓存的方式写文件:
4.4 读写文件
4.5 扩展应用
4.5.1 将文件的内容,拷贝到另一个文件中
4.5.2 判断一个文件/文件夹是否存在的方法
4.5.3 统计文件中,英文、数字、空格 和 其他字符的数量:
4.6 获取命令行参数
4.6.1 os.Args获取命令行参数
4.6.2 flag包解析命令行参数
4.7 json数据格式
4.7.1 基本介绍:
4.7.2 json数据格式说明:
4.7.3 json序列化:
4.7.4 json反序列化
五、单元测试
六、goroutine协程和channel管道
6.1 goroutine协程
6.1.1 进程和线程:
6.1.2 并行和并发:
6.1.3 Go协程和Go主线程
6.1.4 goroutine的调度模型:MPG模式
6.1.5 goroutine协程存在的问题
6.2 channel管道
6.2.1 介绍
6.2.2 基本使用:
6.3 channel的遍历和关闭:
6.3.1 channel的关闭:
6.3.2 channel的遍历:
6.4 goroutine和channel的结合案例:
6.4.1 两个协程同时操作一个管道
6.4.2 多个协程同时操作多个管道
6.5 管道阻塞机制:
6.6 channel使用注意事项:
6.6.1 声明channel为只读/只写属性:
6.6.2 select解决管道取数据的阻塞问题:
6.6.3 recover解决协程中出现panic,而导致整个程序崩溃的问题:
七、反射
7.1 引入:
7.2 基本介绍:
7.3 反射重要的函数和概念:
7.4 反射的实践:
一、引入
1.1 为什么go语言?
1、计算机硬件技术更新频繁,目前的主流编程语言不能合理利用多核多CPU的优势提升软件系统的性能。
2、目前的编程语言:不够简洁、风格不统一、计算能力不强、处理大并发不够好。
3、c/c++运行速度快,但编译的速度却很慢,且存在内存泄漏的风险。
1.2 Go语言的特点:
1、Go = C + Python;
- 具有c语言,静态编译的安全和性能;
- 又达到了python语言,动态语言开发维护的高效率;
2、从c语言继承了很多概念:表达式语法、控制结构、基础数据类型、调用参数传值,指针等,也保留了c语言一样的编译执行方式及弱化的指针;
3、引入包的概念:用于组织程序结构,Go语言的一个文件要归属一个包,不能单独存在;
包的初始化过程(如下图):Go引导程序,会先对整个程序的包进行初始化;
Go语言包的初始化有如下特点:
-
包初始化程序从 main 函数引用的包开始,逐级查找包的引用,直到找到没有引用其他包的包,最终生成一个包引用的有向无环图;
-
Go 编译器会将有向无环图转换为一棵树,然后从树的叶子节点开始逐层向上对包进行初始化;
-
单个包的初始化过程如上图所示,先初始化常量,然后全局变量,最后执行包的 init 函数。

包的三大作用:
- 区别相同名字的函数、变量等标识符;
- 当程序文件很多时,可以很好的管理项目;
- 控制函数、变量等访问范围,即作用域;
包的相关说明:
- 打包:
package 包名;引入包:import 包路径; - import包时,路径是从$GOPATH的src下开始的,不用再带src,编译器自动从src开始引入 ;
- 文件包名 和 文件所在的文件夹的名字,一般是一致的,均为小写;
- 为了让其他包的文件可以访问到本包的函数,则该函数名的首字母需要大写,类似于其他语言的public,这样才能挎包访问;挎包访问的格式:包名.函数名();
- 同一个包下,不能有相同函数名的函数;也不能有相同的全局变量名;
4、垃圾回收机制:内存自动回收,不需要开发人员管理;
5、天然并发:
- 从语言底层支持并发,实现简单;
goroutine轻量级线程,可实现大并发处理,高效利用多核;- 基于CPS(communicating sequential processes)实现;
6、管道通信机制:吸收了管道通信机制,形成了Go语言特有的管道channel;通过管道,可以实现不同的goroutine之间的相互通信;
7、支持函数有多个返回值;
8、切片slice、延时执行defer等;
1.3 Golang的开发工具的介绍:
VSCode、Eclipse、vim、sublime text等。- 搭建SDK(
software development kit)软件开发工具包,用./bin/go.exe来编译和运行go代码。 - VScode安装Golang插件时,遇到的问题及解决方案:

1.4 windows下配置环境变量:
windows系统在查找可执行文件时,在当前目录下如果不存在,则windows系统会在系统中已有的一个path的环境变量指定的目录中查找,故需要将go所在的路径C:/Golang/bin定义在path环境变量中,以便在任何目录下和都可以执行go指令。
- 在系统变量path中,增加C:\Golang\bin;
- 新建GOPATH环境变量,用来存放go的项目的工作路径F:\Go_Project;
1.5 linux搭建Go开发环境:
- 查看linux系统的位数32/64,在终端输入:
uname -a查看; - 将
go1.9.2linux-amd64.tar.gz放入SharedDocuments_ubuntu文件夹下,在linux终端,通过cd ./mnt/hgfs/SharedDocuments_ubuntu/下,可查看到该压缩文件,并输入tar -zxvf go1.9.2linux-amd64.tar.gz -c /home/guangyuansun1/; - linux下配置环境变量,在/etc/profile文件夹下添加三条语句:
export GOROOT = /home/guangyuansun1/go
export PATH = $PATH:$GOROOT/bin
export GOPATH = /home/guangyuansun1/Go_Projects/1.7 Golang执行流程的分析:
1.7.1 go build ***.go + ***.exe 与 go run ***.go的区别
1)如果先编译go build ***.go并生成可执行文件,则能够将可执行文件移植到没有go开发环境的机器上运行***.exe。如果直接调用 go run ***.go,必须使机器上配置了go开发环境;
2)在编译时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以,编译后生成的可执行文件比.go文件大很多;
1.7.2 什么是编译?
- 有了go源文件之后,通过编译器将其编译成机器能够识别的二进制码文件;
- 通过
go build ***.go,可以完成编译的过程,windows会生成.exe文件,linux则会生成.o文件,但都是可执行的二进制文件; - 可以通过
go build -o m_hello.exe hello.go来指定可执行文件的名字;
package main // 表示 hello.go 文件所在的包是 main;
import "fmt" // 引入fmt包(format),以便调用fmt包中的函数
func main() { // func(function)是关键字
fmt.Println("hello world!")
}
// 在cmd终端执行,并跳转到.go文件所在的文件夹位置
go build hello.go // 编译后,会生成hello.exe可执行文件文件
hello.exe // 运行hello.exe可执行文件
// 或者直接用 go run hello.go,会将编译和运行合并执行1.8 Go程序开发的注意事项:
- Go源文件是.go文件结尾;
- Go语言会在每行后自动加分号;
- Go编译器是一行行进行编译的,故在写程序要保证一行就一条语句;
- Go语言定义的变量未使用 或者 import的包没有使用,代码不能编译通过;
- Go语言的注释comment :1)提高代码的可阅读性;2)多行注释的快捷键:
ctrl + /; -
Go语言常用的转义字符escape char:
\t:制表符,对齐作用 \n:换行符 \\:一个\ \":一个" \r:是一个回车,用来将/r之后的内容覆盖掉开头的内容 package main // 表示 hello.go 文件所在的包是 main; import "fmt" // 引入fmt包(format),以便调用fmt包中的函数 func main() { // func(function)是关键字 fmt.Println("hello world!") fmt.Println("F:\\\\go.exe") // 两个//,表示一个// fmt.Println("hello\"world\"") // 这里的/"***/"是为了输出***的内容 fmt.Println("***** world\rhello") // 这里会将/r之后的内容,用来覆盖开头的内容并输出 } -
Golang的API学习网站:Go官方网站、 Go语言中文网 - Golang中文社区
-
Golang中调用一个函数的方式:import 包 包名.函数名();
-
Dos的基本操作原理:cmd(Dos操作系统的终端) --> 输入的命令会用Dos来对指令进行解析,并响应(绝对路径:从当前盘开始定位;相对路径:从当前位置开始定位)。
| Dos常用的操作指令 | 作用 |
|---|---|
| dir | 显示一个目录中的文件和子目录 |
| cd | 显示当前目录的名称或将其更改 |
| cls | 清除屏幕 |
| cmd | 打开另一个 Windows 命令解释程序窗口 |
| help | 提供 Windows 命令的帮助信息 |
| tree | 以图形方式显示驱动程序或路径的目录结构 |
| mkdir | 创建一个空目录 |
| rd /s *** rd /q/s *** |
删除***文件,并且带询问(推荐使用) 删除***文件,并且不带询问 |
| exit | 退出 cmd.exe 程序(命令解释程序) |
| echo *** | 在命令行窗口显示***的内容,或将命令回显打开或关闭 |
| echo .> ***.txt | 创建***.txt文件 |
| del ***.txt | 删除***.txt文件 |
| copy ***.txt destination_path | 将***.txt文件拷贝到destination_path目标路径 |
| move ***.txt destination_path | 将一个或多个文件从一个目录移动到另一个目录(剪切) |
二、Golang的基本语法
2.1 常量:
-
常量要从const修饰,且在定义是必须初始化;
-
常量表达式的值在编译期计算,而不是在运行期;
-
常量间的所有算术运算、逻辑运算和比较运算的结果也是常量;对常量的类型转换操作或以下函数调用都是返回常量结果:len、cap、real、imag、complex和unsafe.Sizeof;
-
常量只能修饰bool类型、数值类型(int、float系列)、string类型;
-
语法:
const identifier [type] = value; -
iota常量生成器:用于生成一组以相似规则初始化的常量。在一个const声明语句中,在第一个声明的常量所在的行,iota将会被置为0,然后在每一个有常量声明的行加一;
const (
a = itoa // a==0
b // b==1
c // c==2
)
const (
a = 1
b = 2
)
const (
a = itoa
b, c = itoa, itoa // a==0,b==1,c==1
)
const (
a = itoa
b = itoa
c = itoa // a==0,b==1,c==2
)- 常见的常量类型:

-
常量名大小写可以控制访问范围:大写则可以挎包访问,小写则不可以;
2.2 Golang的变量及使用:
变量,是程序的基本组成单位,是内存中一个数据存储空间的表示,故通过变量名可以访问到变量。这个内存空间,有自己的类型(变量的数据类型)和名称(变量名)。
2.2.1 使用变量的过程:
1)声明变量;2)赋值;3)使用;(其中,1)和 2)可以结合使用)
package main
import "fmt"
import "reflect"
func main() {
var i int // 声明整型变量,整型的默认值是0
i = 10 // 给整型变量赋值
//var i int = 10 // 声明并给整型变量赋值
// 变量类型推导:
i = 10.0
fmt.Printf("type(i): %T\n", i)
j := 'a' // 等价于 var j char j = 'a'
fmt.Println("j's type: ", reflect.TypeOf(j))
k := "str" // 等价于 var k string = "str"
fmt.Println("k's type: ", reflect.TypeOf(k))
fmt.Println("i =", i)
fmt.Printf("j = %c\n", j)
fmt.Println("k =", k)
}// 产生1~100的随机数:
package main
import "fmt"
import "math/rand"
import "time"
func main() {
// 设置随机数种子,time.Now().Unix():返回的1970:0:0到现在的秒数
rand.Seed(time.Now().Unix())
//生成1~100的随机数
n := rand.Intn(100) + 1
fmt.Println(n)
}2.2.2 多个变量的一次性定义
// golang一次定义多个变量的三种方式:
var i1, j1, k1 int
i1, j1, k1 = 10, 10, 10
var i2, j2, k2 = 20, 20.0, "str2"
i3, j3, k3 := 20, 30.0, "str3"
fmt.Println("i1 =", i1, "j1 =", j1, "k1 =", k1)
fmt.Println("i2 =", i2, "j2 =", j2, "k2 =", k2)
fmt.Println("i3 =", i3, "j3 =", j3, "k3 =", k3)2.2.3 全局变量的一次性定义
package main
import "fmt"
// 全局变量的一次性定义
var (
i4 = 40
j4 = 40.0
k4 = "str4"
)
func main() {
fmt.Println("i4 =", i4, "j4 =", j4, "k4 =", k4)
}2.2.4 注意:
- 数据值可以在同一类型范围内不断变化;
- 变量在同一作用域内不能重名;
- 变量 = 变量名 + 数据类型 + 变量值;
- golang语言中声明的变量没有赋值,则会有默认值,
int:0、float:0、string:""; - 程序中的+号:两边是数值,则是加法运算;两边是字符串,则是字符串的拼接;
2.2.5 变量的作用域
- 局部变量:函数内部声明和定义、使用;
- 全局变量:函数外声明和定义、使用,该变量在整个包中有效(如果首字母大写,则在整个程序中的其他包中也是有效);
- 当全局变量和局部变量同名时,会采用“就近原则”;
// 全局变量的定义时的注意事项:
var n1 int = 10 // 正确
n2 := 10 // 报错,因为该语句等价于 var n2 int n2 = 10,故报错发生了(第二条语句,不能在函数外进行赋值操作)2.3 数据类型:
2.3.1 基本数据类型:
数值型(整型(int、int8(代表8位的整型)、int16、int 32、int64、uint、uint8、uint16、uint32、uint64、byte)、浮点型(float32、float64))、字符型(没有专门的字符型,使用byte来保存单个字符)、布尔型、字符串(go将string归为基本数据类型)
2.3.2 派生/复杂数据类型:
指针Pointer、数组、结构体struct、管道Channel、函数(也是一种数据类型)、切片slice、接口interface、map
2.3.3 基本数据类型的默认值(又称为零值)
| 数据类型 | 默认值 |
|---|---|
| 整型 | 0 |
| 浮点型 | 0 |
| 字符串" | "" |
| 布尔类型 | false |
注:
- 格式化输出
fmt.printf()中,%v表示按照变量的值输出,%T表示输出变量的类型; - golang中查看变量占用的字节数,可以调用unsafe包中的Sizeof()函数;
- 写程序时整型变量采用 “保小不保大” 的原则;
- Golang中统一采用utf-8编码;
有符号整型
| 类型 | 有无符号 | 占用存储空间 | 整数的范围 |
|---|---|---|---|
| int8 | 有 | 1字节 | -128 ~ 127 |
| int16 | 有 | 2字节 | -pow(2, 15) ~ pow(2, 15) - 1 |
| int32 | 有 | 4字节 | -pow(2, 31) ~ pow(2, 31) - 1 |
| int64 | 有 | 8字节 | -pow(2, 63) ~ pow(2, 63) - 1 |
无符号整型
| 类型 | 有无符号 | 占用存储空间 | 整数范围 |
|---|---|---|---|
| uint8 | 无 | 1字节 | 0 ~ 255 |
| uint16 | 无 | 2字节 | 0 ~ pow(2, 16) - 1 |
| uint32 | 无 | 4字节 | 0 ~ pow(2, 32) - 1 |
| uint64 | 无 | 8字节 | 0 ~ pow(2, 64) - 1 |
其他整型
| 类型 | 有无符号 | 占用存储空间 | 整数的范围 | 备注 |
|---|---|---|---|---|
| int | 有 | 32/64位系统占用4/8 bytes | -pow(2, 31) ~ pow(2, 31) - 1 / -pow(2, 63) ~ pow(2, 63) - 1 | 整型默认是int型 |
| uint | 无 | 32/64位系统占用4/8 bytes | 0 ~ pow(2, 32) - 1 / 0 ~ pow(2, 64) - 1 | |
| rune | 有 | 与int32一样 | -pow(2, 31) ~ pow(2, 31) - 1 | 等价于int32,表示一个Unicode码 |
| byte | 无 | 与uint8等价 | 0 ~ 255 | 当要存储字符时,选用byte |
浮点类型:
- 浮点数都是有符号位的,浮点数 = 符号位(浮点数都有符号位) + 指数位 + 尾数位。
- 浮点数会造成数据的精度损失,尽可能地选用float64类型。
- 浮点数的字段长度和范围是固定的,不受操作系统OS的影响。
| 类型 | 占用存储空间 | 浮点数的范围 |
|---|---|---|
| 单精度float32 | 4 bytes | float64位 比 float32位 精度更高 |
| 双精度float64 | 8 bytes | 浮点数默认是float64的 |
字符类型char:
golang中没有专门的字符类型,如果要存储单个字符(字母),则用字节byte来保存;且golang的字符串也是由单个的byte字节组成的。Go语言中的字符采用的是UTF-8编码(兼容ASCII码)。
# utf-8中,英文字符占1 byte,中文字符占用3 byte
var c3 int = '北'
fmt.Printf("c3 =%c, c3对应的码值:%d", c3, c3)Go语言中,字符本质上是一个整数,直接输出的是该字符对应的UTF-8编码的码值;故也可以用码值进行运算,因为均采用的是Unicode编码;
字符在计算机中的存储:字符 -> 对应的码值 -> 二进制 -> 存储;(读取的过程则是反过来执行的);通过字符编码表,可以查询字符与码值的对应关系。
字符串string类型:
一定长度的字符组成的字符序列,即由单个字节组成的。Golang语言的字符串的字节使用,utf-8编码标识的Unicode文本。
1)go语言中的字符串,一旦赋值,不能修改字符串中的内容,即不可变的;
2)字符串的表示:
- 双引号:会识别转义字符;
- 反引号:以字符串的原生形式输出,包括换行和特殊字符;
// 反引号:`***`
// 双引号:"***"3)字符串的拼接:用 + 或者 += 完成拼接;出现太多时,+号必须在上一行末尾;
布尔bool类型:
占用1 byte,且只能取true、false(不能用0代替false赋值)。适用于逻辑运算过程。
2.4 Go语言数据类型转换:
golang中不同类型的变量之间不能进行隐示类型转换,即只能进行显式类型转换。高、低精度之间的转换,也只能进行显式类型转换。为了防止数据溢出,因此在转换时,需要考虑范围。
2.4.1 基本数据类型间的相互转换
- 表达式T(v),将值v转换为T类型。转换时,注意范围,防止由于溢出造成数据丢失。
- 被转换的是变量存储的数据,变量本身的数据类型并没有变化。
2.4.2 基本数据类型 与 string类型的转换:
两种方式:
fmt.Sprintf()strconv.FormatInt()/strconv.FormatBool()/ strconv.FormatFloat()
package main
import "fmt"
func main() {
var (
num1 int = 90
num2 float64 = 23.33
b bool = true
m_char byte = 'a'
str string
)
fmt.Printf("num1 = %d num2 = %f b = %t m_char = %c\n", num1, num2, b, m_char)
// 方式一:使用fmt.Sprintf(),将基本数据类型转为字符串string类型
str = fmt.Sprintf("%d", num1)
fmt.Printf("str type %T str=%s\n", str, str)
str = fmt.Sprintf("%f", num2)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%t", b)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%c", m_char)
fmt.Printf("str type %T str=%q\n", str, str)
// 方式二:使用strconv包中的函数
str = strconv.FormatInt(int64(num1), 10) // 返回num1的10进制字符串
fmt.Printf("str type %T str=%q\n", str, str)
// ‘f’表示生成的字符串中小数的表示格式***.***;5表示小数点后保留5位小数;64表示num2是float64类型
str = strconv.FormatFloat(num2, 'f', 5, 64)
fmt.Printf("str type %T str=%q\n", str, str)
str = strconv.FormatBool(b)
fmt.Printf("str type %T str=%q\n", str, str)
// 整型int转字符型string
var num3 int = 3
str = strconv.Itoa(num3)
fmt.Printf("str type %T str=%q\n", str, str)
}2.4.3 字符串 转换成 基本数据类型:
strconv.ParseInt()/strconv.ParseBool()/ strconv.ParseFloat(),返回的是int64/float64。
package main
import "fmt"
import "strconv"
func main() {
var (
num1 string = "90"
num1_ int64
num2 string = "23.33"
num2_ float64
b string = "true"
b_ bool
)
b_, _ = strconv.ParseBool(b)
fmt.Printf("b_ type %T, b_=%t\n", b_, b_)
// 10表示转成10进制,64表示转成int64
num1_, _ = strconv.ParseInt(num1, 10, 64)
fmt.Printf("num1_ type %T, num1_=%d\n", num1_, num1_)
// 64表示转成float64
num2_, _ = strconv.ParseFloat(num2, 64)
fmt.Printf("num2_ type %T, num2_=%f\n", num2_, num2_)
}注:要确保string能够转换成有效的数据类型,否则会直接转换成默认值(int/float->0;bool->false)。
2.5 一维、二维数组:
2.5.1 一维数组:
1)数组可以用来存放多个同一类型的数据;
2)Go中,数组也是一种数据类型,且是值类型;
3)数据定义和内存分配:数组名、数组的第一个元素的地址,都等于数组的首地址;
package main
import "fmt"
import "strconv"
func main() {
var nums [6]float64 // 数组中元素是float64类型,故每个元素占8bytes
nums[0] = 12.0
nums[1] = 11.0
nums[2] = 13.0
fmt.Printf("%p %p %p\n", &nums, &nums[0], &nums[1])
// 分析数组在内存中的空间分配情况:可以通过数组的首地址访问到所有变量
total_nums_sum := 0.0
for i := 0; i < len(nums); i++ {
fmt.Printf("%v -> %f\t", &nums[i], nums[i])
total_nums_sum += nums[i]
}
fmt.Printf("\n")
avg_nums_sum_str := fmt.Sprintf("%.2f", total_nums_sum / float64(len(nums)))
avg_nums_sum, _ := strconv.ParseFloat(avg_nums_sum_str, 64) // 64表示转成float64
fmt.Printf("total_nums_sum=%f\n avg_nums_sum_str=%q -> avg_nums_sum=%f", total_nums_sum, avg_nums_sum_str, avg_nums_sum)
}4)数组的四种初始化方式;
var numsArr1 [3]int = [3]int{1, 2, 3}
var numsArr2 = [3]int{1, 2, 3}
var numsArr3 = [...]int{1, 2, 3}
var numsArr4 = [3]string{1:"jary", 0:"tom", 2:"mark"}
// var numsArr4 = [3]int{1:2,0:1,2:3}
5)数组的两种遍历方式:①下标;②for - range;
package main
import "fmt"
// 数组的两种遍历方式:1)下标;2)for - range;
func printIntArr(arr *[3]int, size int) {
for i := 0; i < size; i++ {
fmt.Printf("%v ", arr[i])
}
fmt.Printf("\n")
}
func printStrArr(arr *[3]string, size int) {
for index, val := range arr {
fmt.Printf("arr[%d]=%v ", index, val)
}
fmt.Printf("\n")
}
func main() {
// 四种初始化数组的方式
var arr1 [3]int = [3]int{1, 2, 3}
var arr4 = [3]string{1:"Tom", 0:"Steven", 2:"Jarry"}
printIntArr(&arr1, 3)
printStrArr(&arr4, 3)
}数组的使用注意事项:
1)数组是多个相同类型数据的组合,一旦声明/定义,其长度是固定的,不能动态变化;
2)var arr []int,这时arr就是一个slice切片;
3)数组中的元素可以是任何数据类型,包括 值类型 和 引用类型,但不能混用;
4)数组创建后,如果没有赋值,会有默认值(零值);
5)使用步骤:①声明数组并开辟空间;②给数组各个元素赋值(默认零值);③使用数组;
6)数组属于值类型,默认情况下是值传递,因此会进行值拷贝,数组间不会相互影响;如果想用其他函数修改原数组,可以使用引用传递(指针方式);
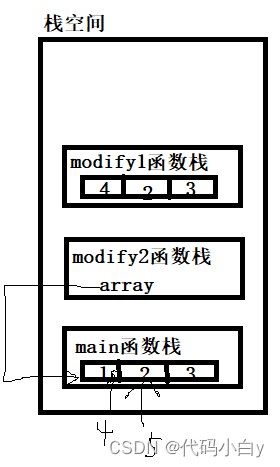
package main
import "fmt"
func PrintArr(arr *[3]int, size int) {
for i := 0; i < size; i++ {
fmt.Printf("%d ", arr[i])
}
fmt.Printf("\n")
}
// 使用值传递
func modify1(arr [3]int) {
arr[0] = 4
}
// 使用引用传递
func modify2(array *[3]int) {
(*array)[0] = 4
(*array)[1] = 5
}
func main() {
var arr [3]int = [3]int{1, 2, 3}
PrintArr(&arr, 3)
modify1(arr)
PrintArr(&arr, 3)
modify2(&arr)
PrintArr(&arr, 3)
}7)长度是数组类型的一部分,在传递函数参数时,需要考虑数组的长度;
举例:将'A' - 'Z'存放在数组中,并打印输出
package main
import "fmt"
import "strconv"
func arrMax(arr *[26]byte, size int) (int, byte){
max_val := (*arr)[0]
max_index := 0
for i := 1; i < size; i++ {
if max_val < (*arr)[i] {
max_val = (*arr)[i]
max_index = i
}
}
return max_index, max_val
}
func test() {
var arr [26]byte
for i := 0; i < len(arr); i++ {
arr[i] = 'A' + byte(i)
}
for i := 0; i < len(arr); i++ {
fmt.Printf("%c ", arr[i])
}
fmt.Printf("\n")
max_index, max_val := arrMax(&arr, 26)
fmt.Printf("arrMax: arr[%d]=%c\n", max_index, max_val)
}
func main() {
test()
var i float64 = 10
var res_str string = fmt.Sprintf("%.2f", i / 3)
res_float64, _ := strconv.ParseFloat(res_str, 64)
fmt.Printf("%q %f", res_str, res_float64)
}2.5.2 二维数组
基本语法:var arr_2D [行][列]int
package main
import "fmt"
func main() {
// 方式一:先定义/声明,再赋值
var arr_2D [3][3]int
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
arr_2D[i][j] = i * j
}
}
fmt.Println(arr_2D)
// 方式二:直接初始化
var arr_2D2 [3][3]int = [3][3]int{{1, 2, 3}, {1, 2, 3}, {1, 2, 3}}
fmt.Println(arr_2D2)
}二维数组在内存中的布局:

// 内存布局的分析
var arr_2D2 [2][3]int
fmt.Printf("%p %p\n", &arr_2D2[0], &arr_2D2[0][0])
fmt.Printf("%p %p\n", &arr_2D2[1], &arr_2D2[1][0])
// 其中&arr_2D2[0] 和 &arr_2D2[1],恰好相差3个整型,即24bytes二维数组的遍历:
for i := 0; i < len(arr_2D2); i++ {
for j := 0; j < len(arr_2D2[i]); j++ {
fmt.Printf("%d ", arr_2D2[i][j])
}
fmt.Printf("\n")
}
fmt.Printf("\n")
for _, address_1D := range arr_2D2 { // address_1D是二维数组中保存的每一行的地址
for _, val := range address_1D {
fmt.Printf("%d ", val)
}
fmt.Printf("\n")
}2.6 切片slice
1)切片的基本定义:var 变量名 []类型;
2)切片的使用和数组类似,遍历切片(for - len 或者 for index, val : range slice)、访问、求切片的长度len(slice),均与数组相同;
3)切片的内存分布:内存空间中,保存了:首地址、长度、容量;

 4)切片slice的三种使用方式:
4)切片slice的三种使用方式:
- 定义一个切片并让切片取引用一个已经创建好的数组,如slice := arr[start:len(arr)];
- 用make来创建切片,可指定大小和容量,且默认是零值;
- 定义一个切片,直接就指定具体数组,使用原理类似make的方式;
方式一、方式二的区别:方式一中数组是程序员可见的,既可以通过切片访问又可以通过数组访问;方式二中的数组是程序员不可见的,只能通过切片访问;
package main
import "fmt"
// 切片(可以理解为动态数组)的基本使用
// 内存中的布局:类似于结构体,有首地址、长度、容量
// 切片定义后,本身是空的;需要让其引用到一个数组 或者 make一个空间供切片使用
func main() {
// 切片的使用:方式一:定义一个切片并让切片取引用一个已经创建好的数组
var arr [6]int = [6]int{0, 1, 2, 3, 4, 5}
slice1 := arr[1:4] // slice[start:end] --> [start, end)
// slice1 := arr[:] // 表示切片包含了说组arr中的所有元素
fmt.Println("arr=", arr)
fmt.Println("slice=", slice1)
fmt.Println("len(slice)=", len(slice1))
fmt.Println("capability of slice is ", cap(slice1))
fmt.Printf("\n")
// 方式二:用make来创建切片
// 基本语法:make(type, len, [cap]) // cap是可选的,cap >= len
var slice2 []float64 = make([]float64, 4, 10)
fmt.Println("slice2=", slice2)
fmt.Println("len(slice2)=", len(slice2), "capability of slice2 is ", cap(slice2))
fmt.Printf("\n")
// 方式三:定义一个切片,直接就指定具体数组,使用原理类似make的方式
var slice3 []int = []int{1, 2, 3}
fmt.Println("slice3=", slice3)
fmt.Println("len(slice3)=", len(slice3), "capability of slice3 is ", cap(slice3))
}5)切片是一个数组的引用,因为切片是引用类型,故在传递数组时,需要遵守引用传递的机制;
package main
import "fmt"
func test1() {
var arr [3]int = [3]int{1, 1, 3}
slice1 := arr[:]
var slice2 []int = slice1
slice2[1] = 2 // 此时,slice1、slice2均指向数组arr所在的内存空间
fmt.Println(arr, "\t", slice1, "\t", slice2)
// 结果是arr、slice1、slice2: [1, 2, 3]
}
// 该处调用函数时,切片形参只是拷贝了切片实参的{指向的数组的首地址, len, cap},
//故本质上只是形参和实参变量本身的地址不同,其指向的数组内存空间相同
func test_slice(slice []int) {
slice[1] = 2 // 这里修改slice指向的内存空间的数据,会改变调用该函数的切片实参
// 切片作为形参时,切片只能在函数内部修改值,不能直接添加值
slice = append(slice, 29) // 无效
fmt.Printf("%p\n", &slice)
// 表明:slice和外部调用该函数的切片实参,指向的是同一块数组内存空间
}
// 切片指针作为形参时,切片即能在函数内部修改值,又能直接添加值
func test_slice_ptr(slice *[]int){
(*slice)[1] = 1
(*slice) = append((*slice), 4)
}
func test2() {
var arr [3]int = [3]int{1, 1, 3}
slice := arr[:]
fmt.Printf("%p\n", slice)
test_slice(slice)
fmt.Println(arr, "\t", slice)
test_slice_ptr(&slice)
fmt.Println(arr, "\t", slice)
// 结果是arr、slice: [1, 2, 3]
}
func main() {
test1()
test2()
}6)切片的长度是变化的,故可以认为切片时一个动态数组,即切片可以动态增长;
7)切片的切片:slice2 = slice1[start:end],此时slice1和slice2指向的是同一个数组空间;
8)用append内置函数,可以使切片进行动态增加;
slice3 = append(slice3, 元素1, 元素2);slice3 = append(slice3, slice2...);(...是对slice2进行解构为一个个元素)
append操作的底层原理分析:
- 本质就是对数组扩容;
- go底层会创建一个新的容量更大的数组;
- 将原slice中包含的元素拷贝到新的数组中,并把新添加的元素也放入新数组;
- slice重新引用到新数组(该新数组,是底层来维护的,程序员不可见,只能通过切片访问);
- 用copy内置函数,完成切片的拷贝操作:
copy(para1, para2),para1、para2都是切片类型;如果cap(para1)
var arr []int = []int{1, 2, 3}
slice1 := arr[:]
slice2 := make([]int, 10) // 默认值全是0
// slice1、slice2的数据空间是独立的,不会相互影响
copy(slice2, slice1) // slice2:[1,2,3,0,0,0,0,0,0,0]
// copy(para1, para2)中,para1、para2必须都是切片类型2.7 string字符串
1)string底层是一个byte数组,因此string也可以进行切片处理;
2)string是不可变的,不能通过str[0]='l'来修改;但可以通过[]byte 或者 []rune来修改,即如果要修改字符串,只能先将str -> []byte 或者 []rune -> 修改 -> 再转换回string。
package main
import "fmt"
func main() {
// string底层也是一个byte数组,因此string也可以进行切片处理
var str string = "129.jpg"
fmt.Println("str =", str)
// 使用切片获取后三位
var str_ string = str[4:7]
fmt.Println("str_ =", str_)
// string是不可变的,不能通过str[0]='l'来修改
// 如果要修改字符串,只能先将str -> []byte 或者 []rune -> 修改 -> 再转换回string
var byte_arr []byte = []byte(str)
byte_arr[0] = '2'
str = string(byte_arr)
fmt.Println("str =", str)
// byte数组每个元素,只能占一个字节,但一个汉字有三个字节
// 故在字符串中,添加汉字,则需要将用[]rune代替[]byte,因为[]rune是按字符处理的故兼容汉字
var rune_arr []rune = []rune(str)
rune_arr[0] = '汉'
str = string(rune_arr)
fmt.Println("str =", str)
}2.8 map
2.8.1 map关系数组
map是key-value的数据结构,又称字段或者关联数组。
1)基本语法:map[keytype]valuetype
- keytype只能是int、string、数字、bool、指针、channel、接口、结构体、数组等
(因为slice、map、function无法用==判断,故keytype不能是slice、map、function),但通常用int、string;
- valuetype通常是数字(整型、浮点型)、string、map、struct等;
2)map声明举例:
var a map[string]stringvar a map[string]intvar a map[int]stringvar a map[string]map[string]string等;
3)map在声明时并不会分配内存,用make初始化后,才会分配内存,然后才能进行赋值和使用;
4)golang中的map,默认是无序的状态,且没有专门的针对排序的方法;key不能重复,但value可以重复;
5)map的三种使用方式:
- 先声明,再make分配内存空间,再使用;
- 声明后直接make分配内存空间,再使用;
- 声明后直接赋值;
package main
import "fmt"
// map在声明时并不会分配内存,用make初始化后,才会分配内存,然后才能进行赋值和使用;
func main() {
// map的三种使用方式:
// 方式一:先声明,再make分配内存空间,再使用
var map1 map[int]string
map1 = make(map[int]string, 5)
// 方式二:声明后直接make分配内存空间,再使用
map2 := make(map[int]string)
for i := 1; i <= 5; i++ {
map2[i] = string('A' + byte(i))
}
// 方式三:声明后直接赋值
map3 := map[int]string{"1":"A", "2":"B", "3":"C", "4":"D", "5":"E"}
// map的遍历:
for key, value := range map3 {
fmt.Printf("map3[%d]=%q\n", key, value)
}
fmt.Println(map3)
}map[string]map[string]string的使用:
package main
import "fmt"
func main() {
studentMap := make(map[string]map[string]string)
studentMap["01"] = make(map[string]string, 3)
studentMap["01"]["name"] = "tom"
studentMap["01"]["sex"] = "male"
studentMap["01"]["address"] = "shanxi"
studentMap["02"] = make(map[string]string, 3)
studentMap["02"]["name"] = "jary"
studentMap["02"]["sex"] = "female"
studentMap["02"]["address"] = "shanghai"
fmt.Println(studentMap)
// map[string]map[string]string的遍历:
for _, address := range studentMap {
for key, value := range address {
fmt.Printf("[%q]=%q ", key, value)
}
fmt.Printf("\n")
}
}6)map的增删改查操作:
- map的增加和更新:map[key]=value;如果key不存在则是增加,否则则是更新。
- map的删除:使用内置函数delete(map,key);如果可以存在则删除,否则不操作也不报错。
补充说明:如果要删除map中所有的key,1)可以通过遍历逐个删除;2)make一个新的map并直接赋值给map(map=make(...)),即这会原来的map成为垃圾被GC回收。
- map的查找:1)val,ok=map[key]; 2)通过for-range遍历不同的key来实现查找的目的。
package main
import "fmt"
import "unsafe"
func SearchMap(map_ map[string]string, key_search string) {
fmt.Printf("%p\n", &map_)
for key, value := range map_ {
if key == key_search {
fmt.Printf("[%q]=%q\n", key, value)
}
}
}
// map的增、删、改、查
func main() {
map_ := make(map[string]string, 5)
map_["name"] = "SGY" // 增
map_["sex"] = "male"
map_["address"] = "shanxi"
map_["phone"] = "8888"
fmt.Println(map_)
fmt.Printf("%d\n", unsafe.Sizeof(map_))
fmt.Printf("%d\n", unsafe.Sizeof(map_["sex"]))
map_["name"] = "Guangyuan" // 改
fmt.Println(map_)
fmt.Printf("%p\n", &map_)
SearchMap(map_, "address") // 查
value, ok := map_["address"]
if ok {
fmt.Printf("[%q]=%q\n", "address", value)
} else {
fmt.Printf("[%q]不存在", "address")
}
// delete(map, key)如果key存在,则删除key-value;不存在,则不操作,也不会报错;
delete(map_, "phone") // 删
fmt.Println(map_)
fmt.Printf("map_的key-value的对数,%d\n", len(map_))
// 没有专门的方法能直接删除map中的所有的key,有两种解决方法:
// 1)只能通过遍历逐个删除;
for key, _ := range map_ {
delete(map_, key)
}
fmt.Println(map_)
// 2)重新给map分配空间,使原来的内存空间的引用变成零,即会被GC当作垃圾回收;
map_ = make(map[string]string)
fmt.Println(map_)
}2.8.2 map切片:
切片的数据类型如果是map,则称为slice of map(map切片),这样使用map的个数就可以动态变化了。
package main
import "fmt"
import "strconv"
// 切片的数据类型如果是map,则称为slice of map(map切片),这样使用map的个数就可以动态变化了
func main() {
var map_slice []map[string]string;
map_slice = make([]map[string]string, 5)
//map_ := make(map[string]string, 10)
var map_ map[string]string
for i := 0; i < len(map_slice); i++ {
map_ = make(map[string]string, 10)
if map_slice[i] == nil {
for j := 0; j < 10; j++ {
map_[strconv.Itoa(j)] = strconv.Itoa(j * 10)
}
map_slice[i] = map_
fmt.Println(map_)
}
}
fmt.Println(map_slice)
// 用append给map切片添加元素,来动态的增加map切片的长度
map_ = map[string]string{
"...":"...///",
"..":"..///",
".":".///",
}
map_slice = append(map_slice, map_)
fmt.Println(map_slice)
fmt.Println("map_slice的切片长度:", len(map_slice))
}2.8.3 map排序:
golang中map默认是无序的,且每次遍历的输出顺序都不同;map的排序,只能先将key进行排序,再根据key值遍历输出。
package main
import (
"fmt"
"strconv"
"sort"
)
// 当切片作为形参时,切片只能在函数内部修改值,不能直接添加值
func Insert_Sort(map_ map[int]string) []int {
var key_ []int
for key, _ := range map_ {
key_ = append(key_, key)
sort_len := len(key_)
if sort_len == 1 {
continue
} else {
left := 0
right := sort_len - 2
for {
if (right - left) > 1 {
middle := (left + right) / 2
if key < key_[middle] {
right = middle
continue
} else if key > key_[middle] {
left = middle
continue
} else {
for i := sort_len - 2; i >= middle; i-- {
key_[i + 1] = key_[i]
}
key_[middle] = key
break
}
} else {
if key >= key_[left] && key <= key_[right] {
for i := sort_len - 2; i >= right; i-- {
key_[i + 1] = key_[i]
}
key_[right] = key
} else if key > key_[right]{
for i := sort_len - 2; i >= right + 1; i-- {
key_[i + 1] = key_[i]
}
key_[right + 1] = key
} else {
for i := sort_len - 2; i >= left; i-- {
key_[i + 1] = key_[i]
}
key_[left] = key
}
break
}
}
}
}
return key_
}
func GetSortedValue(value *[]string, map_ map[int]string, key_ []int) {
for _, key := range key_ {
*value = append((*value), map_[key])
}
}
// golang中map默认是无序的,且每次遍历的输出顺序都不同;
//map的排序,只能先将key进行排序,再根据key值遍历输出;
func main() {
map_ := make(map[int]string, 20)
for i := 0; i < 20; i++ {
map_[i] = strconv.Itoa(i * 10)
}
fmt.Println(map_)
// 方式一:先将key放入切片中, 并对切片进行排序;最后按照切片中的key查找相应的value
var key_1 []int
for key, _ := range map_ {
key_1 = append(key_1, key)
}
sort.Ints(key_1)
fmt.Println(key_1)
var value_1 []string
GetSortedValue(&value_1, map_, key_1)
fmt.Println(value_1)
// 方式二:将key逐个放入key_中,并利用插排,完成排序;最后按照切片中的key查找相应的value
var key_2 []int = Insert_Sort(map_)
fmt.Println(key_2)
var value_2 []string
GetSortedValue(&value_2, map_, key_2)
fmt.Println(value_2)
}2.8.4 map的使用细节:
- map是引用类型,遵守引用类型传输的机制,即直接将map作为形参传入函数时,函数内部对map的修改会影响外部map。
- map的key-value个数达到容量后,会自动扩容,并不会发生panic,即map能动态增长键值对key-value。
- map的value也经常是struct类型,更适合管理更复杂的数据。
package main
import (
"fmt"
"strconv"
)
type Student struct {
Name string
Age int
Address string
}
// map也是引用类型,遵守引用类型传输的机制,
//即直接将map作为形参传入函数时,函数内部对map的修改会影响外部map
func Map_Modify(map_ map[string]string, key string, value string) {
map_[key] = value
}
func main() {
map_ := make(map[string]string, 10)
for i := 0; i < 10; i++ {
map_[strconv.Itoa(i)] = strconv.Itoa(i * 10)
}
fmt.Println(map_)
// 直接将map作为形参传入函数时,函数内部对map的修改会影响外部map
Map_Modify(map_, "9", "99")
fmt.Println(map_)
// map的key-value个数达到容量后,会自动扩容,并不会发生panic,
//即map能动态增长键值对key-value
map_[strconv.Itoa(10)] = strconv.Itoa(100)
fmt.Println(map_)
// map的value也经常是struct类型,更适合管理更复杂的数据
students := make(map[string]Student, 10)
student1 := Student{"tom", 18, "北京"}
students["1"] = student1
student2 := Student{"jary", 20, "西安"}
students["2"] = student2
fmt.Println(students)
for num, student := range students { // 遍历map[string]Student,即value时struct结构体的map
fmt.Printf("%q -> %q,%d,%q\n", num, student.Name, student.Age, student.Address)
}
}2.9 指针
- 基本数据类型(int系列、float系列、bool、string、数组和结构体struct)中,变量存的是值,也叫值类型。值类型都有对应的指针类型,形式为*数据类型。
- 获取变量的地址用&;
- 指针变量ptr存的是一个地址,且该地址指向的空间存的是值,比如
var ptr *int = &num; - 获取指针的值,使用*,比如
*ptr;

package main
import "fmt"
func main() {
var i int = 10
fmt.Println("i=", i, " 地址是", &i)
var ptr *int = &i
*ptr = 20
fmt.Println("ptr的地址是", &ptr, "*ptr=", *ptr, "指向的内存地址是", ptr)
}2.10 值类型和引用类型
- 值类型:基本数据类型int/float系列、bool、string、数组和结构体struct;
值类型默认是值传递,变量直接存储值,内存通常在栈中分配;

- 引用类型:指针、slice切片、map、管道channel、接口interface
引用类型默认是引用传递,变量存储的是一个地址,该地址对应的堆区的内存空间才真正存储的是数据,且内存通常在堆上分配,当没有变量引用这个地址时,该地址对应的数据空间会被当成垃圾并由GC来回收。

总结:
1、函数参数的传递方式:值传递 和 引用传递;
- 相同点:都传递的是变量的副本;
- 不同点:值传递,传递的是值拷贝的副本;引用传递,传递的是地址拷贝的副本;
- 相比之下,地址拷贝的效率更高;
2、如果希望在函数中修改传入函数的参数,则可以传入该变量的地址,而函数内则以指针的方式操作变量。从效果上看类似于引用。
2.11 标识符:
2.11.1 标识符的概念:
- Golang中对各种变量、方法、函数等命名时,使用的字符序列;
- 凡是可以自己起名的地方都叫标识符;
- 标识符的命名规则:不能使用空格、严格区分大小写、不能使用系统保留关键字作为标识符;_被称为占位符,不能直接作为标识符(能与字符结合使用,构成标识符);
2.11.2 标识符命名的规范:
1、包名:让package的名字和目录保持一致,尽量采用有意义的包,不能和标准库冲突;
2、变量名、常量名、函数名:采用驼峰法;
3、首字母大写为public权限(即可以跨包使用该变量、函数、常量)、首字母小写为private:如果变量名、函数名、常量名首字母大写,则可以被其他包访问到;如果首字母小写,则只能在本包中使用;
package main
import fmt
import "Go_Code/DataType/..."
// 要想在该函数中调用...包中的变量、函数、常量,则需要将...该包中的相应的变量、函数、常量的首字母大写2.11.3 系统保留关键字
break |
continue |
select |
interface |
default |
|---|---|---|---|---|
case |
defer |
go |
map |
struct |
chan |
goto |
import |
package |
switch |
const |
if |
else |
type |
fallthrough |
return |
for |
range |
func |
var |
2.11.4 预定义标识符:
包含内建的常量、类型和函数:
int16 |
int32 |
int64 |
float32 |
float64 |
complex |
|---|---|---|---|---|---|
complex64 |
complex128 |
bool |
real |
new |
make |
string |
panic |
uint64 |
uint16 |
uint8 |
uint |
recover |
true |
false |
close |
int |
int8 |
append |
bool |
type |
cap |
nil |
uintprt |
len |
iota |
imag |
copy |
print |
println |
分类:

make、new内建函数的区别:

2.12 运算符:
算数运算符、赋值运算符、比较/关系运算符、逻辑运算符、位运算符、其他运算符。
2.12.1 算数运算符:
+(加法 或者 字符串拼接)、-、*、/(整数相除只能保留整数)、%(按照公式 a-(a/b)*b运算)、i++、i--(golang中,自增和自减 只能单独使用,且不存在++i、--i)
2.12.2 关系运算符:
结果都是布尔类型,即true / false;经常用在比较表达式 / 循环结构的条件中;常用的关系运算符: == 、!= 、>、<、>=、<=;关系运算符组成的表达式,称为关系表达式;
2.12.3 逻辑运算符:
用于连接多个条件的判断(一般是多个关系表达式);常用的逻辑运算符:&&与、||或、!非;
- 短路与(&&中第一个条件为false,则不会判断第二个条件);
- 短路或(||中第一个条件为true,则不会判断第二个条件);
2.12.4 赋值运算符:
=、+=、-=、*=、/=、%=;<<=、>>=、&=(按位与后赋值)、^=(按位异或后赋值)、|=(按位或后赋值)
如何在不用中间变量的情况下,完成两个变量值的交换:a = a + b; b = a - b; a = a - b;
2.12.5 位运算符:
&(按位与)、^(按位异或)、|(按位或)、<<、>>
左移<<、右移>>运算符的规则:
- 右移运算符:低位溢出,符号位不变,并用符号位填补溢出的高位;
- 左移运算符:高位溢出,符号位不变,低位溢出用0填补;
原码、反码、补码:
- 二进制的最高位是符号位:0表示正数、1表示负数;
- 正数的原码、反码、补码,都相同;
- 0的反码/补码还是0;
- 负数的反码是原码中,符号位不变、其余位取反;负数的补码=反码+1;
- 计算机在运行时,都是以补码的方式进行运算的;
package main
import "fmt"
func main() {
var i int = -2
var j int = 3
fmt.Printf("i's binary code is %b\n", i)
fmt.Printf("j's binary code is %b\n", j)
fmt.Println("i<<2 =", i<<2)
fmt.Println("i^j =", i^j)
fmt.Println("i|j =", i|j)
fmt.Println("i&j =", i&j)
}2.12.6 取址符:
& 指针变量:* (*a是一个指针变量,能够取出该指针指向的内容)
在终端可以使用,fmt.Scanln(&变量名) 或者 fmt.Scanf("%t %d %s % f", &bool_var, &int_var, &str_var, &float_var) 来获取终端的输入。
2.12.7 运算符的优先级:
只有单目运算符 和 赋值运算符,是从右向左运算的。
优先级的一览表,如下图:

2.13 流程控制
2.13.1 顺序控制
程序自上而下执行,没有任何跳转和判断。
2.13.2 分支控制
单/双分支:
// 单分支
if 条件 {
代码
}
// 双分支
if 条件 {
代码一
} else {
代码二
}多分支:

switch分支结构的使用:

switch 表达式 {
case 表达式1, 表达式2, ...:
语句块1
case 表达式3, 表达式4, ...:
语句块2
...
default:
语句块
}switch分支结构中的注意事项:
- case后的表达式,可以有点多个,可以是变量、常量(是常量则case后的表达式中常量不能重复)、有返回值的函数;
- switch的数据类型,必须和case后的表达式数据类型相同,否则会报错;
- default语句,并不是必须的;
- switch后不带条件,相当于if ... else ...;
- golang语句中,case执行完后不需要break,则会直接退出该switch控制;
- switch穿透 - fallthrough(默认只能穿透一层):如果在case语句块后,增加fallthrough,则会继续执行下一个case包,故称为switch穿透;
- Type Switch: switch语句还可以被用于type-switch判断某个interface变量中实际指向的变量类型。
package main
import "fmt"
func main()
{
var x interface{}
var y float64 = 10.0
x = y
switch i := x.(type) {
case nil:
fmt.Printf("x的类型是 %T", i)
case int:
fmt.Println("x 是 int型")
case float64:
fmt.Println("x 是 float64型")
case bool, string:
fmt.Println("x 是 bool型 或者 string型")
case func(int) float64:
fmt.Println("x 是 func(int)型")
default:
fmt.Println("x 是 未知型")
}
}2.13.3 循环控制
for循环:
// 基本语法:
for 循环变量的初始化;循环条件;循环变量的迭代 {
循环操作
}
// 执行顺序:执行循环变量初始化 -> 执行循环条件的判断,为真则执行循环操作 -> 执行循环迭代 -> 反复执行循环条件判断 和 执行循环迭代
// 注意事项:
// 1)循环条件是返回一个布尔值的表达式
// 2)for循环语句,第二种写法:
循环变量的初始化
for 循环条件 {
循环操作
循环变量的迭代
}
// 3)for死循环的写法:常常与break配合使用
for ;; { // 或者 for {
循环操作
}
字符串的遍历:当字符串中含有中文时,那么通过下标访问字符串,就会出现乱码。原因:按照下标访问,每次访问的是一个字节,而一个汉字的UTF-8编码占了3字节。将string转换成[]rune切片,即可通过下标访问汉字,且不会乱码。
package main
import "fmt"
func main() {
var str string = "hello world!"
// 方式一:通过下标访问
for i := 0; i < len(str); i++ {
fmt.Printf("%c", str[i])
}
fmt.Println("\n")
// 方式二:通过for - range访问
for index, val := range str {
fmt.Printf("str[%d]=%c\n", index, val)
}
// 当字符串中含有中文时的遍历,每个汉字占用3bytes
var str2 string = "hello world!广源孙"
for index, val := range str2 {
fmt.Printf("str2[%d]=%c\n", index, val)
}
// 但按照下标访问,每次只能访问1bytes,故需要通过切片解决
str3 := []rune(str2)
for i := 0; i < len(str3); i++ {
fmt.Printf("%c", str3[i])
}
fmt.Println("\n")
}while与do ... while的实现:
go语言中,不存在while和do...while的语法,可以通过for来替代。
// 通过for语句实现while循环
for {
if 循环结束的条件 {
break
}
循环操作
循环变量的迭代
}
// 通过for语句实现do...while循环
for {
循环操作
循环变量的迭代
if 循环结束的条件 {
break
}
}package main
import "fmt"
func main() {
// 通过for实现while循环
var i int = 1
for {
if i > 10 {
break
}
fmt.Println("hello world - ", i)
i++
}
// 通过for实现do...while循环
i = 1
for {
fmt.Println("hello world - ", i)
i++
if i > 10 {
break
}
}
}多重循环控制:
嵌套循环(将内层循环当作外层循环的循环体),外层循环、内层循环
举例:
1、打印金字塔

package main
import "fmt"
func main() {
var pyramid_level int = 5
for i := 1; i <= pyramid_level; i++ {
for j := 1; j <= i; j++ {
fmt.Printf("*")
}
fmt.Printf("\n")
}
fmt.Printf("\n")
pyramid_level = 6
for i := 0; i < pyramid_level; i++ {
for j := 0; j < 2 * i + 1; j++ {
fmt.Printf("*")
}
fmt.Printf("\n")
}
fmt.Printf("\n")
pyramid_level = 6
for i := 0; i < pyramid_level; i++ {
for j := 0; j < pyramid_level - i - 1; j++ {
fmt.Printf(" ")
}
for j := 0; j < 2 * i + 1; j++ {
fmt.Printf("*")
}
for j := 0; j <= pyramid_level - i - 1; j++ {
fmt.Printf(" ")
}
fmt.Printf("\n")
}
}2、九九乘法表

package main
import "fmt"
func main() {
var num int = 9
for i := 0; i <= num; i++ {
for j := 0; j <= i; j++ {
fmt.Printf("%d*%d=%d\t", i, j, i*j)
}
fmt.Printf("\n")
}
}标签:
break:用于终止for循环;continue:用于结束本次for循环,并继续执行下一个for循环。
- break出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块;
- continue出现在多层嵌套的语句块中时,可以通过标签指明要跳过的是哪一层语句块;
package main
import "fmt"
func main() {
label1:
for i := 0; i < 4; i++ {
//label2:
for j:= 0; j < 4; j++ {
if j == 2 {
//break // 默认跳出最近的for循环,即等价于break label2
break label1
//break label2
}
fmt.Printf("%d\t", j)
}
fmt.Printf("\n")
}
fmt.Printf("\n")
label3:
for i := 0; i < 4; i++ {
for j:= 0; j < 4; j++ {
if j == 2 {
//continue
continue label3
}
fmt.Printf("i=%d, j=%d\n", i, j)
}
fmt.Printf("\n")
}
}跳转控制语句goto:
- goto语句可以无条件跳转到程序中指定的行;
- 一般与条件语句结合,实现条件转移,跳出循环体等功能;
- 尽量避免使用goto;
2.14 函数:
实现代码的模块化管理,以便后续代码的维护;减少代码的冗余;包中的函数名首字母必须大写,才能认为是可导出的;
2.14.1 写法
// 函数:实现某一功能的代码块
func 函数名(形参列表) (返回值列表) {
执行语句
return 返回值列表
}package main
import "fmt"
func ArithmeticOperate(num1 float64, num2 float64, operator byte) float64 {
var result float64
switch operator {
case '+':
result = num1 + num2
case '-':
result = num1 - num2
case '*':
result = num1 * num2
case '/':
result = num1 / num2
default:
fmt.Printf("Operator Error")
}
return result
}
func main() {
res := ArithmeticOperate(1, 3, '/')
fmt.Printf("%f", res)
}2.14.2 打包/引包的方法:
- 一般包名和.go文件名相同;且package ***打包操作,必须在.go文件的开头;
- 为了让包中的函数/变量/常量在其他包中,能够正常访问,需要在声明和定义时将函数/变量/常量的首字母大写;
- 同一个包下,不能有同名的函数/变量/常量,否则会报重复定义的错误;
utils.go
package Utils // package cal
import "fmt"
func ArithmeticOperate(num1 float64, num2 float64, operator byte) float64 {
var result float64
switch operator {
case '+':
result = num1 + num2
case '-':
result = num1 - num2
case '*':
result = num1 * num2
case '/':
result = num1 / num2
default:
fmt.Printf("Operator Error")
}
return result
}main.go
package main
import "fmt"
import "Go_Code/Function/ArithmeticOperate/utils"
// import包时,路径是从$GOPATH的src下开始的,不需要再带src,编译器会自动从src开始引入
func main() {
var num1 float64 = 4
var num2 float64 = 3
var operator byte = '/'
res := utils.ArithmeticOperate(num1, num2, operator)
// res := cal.ArithmeticOperate(num1, num2, operator)
fmt.Printf("%.4f", res)
}2.14.3 函数调用的底层机制:
在调用函数时,会将代码区的该函数实例化,并在栈区分配内存空间,且是独立存在的;完成调用后(执行完毕后),会销毁该函数在栈区的内存空间。
2.14.4 递归调用:
- 递归调用时,每调用一次函数本体,都会在栈区分配一块独立的内存空间(新函数栈);
- 函数的局部变量是独立的,不会相互影响;
- 递归执行的过程,必须是向退出递归的条件逼近;
- 当函数执行完毕后,或者遇到return后,就会返回,遵循谁调用,就将结果返回给谁;
2.14.5 函数的注意事项:
1)函数的形参列表、返回值列表,都可以是多个的;
2)形参列表 和 返回值列表的数据类型,可以是值类型 和 引用类型;
3)函数的首字母大写,认为是可以挎包使用的,即public;首字母小写,认为是private,只能在本包中使用;
4)基本数据类型 和 数组,默认都是 值传递 的,即进行值拷贝。如果想用引用传递,则必须传入变量的地址,并在函数内通过指针的方式操作变量,类似于引用;

package main
import "fmt"
func test03(n *int) {
*n = *n + 1
}
func main() {
var num int = 1;
test03(&num)
fmt.Printf("num = %d", num)
}5)Go语言不支持函数重载;
6)在Go中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量,通过该变量可以对函数进行调用;函数也可以作为形参;支持对函数返回值命名;
package main
import "fmt"
// 支持对函数返回值命名
func GetSum2(n1 int, n2 int) (n int) {
n = n1 + n2
return
}
func GetSum1(n1 int, n2 int) int {
n := n1 + n2
return n
}
// 函数也可以作为形参
func GetSum_(myAddfunc func(int, int) int, n1 int, n2 int) int {
return myAddfunc(n1, n2)
}
func main() {
// Go中,**函数也是一种数据类型**,可以赋值给一个变量,则该变量就是一个函数类型的变量
FuncTypeVar := GetSum2
fmt.Printf("FuncTypeVar type is %T\n", FuncTypeVar) // func(int, int) int
// 通过该变量可以对函数进行调用
result := FuncTypeVar(10, 11)
fmt.Printf("result = %d\n", result)
// 函数也可以作为形参
result2 := GetSum_(FuncTypeVar, 10, 11)
fmt.Printf("result2 = %d\n", result2)
}为了简化数据类型定义,Go支持自定义数据类型
- 基本语法:type 自定义数据类型 数据类型 // 相当于一个别名
- 举例:type mySum func(int, int) int
8)占位符_,可以在调用有多个返回值的函数时,忽略某个返回值;
9)Go支持可变参数:可变参数要放在,形参的最后。
其中,args是slice切片,可以通过下标args[index]访问到。
// 支持0 ~ 多个参数
func (args... int) int {
}
// 支持1 ~ 多个参数
func (n1 int, args... int) int {
}
package main
import "fmt"
func sum(n1 int, args... int) int {
sum := n1
for i := 0; i < len(args); i++ {
sum += args[i] // 表示依次取出args切片中的各个元素
}
return sum
}
func main() {
res := sum(1, 2, 3, 4)
fmt.Printf("result = %d\n", res)
}2.14.6 init函数的基本介绍:
每个.go文件,都可以包含一个init函数,该函数会在main函数执行之前,被Go运行框架调用,也就是说init会在main函数前被调用,通常用来完成初始化的工作。
如果一个函数中同时含有全局变量的定义、init()函数、main()函数,则执行的顺序是,全局变量的定义 -> init()函数 -> main()函数。
package main
import "fmt"
// init()函数,可以用来完成一些初始化的工作
var age = test()
func test() int {
fmt.Println("test()")
return 90
}
func init() {
fmt.Println("..... Init() .....")
}
func main() {
fmt.Println("..... main() .....", age)
}注:当存在多个被引用的包时,且中都含有init()函数时,执行顺序如下图。

2.14.7 匿名函数:
Go支持匿名函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用。
package main
import "fmt"
var (
// 定义全局匿名函数
m_global_func = func (n1 int, n2 int) int {
return n1 + n2
}
)
func main() {
// 在定义匿名函数时,就直接调用,这种方式匿名函数只能调用一次
result1 := func (n1 int, n2 int) int {
return n1 + n2
}(10 ,20)
fmt.Printf("result1 = %v\n", result1)
// 将匿名函数赋值给一个变量,则该变量的数据理性就是函数类型,故可以通过变量直接调用函数
m_func := func (n1 int, n2 int) int {
return n1 + n2
}
result2 := m_func(10, 20)
fmt.Printf("result2 = %v\n", result2)
// 使用全局匿名函数
result3 := m_global_func(10, 20)
fmt.Printf("result3 = %v\n", result3)
}2.14.8 闭包:
- 闭包就是一个函数和与其相关的引用环境组合的一个整体(实体);
- 可以将闭包理解为一个类:函数操作func (x int) (int, string)、n和str是字段,函数与用到的n共同构成了闭包;
- 闭包最大的优点在于,“类”的字段只需初始化一次,每次调用该闭包时都会保留了上次修改后的字段;
- 当我们反复调用函数m_func时,n、str只初始化一次,故每次调用是在原来的基础上累加。
package main
import "fmt"
// 累加器
func AddUpper() func (int) (int, string) {
// 该匿名函数和它引用到的函数外的变量n,形成了一个整体,共同构成了闭包
var n int = 10
var str string = "hello"
// 返回了一个匿名函数
return func (x int) (int, string) {
n = n + x
var str_ string = ""
for i := 0; i < x; i++ {
str_ = str_ + "$"
}
str += str_
return n, str
}
}
func main() {
m_func := AddUpper()
result1, str1 := m_func(1)
fmt.Printf("result1 = %v\t str1 = %s\n", result1, str1)
result2, str2 := m_func(2)
fmt.Printf("result2 = %v\t str2 = %s\n", result2, str2)
result3, str3 := m_func(3)
fmt.Printf("result2 = %v\t str2 = %s\n", result3, str3)
}package main
import "fmt"
import "strings"
// 使用传统函数
func makeSuffix1(suffix string, fileName string) string {
if !strings.HasSuffix(fileName, suffix) {
fileName = fileName + ".jpg"
}
return fileName
}
// 使用闭包:匿名函数 + 匿名函数外的变量引用
func makeSuffix2(suffix string) func (string) string {
return func (fileName string) string {
if !strings.HasSuffix(fileName, suffix) {
fileName = fileName + suffix
}
return fileName
}
}
func main() {
// 传统的函数
fmt.Printf("fileName = %s\n", makeSuffix1(".jpg", "1"))
fmt.Printf("fileName = %s\n", makeSuffix1(".jpg", "2.jpg"))
// 闭包
m_func := makeSuffix2(".jpg")
fmt.Printf("fileName = %s\n", m_func("1"))
fmt.Printf("fileName = %s\n", m_func("2.jpg"))
}2.14.9 defer的基本使用:
- 当执行到defer时,会将defer后的语句压入到独立的栈中(defer栈中);
- 当函数执行完毕后,再从defer栈中,按照“先入后出”的原则出栈,并执行;
- 在将defer语句放入到栈中时,也会将相关的值拷贝同时入栈;
package main
import "fmt"
func sum(n1 int, n2 int) int {
// 1)当执行到defer时,会将defer后的语句压入到独立的栈中(defer栈中)
// 2)当函数执行完毕后,再从defer栈中,按照“先入后出”的原则出栈,并执行
defer fmt.Println("ok1, n1=", n1)
defer fmt.Println("ok2, n2=", n2)
// 3)在将defer语句放入到栈中时,也会将相关的值拷贝同时入栈,因此此处改变n1、n2并不会影响最终打印的结果
n1++
n2++
res := n1 + n2
fmt.Println("ok3, res=", res)
return res
}
func main() {
result := sum(10, 20)
fmt.Println("result=", result)
}defer的最重要的价值是:当函数执行完毕后,可以及时的释放函数创建的资源。
- 创建了资源后(打开了文件、获取数据库的链接、或者是锁资源),可以直接在其后添加
defer file.close 或者 defer connect.Close(); - 会在该函数执行完成后,及时的调用defer栈,执行相应的代码并释放资源。
2.14.10 字符串常用的系统函数:
1)统计字符串的长度len()`:
获得字符串所占用的字节数;当字符串中含有中文时,一个中文字符占用3bytes;
2)字符串的遍历,同时处理有中文字符的问题:
由于一个中文字符占用3bytes,故在输出中文字符时,需要将字符串变成切片,才能正常输出;
package main
import "fmt"
func main() {
var str string = "hello 北京"
// 在输出中文字符时,需要将字符串变成切片,才能正常输出
str2 := []rune(str)
for i := 0; i < len(str2); i++ {
fmt.Printf("%c", str2[i])
}
fmt.Printf("\n")
// 或者采用for_range,来输出含有中文的字符串
for _, val := range str {
fmt.Printf("%c", val)
}
}3)字符串与整型互转:
- 字符串转整型:
n, err = strconv.Atoi("12"); - 整型转字符串:
n, err = strconv.Itoa(12); - 10进制 转 2、8、16进制:
str = strconv.FormatInt(123, 2);
package main
import "fmt"
import "strconv"
func str2Int(str string) int64 {
var n int64
var err error
n, err = strconv.ParseInt(str, 10, 64) // 10表示转成10进制,64表示转成int64
//var n int
//n, err = strconv.Atoi(str) // Atoi是ParseInt(str, 10, 0)的简写
if err != nil {
fmt.Println("转换错误", err)
return -1
} else {
return n
}
}
func int2Str(val int) (string, string, string){
// %b 表示为二进制
// %d 表示为十进制
// %o 表示为八进制
// %x 表示为十六进制,使用a-f
str1 := fmt.Sprintf("%d", val)
str2 := strconv.Itoa(val) // Itoa是FormatInt(val, 10) 的简写
str3 := strconv.FormatInt(int64(val), 10) // 返回val的2、8、10、16进制字符串
return str1, str2, str3
}
func main() {
// 字符串转整型
var str string = "12"
n := str2Int(str)
if n != -1 {
fmt.Printf("%T:%v -> %T:%v\n", str, str, n, n)
}
//n := str2Int("hello")
n = str2Int("h")
if n != -1 {
fmt.Printf("%T:%v -> %T:%v\n", str, str, n, n)
}
// 整型转字符串
var num int = 123
var str1, str2, str3 string
str1, str2, str3 = int2Str(num)
fmt.Printf("%T:%v -> %T:%q\n", num, num, str2, str2)
fmt.Printf("str1=%q str2=%q str3=%q\n", str1, str2, str3)
}字符串 与 其余基本数据类型(int、float、float64、bool)互转:
package main
import "fmt"
import "strconv"
import "reflect"
import "strings"
// go语言中,可以使用interface{}表示任何类型
func BDT2String(num interface{}) (str string) {
// 方式一:使用fmt.Sprintf(),将基本数据类型转为字符串string类型
// 方式二:使用strconv包中的函数
switch val := num.(type) {
case int:
str = fmt.Sprintf("%d", val)
str = strconv.Itoa(val) // Itoa是FormatInt(val, 10) 的简写
str = strconv.FormatInt(int64(val), 8) // 返回val的2、8、10、16进制字符串
case float64:
str = fmt.Sprintf("%f", val)
// ‘f’表示生成的字符串中小数的表示格式***.***;5表示小数点后保留5位小数;64表示val是float64类型
str = strconv.FormatFloat(val, 'f', 5, 64)
case bool:
str = fmt.Sprintf("%t", val)
str = strconv.FormatBool(val)
case byte:
str = fmt.Sprintf("%c", val)
str = fmt.Sprintf("%c", val)
}
return str
}
func string2BDT(str string) {
var num_ interface{}
if str == "true" || str == "false" {
num_, _ = strconv.ParseBool(str)
} else if strings.IndexAny(str, ".") != -1 {
num_, _ = strconv.ParseFloat(str, 64) // 64表示转成float64
} else {
num_, _ = strconv.ParseInt(str, 10, 64) // 10表示转成10进制,64表示转成int64
num_, _ = strconv.Atoi(str) // Atoi是ParseInt(str, 10, 0)的简写
}
fmt.Printf("%T:%q -> %T:%v\n", str, str, num_, num_)
}
func main() {
var (
num1 int = 90
num2 float64 = 23.33
b bool = true
m_char byte = 'a'
)
fmt.Printf("%v -> %q\n", num1, BDT2String(num1))
fmt.Printf("%v -> %q\n", num2, BDT2String(num2))
fmt.Printf("%v -> %q\n", b, BDT2String(b))
fmt.Printf("%v -> %q\n", m_char, BDT2String(m_char))
fmt.Printf("\n")
fmt.Println("num1's type: ", reflect.TypeOf(num1))
fmt.Println("num2's type: ", reflect.TypeOf(num2))
fmt.Println("b's type: ", reflect.TypeOf(b))
fmt.Println("m_char's type: ", reflect.TypeOf(m_char))
fmt.Printf("\n")
string2BDT("true")
string2BDT("15.2")
string2BDT("15")
}4)字符串与[ ]byte互转:
- 字符串转[ ]byte:
var bytes = []byte("12"); - [ ]byte转字符串:
n, err = string([]byte(97, 98, 99));
package main
import "fmt"
func main() {
// 字符串转[]byte
var bytes []byte = []byte("hello go")
fmt.Printf("bytes=%v\n", bytes)
// []byte转字符串
str := string([]byte{97, 98})
fmt.Printf("%s", str)
}5)查找子串是否在字符串中:
strings.Contains("seafoo", "foo"); // true6)统计一个字符串中有几个指定的子串:
strings.Count("cheese", "e"); // 47)不区分大小写的字符串比较:
fmt.Println(strings.EqualFold("abc", "ABc")); // true // 不区分大小写的比较
"abc" != "ABc"; // 如果直接用==判断,则会区分大小写8)返回子串在字符串中,第一次/最后一次出现的index值,没有则返回-1:
strings.Index("chinese", "e") // 4 // 第一次出现的index值
strings.LastIndex("chinese", "e") // 6 // 最后一次出现的index值9)将指定的子串 替换成 另一个子串(原字符串不发生变化,只是产生了新的字符串):
func Replace(s string, old string, new string, n int) string
// 返回将s中前n个不重叠old子串都替换为new的新字符串,如果n<0会替换所有old子串10)按照指定的某个字符,为分割的标识,将一个字符串拆分成字符串数组(原字符串不发生变化,只是产生了新的字符串):
strArr := strings.Split("hello,world", ",")11)将字符串进行大小写转换:
strings.ToLower("Go") // go
strings.ToUpper("Go") // GO12)将字符串左/右边指定的字符去掉:
strings.TrimSpace(" hello world ") // 去掉字符串左右两边的空格
strings.Trim("! hello!", " !") // 去掉字符串左右两边的"!"和" "
strings.TrimLeft("! hello!", " !") // 去掉字符串左边的"!"和" "
strings.TrimRight("! hello!", " !") // 去掉字符串右边的"!"和" "13)判断字符串是否是以指定的字符串开头/结束:
strings.HasPrefix("http:://***.com", "http") // true
strings.HasSuffix("we.jpg", ".png") // false2.14.11 时间和日期相关的函数:
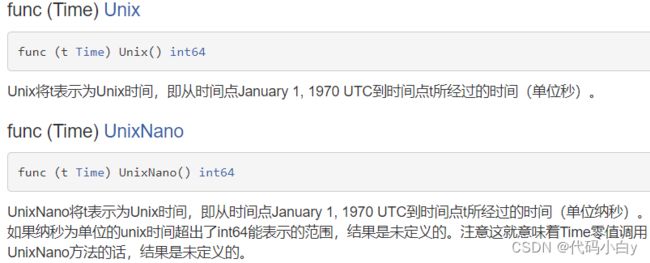
now := time.Now() // 返回当前的时间
// 格式化日期和时间
fmt.Printf("%d-%d-%d %d:%d:%d\n", now.Year(), int(now.Month()), now.Day(),now.Hour(), now.Minute(), now.Second())
dateStr = fmt.Sprintf("%d-%d-%d %d:%d:%d\n", now.Year(), int(now.Month()), now.Day(), now.Hour(), now.Minute(), now.Second())
fmt.Printf("%v\n", dateStr)
fmt.Printf(now.Format("2006/01/02 15:04:05"))
fmt.Printf(now.Format("2006-01-02"))
fmt.Printf(now.Format("15:04:05"))
fmt.Printf(now.Format("2006"))时间常量:Nanosecond、Microsecond、Millisecond、Second、Minute、Hour
// 休眠时间
time.Sleep(d*Duration) // Duration时间间隔,即时间常数d的整数倍数
// 获取当前 unix时间戳 和 unixnano时间戳(作用时可以获取随机数字)
fmt.Printf("%v %v\n", time.Now.Unix(), time.Now.UnixNano)
start := time.Now().Unix()
// 代码块
end := time.Now().Unix()
fmt.Printf("代码块的执行时间:%v\n", end - start)2.14.12 内置函数builtin:
go语言中,可以直接使用的函数。
1)len:用来求取长度,比如string、array、slice、map、channel;
2)new:用来分配内存,主要用来分配值类型,比如:int、float32、struct...,返回的是指针;

3)make:用来分配内存,主要用来分配引用类型,比如chan、map、slice等;
4)append:用来使slice切片,动态增长;
- 用法一:
slice3 = append(slice3, 元素1, 元素2) - 用法二:
slice3 = append(slice3, slice2...),其中,...是对slice2进行解构为一个个元素
append操作的底层原理分析:
- 本质就是对数组扩容;
- go底层会创建一个新的容量更大的数组;
- 将原slice中包含的元素拷贝到新的数组中,并把新添加的元素也放入新数组;
- slice重新引用到新数组(该新数组是底层来维护的,程序员不可见,只能通过切片访问)。
2.15 Go语言错误处理机制:
Go语言不支持try..catch..finally这种处理方式。Go中引入的处理方式为:defer,panic,recover;
这些异常的场景可以这么简单描述:Go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
package main
import "fmt"
func test() float64 {
// 匿名函数的定义和调用
defer func() {
// recover()内置函数,可以捕获到异常
if err := recover(); err != nil { // 说明捕获到了错误
fmt.Println("err=", err)
}
}()
num1 := 10
num2 := 0
return float64(num1 / num2)
}
func main() {
test()
}自定义错误类型:Go语言支持定义错误,使用errors.New()和panic内置函数;
// errors.New("错误说明") // 会返回一个error类型的值,表示一个错误
// panic(err) // 如果发生异常,则输出这个错误,并终止程序package main
import "fmt"
import "errors"
// 定义一个函数,用来读取配置文件ini.conf中的信息
// 如果文件传入不正确,则获取一个自定义的错误信息
func readConf(fileName string) (err error) {
if fileName == "config.ini" {
return nil
} else {
return errors.New("读取文件错误")
}
}
func test2() {
err := readConf("config_.ini")
if err != nil {
// 如果读取文件发生异常,则输出这个错误,并终止程序
panic(err)
}
fmt.Println("test2()继续执行")
}
func main() {
test()
test2()
}三、面向对象编程
3.1 引入
- golang是基于struct来实现面向对象OOP特性的。
- golang中的面向对象非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数和析构函数、隐藏的this指针等。
- 但仍然有面向对象编程的继承、封装和多态的特性,只是实现的方式不同(比如继承:golang中没有extends关键字 ,继承是通过匿名字段来实现的)。
3.2 结构体:
3.2.1 使用细节
- 结构体是一种自定义的数据类型,而结构体变量代表一个具体的变量。
- 结构体中,字段/属性,是相互独立的,且所有字段在内存中是连续分布的。
字段的声明语法同变量:type 结构体名称 struct{ field1 type ... fieldn type }。字段的类型可以为:基本类型、数组和引用类型。- 在创建一个结构体变量后,如果没有给字段赋值,都对应一个零值(默认值);指针、slice、map的零值都是nil,即还没有分配空间。
- 结构体是值类型,即结构体变量之间,默认是值拷贝;
- 结构体是用户单独定义的类型,和其它类型转换时需要完全相同的字段(名称、个数和类型)
type A struct {
Name string
Age int
}
type B struct {
Name string
Age int
}
func main() {
var stu1 A
var stu2 B
stu2 = B(stu1) // stu2 = stu1会报错,必须进行强转,且A、B结构体的所有字段完全相同
fmt.Printf("%v %v\n", stu1, stu2)
}- 结构体进行type重新定义(相当于取别名),golang认为是新的数据类型,但是相互之间可以进行强制转换。
type Student struct {
Name string
Age int
}
type Stu Student
func main() {
var stu1 Student
var stu2 Stu
stu2 = Stu(stu1) // stu2 = stu1会报错,必须进行强转
fmt.Printf("%v %v\n", stu1, stu2)
}- struct的每个字段上,可以写一个tag,该tag可以通过反射机制获取,常见的使用场景是序列化和反序列化。
package main
import (
"fmt"
"encoding/json"
)
// 当结构体中,字段/属性 的首字母是小写,则经过json.Marshal的处理返回的是空字符串;
//因为json.Marshal相当于在其他包中访问该结构体,首字母小写则无法被其他包访问;
type Monster struct {
Name string `json:"name"`
Age int `json:"age"`
Skill string `json:"skill"`
}
// 通过tag来解决
func main() {
// 将monster变量 序列化 为 json格式字串
monster1 := Monster{"tom", 12, "killer"}
jsonStr, err := json.Marshal(monster1) // json.Marshal()函数中,使用了“反射”
if err != nil {
fmt.Println("json发生错误", err)
} else {
fmt.Println("jsonStr = ", string(jsonStr))
}
}3.2.2 创建结构体变量 和 访问结构体字段:
golang在创建结构体变量时,可以直接指定字段/属性的值。
package main
import "fmt"
type Person struct {
Name string
Age int
}
func main() {
// 方式一:先创建结构体变量时,再指定字段/属性的值
var p1 Person
p1.Name = "Mary"
p1.Age = 10
fmt.Println(p1)
// 方式二:创建结构体变量时,直接指定字段/属性的值
p2 := Person{"Jary", 40}
fmt.Println(p2) // 将字段名和字段值,写在一起
p2 = Person{ // 这种写法不依赖与字段/属性,在结构体中声明的顺序
Name : "Jary",
Age : 20,
}
fmt.Println(p2)
// 方式三:结构体指针
var p3 *Person = new(Person)
// 结构体指针的标准访问形式:
(*p3).Name = "Jary" // p3.Name也可以,因为golang会在底层做转换处理
(*p3).Age = 20
fmt.Println(*p3)
// 方式四:结构体指针
var p4 *Person = &Person{"Tom", 30}
fmt.Println(*p4)
p4 = &Person{
// 这种写法不依赖于,字段/属性在结构体中声明的顺序
Name : "Tom",
Age : 20,
}
fmt.Println(*p4)
var p5 *Person = &p1
fmt.Printf("p1的地址%p\n", &p1)
fmt.Printf("p5的地址%p p5的值(即p5这段内存中保存的结构体指针指向的地址)%p\n", &p5, p5)
fmt.Println(*p5)
}3.2.3 结构体的内存分配机制:
结构体变量中,不同字段/属性的值是连续分布的(即使字段/属性是指针类型,也是来连续的存放指针指向的地址(但指针指向的地址不一定是连续的));
package main
import "fmt"
type Point struct {
x int
y int
}
type Rect1 struct {
leftUp, rightDown Point
}
type Rect2 struct {
leftUp, rightDown *Point
}
// 结构体的内存分配机制:
func main() {
rect1 := Rect1{Point{0, 0}, Point{1, 1}}
// 结构体变量中,不同字段/属性的值 是连续分布的
fmt.Printf("%p %p %p %p\n", &rect1.leftUp.x, &rect1.leftUp.y, &rect1.rightDown.x, &rect1.rightDown.y)
// 即使字段/属性是指针类型,也是来连续的存放指针指向的地址(但指针指向的地址不一定是连续的)
rect2 := Rect2{&Point{0, 0}, &Point{1, 1}}
fmt.Printf("本身的地址:%p %p\n", &rect2.leftUp, &rect2.rightDown)
fmt.Printf("指向的地址:%p %p\n", rect2.leftUp, rect2.rightDown)
}3.3 方法的声明、调用和传参机制:
3.3.1 方法和函数的区别:
- 调用方式不同(函数:函数名(实参列表);方法:变量.方法名(实参列表));
- 普通函数:接收者为值类型时,调用时只能传值;为引用类型时,调用时只能传地址;
- 对于方法,接收者为指针类型时,可以直接用指针类型的结构体变量调用该方法(编译器会进行优化,加上&符号),即最终还是看方法是如何绑定结构体变量的,如果绑定的是指针类型则是地址传递,如果是值类型则是值拷贝传递。
3.3.2 方法的声明和定义:
// 方法的声明和(定义)
func (receiver type) methodName(参数列表) (返回值列表) {
方法体
return 返回值
}
// 其中,receiver type表示将这个方法和type这个类型进行绑定,或者该方法用于type类型
// type可以是结构体,或者自定义的数据类型
// receiver就是type类型的一个变量(实例)3.3.3 方法的访问范围和传参机制:
- 访问范围控制方式和函数一样:方法名首字母小写,只能在本包中调用;大写,则既可以在本包中使用,也可以在其他包中使用。
- 方法中的传参机制:主要看方法是如何绑定结构体变量的,如果绑定的是值类型则是值拷贝,是传递指针类型则是地址传递(地址拷贝,会提高系统的执行效率,同时方法内部对该结构体变量字段的修改会影响方法外)。
package main
import "fmt"
type A struct {
Num int
}
// A结构体对象a,是值传递进入test()函数的,
//故函数内部的修改该对象对应的字段的值,并不会影响函数外
func (a A) test1() {
a.Num = 20
fmt.Println("将test1()方法,和结构体A的变量进行绑定")
fmt.Printf("test1()中a变量所在的地址:%p\n", &a)
fmt.Println(a.Num)
}
// 为了提高程序执行的效率,通常使用的方法和结构体时,进行指针类型的绑定
func (a *A) test2() {
(*a).Num = 30 // 等价于a.Num = 30,因golang的底层做了处理
fmt.Println("将test2()方法,和结构体A的指针变量进行绑定")
// 采用的是引用传递,来完成变量的传递
fmt.Printf("test2()中a变量所在的地址:%p a指针变量指向的地址(即a中保存的地址):%p\n", &a, a) // 该地址中,a指针变量指向的地址 与 main()函数中a变量的地址相同,表明了该变量与该方法时指针类型的绑定
fmt.Println((*a).Num)
}
func main() {
var a A
fmt.Printf("main()中a变量所在的地址:%p\n", &a)
a.Num = 10
// c采用值传递,将a结构体变量传入test()方法中
a.test1() // (&a).test1()仍然将结构体变量a的字段值拷贝到方法栈中
fmt.Println(a.Num)
// 采用引用传递,将a结构体变量传入test()方法中
(&a).test2() // 等价于a.test2(),因golang会自动加上&a
fmt.Println(a.Num)
}3.3.4 自定义数据类型都可以有方法:
package main
import "fmt"
// 自定义的类型都可以有方法,包括结构体和int、float64等
type integer int
func (i integer) Print() { // 值传递
fmt.Printf("i=%v\n", i)
}
func (i *integer) Change() { // 指针(引用)传递
*i = *i + 1
}
func main() {
var i integer = 19
i.Print()
(&i).Change()
i.Print()
fmt.Printf("i=%v\n", i)
}3.3.5 结构体中的String()方法
如果结构体实现了String()方法,则fmt.Println()默认会调用String()方法进行输出。
package main
import "fmt"
type Student struct {
Name string
Age int
Address string
}
func (stu *Student) String() string {
var str string = fmt.Sprintf("name=[%v] age=[%v] address=[%v]", (*stu).Name, stu.Age, stu.Address)
return str
}
func main() {
var stu Student = Student{"tom", 12, "shanxi"}
fmt.Println(stu)
// fmt.Println()默认会调用这个变量的String()方法,进行输出
fmt.Println(&stu)
}3.3.6 工厂模式:
用来解决 访问私有的结构体/结构体的字段(属性)的问题,类似于一个构造函数。

main.go
package main
import (
"fmt"
"Go_Code/Struct/factory_pattern/model"
)
// golang的结构体中,“没有构造函数”,通常可以使用“工厂模式”来解决问题
func main() {
stu := model.Student{
Name : "tom",
Age : 12,
}
fmt.Println(stu)
// pers := model.person{ // 报错
// Name : "tom",
// Age : 12,
// }
// fmt.Println(pers)
var pers = model.NewPerson("tom", 20)
fmt.Println(*pers)
fmt.Printf("pers type: %T\n", *pers)
fmt.Printf("Name=[%s] Age=[%d]\n", (*pers).Name, (*pers).GetAge())
}student.go
package model
// model包中,结构体变量首字母大写;
//外部main包中,引入后,可以直接调用;
type Student struct {
Name string
Age int
}
// model包中,结构体变量首字母小写;
//外部main包中,引入后,不可以直接调用;
//使用工厂模式,可以解决
type person struct {
Name string
age int
}
func NewPerson(m_name string, m_age int) *person {
return &person{
Name : m_name,
age : m_age,
}
}
// 如果结构体中age字段首字母小写,则其他包无法直接访问;可以通过函数来间接访问
func (pers *person) GetAge() int {
return (*pers).age
}3.4 接口
3.4.1 go语言核心interface:
- golang中面向接口interface编程是非常重要的特性(耦合度非常低);
- interface类型可以定义为一组方法,但不需要实现,并且interface中不能包含任何变量;如果某个自定义的数据类型要使用该接口时,再把接口的所有方法都实现了;
- 接口体现了“多态”和“高内聚低耦合”的思想;
// 基本语法:
type 接口名 interface {
method1(参数列表) 返回值列表
method2(参数列表) 返回值列表
}
func (自定义数据类型) method1(参数列表) 返回值列表 {
// 方法实现
}
func (自定义数据类型) method2(参数列表) 返回值列表 {
// 方法实现
}
// 小结:
// 1、接口里的所有方法都没有方法体(即都没有实现);
// 2、接口体现了“多态”和“高内聚低耦合”的思想;
// 3、golang中的接口,“不需要显示实现”。只需要一个变量,含有接口类型的所有方法,那么这个变量就实现了这个接口。
package main
import "fmt"
// 接口里的所有方法都没有方法体(即都没有实现)
type USB interface { // 接口
Start()
Stop()
}
type Camera struct {
}
func (camera Camera) Start() {
fmt.Println("camera开始工作")
}
func (camera Camera) Stop() {
fmt.Println("camera停止工作")
}
type Phone struct {
}
func (phone Phone) Start() {
fmt.Println("phone开始工作")
}
func (phone Phone) Stop() {
fmt.Println("phone停止工作")
}
type Computer struct {
}
// 多态参数usb
func (computer Computer) Working(usb USB) {
// 只需要一个变量,含有接口类型的所有方法,那么这个变量就实现了这个接口
usb.Start()
usb.Stop()
}
func main() {
var computer Computer
var camera Camera
var phone Phone
// 接口体现了“多态”和“高内聚低耦合”的思想
computer.Working(camera)
computer.Working(phone)
}3.4.2 接口的应用场景:
定规则;便于管理;
3.4.3 接口的注意细节:
1)接口本身不能创建实例,但可以指向一个实现了该接口所有方法的自定义类型的变量(实例)
(自定义的类型只有实现了某个接口的所有方法,才能将该自定义类型的实例赋给接口类型);
package main
import "fmt"
type Interface interface {
Say()
}
type Stu struct {
Name string
}
func (stu Stu) Say() {
fmt.Println("stu say()", stu.Name)
}
func main() {
var stu Stu = Stu{"tom~"}
stu.Say()
// 接口本身不能创建实例,但可以指向一个实现了该接口所有方法的自定义类型的变量(实例);
var interface1 Interface = stu
interface1.Say()
}2)接口中所有的方法都没有方法体,即都没有实现方法;且接口中不能有任何变量;
3)golang中,一个自定义的类型需要将某个接口的所有方法都实现,我们才能说这个自定义的类型实现了该接口;
4)只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型;
package main
import "fmt"
type Interface interface {
Say()
}
// 只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型;
type integer int
func (i integer) Say() {
fmt.Println("integer say()", i)
}
type Student struct {
}
func (student *Student) Say() {
fmt.Println("Say()")
}
func main() {
var i integer = 10
i.Say()
// 类似于c++中,将派生类对象 赋给 基类对象:
var interface2 Interface = i // 接口本身不能创建实例,但可以指向一个实现了该接口的自定义类型的变量(实例)
interface2.Say()
var stu Student = Student{}
var interface1 Interface = &stu // Student实现接口的Say()方法,是用指针类型的结构体变量,故赋值时要赋地址
interface1.Say()
}5)一个自定义的数据类型可以实现多个接口;
package main
import "fmt"
type Interface1 interface {
Say()
}
type Interface2 interface {
Hello()
}
type Commander struct {
Name string
}
func (commander Commander) Say() {
fmt.Println("commander say()", commander.Name)
}
func (commander Commander) Hello() {
fmt.Println("commander hello()", commander.Name)
}
func main() {
// 一个自定义的数据类型可以实现多个接口;
var commander Commander = Commander{"jary~"}
commander.Say()
commander.Hello()
var interface3 Interface1 = commander
interface3.Say()
var interface4 Interface2 = commander
interface4.Hello()
}6)一个接口A可以继承多个别的接口(B、C等),这时如果要实现A接口,也必须将B、C接口的方法全部实现;
package main
import "fmt"
type Interface1 interface {
Say()
}
type Interface2 interface {
Hello()
}
// 一个接口Interface3可以继承多个别的接口(Interface1、Interface2等),这时如果要实现Interface3接口,也必须将Interface1、Interface2接口的方法全部实现;
type Interface3 interface {
Interface1
Interface2
Hi()
}
type Student struct {
}
func (stu Student) Say() {
fmt.Println("stu Say()")
}
func (stu Student) Hello() {
fmt.Println("stu Hello()")
}
func (stu Student) Hi() {
fmt.Println("stu Hi()")
}
func main() {
var stu Student
var interface3 Interface3 = stu
interface3.Hello()
interface3.Say()
interface3.Hi()
}注意:在接口的继承中,如何两个父类接口含有相同的方法,则会报错(等价于该接口中含有两个重名的方法)。
type base1 interface {
test01()
test02()
}
type base2 interface {
test01()
test03()
}
type inter interface {
base1
base2 // 此处会报错,该接口中出现了重复的方法
} 7)interface类型默认是一个指针(引用类型)(如果没有对interface初始化,使用时则会返回nil);
8)空接口interface{}没有任何方法,所以所有类型都实现了空接口,即任何一个变量都可以赋给一个空接口;
var stu Student
var nil_interface interface{} = stu // 任何数据类型都可以赋给一个空接口
var i int
nil_interface = i3.4.4 interface的最佳实践:
实现对结构体切片的排序:
type Interface interface {
// Len方法返回集合中的元素个数
Len() int
// Less方法报告索引i的元素是否比索引j的元素小
Less(i, j int) bool
// Swap方法交换索引i和j的两个元素
Swap(i, j int)
}
sort.Sort(data interface)package main
import (
"fmt"
"math/rand"
"sort"
)
// 切片是引用类型(作为形参传入时,函数内部对切片的修改会影响函数外部的切片的内容)
func BubbleSort(slice []int, reverse bool) { // reverse=false默认是升序;reverse=true默认是降序;
for i := 0; i < len(slice); i++ {
for j := 0; j < len(slice)-i-1; j++ {
if !reverse {
if slice[j] > slice[j+1] {
temp := slice[j]
slice[j] = slice[j+1]
slice[j+1] = temp
}
} else {
if slice[j] < slice[j+1] {
temp := slice[j]
slice[j] = slice[j+1]
slice[j+1] = temp
}
}
}
}
}
// 快速排序
func QuickSort(slice []int, begin int, end int) {
if begin > end { // 递归结束的条件
return
}
// 定义基准点是temp
// 目标是:将基准点移动到切片中间的某个位置,使该位置的左边都小于基准点,右边都大于基准点
temp := slice[begin]
i := begin
j := end
for i != j {
for temp <= slice[j] && j > i {
j--
}
for temp >= slice[i] && j > i {
i++
}
if j > i {
tmp := slice[i]
slice[i] = slice[j]
slice[j] = tmp
}
}
slice[begin] = slice[i]
slice[i] = temp
// 对i左侧进行快速排序
QuickSort(slice, begin, i-1)
// 对i右侧进行快速排序
QuickSort(slice, i+1, end)
}
type Hero struct {
Name string
Age int
}
type HeroSlice []Hero // 定义结构体切片
func (heroSlice HeroSlice) Len() int {
return len(heroSlice)
}
func (heroSlice HeroSlice) Less(i, j int) bool {
return heroSlice[i].Age < heroSlice[j].Age // 升序
//return heroSlice[i].Age > heroSlice[j].Age // 降序
}
func (heroSlice HeroSlice) Swap(i, j int) {
var temp Hero = heroSlice[i]
heroSlice[i] = heroSlice[j]
heroSlice[j] = temp
}
func main() {
var int_slice []int = []int{10, 0, 7, 2, 4, 3, 6, 8, 1, 9} // 定义一个切片
BubbleSort(int_slice, true) // 冒泡排序
fmt.Println(int_slice)
//sort.Ints(int_slice) // Ints函数将对切片进行递增排序
QuickSort(int_slice, 0, len(int_slice)-1) // 快速排序对切片进行升序排序
fmt.Println(int_slice)
// 利用接口,对结构体切片进行排序
var heroes HeroSlice
for i := 0; i < 10; i++ {
var hero Hero = Hero{
Name: fmt.Sprintf("hero_%d", rand.Intn(10)),
Age: rand.Intn(100),
}
heroes = append(heroes, hero)
}
fmt.Printf("..... 排序前 ..... : ")
for _, val := range heroes {
fmt.Printf("%v ", val)
}
fmt.Println()
fmt.Printf("..... 排序后 ..... : ")
sort.Sort(heroes)
fmt.Println(heroes)
}3.4.5 接口与继承的关系:
- 当 A结构体 继承了 B结构体,那么A结构体就自动继承了 B结构体 的 字段和方法,并且可以直接使用;
- 当 A结构体需要扩展功能时,同时不希望去破坏继承关系,则可以去实现某个接口即可;故可以认为 “接口是继承的一种补充”。

package main
import "fmt"
type LearningEnglish interface {
LearnEnglish()
}
type Athlete struct {
kind string
}
func (athlete *Athlete) AthleteKind() {
fmt.Printf("%s athlete\n", (*athlete).kind)
}
type Basketball struct {
Athlete
}
type Soccer struct {
Athlete
}
func (soccer *Soccer) LearnEnglish() {
fmt.Printf("%s must learn the English\n", (*soccer).kind)
}
func main() {
soccer := Soccer{
Athlete: Athlete{
kind: "soccer",
},
}
soccer.AthleteKind()
soccer.LearnEnglish()
basketball := Basketball{
Athlete: Athlete{
kind: "basketball",
},
}
basketball.AthleteKind()
}3.4.6 接口、继承解决的问题不同:
- 继承的价值主要在于:解决了代码的 复用性 和 可维护性;
- 接口的价值在于:设计好各种规范(方法),让其它自定义类型去实现这些方法;
- 接口 比 继承更加灵活;
- 接口在一定程度上实现了代码的解耦;
3.4.7 类型断言:
由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型推断,具体如下:
package main
import "fmt"
type Point struct {
x int
y int
}
func main() {
var a interface{}
var point Point = Point{1, 2}
a = point // 空接口,可以接受任何数据类型
var b Point = a.(Point) // 必须进行类型断言,即判断a是否是指向Point的变量,不是则会进行报错
fmt.Println(b)
var c float32 = 1.1
a = c
d, ok := a.(float32)
fmt.Println(d)
if ok {
fmt.Println("convert successfully")
} else {
fmt.Println("convert fail")
}
}注意:在进行类型断言时,如果类型不匹配,就会报panic,因此进行类型断言时,要确保原来的空接口指向的是断言的类型;
3.4.8 类型断言的最佳实践:
1)在Phone结构体中,增加call方法,当usb接口接受的是Phone变量时,还需要调用call方法 。
package main
import "fmt"
// 接口里的所有方法都没有方法体(即都没有实现)
type USB interface { // 接口
Start()
Stop()
}
type Camera struct {
Name string
}
func (camera Camera) Start() {
fmt.Println("camera开始工作")
}
func (camera Camera) Stop() {
fmt.Println("camera停止工作")
}
type Phone struct {
Name string
}
func (phone Phone) Start() {
fmt.Println("phone开始工作")
}
func (phone Phone) Stop() {
fmt.Println("phone停止工作")
}
func (phone Phone) Call() {
fmt.Println("Phone正在打电话")
}
type Computer struct {
}
// 多态变量usb(空接口,可以接受任何数据类型)
func (computer Computer) Working(usb USB) {
// 只需要一个变量,含有接口类型的所有方法,那么这个变量就实现了这个接口
usb.Start()
// 类型断言:当空接口usb接受的变量是Phone类型时,需要进行类型断言,并执行Phone独有的方法Call()
usb_, ok := usb.(Phone)
if ok { // 类型断言成功,即ok==true
usb_.Call()
}
usb.Stop()
}
func main() {
var computer Computer
var camera Camera = Camera{"kongjia"}
var phone Phone = Phone{"xiaomi"}
// 接口体现了“多态”和“高内聚低耦合”的思想
computer.Working(camera)
computer.Working(phone)
fmt.Printf("\n")
// 多态数组
var usb_arr [2]USB = [2]USB{Camera{"kongjia"}, Phone{"xiaomi"}}
for i := 0; i < len(usb_arr); i++ {
computer.Working(usb_arr[i])
}
}2)写一个函数,循环判断传入参数的类型。
package main
import (
"fmt"
)
type Student struct {
Name string
Age int
Number string
}
// 函数的形参是可变参数
func TypeJudge(params ...interface{}) {
for index, val := range params { // type关键字的固定写法
switch val.(type) {
case bool:
fmt.Printf("第 %d 个参数是布尔类型,值是 %v\n", index, val)
case float32, float64:
fmt.Printf("第 %d 个参数是浮点数,值是 %.2f\n", index, val)
case int, int8, int16, int32, int64:
fmt.Printf("第 %d 个参数是整型,值是 %d\n", index, val)
case string:
fmt.Printf("第 %d 个参数是字符串,值是 %s\n", index, val)
case Student:
fmt.Printf("第 %d 个参数是Student类型,的值是 %v\n", index, val)
var val_ Student = val.(Student) // 类型断言,将接口的一般类型转换为Student类型
fmt.Printf("[Name]=%s, [Age]=%d, [Number]=%s\n", val_.Name, val_.Age, val_.Number)
case *Student:
fmt.Printf("第 %d 个参数是*Student类型,的值是 %v\n", index, val)
var val_ *Student = val.(*Student) // 类型断言,将接口的一般类型转换为Student类型
fmt.Printf("[Name]=%s, [Age]=%d, [Number]=%s\n", (*val_).Name, (*val_).Age, (*val_).Number)
default:
fmt.Printf("unmatched failure")
}
}
}
func main() {
var stu Student = Student{
Name: "mimi",
Age: 25,
Number: "2222666",
}
TypeJudge(11, "22", 1.2, true, stu, &stu)
}3.5 封装、继承和多态
golang中仍然有面向对象的继承、封装和多态的特性,只是实现方式和其他OOP语言不同。
golang本身对面向对象做了简化。
3.5.1 封装
对结构体中的属性进行封装;通过 方法、包 实现封装;

main.go
package main
import (
"Go_Code/OOP/encapsulation/module"
"fmt"
)
func main() {
var name string = "tom"
// 将Person结构体进行封装,使外界不能直接访问age、salary私有的字段/属性;
var person1 *(module.Person) = module.NewPerson(name)
(*person1).SetAge(20)
(*person1).SetSalary(10000)
fmt.Println(*person1)
fmt.Printf("name=%s, age=%d, salary=%.2f\n", (*person1).Name, (*person1).GetAge(), (*person1).GetSalary())
fmt.Println()
account1 := module.NewAccount("2222222", "666666", 10000.00) // var account1 *(module.account)
fmt.Println(account1)
var account_1 string = "2222222"
var pwd_1 string = "666666"
var money float64 = 12000.00
fmt.Printf("account=%s, balance=%.2f\n", account_1, (*account1).GetBalance(account_1, pwd_1))
(*account1).Deposite(money, pwd_1)
fmt.Println(*account1)
(*account1).WithDraw(money, pwd_1)
fmt.Println(*account1)
}person.go
package module
import "fmt"
type Person struct {
Name string
age int
salary float64
}
// 全局函数,相当于c++中的构造函数
func NewPerson(name string) *Person {
return &Person{
Name: name,
}
}
// 结构体对象Person的SetAge()方法
func (person *Person) SetAge(age int) {
if age >= 0 || age < 150 {
(*person).age = age
} else {
fmt.Printf("%v输入有误,年龄的范围是0~150\n", age)
}
}
// 结构体对象Person的GetAge()方法
func (person *Person) GetAge() int {
return (*person).age
}
// 结构体对象Person的SetSalary()方法
func (person *Person) SetSalary(salary float64) {
if salary < 0 || salary > 30000 {
fmt.Printf("%v输入有误", salary)
} else {
(*person).salary = salary
}
}
// 结构体对象Person的GetSalary()方法
func (person *Person) GetSalary() float64 {
return (*person).salary
}account.go
package module
import "fmt"
type account struct {
account string
pwd string
balance float64
}
// 工厂模式的函数,相当于构造函数
func NewAccount(m_account string, m_pwd string, m_balance float64) *account {
if len(m_account) < 6 || len(m_account) > 10 {
fmt.Printf("%s输入有误", m_account)
return nil
} else if len(m_pwd) != 6 {
fmt.Printf("%s输入有误", m_account)
return nil
} else if m_balance < 0 {
fmt.Printf("%s输入有误", m_account)
return nil
} else {
return &account{
account: m_account,
pwd: m_pwd,
balance: m_balance,
}
}
}
func (account *account) Deposite(money float64, pwd string) {
if pwd != (*account).pwd {
fmt.Println("password is error")
} else if money < 0 {
fmt.Println("money is error")
} else {
(*account).balance += money
fmt.Println("save the money successfully")
fmt.Printf("your balance is %.2f", (*account).balance)
}
}
func (account *account) WithDraw(money float64, pwd string) {
if pwd != (*account).pwd {
fmt.Println("password is error")
} else if money < 0 || money > (*account).balance {
fmt.Println("money is error")
} else {
(*account).balance -= money
fmt.Println("withdraw the money successfully")
fmt.Printf("your balance is %.2f", (*account).balance)
}
}
func (account *account) GetBalance(m_account string, m_pwd string) float64 {
if m_account == (*account).account && m_pwd == (*account).pwd {
return (*account).balance
} else {
return -1
}
}3.5.2 继承
- 当多个结构体中出现相同的属性/字段 和 方法时,可以从这些结构体中抽象出相同的属性/字段和方法,避免了多次定义这些属性/字段和方法,故可以解决代码的复用问题;
- golang中,如果一个struct结构体嵌套了另一个匿名结构体,故该结构体可以直接访问匿名结构体的字段/属性和方法,从而实现继承的特性;
main.go
package main
import (
"Go_Code/OOP/extends/module"
"fmt"
)
func main() {
// Pupil结构体继承了Student的属性/字段,Name、Number、score
pupil := module.Pupil{}
pupil.Name = "tom"
pupil.Number = "666666"
(&pupil.Student).SetScore(70) // Pupil结构体继承了Student的SetScore()的方法
// 等价于pupil.SetScore(),因子类与父类没有同名的方法;
// 如果子类与父类有同名的方法,通过子类对象直接访问时,采取“就近原则”;如果必须访问父类的该方法,则需要通过pupil.Student.SetScore(),即在中间加父类结构体名来完成
fmt.Println(&pupil) // Pupil结构体继承了Student的String()的方法,相当于c++重载<<运算符
// Graduate结构体继承了Student的属性/字段,Name、Number、score
graduate := module.Graduate{}
graduate.Name = "jary"
graduate.Number = "777777"
(&graduate.Student).SetScore(80) // Graduate结构体继承了Student的SetScore()的方法
fmt.Println(&graduate) // Graduate结构体继承了Student的String()的方法,相当于c++重载<<运算符
}student.go
package module
import "fmt"
type Student struct {
Name string
Number string
score float64
}
func (student *Student) SetScore(score float64) {
(*student).score = score
}
func (student *Student) String() string {
return fmt.Sprintf("name=[%s],number=[%s],score=[%.2f]\n", (*student).Name, (*student).Number, (*student).score)
}
type Pupil struct {
Student // 嵌入了匿名的结构体Student
}
func (pupil *Pupil) testing() {
fmt.Printf("pupil:%s is testing\n", (*pupil).Name)
}
type Graduate struct {
Student // 嵌入了匿名的结构体Student
}
func (graduate *Graduate) testing() {
fmt.Printf("graduate:%s is testing\n", (*graduate).Name)
}继承的深入讨论:
- 结构体可以使用嵌套匿名结构体所有的字段和方法,即首字母大/小写的 字段、方法,都可以使用,但小写是私有仍然只能本包使用。
- 匿名结构体字段/方法的访问,b.A.test()可以简化为b.test()。
- 当结构体 和 匿名结构体有相同的字段 或者 方法时,编译器默认采用就近访问原则,如果希望访问匿名结构体的 字段 和 方法,可以通过 匿名结构体名 来区分(当子类访问字段/属性 或者 方法时,会先在本结构体进行查找,然后再查找父类结构体中,找不到则会报错);
- 嵌套的匿名结构体可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值;
- 多继承:嵌套了两个/多个 匿名结构体,如两个匿名结构体有相同的字段和方法(且本结构体没有同名的字段和方法),访问时则必须加上要访问的匿名结构体的名称,否则会报错;

main.go
package main
import (
"Go_Code/OOP/Multi_Extends/module"
)
// 多继承的问题:如果结构体Base1和Base2有相同的字段和方法(且),
// 1)本结构体Child中没有同名的字段和方法,则访问时必须加上要访问的匿名结构体的名称,否则会报错;
// 2)本结构体Child中有同名的字段和方法,则访问时可以不加但会采取就近原则访问,要访问的匿名结构体的字段则必须加匿名结构体的名称
func main() {
// 嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值;
var child module.Child = module.Child{
module.Base1{ Name:"tom_base1" },
&module.Base2{"tom_base2"},
"tom_child",
}
child.Name = "tom_child_"
child.ShowInfo()
child.Base1.Name = "tom_base1_"
child.Base1.ShowInfo()
(*child.Base2).Name = "tom_base2_"
child.Base2.ShowInfo()
}multi_extends.go
package module
import "fmt"
type Base1 struct {
Name string
}
func (base1 *Base1) ShowInfo() {
fmt.Println("base1.Name=", base1.Name)
}
type Base2 struct {
Name string
}
func (base2 *Base2) ShowInfo() {
fmt.Println("base2.Name=", base2.Name)
}
type Child struct {
Base1
*Base2
Name string
}
func (child *Child) ShowInfo() {
fmt.Println("child.Name=", child.Name)
}- 组合(结构体中嵌套有名结构体):如果一个struct嵌套了一个有名结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字。
package main
import "fmt"
type Base1 struct {
Name string
}
func (base1 *Base1) ShowInfo() {
fmt.Println("Name=", base1.Name)
}
// 如果一个struct嵌套了一个有名结构体,这种模式就是组合,
//如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字。
type Child struct {
Name string
base1 Base1 // 有名结构体
}
func (child *Child) ShowInfo() {
fmt.Println("Name=", child.Name)
}
func main() {
var child Child
child.Name = "child"
(&child).ShowInfo()
child.base1.Name = "base1"
(&child.base1).ShowInfo()
}3.5.3 多态
1)变量(实例)具有多种形态。
2)Go语言中,多态的特征是通过接口实现的。
可以按照统一的接口来调用不同的实现,这时接口变量就显现不同的形态。
3)多态参数:通过传递不同类型的变量,并能根据接口进行自动识别,即接口的多态。
package main
import "fmt"
// 接口里的所有方法都没有方法体(即都没有实现)
type USB interface { // 接口
Start()
Stop()
}
type Camera struct {
}
func (camera Camera) Start() {
fmt.Println("camera开始工作")
}
func (camera Camera) Stop() {
fmt.Println("camera停止工作")
}
type Phone struct {
}
func (phone Phone) Start() {
fmt.Println("phone开始工作")
}
func (phone Phone) Stop() {
fmt.Println("phone停止工作")
}
type Computer struct {
}
// 多态参数usb
func (computer Computer) Working(usb USB) {
// 只需要一个变量,含有接口类型的所有方法,那么这个变量就实现了这个接口
usb.Start()
usb.Stop()
}
func main() {
var computer Computer
var camera Camera
var phone Phone
// 接口体现了“多态”和“高内聚低耦合”的思想
computer.Working(camera)
computer.Working(phone)
}4)多态数组:在USB数组中,保存了Phone 和 Camera变量,在遍历数组时,能够根据不同的变量,调用不同的对象属性。
// 多态数组
var usb_arr [2]USB = [2]USB{camera, phone}
for i := 0; i < len(usb_arr); i++ {
computer.Working(usb_arr[i])
}四、文件
4.1 文件的基础认识
1)文件是保存数据的一种形式,即数据源的一种,是一种特殊的数据库。文件在程序中,是以流的形式来操作的。

流:数据在数据源(文件)和程序(内存)之间经历的路径。
- 输入流:数据从数据源(文件)到程序(内存)的路径。
- 输出流:数据从程序(内存)到数据源(文件)的路径。
2)os.File封装了所有文件相关的操作,且File是一个结构体。

package main
import (
"fmt"
"os"
)
func main() {
// file名称:文件对象/文件指针/文件句柄
file, err := os.Open("./test.txt")
if err != nil {
fmt.Println(err)
}
fmt.Println(file) // file 是一个指针
// defer file.Close()
err = file.Close()
if err != nil {
fmt.Println(err)
}
}4.2 读取文件内容并显示在终端
4.2.1 带缓冲区的方式:
带缓冲区的方式读取文件内容,并显示在终端,bufio.NewReader() 和 reader.ReadString()。

package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
// file名称:文件对象/文件指针/文件句柄
file, err := os.Open("./test.txt")
if err != nil {
fmt.Println(err)
}
//当函数退出时,能及时的关闭文件句柄,防止内存泄漏
defer file.Close()
// 读取文件内容,并显示在终端(带缓冲区的方式):bufio.NewReader(rd io.Reader)
//,其中io.Reader是一个接口且只有一个方法Read,而os.File中实现了该方法
//,故可以直接将file赋值给该接口(接口本身不能创建实例,但可以指向一个实现了该接口所有方法的自定义类型的变量(实例))
var reader *bufio.Reader = bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF { // io.EOF表示已经读到了文件的末尾
break
}
fmt.Printf("%v", str)
}
}4.2.2 一次性读取的方式:
一次性将整个文件读取到内存并显示在终端,这种方式适合于文件不大的情况,ioutil.ReadFile()成功的调用返回的err为nil而非EOF。

package main
import (
"fmt"
"io/ioutil"
)
func OnceReadFile() {
// 使用ioutil.ReadFile()一次性将文件读取到位
content, err := ioutil.ReadFile("./test.txt")
if err != nil {
fmt.Println(err)
}
// 把读取到的文件内容显示在终端
fmt.Printf("%v", string(content)) // content:[]byte切片
// 此种读取文件的方式并没有显式的使用Open(),故不需要Close()
//,因为都被封装到了ReadFile()函数的内部
}
func main() {
OnceReadFile()
}4.3 给文件写内容
4.3.1 打开文件
![]()
该函数是一个更一般性的文件打开函数,它使用指定的选项、指定的模式、打开指定名称的文件。
flag int:文件打开模式(可以组合),如下:

perm FileMode:权限控制(linux下使用才有效)。
4.3.2 使用带缓存的方式写文件:
package main
import (
"bufio"
"fmt"
"os"
)
func WriteContentToFile() {
file, err := os.OpenFile("./test.txt", os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
// 写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
writer.WriteString("hello world!\n")
writer.WriteString("1 2 3 . . .")
// writer是先将内容写入到缓存中的,故需要调用Flush()方法,将缓存中的数据真正写到文件中
writer.Flush()
}
func CoverFileContent() {
file, err := os.OpenFile("test.txt", os.O_WRONLY|os.O_TRUNC, 0666)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
writer.WriteString("Hello world!\n")
}
writer.Flush()
}
func AppendContentToFile() {
file, err := os.OpenFile("./test.txt", os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
writer.WriteString("1 2 3 ...")
writer.Flush()
}
func main() {
WriteContentToFile()
CoverFileContent()
AppendContentToFile()
}4.4 读写文件
注意文件指针的位置,在末尾会导致读取不到文件的内容
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
file, err := os.OpenFile("./test.txt", os.O_APPEND|os.O_RDWR, 0666)
if err != nil {
fmt.Println(err)
}
defer file.Close()
// 从文件读取内容
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF { // 表明已经读到了文件的末尾
break
}
fmt.Print(str)
}
fmt.Println("...read the file completely...")
// 向文件写内容
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
if i == 0 {
writer.WriteString("\n")
}
writer.WriteString("\nHello World!")
}
writer.WriteString("\n1 2 3 走 ...")
writer.Flush()
fmt.Println("...write the file completely...")
}4.5 扩展应用
4.5.1 将文件的内容,拷贝到另一个文件中
![]()
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
)
/* 该函数只适合拷贝小文件 */
// 将test.txt文件下的内容,拷贝到test_.txt文件下
func OnceCopy(srcName string, dstName string) {
data, err := ioutil.ReadFile(srcName)
if err != nil {
fmt.Println(err)
return
}
err = ioutil.WriteFile(dstName, data, 0666)
if err != nil {
fmt.Println(err)
}
}
/* 该函数适合拷贝大文件 */
func CopyFile(dstFileName string, srcFileName string) (written int64, err error) {
srcFile, err := os.Open(srcFileName)
if err != nil {
fmt.Printf("Open source file error: error type is %v\n", err)
}
defer srcFile.Close()
// 通过srcFile获取Reader
reader := bufio.NewReader(srcFile)
dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("Open destination file error: error type is %v\n", err)
}
defer dstFile.Close()
// 通过dstFile获取Writer
writer := bufio.NewWriter(dstFile)
return io.Copy(writer, reader)
}
func main() {
OnceCopy("./test_src/test.txt", "./test_dst/test_.txt")
var dstFileName string = "./test_dst/timg_.jpg"
var srcFileName string = "./test_src/timg.jpg"
_, err := CopyFile(dstFileName, srcFileName)
if err != nil {
fmt.Println(err)
} else {
fmt.Println("Copy successfully!")
}
}
4.5.2 判断一个文件/文件夹是否存在的方法
![]()
package main
import (
"fmt"
"os"
)
// 判断一个文件/文件夹是否存在的方法:
// 使用os.Stat(name string) (fi FileInfo, err error)函数返回的错误类型判断:
// 1)err == nil,则文件存在;
// 2)os.IsNotExist(err) == true,则文件不存在;
// 3)如果错误为其他类型,则不确定是否存在;
func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil {
return true, nil
}
if os.IsNotExist(err) {
return false, nil
}
return false, err
}
func main() {
path := "F:/Go_Project/src/Go_Code/File/read_file" // 只能是绝对路径
exist, err := PathExists(path)
if err == nil && exist {
fmt.Printf("%s exists", path)
} else if err == nil && !exist {
fmt.Printf("%s non_exists", path)
} else {
fmt.Printf("Error information is %v, don't know whether exists.", err)
}
}4.5.3 统计文件中,英文、数字、空格 和 其他字符的数量:
package main
import (
"bufio"
"fmt"
"io"
"os"
)
// byte:uint8 rune:int32
type CharCount struct {
EngCount int
NumCount int
SpaceCount int
OtherCount int
}
func (charCount *CharCount) String() string {
str := fmt.Sprintf("[EngCount]=%d [NumCount]=%d [SpaceCount]=%d [OtherCount]=%d", (*charCount).EngCount, charCount.NumCount, charCount.SpaceCount, charCount.OtherCount)
return str
}
func main() {
// 打开文件,读取一行,并统计改行有多少个英文、数字、空格和其他字符,并将结果保存到一个结构体中
file, err := os.Open("./test.txt")
if err != nil {
fmt.Printf("open file error is %v\n", err)
}
defer file.Close()
reader := bufio.NewReader(file)
var charCount CharCount
for {
str, err := reader.ReadString('\n')
for _, val := range str {
// type rune = int 32
if val >= rune(byte('a')) && val <= rune(byte('z')) || val >= rune(byte('A')) && val <= rune(byte('Z')) {
charCount.EngCount++
} else if val == rune(byte(' ')) || val == rune(byte('\t')) {
charCount.SpaceCount++
} else if val >= rune(byte('0')) && val <= rune(byte('9')) {
charCount.NumCount++
} else {
charCount.OtherCount++
}
}
if err == io.EOF { // 代表已经读到了文件的末尾
break
}
}
fmt.Println(charCount)
fmt.Println(&charCount) // 调用了结构体CharCount中的String()方法
}
4.6 获取命令行参数
4.6.1 os.Args获取命令行参数
os包中的变量Args是一个string切片,用来存储所有的命令行参数。

package main
import (
"fmt"
"os"
)
// 运行程序./main.exe tomt tomt wiwie 09 // 命令行参数有 %d 个 5
func OsArgs_GetCommandParams() {
var str_slice []string = os.Args
fmt.Println("命令行参数有 %d 个", len(str_slice))
for index, val := range str_slice {
fmt.Printf("args[%v]=%v\n", index, val)
}
}
func main() {
OsArgs_GetCommandParams()
}4.6.2 flag包解析命令行参数


package main
import (
"flag"
"fmt"
"os"
)
// 运行程序./main.exe tomt tomt wiwie 09 // 命令行参数有 %d 个 5
func OsArgs_GetCommandParams() {
var str_slice []string = os.Args
fmt.Println("命令行参数有 %d 个", len(str_slice))
for index, val := range str_slice {
fmt.Printf("args[%v]=%v\n", index, val)
}
}
// flag包,用来解析命令行参数(不用在意参数的顺序)
func Flag_GetCommandParams() {
var user string
var pwd string
var host string
var post int
flag.StringVar(&user, "u", "", "default user is nil")
flag.StringVar(&pwd, "pwd", "", "default pwd is nil")
flag.StringVar(&host, "h", "localhost", "default hostname is localhost")
flag.IntVar(&post, "port", 0, "default port is 0")
// 转换操作,必须调用该方法!!!
flag.Parse()
fmt.Printf("[user]=%s [pwd]=%s [host]=%s [post]=%d", user, pwd, host, post)
}
func main() {
//OsArgs_GetCommandParams()
Flag_GetCommandParams()
}4.7 json数据格式
4.7.1 基本介绍:
json(javascript object notation)是一种轻量级的数据交换格式,易于阅读和编写、机器的解析和生成,并有效地提升了网络传输效率。
通常程序在网络传输时会先将数据(结构体、map等)序列化成json字符串,接收方将json字符串反序列化后,可以恢复成原来的数据类型。这种传输方式,已经成为了各个语言的标准。

4.7.2 json数据格式说明:
一个JSON对象是一个字符串到值的映射,写成一系列的name:value对形式,用花括号包含并以逗号分隔;也可以用于编码Go语言的map类型(key类型是字符串)和结构体。例如:
[{"key1":value1, "key2":value2, "key3":value3, "key4":[value4,value5]}, {"key6":value6, "key7":value7, "key8":value8, "key9":[value9,value10]}, ...]
JSON在线解析及格式化验证 - JSON.cn
4.7.3 json序列化:
json序列化,是将key-value结构的数据类型(如结构体、map、切片)序列化成json字符串。
基本数据类型,也可以序列化,但意义不太大。

package main
import (
"encoding/json"
"fmt"
)
// 用tag来指定序列化后的key
type Monster struct {
Name string `json:"monster_name"` // 涉及“反射机制”
Age int `json:"monster_age"`
Phone string `json:"monster_phone"`
Email string `json:"monster_email"`
}
func NewMonster(name string, age int, phone string, email string) *Monster {
return &Monster{
Name: name,
Age: age,
Phone: phone,
Email: email,
}
}
// 将 结构体 和 结构体切片 序列化
func SerialStructAndStructSlice() {
var monster1 *Monster = NewMonster("tom", 14, "1234567", "[email protected]")
var monster2 *Monster = NewMonster("jary", 16, "1234568", "[email protected]")
res, err := json.Marshal(*monster1) // Marshal(val interface{})
if err != nil {
fmt.Printf("Serialization failed, Error is %s\n", err)
}
fmt.Println(string(res))
// var monsters []Monster = make([]Monster, 2)
// monsters[0] = *monster1
// monsters[1] = *monster2
var monsters []Monster
monsters = append(monsters, *monster1)
monsters = append(monsters, *monster2)
res, err = json.Marshal(monsters) // Marshal(val interface{})
if err != nil {
fmt.Printf("Serialization failed, Error is %s\n", err)
}
fmt.Println(string(res))
}
// 将 map 和 map切片 进行序列化
func SerialMap() {
var map_1 map[string]interface{} = make(map[string]interface{}, 5)
map_1["name"] = "tom"
map_1["sex"] = "male"
map_1["age"] = 35
map_1["work"] = "worker"
res, err := json.Marshal(map_1)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(res))
var map_2 map[string]interface{} = make(map[string]interface{}, 5)
map_2["name"] = "jary"
map_2["sex"] = "female"
map_2["age"] = 25
map_2["work"] = "student"
var map_ []map[string]interface{}
map_ = append(map_, map_1)
map_ = append(map_, map_2)
res, err = json.Marshal(map_)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(res))
}
func main() {
SerialStructAndStructSlice()
SerialMap()
}4.7.4 json反序列化
- 反序列化,指将
json格式的数据反序列化成对应的数据类型(比如,结构体、map、切片等)的操作。 - 在反序列化时,需要保持反序列化后的数据类型 和 序列化前的数据类型 保持一致。
- 如果json字符串是通过转义字符获取到的,则不需要再对其转义处理。

package main
import (
"encoding/json"
"fmt"
)
// 将json反序列化 成 map
func DeserializationMap() {
// 在开发过程中,该json字符串一般是通过,网路传输/读取文件 得到的
var str string = "[{\"age\":35,\"name\":\"tom\",\"sex\":\"male\",\"work\":\"worker\"}," +
"{\"age\":25,\"name\":\"jary\",\"sex\":\"female\",\"work\":\"manager\"}]"
var map_ map[string]interface{}
err := json.Unmarshal([]byte(str), &map_)
if err != nil {
fmt.Println(err)
}
fmt.Println(map_)
for key, val := range map_ {
fmt.Printf("[%s]=%v\t", key, val)
}
fmt.Println()
}
type Monster struct {
Name string
Age int
Sex string
}
func DeserializationStruct() {
// 在开发过程中,该json字符串一般是通过,网路传输/读取文件 得到的
var str string = "{\"Name\":\"tom\",\"Age\":25,\"sex\":\"male\"}"
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Println(err)
}
fmt.Println(monster)
}
func main() {
DeserializationMap()
DeserializationStruct()
}五、单元测试
传统方法,
- 需要在main函数中调用需要测试的函数单元,比较麻烦;
- 但测试多个模块时,会不利于管理和理清思路;
Go语言中,自带有一个轻量级的测试框架testing和自带的go test 命令,来实现单元测试 和 性能测试。同时,可以根据这个testing框架写针对相应函数的测试用例/压力测试用例。
单元测试,可以解决的问题:
- 确保每个函数是可运行的,并且运行结果是正确的;
- 确保写出来的代码的性能是最好的;
- 单元测试能及时发现程序设计或实现的逻辑错误;而性能测试,重点在于让程序在高并发的情况下,也能正常运行;
单元测试的入门总结:
- 测试用例 文件名必须以
_test.go结尾; - 测试用例函数必须以Test开头,一般来说:
Test+首字母大写的被测试的函数名; - 测试用例函数 的形参类型必须是
*testing.T; - 运行测试用例指令:go test(只有运行错误,才会输出日志) / go test -v(运行正确或错误,都会输出日志);
- 当出现错误时,可以使用
t.Fatalf()来格式化输出错误信息;t.Logf()可以输出相应的日志; - 测试用例,并不需要放在
main()函数中执行; - 测试单个文件,需要带上被测试的源文件:
go test -v ***_test.go ***.go; - 测试单个方法:
go test -v -test.run TestXxxx(其中Xxxx是待测试的函数名,首字母大写);
六、goroutine协程和channel管道
6.1 goroutine协程
6.1.1 进程和线程:
1)进程是程序在操作系统中的一次执行过程,是系统进行进行资源分配和调度的基本单位;
2)线程是进程的一个执行实例,是程序执行的最小单位(比进程更小的能独立运行的基本单位);
3)一个进程可以创建和销毁多个线程,同一个进程中的多个线程可以并发执行;
4)一个程序至少有一个进程,一个进程至少有一个线程;
6.1.2 并行和并发:
1)并发:多线程程序在单核上运行;微观上来看,某一个时间点只有一个任务在执行;
2)并行:多线程程序在多核上运行;微观上来看,某一个时间点有多个任务同时在执行。因此,并行的速度比并发快。
6.1.3 Go协程和Go主线程
1)Go主线程(可以理解为线程/进程):一个Go线程上,可以起多个协程,可以理解为协程是轻量级的线程(编译器做优化);
2)Go协程的特点:
- 有独立的栈空间;
- 共享程序堆空间;
- 调度由用户控制;
- 协程是轻量级的线程;
如果主线程退出了,则协程即使没有执行完毕, 也会直接退出;协程也可以在主线程没有结束前,完成任务并退出。
3)总结:
- 主线程是一个物理线程,直接作用在CPU上,是重量级的,非常耗费CPU资源;
- 协程是从主线程开启的,是轻量级的线程,是逻辑态,对资源的消耗相对小;
- golang的协程机制是重要的特点,可以轻松开启上万个协程;其他编程语言的并发是基于线程的,开启过多的线程会对资源消耗巨大,这就凸现了golang在并发上的优势;
6.1.4 goroutine的调度模型:MPG模式
M:操作系统的主线程(是物理线程)、P:协程执行需要的上下文、G:协程
MPG模式运行的两种状态:
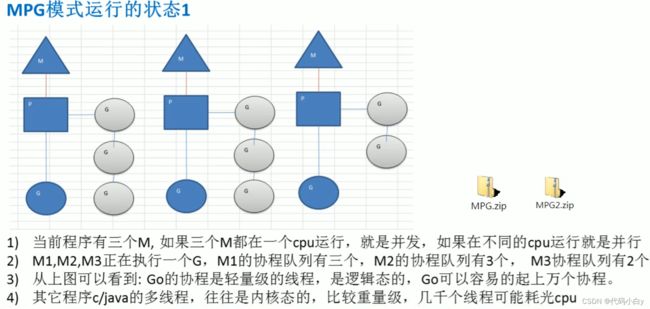

举例:
package main
import (
"fmt"
"runtime"
"strconv"
"time"
)
func test() {
for i := 1; i < 10; i++ {
fmt.Println("hello world" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
num := runtime.NumCPU()
fmt.Printf("the number of CPU is %d\n", num)
runtime.GOMAXPROCS(num) // 设置最大可以调度的CPU的个数
go test() // 开启了一个协程
for i := 1; i < 10; i++ {
fmt.Println("hello golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}6.1.5 goroutine协程存在的问题
- 用
goroutine协程,来实现并行和并发,如何实现不同协程间的通信; - 由于没有对全局变量加锁,故在程序在运行时,可能存在资源竞争的问题(如concurrent map writes)(通过
go build -race main.go来检查);
package main
import "fmt"
var map_ map[int]int = make(map[int]int, 200)
func Factorial(n int) {
var res int
for i := 1; i < n; i++ {
res *= i
}
map_[n] = res
}
func main() {
for i := 0; i < 200; i++ {
go Factorial(i)
}
for index, val := range map_ {
fmt.Printf("map[%d]=%d\n", index, val)
}
}
不同的goroutine之间如何通信: ①全局变量加锁同步、②使用channel管道
1)使用全局变量加锁同步改进程序:通过加入互斥锁解决问题;

package main
import (
"fmt"
"sync"
"time"
)
var (
map_ map[int]int64 = make(map[int]int64, 200)
lock sync.Mutex // 加入全局变量互斥锁
)
func Factorial(n int) {
var res int64 = 1
for i := 1; i <= n; i++ {
res *= int64(i)
}
// 加锁
lock.Lock()
map_[n] = res
// 解锁
lock.Unlock()
}
func main() {
for i := 0; i < 20; i++ {
go Factorial(i)
}
time.Sleep(10 * time.Second)
// 此处加互斥锁,是为了避免出现正在执行某个协程(即写map),就开始输出(即读map)
lock.Lock()
fmt.Println(map_)
for index, val := range map_ {
fmt.Printf("map[%d]=%d\n", index, val)
}
lock.Unlock()
}
2)为什么需要channel管道
- 使用sync同步通信,即加互斥锁,避免资源竞争时很低级的;
- 主线程的等待休眠时间很难把握,时间短了可能goroutine正在执行主线程就结束了;时间长了,会造成等待时间过长和资源浪费;
- 通过全局变量加锁同步实现通讯,也不利于多协程对全局变量的读写操作;
,从而需要新的通信方式 -- channel管道。
6.2 channel管道
6.2.1 介绍
-
channel本质是一个数据结构 -- 队列,即FIFO;
-
多协程goroutine访问同一个全局变量时,不需要加锁,因为channel本身就是线程安全的;
-
channel是有类型的,如一个string类型的channel只能存放string类型的数据。
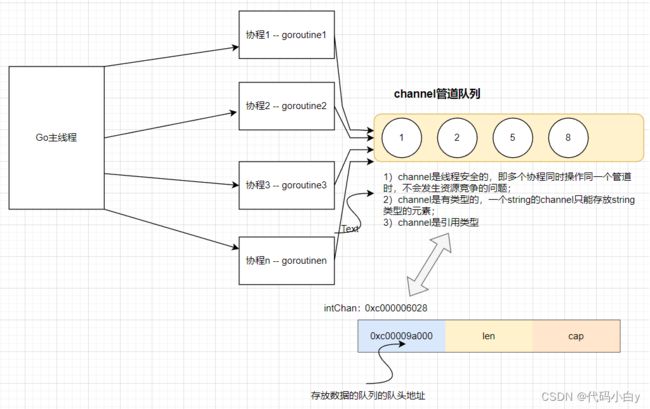
6.2.2 基本使用:
1、声明和定义channel:
channel是引用类型;必须初始化后,才能写入数据,即make后才能使用;channel管道是有类型的;
//var 变量名 chan 数据类型
var intChan chan int // intChan用于存储int数据
var stringChan chan string
var mapChan chan map[int]string
type Person struct {
Name string
Age int
}
var perChan chan Person
var perPtrChan chan *Person
package main
import "fmt"
// channel是引用类型
func main() {
// 1、声明和定义一个int类型的容量capability=3的管道
var intChan chan int = make(chan int, 3)
fmt.Printf("intChan的地址 %p, intChan中保存的值 %v\n", &intChan, intChan)
// 2、给管道中添加元素,不能超过其容量capability,否则会报错deadlock死锁
intChan <- 10
num := 20
intChan <- num
fmt.Printf("len(intChan)=%v, cap(intChan)=%v\n", len(intChan), cap(intChan))
// 3、从管道中取出数据
var num2 int
for i := len(intChan); i > 0; i-- {
num2 = <-intChan
fmt.Printf("%v ", num2)
}
fmt.Println()
fmt.Printf("len(intChan)=%v, cap(intChan)=%v\n", len(intChan), cap(intChan))
// 4、在没有使用协程的情况下,如果管道的数据已经全部取出,再取的话会报错deadlock死锁
num2 = <-intChan
}2、注意事项:
-
channel是引用类型,且必须初始化后,才能写入数据,即make后才能使用;
-
channel管道是有类型的,即只能存放指定数据类型的数据;
-
给管道中添加元素,不能超过其容量capability(channel并不会自动扩容),否则会报错deadlock死锁;
-
在没有使用协程的情况下,如果管道的数据已经全部取出,再取的话会报错deadlock死锁
package main
import (
"strings"
"fmt"
)
func main() {
// 创建一个最多可存放10个任意数据类型变量的管道allChan
var allChan chan interface{}
allChan = make(chan interface{}, 10) // channel并不会自动扩容
allChan <- 10
num := 20
allChan <- num
allChan <- Person{"tom", 24}
var map_ map[int]string = make(map[int]string, 2)
map_[1] = "hihi"
map_[2] = "haha"
map_[3] = "heihei"
allChan <- map_
fmt.Printf("len(map_)=%v: %v\n", len(map_), map_)
var slice []int = make([]int, 4)
slice = append(slice, 1, 2)
allChan <- slice
fmt.Printf("len(slice)=%v,cap(slice)=%v: %v\n", len(slice), cap(slice), slice)
fmt.Printf("len(allChan)=%v,cap(allChan)=%v\n", len(allChan), cap(allChan))
// 读取管道中的任意类型的数据
for len(allChan) > 0 {
val := <-allChan
switch val.(type) {
case int:
fmt.Println(val)
case Person:
val_ := val.(Person)
str := "Person: [" + fmt.Sprintf("Name:%v, Age:%v", val_.Name, val_.Age) + "]"
fmt.Println(str)
case map[int]string:
fmt.Println(val)
case []int:
val_ := val.([]int)
str := "[]int: ["
for i := len(val_) - 1; i >= 0; i-- {
str += fmt.Sprintf("%v ", val_[i])
}
str = strings.TrimSpace(str)
str += fmt.Sprintln("]")
fmt.Println(str)
}
}
}6.3 channel的遍历和关闭:
6.3.1 channel的关闭:
使用内置函数close可以关闭channel,当channel关闭后,就不能再向channel写数据,但仍可以从中读数据。
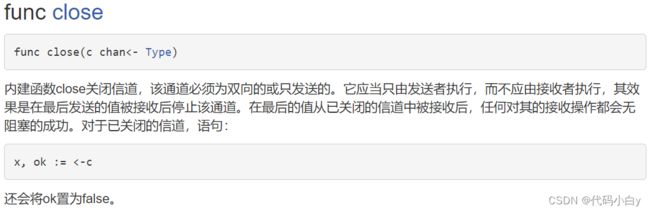
6.3.2 channel的遍历:
支持for-range的方式遍历,但注意for-range管道时,当遍历到最后的时候,
-
如果发现channel是打开的,则认为还有可能继续给管道写入数据,故会等待,当没有程序给管道写入数据时,就会出现deadlock报错;
-
如果发现channel是关闭的,则会在遍历完后,正常退出即可;
package main
import (
"fmt"
)
var chan_cap int = 20
func main() {
var allChan chan interface{} = make(chan interface{}, chan_cap)
for i := 0; i < chan_cap; i++ {
allChan <- i
}
close(allChan)
//allChan <- 20 // 报错,不能向已经关闭的channel管道中,发送数据
// channel管道关闭后,仍然可以正常的读取数据
// 方式一:
for i := len(allChan); i > 0; i-- {
val := <-allChan
fmt.Println(val)
}
// 方式二:for-range
// 只有在管道关闭后,遍历完才能正常的退出,否则会报deadlock错误
for val := range allChan {
fmt.Println(val)
}
}6.4 goroutine和channel的结合案例:
6.4.1 两个协程同时操作一个管道
要求(writeData、readData操作的是同一个管道intChan):
-
开启一个writeData协程,向管道intChan写50个数据;
-
开启一个readData协程,从管道intChan中读取writeData向其写入的数据;
-
主线程需要等待writeData和readData,都执行完成后才能退出;

package main
import (
"fmt"
)
var intChan_cap int = 50
func writeData(intChan chan int) {
for i := 0; i < intChan_cap; i++ {
intChan <- i
fmt.Printf("write a data %v into intChan\n", i)
}
close(intChan)
}
func readData(intChan chan int, exitChan chan bool) {
for {
val, ok := <-intChan // intChan通道如果已关闭且intChan已空,则ok==false
if !ok {
break
}
fmt.Printf("read a data %v from intChan\n", val)
}
exitChan <- true
close(exitChan)
}
func main() {
var intChan chan int = make(chan int, intChan_cap)
var exitChan chan bool = make(chan bool, 1)
go writeData(intChan)
go readData(intChan, exitChan)
// exitChan管道的引入,是为了让主线程阻塞等待
//,只有readData和writeData协程都执行完且intChan和exitChan已关闭且exitChan为空后时,才有ok==false
//,此时才结束掉主线程
for {
_, ok := <-exitChan // exitChan已关闭且为空后,才有ok==false
if !ok {
break
}
}
}6.4.2 多个协程同时操作多个管道
1、要求:
-
启动一个协程,将1-2000的数放入到一个channel中,比如numchan
-
启动八个协程,从intChan取出数n,并计算1+..n的值,后存放到reschan
-
最后等待工作完成后,再遍历reschan,最后显示结果

package main
/*
var intChan chan int
var resChan chan map[int]int
var exitChan chan bool
*/
import (
"fmt"
"runtime"
)
var intChan_cap int = 2000
var goroutine_nums = 8
/* 每个协程都从intChan管道中拿数据,并分别计算数据的累加和,存入resChan中 */
func calc(intChan chan int, resChan chan map[int]int, exitChan chan bool) {
for {
// 从intChan管道取出需要计算累加的数据
k, ok := <-intChan // 如果intChan已关闭,则ok==false
if !ok {
break
}
var resNum int
for i := 1; i <= k; i++ {
resNum += i
}
map_ := map[int]int{k: resNum}
resChan <- map_
}
// 当一个协程调用calc函数结束后,给exitChan管道中,添加一个元素true
exitChan <- true
}
func main() {
// 查询物理CPU个数,并设置最大可调用的CPU个数
cores := runtime.NumCPU()
runtime.GOMAXPROCS(cores - 1)
// channel是"引用类型";当管道满了后,会deadlock死锁错误(channel不会扩容);
intChan := make(chan int, intChan_cap)
resChan := make(chan map[int]int, intChan_cap)
exitChan := make(chan bool, goroutine_nums) // 用来判断所有协程对resChan写入操作是否完成
// 写一个匿名函数来给intChan管道写入数据,并调用
go func() {
for i := 1; i <= 2000; i++ {
intChan <- i
}
close(intChan)
}()
// 开启goroutine_nums个协程,来计算分别每个数值的累加和
for i := 0; i < 8; i++ {
go calc(intChan, resChan, exitChan)
}
// 循环请求goroutine_nums次,等待读取eixtChan中的true达到数目后
//,证明所有计算完成并已写入到resChan中,这时才可以继续主线程
for i := 0; i < goroutine_nums; {
val, _ := <-exitChan
if !val { // 等价于if !(<-exitChan)
continue
} else {
i++
}
}
// 关闭resChan管道,并用for-range遍历管道的数据
close(resChan)
//遍历结果集
for val := range resChan {
fmt.Println(val)
}
}2、要求:统计1 ~ 8000的数字中,哪些是素数?

package main
/* 统计1~8000所有的素数 */
import (
"fmt"
"math"
)
var goroutineNums int = 4
func getPrimeNum(intChan chan int, primeChan chan int, exitChan chan bool) {
var flag bool
for {
val, ok := <-intChan
// 该协程从intChan中拿数据
//,如果intChan已关闭则拿数据直到没有后ok==false正常退出;如果intChan没有关闭,拿不到数据会一直阻塞拿到后继续执行...
if !ok {
break
}
flag = true
for i := 2; i <= int(math.Sqrt(float64(val))); i++ {
if val%i == 0 {
flag = false
break
}
}
if flag {
primeChan <- val
}
}
// 每当有一个协程调用完该函数,则会给exitChan管道写入一个数据true
exitChan <- true
}
func main() {
var intChan chan int = make(chan int, 8000)
var primeChan chan int = make(chan int, 8000)
var exitChan chan bool = make(chan bool, goroutineNums)
go func() {
for i := 1; i < 8000; i++ {
intChan <- i
}
close(intChan)
}()
for i := 0; i < goroutineNums; i++ {
go getPrimeNum(intChan, primeChan, exitChan)
}
go func() { // 增加该协程是为了保证当primeChan中一旦有数据就可以打印输出,而不是等到close(primeChan)后才读取和打印输出
for i := 0; i < goroutineNums; { // 当exitChan管道中有8个true时,表示所有素数已求解完毕,可以close(primeChan)
if !(<-exitChan) {
continue
} else {
i++
}
}
close(primeChan)
}()
for {
// 只有上一个匿名函数的协程执行完成后
//,即exitChan中有8个true且close(primeChan)时,此后读取到primeChan最后一个元素后才有ok==false,即才能正常结束主线
res, ok := <-primeChan // primeChan中如果没有数据就取的话,由于primeChan管道并没有关闭,故会阻塞知道读到数据才打印输出并继续读取...
if !ok {
break
} else {
fmt.Println(res)
}
}
}6.5 管道阻塞机制:
如果编译器(运行时),发现一个管道只有写,没有读,则该管道会阻塞而deadlock;
写管道和读管道的频率不一致,无所谓;
6.6 channel使用注意事项:
6.6.1 声明channel为只读/只写属性:
package main
import "fmt"
/* channel使用注意事项: */
func main() {
// 1、管道可以声明为只读/只写
var intDoubleChan chan int = make(chan int, 2) // 默认情况下是双向的
intDoubleChan <- 10
num := <-intDoubleChan
fmt.Println(num)
// 声明为只写的管道
var intWriteChan chan<- int = make(chan<- int, 2)
intWriteChan <- 10
//num = <-intWriteChan // error:cannot receive from send-only channel intChan2
// 声明为只读的管道
var intReadChan <-chan int = make(<-chan int, 2)
num = <-intReadChan // 因在不涉及协程时,intReadChan没有关闭且其中没有元素,故读取的话会报deadlock错误
//intReadChan <- 10 // error:cannot send to receive-only type <-chan int
//fmt.Println(num)
}6.6.2 select解决管道取数据的阻塞问题:
package main
import "fmt"
func main() {
var intChan chan int = make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
var stringChan chan string = make(chan string, 10)
for i := 0; i < 10; i++ {
stringChan <- fmt.Sprintf("-%v", i)
}
// 传统方式遍历读取管道数据时,如果提前关闭管道,会发生死锁deadlock阻塞
for {
// 如果intChan被取空了且没有关闭,也不会一直阻塞而deadlock,会自动向下执行下一个case,直到最终执行完default为止
select {
case v := <-intChan:
fmt.Printf("get data from the intChan, %v\n", v)
case v := <-stringChan:
fmt.Printf("get data from the stringChan, %v\n", v)
default:
fmt.Println("intChan、stringChan管道都已空")
return
}
}
}6.6.3 recover解决协程中出现panic,而导致整个程序崩溃的问题:
说明:①如果程序的一个协程出现panic,在没有捕获该panic的前提下,整个程序会崩溃掉;
②若在协程中用recover捕获了该panic,这样即使该协程出现panic但主线程和主线程上的其他协程仍然可以正常执行。
package main
import "fmt"
func main() {
go func() {
for i := 0; i < 10; i++ {
fmt.Println("hello world " + string('a'+byte(i)))
}
}()
/*
go func() {
var map_ map[int]string
map_[0] = "hello world 0" // panic: assignment to entry in nil map
}()
*/
// 通过defer + recover,解决该协程中由于panic导致其他协程也崩溃的问题,使其他协程正常执行
go func() {
defer func() {
err := recover()
if err != nil {
fmt.Printf("该协程执行报错,%v\n", err)
}
}()
//var map_ map[int]string
//map_[0] = "hello world 0" // panic: assignment to entry in nil map
}()
// 阻塞主线程等待所有协程执行完毕
time.Sleep(10 * time.Second)
}七、反射
7.1 引入:
1)不知道接口调用哪个函数,根据传入参数在运行时确定调用的具体接口,需要用到对函数/方法的反射。
test1 := func(val1 int, val2 int) {
t.Log(val1, val2)
}
test1 := func(val1 int, val2 int, s string) {
t.Log(val1, val2, s)
}
// 要求用反射机制,完成函数的适配器,用桥连接:
func bridge(funcPtr interface{}, args ...interface{}) {
// 使用反射机制写
}
// 第一个参数以接口的形式传入函数指针;
// 第二个参数args以可变参数的形式传入;
// bridge()函数中,可以用反射来动态执行funcPtr()函数
bridge(test1, 1, 2)
bridge(test2, 1, 2, "hello")2)结构体的序列化时,如果结构体指定了Tag,也会使用反射生成对应的字符串。
7.2 基本介绍:
1)反射可以在运行时,动态的获取变量的各种信息,比如类型、类别;
2)如果是结构体类型,还可以获取到结构体本身的信息,包括结构体的字段、方法;
3)通过反射,可以修改变量的值,还可以调用关联的方法;


7.3 反射重要的函数和概念:
1)reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型;

2)reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型(结构体),继而可以获取很多该变量的信息;

3)反射中,变量、interface{}、reflect.Value是可以相互转换的;


4)reflect.Value.Kind,获取类型的类别,返回的是一个常量;


func StructTypeConvert(val interface{}) {
rTyp := reflect.TypeOf(val)
rTypKind := rType.Kind()
fmt.Println(rTyp, rKind)
rVal := reflect.ValueOf(val)
fmt.Println(rVal.Type(), rVal.Kind())
}Type是类型,Kind是类别,两者可能相同也可能不同:
var i int = 10
//Type:int Kind:int
var stu Person := Person{"tom", 10}
//Type:包名.Person Kind:struct5)使用反射获取变量值时,要求数据类型匹配,否则会报panic错误;
package main
import (
"fmt"
"reflect"
)
/* 基本数据类型、interface{}、reflect.Value,之间的相互转换: */
func BaseTypeConvert(val interface{}) {
// 通过反射获取传入变量的类型type、kind、值
// 1、利用reflect.TypeOf(变量名)获取变量的类型,返回reflect.Type类型
rTyp := reflect.TypeOf(val)
fmt.Println(rTyp)
// 2、利用reflect.ValueOf(变量名)获取变量的值,返回reflect.Value类型(结构体),继而可以获取很多该变量的信息
rVal := reflect.ValueOf(val)
fmt.Println(rVal.Type(), rVal.Int())
// 3、利用reflect.Value结构体中,Interface()方法,将reflect.Value类型转换成interface{}接口类型
val_ := rVal.Interface()
fmt.Println(val_.(int))
}
/* 结构体类型、interface{}、reflect.Value,之间的相互转换: */
func StructTypeConvert(val interface{}) {
// 通过反射获取传入变量的类型type、kind、值
// 1、利用reflect.TypeOf(变量名)获取变量的类型,返回reflect.Type类型
rTyp := reflect.TypeOf(val)
fmt.Println(rTyp)
// 2、利用reflect.ValueOf(变量名)获取变量的值,返回reflect.Value类型(结构体),继而可以获取很多该变量的信息
rVal := reflect.ValueOf(val)
fmt.Println(rVal.Type())
// 3、利用reflect.Value结构体中,Interface()方法,将reflect.Value类型转换成interface{}接口类型
val_ := rVal.Interface()
person, ok := val_.(Person)
if ok {
fmt.Println(person.Name, person.Age)
}
}
func main() {
var i int = 100
BaseTypeConvert(i)
/*结果:
int
int 100
100
*/
person := Person{
Name: "tom",
Age: 10,
}
StructTypeConvert(person)
/*结果:
main.Person
main.Person
tom 10
*/
}6)通过反射来修改变量的值,当使用Set***方法需要通过对应的指针类型完成,这样才能改变传入的变量的值,同时需要使用到reflect.Value.Elem()方法;

package main
import (
"fmt"
"reflect"
)
func ChangeValue(val interface{}) {
rVal := reflect.ValueOf(val)
fmt.Printf("%v: %v\n", rVal, rVal.Elem())
rVal.Elem().SetInt(30)
}
func main() {
var i int = 10
fmt.Printf("%v: %v\n", &i, i)
rVal := reflect.ValueOf(&i)
rVal.Elem().SetInt(20)
fmt.Println(i)
ChangeValue(&i)
fmt.Println(i)
}7)使用反射来遍历结构体的字段、获取结构体的标签值,调用结构体的方法;修改结构体字段值,需要在调用函数时传入地址;



package main
import (
"fmt"
"reflect"
)
/* 使用反射来遍历结构体的字段,调用结构体的方法,并获取结构体的标签值 */
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Sex rune `json:"sex"`
Phone string `json:"phone"`
}
func NewPerson(name string, age int, sex rune, phone string) *Person {
return &Person{
Name: name,
Age: age,
Sex: sex,
Phone: phone,
}
}
func (this Person) Print() {
fmt.Println(".........................")
fmt.Printf("name:%v,age=%v,sex=%v,phone=%v\n", this.Name, this.Age, this.Sex, this.Phone)
fmt.Println(".........................")
}
func (this *Person) SetAge(age int) {
this.Age = age
}
func (this *Person) SetName(name string) {
this.Name = name
}
func reflectStruct1(val interface{}) {
// 获取reflect.Type类型
rTyp := reflect.TypeOf(val)
// 获取reflect.Value类型
rVal := reflect.ValueOf(val)
// 得到结构体的Type、Kind
fmt.Printf("type=%v, kind=%v\n", rVal.Type(), rVal.Kind())
if rVal.Kind() != reflect.Struct {
fmt.Println("rVal's kind is not const reflect.Struct")
return
} else {
// 遍历结构体的所有字段,字段名、结构体变量字段的值、json格式键值对及以及键值对中的值
fieldNums := rVal.NumField()
fmt.Printf("rVal struct has %v fields\n", fieldNums)
for i := 0; i < fieldNums; i++ {
fmt.Printf("field:%v = %v, tag:%v -> %v\n", rTyp.Field(i).Name, rVal.Field(i),
rTyp.Field(i).Tag, rTyp.Field(i).Tag.Get("json"))
}
// 遍历结构体的所有方法(方法的排序默认是按照函数名的ASCII码排序)
methodNums := rVal.NumMethod()
fmt.Printf("rVal struct has %v methods\n", methodNums)
rVal.Method(0).Call(nil)
/*
// 这里由于传递的参数是Person值类型,故内部不能修改结构体变量的字段值
var params1 []reflect.Value
params1 = append(params1, reflect.ValueOf(20))
rVal.Method(1).Call(params1)
var params2 []reflect.Value
params2 = append(params2, reflect.ValueOf("jary"))
rVal.Method(2).Call(params2)
*/
}
}
/* 这里传入的参数是*Person指针类型,故内部能修改传入的结构体变量的字段值 */
func reflectStruct2(val interface{}) {
// 获取reflect.Value类型
rVal := reflect.ValueOf(val)
// 得到结构体的Type、Kind
fmt.Printf("type=%v, kind=%v\n", rVal.Type(), rVal.Kind())
if rVal.Elem().Kind() != reflect.Struct {
fmt.Println("rVal's kind is not const reflect.Struct")
return
} else {
methodNums := rVal.NumMethod()
fmt.Printf("rVal struct has %v methods\n", methodNums)
rVal.Method(0).Call(nil)
// 调用结构体中的Set***()方法,修改传入的变量的字段值
var params1 []reflect.Value
params1 = append(params1, reflect.ValueOf(20))
rVal.Method(1).Call(params1)
var params2 []reflect.Value
params2 = append(params2, reflect.ValueOf("jary"))
rVal.Method(2).Call(params2)
rVal.Method(0).Call(nil)
}
}
func main() {
var person *Person = NewPerson("tom", 10, '男', "10088")
reflectStruct1(*person)
reflectStruct2(person)
}7.4 反射的实践:
1、定义两个函数test1、test2,定义一个适配器函数用作统一处理的接口。(用反射机制实现)
package main
import (
"fmt"
"reflect"
"strconv"
)
func main() {
test1 := func(num1 int, num2 int, num3 int) {
fmt.Println(num1 + num2 + num3)
}
test2 := func(num int, str string) string {
fmt.Println(str + strconv.Itoa(num))
return str + strconv.Itoa(num)
}
bridge := func(call interface{}, args ...interface{}) {
n := len(args)
var params []reflect.Value = make([]reflect.Value, n)
for i := 0; i < n; i++ {
params[i] = reflect.ValueOf(args[i])
}
var function reflect.Value = reflect.ValueOf(call)
fmt.Println(function.Type())
function.Call(params)
}
bridge(test1, 1, 2, 3)
bridge(test2, 1, "hello ")
}2、使用反射操作结构体数据类型:
package main
import (
"fmt"
"reflect"
)
type User struct {
Name string
Age int
}
var (
user *User
rVal reflect.Value
)
func main() {
user = &User{"tome", 10}
rVal = reflect.ValueOf(user)
fmt.Printf("type:%v, kind:%v\n", rVal.Type(), rVal.Kind())
rVal_ := rVal.Elem()
fmt.Printf("type:%v, kind:%v\n", rVal_.Type(), rVal_.Kind())
fmt.Printf("rVal has %v fields\n", rVal_.NumField())
rVal_.Field(0).SetString("jary")
rVal_.Field(1).SetInt(20)
fmt.Println(rVal_)
}